













データ処理の効率化は、ビッグデータ分析に依存して意思決定を行う企業や組織にとって非常に重要です。データ処理のパフォーマンスに大きな影響を与える重要な要素の1つが、データの保存フォーマットです。本記事では、Google Cloud Platform (GCP)におけるビッグデータ環境でのクエリパフォーマンスとコストに関して、Parquet、Avro、ORCといった異なる保存フォーマットがどのように影響を与えるかを探ります。また、ベンチマーク、コストの影響についても議論し、特定のユースケースに基づいた適切なフォーマットの選定に関する推奨事項も提供します。
ビッグデータにおける保存フォーマットの紹介
データ保存フォーマットは、ビッグデータ処理環境の基盤です。保存フォーマットは、データの保存、読み取り、および書き込みの方法を定義し、保存効率、クエリパフォーマンス、およびデータ取得速度に直接影響を与えます。ビッグデータのエコシステムでは、ParquetやORCのようなカラム形式のフォーマットや、Avroのような行ベースのフォーマットが、特定のクエリや処理タスクに最適化されたパフォーマンスを提供するため、広く使用されています。
- Parquet:Parquetは、読み取りが多い操作や分析向けに最適化されたカラム形式の保存フォーマットです。圧縮やエンコーディングの効率が非常に高く、読み取りパフォーマンスや保存効率が優先されるシナリオに最適です。
- Avro:Avroはデータのシリアル化を目的とした行ベースの保存フォーマットです。スキーマの進化に対応しており、データを迅速にシリアル化およびデシリアル化する必要がある、書き込みが多い操作に頻繁に使用されます。
- ORC (Optimized Row Columnar):ORCは、Parquetに似ている列式格納形式ですが、読み書き操作に最適化されており、圧縮において非常に効果的であり、ストレージコストを削減し、データの読み取りを高速化します。
研究目標
この研究の主要な目標は、異なるストレージ形式(Parquet、Avro、ORC)が大規模データ環境でのクエリパフォーマンスとコストにどのように影響を与えるかを評価することです。この記事は、さまざまなクエリタイプとデータ量に基づいてベンチマークを提供し、データエンジニアやアーキテクトが自分の特定の使用状況に最適な形式を選択することを助けることを目的としています。
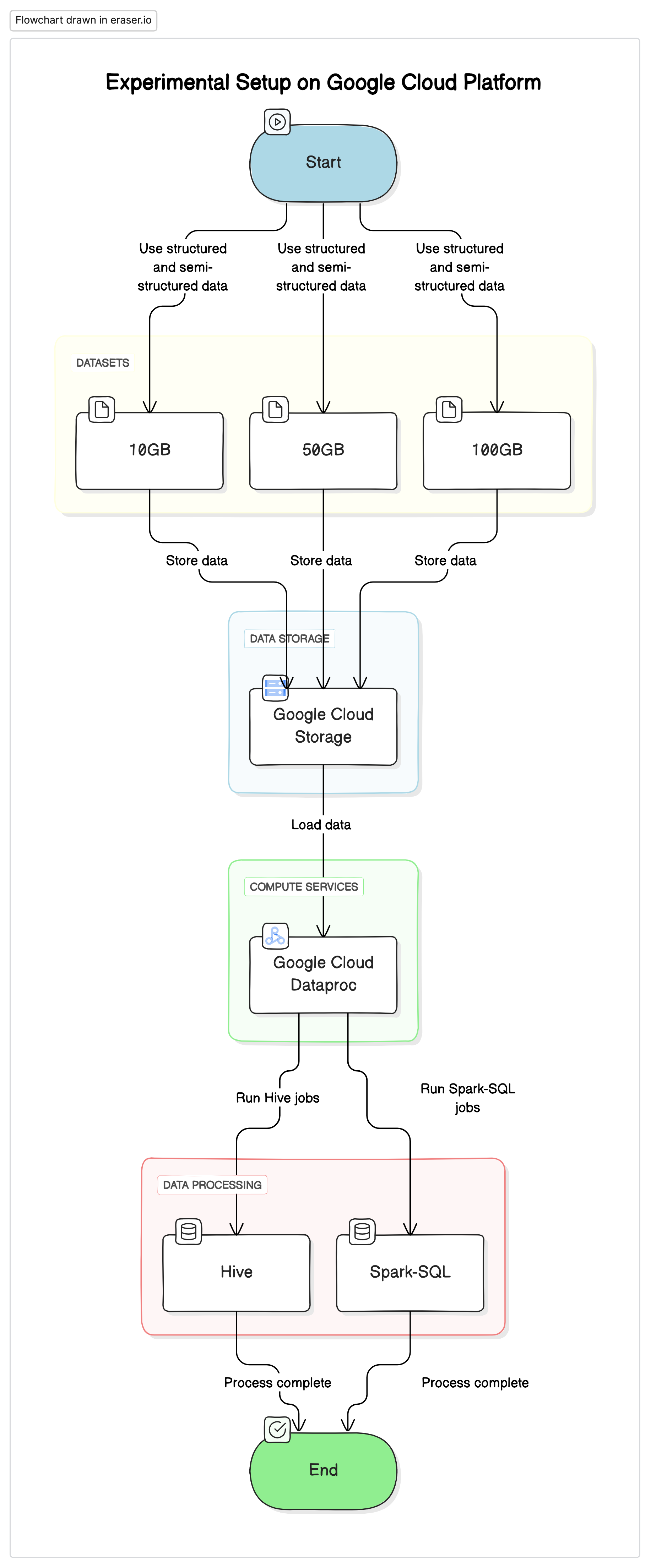
実験装置
