













A eficiente gestão de banco de dados é vital para lidar com grandes conjuntos de dados enquanto mantém o desempenho ótimo e a facilidade de manutenção. A partição de tabelas no PostgreSQL é um método robusto para dividir logicamente uma grande tabela em partes menores e gerenciáveis chamadas partições. Essa técnica ajuda a melhorar o desempenho das consultas, simplificar tarefas de manutenção e reduzir custos de armazenamento.

Este artigo explora profundamente a criação e gestão de partição de tabelas no PostgreSQL, focando na extensão pg_partman para partição baseada em tempo e em série. Os tipos de partições suportados no PostgreSQL são discutidos em detalhes, juntamente com casos de uso do mundo real e exemplos práticos para ilustrar sua implementação.
Introdução
Aplicações modernas geram quantidades massivas de dados, exigindo estratégias eficientes de gestão de bancos de dados para lidar com esses volumes. A partição de tabelas é uma técnica onde uma grande tabela é dividida em segmentos menores e logicamente relacionados. O PostgreSQL oferece um framework de partição robusto para gerenciar efetivamente esses conjuntos de dados.
Por que a Partição?
- Melhora no desempenho das consultas. As consultas podem pular rapidamente partições irrelevantes usando a exclusão de restrições ou poda de consultas.
- Manutenção simplificada. Operações específicas de partições, como aspiração ou reindexação, podem ser realizadas em conjuntos de dados menores.
- Arquivamento eficiente. Partições mais antigas podem ser excluídas ou arquivadas sem impactar o conjunto de dados ativo.
- Escalabilidade. A partição permite a escalabilidade horizontal, especialmente em ambientes distribuídos.
