













効率的なデータベース管理は、大規模なデータセットを処理しながら最適なパフォーマンスと保守の容易さを維持するために不可欠です。PostgreSQLにおけるテーブルパーティショニングは、大きなテーブルをより小さな、管理しやすいパーティションと呼ばれる部分に論理的に分割する堅牢な方法です。この技術は、クエリのパフォーマンス向上、保守タスクの簡略化、ストレージコストの削減に役立ちます。

この記事では、PostgreSQLでのテーブルパーティショニングの作成と管理に詳しく踏み込み、時間ベースとシリアルベースのパーティショニングのためのpg_partman拡張機能に焦点を当てています。PostgreSQLでサポートされているパーティションの種類について詳細に説明し、実際のユースケースや具体的な例を示してその実装を説明します。
序論
現代のアプリケーションは膨大な量のデータを生成し、これらのボリュームを処理するために効率的なデータベース管理戦略が必要です。テーブルパーティショニングは、大きなテーブルをより小さな、論理的に関連するセグメントに分割する手法です。PostgreSQLはこのようなデータセットを効果的に管理するための堅牢なパーティショニングフレームワークを提供しています。
パーティショニングの必要性
- クエリのパフォーマンス向上。クエリのプルーニングやクエリの除外制約を使用して関係のないパーティションを素早くスキップできます。
- 保守の簡略化。パーティション固有の操作(例:vacuumingや再インデックス作業)をより小さなデータセットで実行できます。
- 効率的なアーカイブ。古いパーティションを削除またはアーカイブでき、アクティブなデータセットに影響を与えません。
- 拡張性。パーティショニングは、特に分散環境において水平スケーリングを可能にします。
ネイティブ vs 拡張ベースのパーティショニング
PostgreSQLのネイティブの宣言型パーティショニングは、パーティショニングの多くの側面を簡素化しますが、pg_partmanのような拡張機能は、特に動的なユースケースに対して追加の自動化および管理機能を提供します。
