













La gestión eficiente de bases de datos es vital para manejar grandes conjuntos de datos manteniendo un rendimiento óptimo y facilidad de mantenimiento. La partición de tablas en PostgreSQL es un método robusto para dividir lógicamente una tabla grande en piezas más pequeñas y manejables llamadas particiones. Esta técnica ayuda a mejorar el rendimiento de las consultas, simplificar las tareas de mantenimiento y reducir los costos de almacenamiento.

Este artículo profundiza en la creación y gestión de particiones de tablas en PostgreSQL, centrándose en la extensión pg_partman para particionamiento basado en tiempo y serie. Se discuten en detalle los tipos de particiones soportados en PostgreSQL, junto con casos de uso del mundo real y ejemplos prácticos para ilustrar su implementación.
Introducción
Las aplicaciones modernas generan cantidades masivas de datos, lo que requiere estrategias eficientes de gestión de bases de datos para manejar estos volúmenes. La partición de tablas es una técnica donde una tabla grande se divide en segmentos más pequeños y lógicamente relacionados. PostgreSQL ofrece un sólido marco de particionamiento para gestionar estos conjuntos de datos de manera efectiva.
¿Por qué particionar?
- Mejora del rendimiento de las consultas. Las consultas pueden omitir rápidamente particiones irrelevantes utilizando la exclusión de restricciones o la poda de consultas.
- Simplificación del mantenimiento. Operaciones específicas de particiones como el vaciado o la reindexación pueden realizarse en conjuntos de datos más pequeños.
- Archivado eficiente. Las particiones antiguas pueden ser eliminadas o archivadas sin afectar al conjunto de datos activo.
- Escalabilidad. La partición habilita el escalado horizontal, especialmente en entornos distribuidos.
Nativa vs. Particionamiento basado en extensión
El particionamiento declarativo nativo de PostgreSQL simplifica muchos aspectos del particionamiento, mientras que extensiones como pg_partman proporcionan automatización adicional y capacidades de gestión, especialmente para casos de uso dinámicos.
Particionamiento nativo vs. pg_partman
| Feature | Native Partitioning | pg_partman |
|---|---|---|
| Automatización | Limitada | Completa |
| Tipos de partición | Intervalo, Lista, Hash | Tiempo, Serial (avanzado) |
| Mantenimiento | Se requieren scripts manuales | Automatizado |
| Facilidad de uso | Requiere experiencia en SQL | Simplificado |
Tipos de particionamiento de tablas en PostgreSQL
PostgreSQL admite tres estrategias de particionamiento principales: Intervalo, Lista y Hash. Cada una tiene características únicas adecuadas para diferentes casos de uso.
Particionamiento por intervalo
El particionamiento por intervalo divide una tabla en particiones basadas en un rango de valores en una columna específica, frecuentemente una columna de fecha o numérica.