Nativo vs Baseado em Extensão
A partição declarativa nativa do PostgreSQL simplifica muitos aspectos da partição, enquanto extensões como pg_partman fornecem automação adicional e capacidades de gerenciamento, especialmente para casos de uso dinâmicos.
Partição Nativa vs pg_partman
| Feature | Native Partitioning | pg_partman |
|---|---|---|
| Automação | Limitada | Completa |
| Tipos de Partição | Range, Lista, Hash | Tempo, Serial (avançado) |
| Manutenção | Scripts manuais necessários | Automatizada |
| Facilidade de Uso | Requer expertise em SQL | Simplificada |
Tipos de Particionamento de Tabela no PostgreSQL
O PostgreSQL suporta três estratégias de partição principais: Range, Lista e Hash. Cada uma possui características únicas adequadas para diferentes casos de uso.
Particionamento por Range
O particionamento por range divide uma tabela em partições com base em um intervalo de valores em uma coluna específica, frequentemente uma coluna de data ou numérica.
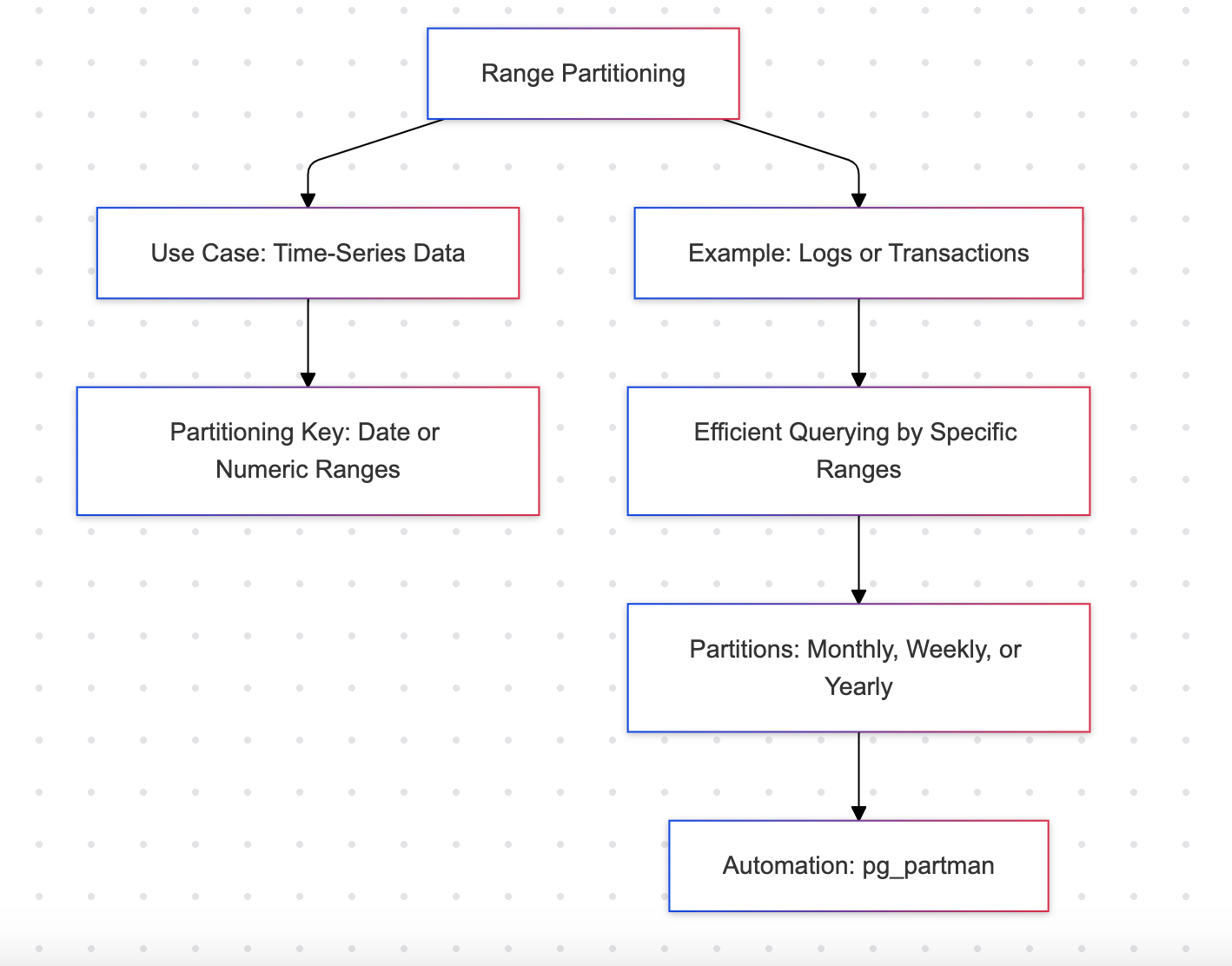
Exemplo: Dados de vendas mensais
CREATE TABLE sales (
sale_id SERIAL,
sale_date DATE NOT NULL,
amount NUMERIC
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2023_01 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
Vantagens
- Eficiente para dados de séries temporais como logs ou transações
- Suporta consultas sequenciais, como recuperar dados para meses específicos
Desvantagens
- Requer intervalos predefinidos, o que pode levar a atualizações frequentes no esquema
Particionamento de Lista
O particionamento de lista divide os dados com base em um conjunto discreto de valores, como regiões ou categorias.