ネイティブパーティショニング vs pg_partman
| Feature | Native Partitioning | pg_partman |
|---|---|---|
| 自動化 | 限定 | 包括的 |
| パーティションの種類 | 範囲、リスト、ハッシュ | 時間、シリアル(高度) |
| メンテナンス | 手動スクリプトが必要 | 自動化された |
| 使いやすさ | SQLの専門知識が必要 | 簡素化された |
PostgreSQLにおけるテーブルパーティショニングの種類
PostgreSQLは、3つの主要なパーティショニング戦略をサポートしています: 範囲、リスト、ハッシュ。それぞれが異なるユースケースに適した独自の特性を持っています。
範囲パーティショニング
範囲パーティショニングは、特定の列の値の範囲に基づいてテーブルをパーティションに分割します。通常は、日付や数値の列です。
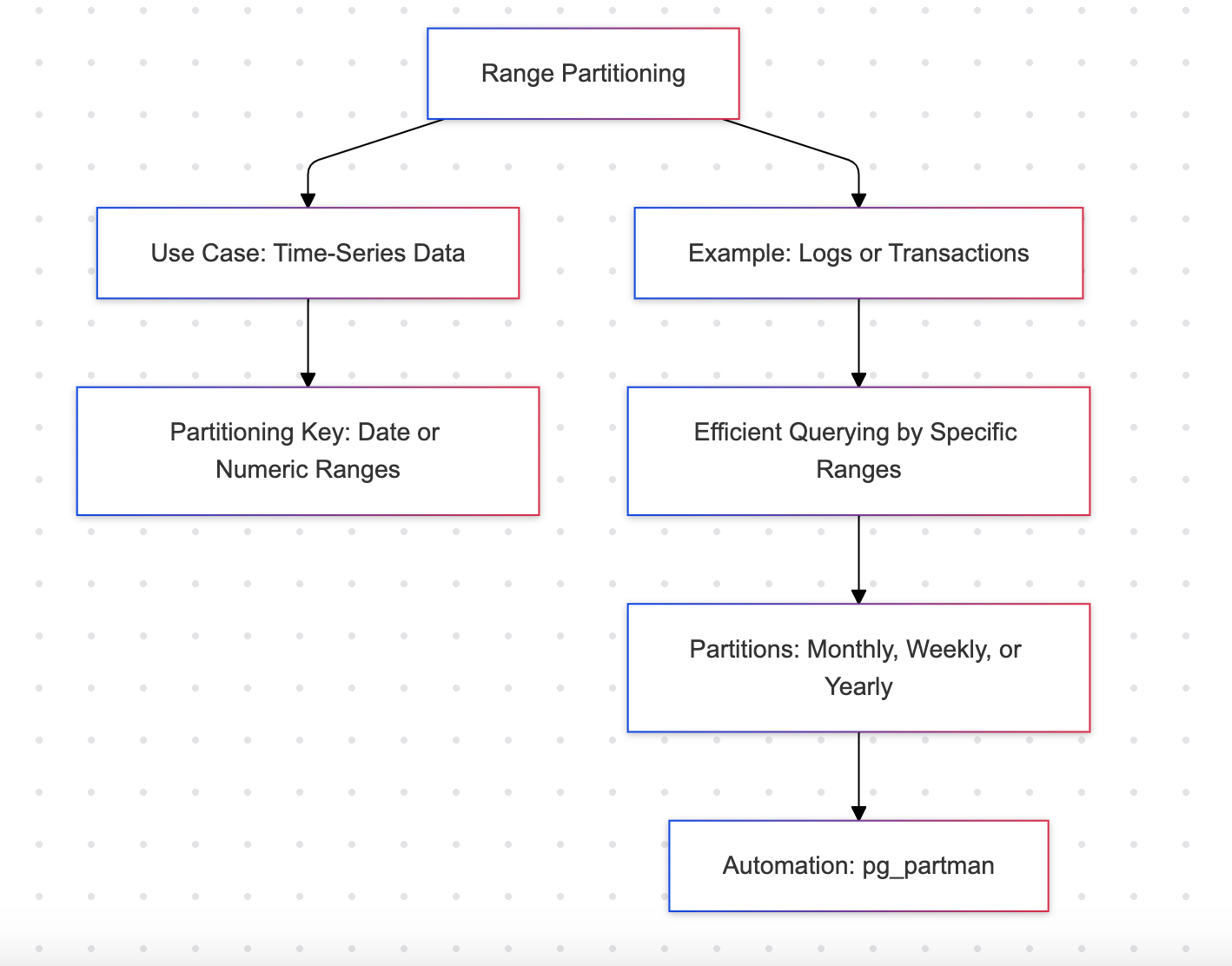
例: 月次売上データ
CREATE TABLE sales (
sale_id SERIAL,
sale_date DATE NOT NULL,
amount NUMERIC
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2023_01 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
利点
- ログや取引などの時系列データに効率的
- 特定の月のデータを取得するなどの連続クエリをサポートします
欠点
- 事前に定義された範囲が必要であり、スキーマの頻繁な更新を引き起こす可能性がある
リストパーティショニング
リストパーティショニングは、地域やカテゴリなどの離散値に基づいてデータを分割します。
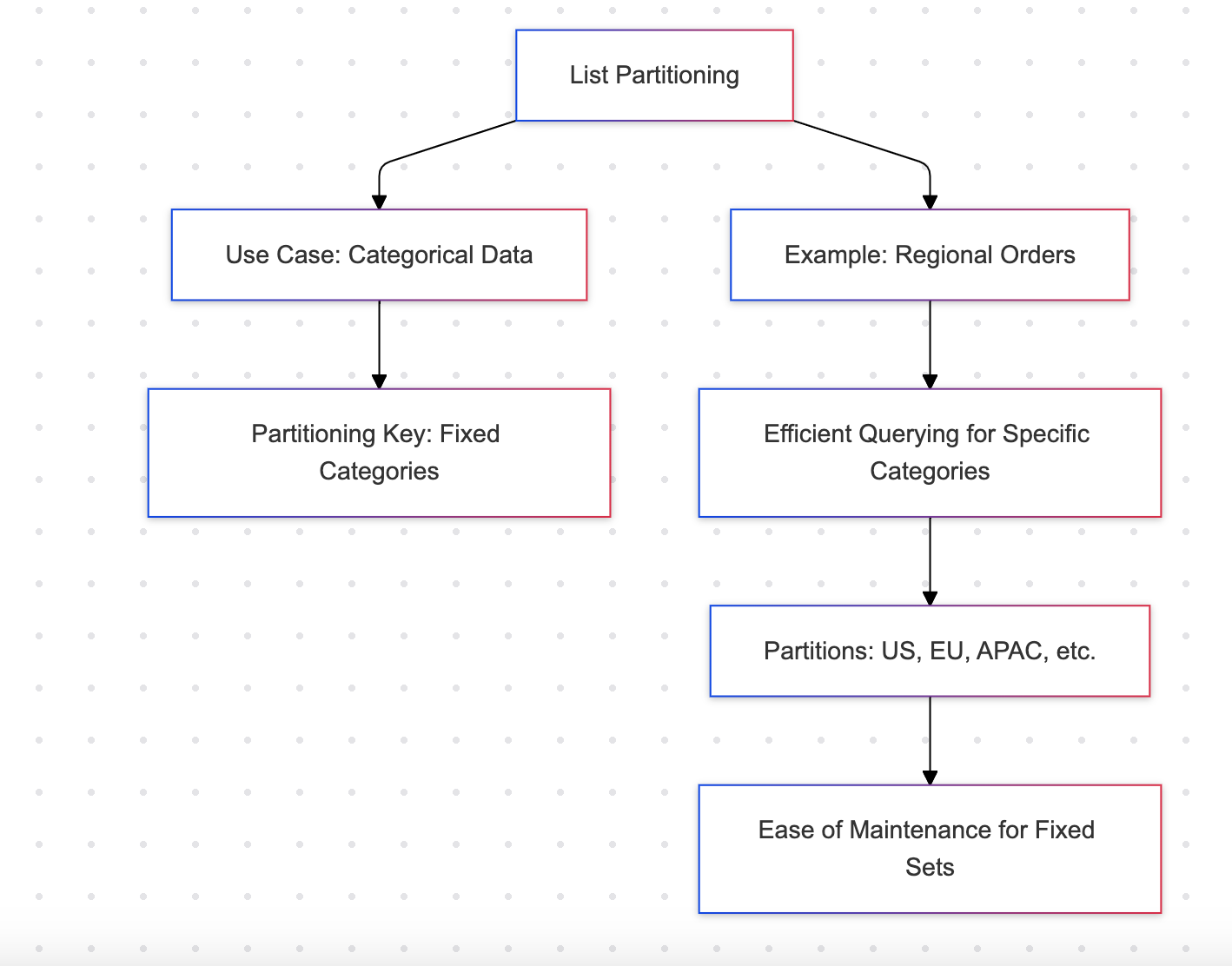
例:地域別の注文
CREATE TABLE orders (
order_id SERIAL,
region TEXT NOT NULL,
amount NUMERIC
) PARTITION BY LIST (region);
CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US');
CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('EU');
利点
- カテゴリ数が有限なデータセットに適しています(例:地域、部門)
- 固定されたパーティションセットを管理するのは簡単です
欠点
- 動的または拡張カテゴリには適していません
ハッシュパーティショニング
ハッシュパーティショニングは、ハッシュ関数を使用して行を複数のパーティションに分散します。これによりデータが均等に分散されます。
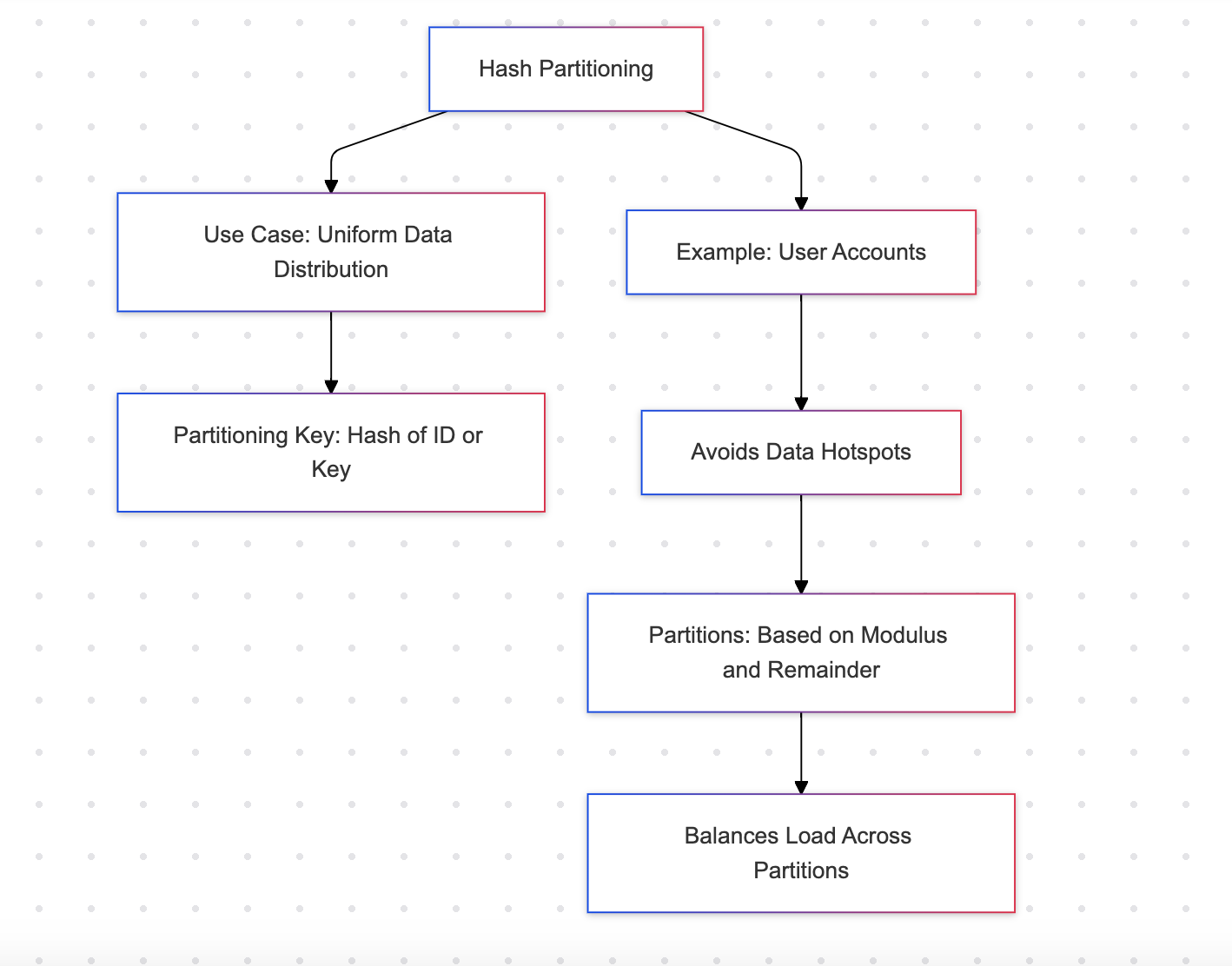
例:ユーザーアカウント
CREATE TABLE users (
user_id SERIAL,
username TEXT NOT NULL
) PARTITION BY HASH (user_id);
CREATE TABLE users_partition_0 PARTITION OF users
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
利点
- ホットスポットを防ぎ、パーティション全体にデータが均等に分散されます
- 均等に分散されたワークロードに適しています
欠点
- 人間が読み取れない; パーティションを直感的に特定することはできません
pg_partman:包括的ガイド
pg_partmanは、特に時間ベースやシリアルベースのデータセットのパーティション管理を簡素化するPostgreSQLの拡張機能です。
インストールとセットアップ
pg_partmanは、PostgreSQLで拡張機能としてインストールする必要があります。パーティション化されたテーブルを動的に作成および管理するための一連の関数を提供します。
- パッケージマネージャーを使用してインストールします:
シェル
sudo apt-get install postgresql-pg-partman - データベースに拡張機能を作成します:
SQL