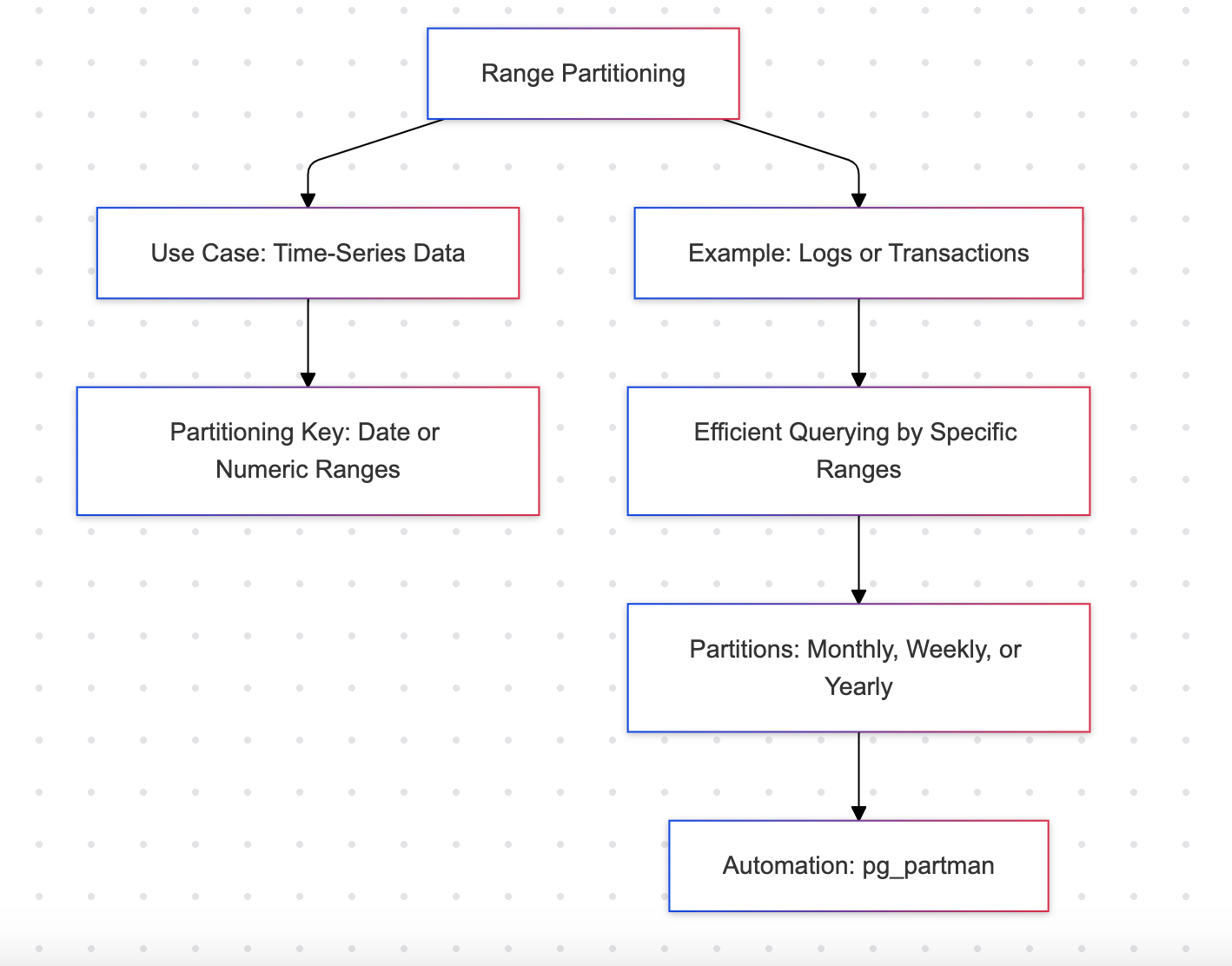
Ejemplo: Datos de ventas mensuales
CREATE TABLE sales (
sale_id SERIAL,
sale_date DATE NOT NULL,
amount NUMERIC
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2023_01 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
Ventajas
- Eficiente para datos de series temporales como logs o transacciones
- Compatible con consultas secuenciales, como recuperar datos para meses específicos
Desventajas
- Requiere rangos predefinidos, lo que puede llevar a actualizaciones frecuentes del esquema
Particionamiento por lista
El particionamiento por lista divide los datos en función de un conjunto discreto de valores, como regiones o categorías.