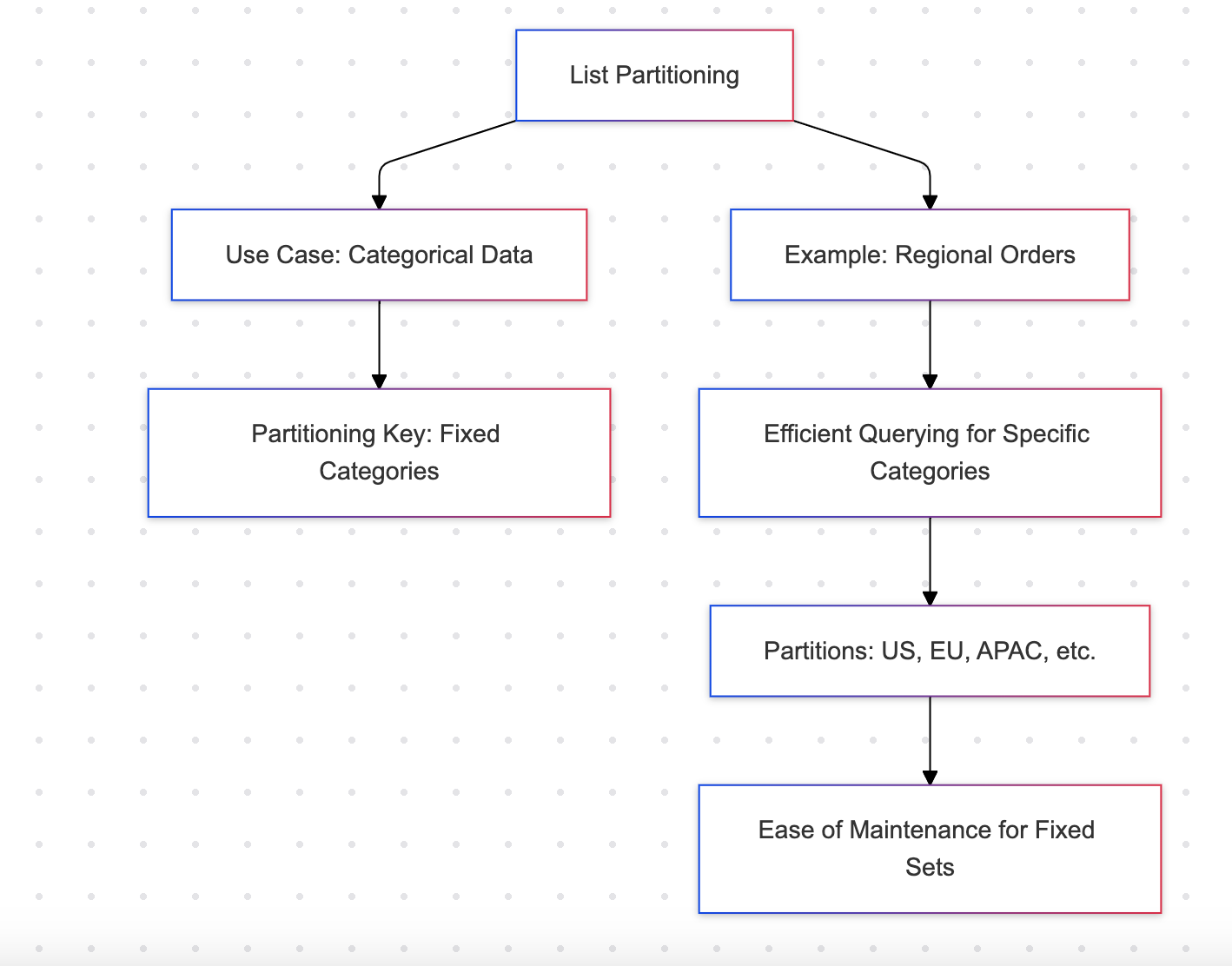
Exemplo: Pedidos regionais
CREATE TABLE orders (
order_id SERIAL,
region TEXT NOT NULL,
amount NUMERIC
) PARTITION BY LIST (region);
CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US');
CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('EU');
Vantagens
- Ideal para conjuntos de dados com um número finito de categorias (por exemplo, regiões, departamentos)
- Fácil de gerenciar para um conjunto fixo de partições
Desvantagens
- Não adequado para categorias dinâmicas ou em expansão
Particionamento por Hash
O particionamento por hash distribui linhas em um conjunto de partições usando uma função de hash. Isso garante uma distribuição uniforme dos dados.