CREATE EXTENSION pg_partman;
パーティショニングの設定
pg_partmanは、時系列データや連続した識別子を持つデータセットに特に有用な、時間ベースおよびシリアルベースのパーティショニングをサポートしています。
時間ベースのパーティショニングの例
CREATE TABLE logs (
id SERIAL,
log_time TIMESTAMP NOT NULL,
message TEXT
);
SELECT partman.create_parent(
p_parent_table := 'public.logs',
p_control := 'log_time',
p_type := 'time',
p_interval := 'daily'
);
この設定:
- 毎日のパーティションを自動的に作成します
- ログデータのクエリとメンテナンスを簡素化します
シリアルベースのパーティショニングの例
CREATE TABLE transactions (
transaction_id BIGSERIAL PRIMARY KEY,
details TEXT NOT NULL
);
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 100000
);
これにより、10万行毎にパーティションを作成し、親テーブルを管理可能な状態に保ちます。
自動化機能
自動メンテナンス
将来のパーティションが事前に作成されるよう、run_maintenance()を使用します:
SELECT partman.run_maintenance();
保持ポリシー
古いパーティションを自動的に削除するための保持期間を定義します:
UPDATE partman.part_config
SET retention = '12 months'
WHERE parent_table = 'public.logs';
pg_partmanの利点
- 動的なパーティション作成を簡素化します
- クリーンアップとメンテナンスを自動化します
- 手動スキーマ更新の必要性を軽減します
テーブルパーティショニングの実用的なユースケース