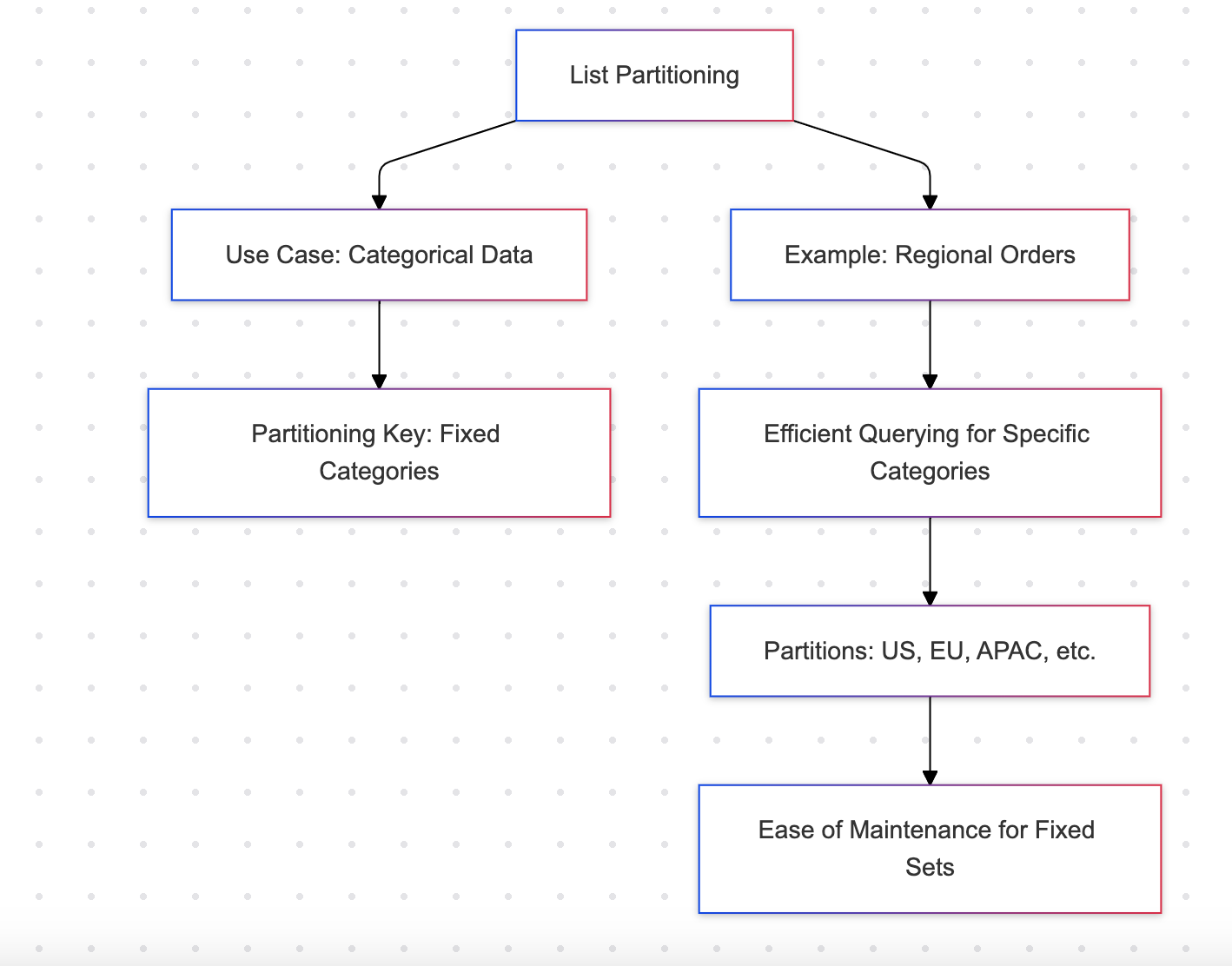
Ejemplo: Pedidos regionales
CREATE TABLE orders (
order_id SERIAL,
region TEXT NOT NULL,
amount NUMERIC
) PARTITION BY LIST (region);
CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US');
CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('EU');
Ventajas
- Ideal para conjuntos de datos con un número finito de categorías (por ejemplo, regiones, departamentos)
- Fácil de gestionar para un conjunto fijo de particiones
Desventajas
- No es adecuado para categorías dinámicas o en expansión
Particionamiento por hash
El particionamiento por hash distribuye filas en un conjunto de particiones utilizando una función de hash. Esto asegura una distribución uniforme de los datos.