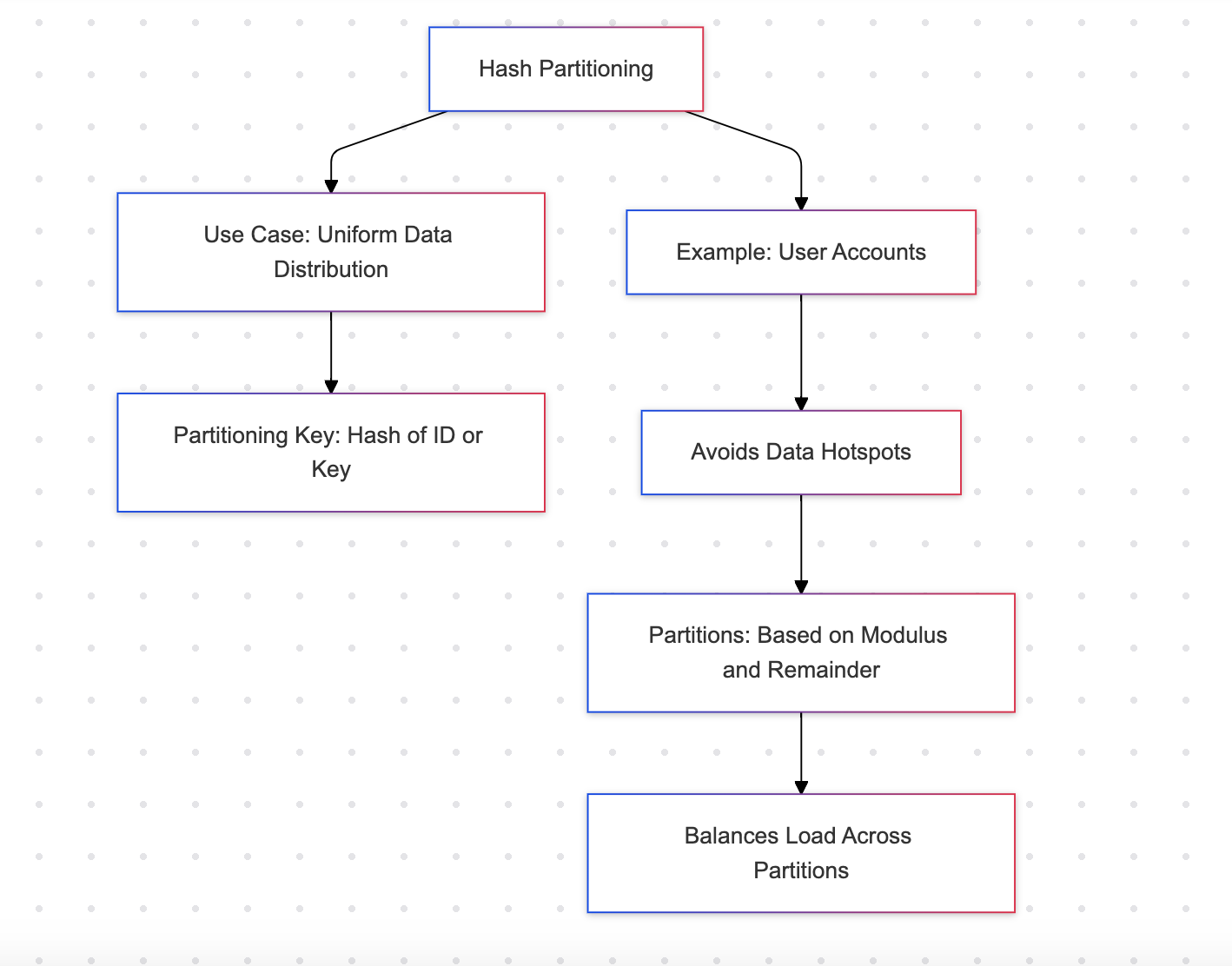
Exemplo: Contas de usuário
CREATE TABLE users (
user_id SERIAL,
username TEXT NOT NULL
) PARTITION BY HASH (user_id);
CREATE TABLE users_partition_0 PARTITION OF users
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
Vantagens
- Garante uma distribuição equilibrada entre as partições, prevenindo pontos de acesso
- Adequado para cargas de trabalho uniformemente distribuídas
Desvantagens
- Não é legível para humanos; as partições não podem ser identificadas intuitivamente
pg_partman: Um Guia Abrangente
pg_partman é uma extensão do PostgreSQL que simplifica o gerenciamento de partições, especialmente para conjuntos de dados baseados em tempo e serial.