- ログ管理。日ごとにパーティション分割された高頻度ログを簡単にアーカイブおよびクエリできます。
- マルチリージョンデータ。地域ごとに注文を分割することで、拡張性が向上したeコマースシステム。
- 時系列データ。パーティショニングされたテレメトリデータを持つIoTアプリケーション。
ログ管理
ログを日付や月ごとにパーティション分割して、高頻度データを効率的に管理します。
SELECT partman.create_parent(
p_parent_table := 'public.server_logs',
p_control := 'timestamp',
p_type := 'time',
p_interval := 'monthly'
);
マルチリージョンデータ
販売や在庫データを地域ごとにパーティション分割して、スケーラビリティを向上させます。
CREATE TABLE sales (
sale_id SERIAL,
region TEXT NOT NULL
) PARTITION BY LIST (region);
高容量トランザクション
トランザクションをシリアルIDでパーティション分割して、インデックスの肥大化を回避します。
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 10000
);
結論
テーブルのパーティショニングは大規模データセットを管理するための不可欠なテクニックです。PostgreSQLの組み込み機能とpg_partman拡張機能を組み合わせると、動的かつ自動化されたパーティショニング戦略の実装が容易になります。 これらのツールは、データベース管理者がパフォーマンスを向上させ、メンテナンスを簡素化し、効果的にスケーリングするのを可能にします。
パーティショニングは、特に高容量アプリケーションにおいて、現代のデータベース管理の基盤です。これらの概念を理解し適用することで、堅牢でスケーラブルなデータベースシステムを確保できます。
Source:
https://dzone.com/articles/postgresql-partitioning-pg-partman-data-management