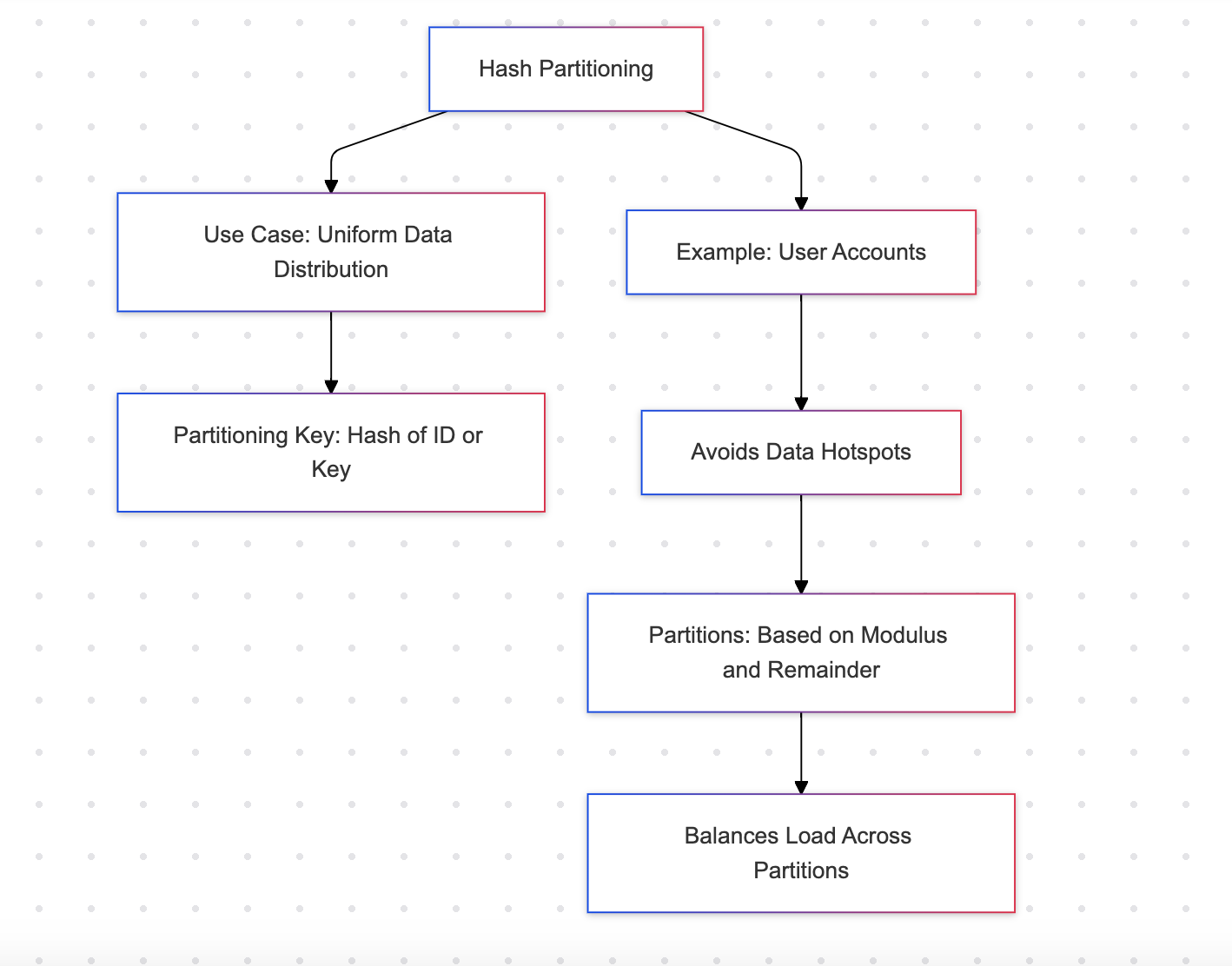
Ejemplo: Cuentas de usuario
CREATE TABLE users (
user_id SERIAL,
username TEXT NOT NULL
) PARTITION BY HASH (user_id);
CREATE TABLE users_partition_0 PARTITION OF users
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
Ventajas
- Garantiza una distribución equilibrada entre las particiones, evitando puntos críticos
- Adecuado para cargas de trabajo uniformemente distribuidas
Desventajas
- No es legible para humanos; las particiones no pueden identificarse de manera intuitiva
pg_partman: Una guía completa
pg_partman es una extensión de PostgreSQL que simplifica la gestión de particiones, especialmente para conjuntos de datos basados en el tiempo y en series.