Instalação e Configuração
pg_partman requer instalação como uma extensão no PostgreSQL. Ele fornece um conjunto de funções para criar e gerenciar tabelas particionadas dinamicamente.
- Instale usando seu gerenciador de pacotes:
Shell
sudo apt-get install postgresql-pg-partman - Crie a extensão em seu banco de dados:
SQL
CRIE EXTENSÃO pg_partman;
Configurando Particionamento
pg_partman suporta particionamento baseado em tempo e baseado em série, que são particularmente úteis para conjuntos de dados com dados temporais ou identificadores sequenciais.
Exemplo de Particionamento Baseado em Tempo
CREATE TABLE logs (
id SERIAL,
log_time TIMESTAMP NOT NULL,
message TEXT
);
SELECT partman.create_parent(
p_parent_table := 'public.logs',
p_control := 'log_time',
p_type := 'time',
p_interval := 'daily'
);
Esta configuração:
- Cria automaticamente partições diárias
- Simplifica consultas e manutenção para dados de log
Exemplo de Particionamento Baseado em Série
CREATE TABLE transactions (
transaction_id BIGSERIAL PRIMARY KEY,
details TEXT NOT NULL
);
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 100000
);
Isto cria partições a cada 100.000 linhas, garantindo que a tabela pai permaneça gerenciável.
Recursos de Automação
Manutenção Automática
Use run_maintenance() para garantir que futuras partições sejam pré-criadas:
SELECT partman.run_maintenance();
Políticas de Retenção
Defina períodos de retenção para descartar automaticamente partições antigas:
UPDATE partman.part_config
SET retention = '12 months'
WHERE parent_table = 'public.logs';
Vantagens do pg_partman
- Simplifica a criação dinâmica de partições
- Automatiza a limpeza e manutenção
- Reduz a necessidade de atualizações manuais de esquema
Casos de Uso Práticos para Particionamento de Tabelas
- Gerenciamento de logs. Logs de alta frequência particionados por dia para arquivamento e consulta fáceis.
- Dados multirregionais. Sistemas de comércio eletrônico dividindo pedidos por região para melhor escalabilidade.
- Dados de séries temporais. Aplicações de IoT com dados de telemetria particionados.
Gerenciamento de Logs
Divida os logs por dia ou mês para gerenciar eficientemente dados de alta frequência.
SELECT partman.create_parent(
p_parent_table := 'public.server_logs',
p_control := 'timestamp',
p_type := 'time',
p_interval := 'monthly'
);
Dados Multirregionais
Divida os dados de vendas ou inventário por região para melhor escalabilidade.
CREATE TABLE sales (
sale_id SERIAL,
region TEXT NOT NULL
) PARTITION BY LIST (region);
Transações de Alto Volume
Divida as transações por número de série ID para evitar índices inflados.
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 10000
);
Conclusão
A partição de tabelas é uma técnica indispensável para gerenciar grandes conjuntos de dados. Os recursos integrados do PostgreSQL, combinados com a extensão pg_partman, tornam mais fácil a implementação de estratégias de partição dinâmica e automatizada. Essas ferramentas permitem aos administradores de banco de dados melhorar o desempenho, simplificar a manutenção e escalar de forma eficaz.
A partição é um pilar para o gerenciamento de banco de dados moderno, especialmente em aplicações de alto volume. Compreender e aplicar esses conceitos garante sistemas de banco de dados robustos e escaláveis.
Source:
https://dzone.com/articles/postgresql-partitioning-pg-partman-data-management