Instalación y configuración
pg_partman requiere instalación como una extensión en PostgreSQL. Proporciona un conjunto de funciones para crear y gestionar tablas particionadas de forma dinámica.
- Instale utilizando su gestor de paquetes:
Shell
sudo apt-get install postgresql-pg-partman - Cree la extensión en su base de datos:
SQL
CREATE EXTENSION pg_partman;
Configuración de Particionamiento
pg_partman admite particionamiento basado en tiempo y en serie, que son particularmente útiles para conjuntos de datos con datos temporales o identificadores secuenciales.
Ejemplo de Particionamiento Basado en Tiempo
CREATE TABLE logs (
id SERIAL,
log_time TIMESTAMP NOT NULL,
message TEXT
);
SELECT partman.create_parent(
p_parent_table := 'public.logs',
p_control := 'log_time',
p_type := 'time',
p_interval := 'daily'
);
Esta configuración:
- Crea automáticamente particiones diarias
- Simplifica la consulta y el mantenimiento de datos de registro
Ejemplo de Particionamiento Basado en Serie
CREATE TABLE transactions (
transaction_id BIGSERIAL PRIMARY KEY,
details TEXT NOT NULL
);
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 100000
);
Esto crea particiones cada 100,000 filas, asegurando que la tabla principal permanezca manejable.
Funciones de Automatización
Mantenimiento Automático
Utilice run_maintenance() para asegurar que las futuras particiones estén pre-creadas:
SELECT partman.run_maintenance();
Políticas de Retención
Defina períodos de retención para eliminar automáticamente particiones antiguas:
UPDATE partman.part_config
SET retention = '12 months'
WHERE parent_table = 'public.logs';
Ventajas de pg_partman
- Simplifica la creación dinámica de particiones
- Automatiza la limpieza y el mantenimiento
- Reduce la necesidad de actualizaciones manuales de esquema
Casos de Uso Prácticos para el Particionamiento de Tablas
- Administración de registros. Registros de alta frecuencia particionados por día para facilitar el archivo y la consulta.
- Datos multirregionales. Sistemas de comercio electrónico que dividen pedidos por región para una mejor escalabilidad.
- Datos de series temporales. Aplicaciones de IoT con datos de telemetría particionados.
Gestión de Registros
Particionar registros por día o mes para gestionar eficientemente datos de alta frecuencia.
SELECT partman.create_parent(
p_parent_table := 'public.server_logs',
p_control := 'timestamp',
p_type := 'time',
p_interval := 'monthly'
);
Datos Multi-Regionales
Particionar datos de ventas o inventario por región para una mejor escalabilidad.
CREATE TABLE sales (
sale_id SERIAL,
region TEXT NOT NULL
) PARTITION BY LIST (region);
Transacciones de Alto Volumen
Particionar transacciones por el ID serial para evitar índices inflados.
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 10000
);
Conclusión
La partición de tablas es una técnica indispensable para gestionar grandes conjuntos de datos. Las características integradas de PostgreSQL, combinadas con la extensión pg_partman, facilitan la implementación de estrategias de particionamiento dinámicas y automatizadas. Estas herramientas permiten a los administradores de bases de datos mejorar el rendimiento, simplificar el mantenimiento y escalar de manera efectiva.
El particionamiento es un pilar fundamental para la gestión moderna de bases de datos, especialmente en aplicaciones de alto volumen. Comprender y aplicar estos conceptos garantiza sistemas de bases de datos robustos y escalables.
Source:
https://dzone.com/articles/postgresql-partitioning-pg-partman-data-management