この研究を実施するために、私たちはGoogle Cloud Platform(GCP)を基盤とし、Google Cloud Storageをデータリポジトリとし、Google Cloud DataprocをHiveとSpark-SQLのジョブの実行に使用しました。実験で使用されたデータは、構造化されたデータと半構造化されたデータのミックスで、実際のシーンを mimic しました。
主要なコンポーネント
- Google Cloud Storage:異なる形式(Parquet、Avro、ORC)でデータセットを格納するために使用しました。
- Google Cloud Dataproc:管理型Apache HadoopおよびApache Sparkサービスで、HiveとSpark-SQLのジョブを実行するために使用しました。
- データセット:大きさが変わる3つのデータセット(10GB、50GB、100GB)で、異なるデータ型を混在させています。
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
テストクエリ
- 簡単なSELECTクエリ:テーブルから全列を基本とした取得
- 絞り込みクエリ:WHERE句を含んだSELECTクエリを使用して特定の行を抽出
- 集計クエリ:GROUP BYとSUM、AVGなどの集計関数を使用したクエリ
- 結合クエリ:2つ以上のテーブルを共通のキーにより結合するクエリ
結果と分析
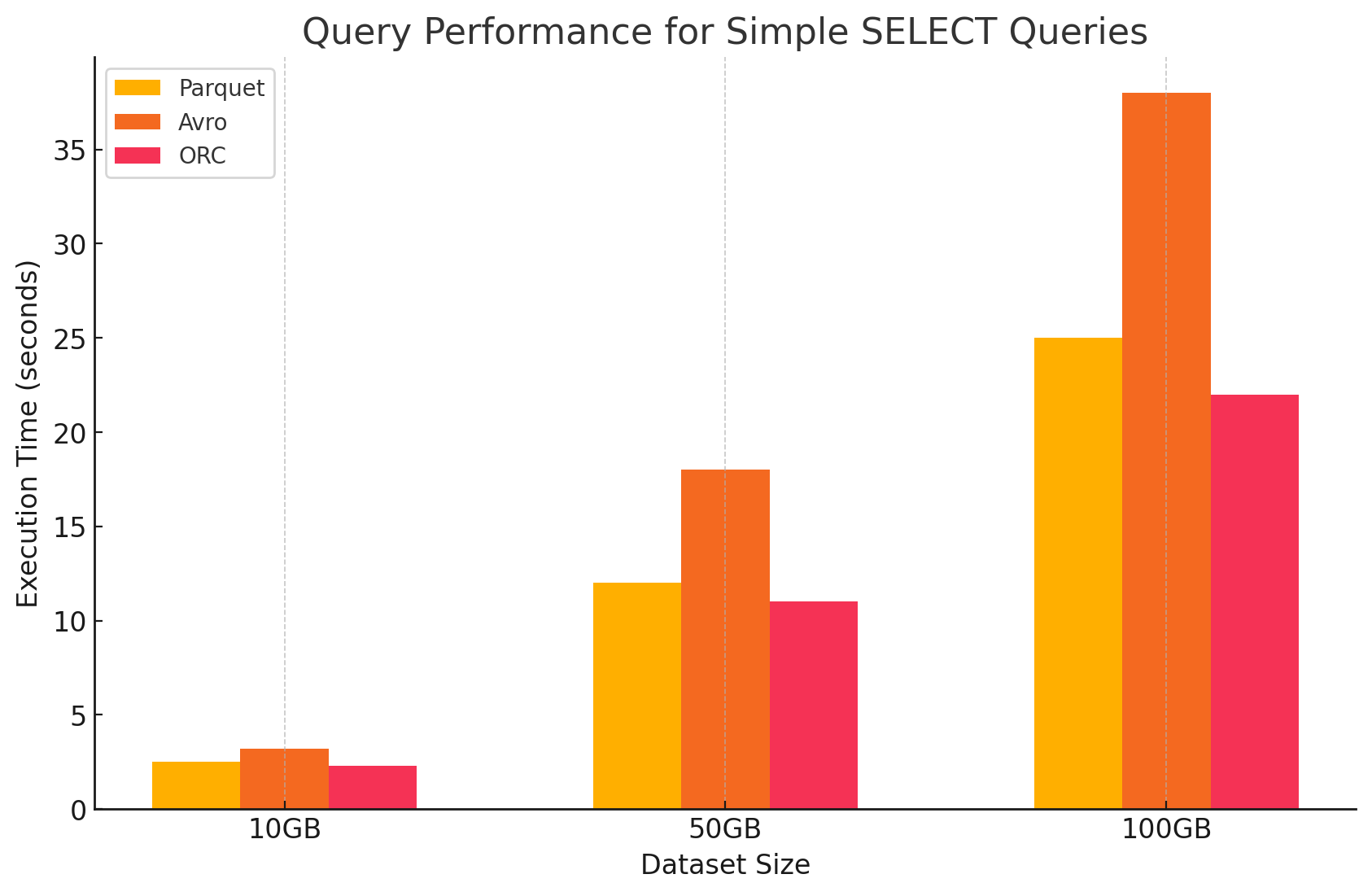
1. 簡単なSELECTクエリ
- Parquet:列単位の格納形式により特定の列に対する高速なスキャンができるため、Parquetは異なった性能を示しました。Parquetファイルは高倍の圧縮があり、ディスクから読み取られるデータ量を減少させ、クエリの実行時間を短縮しました。
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro:Avroは平均的な性能を示しました。行ベースの形式であるため、必要な列だけを読み取る代わりに全ての行を読む必要がありました。これはI/O操作を増やし、ParquetやORCと比較してクエリの性能を低くする結果となりました。
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC:ORCはParquetと似たパフォーマンスを示しましたが、より良い圧縮と最適化された格納技術があり、読み取り速度を向上させました。ORCファイルは列単位であり、SELECTクエリの場合、特定の列しか取得しないことができるため適切です。
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
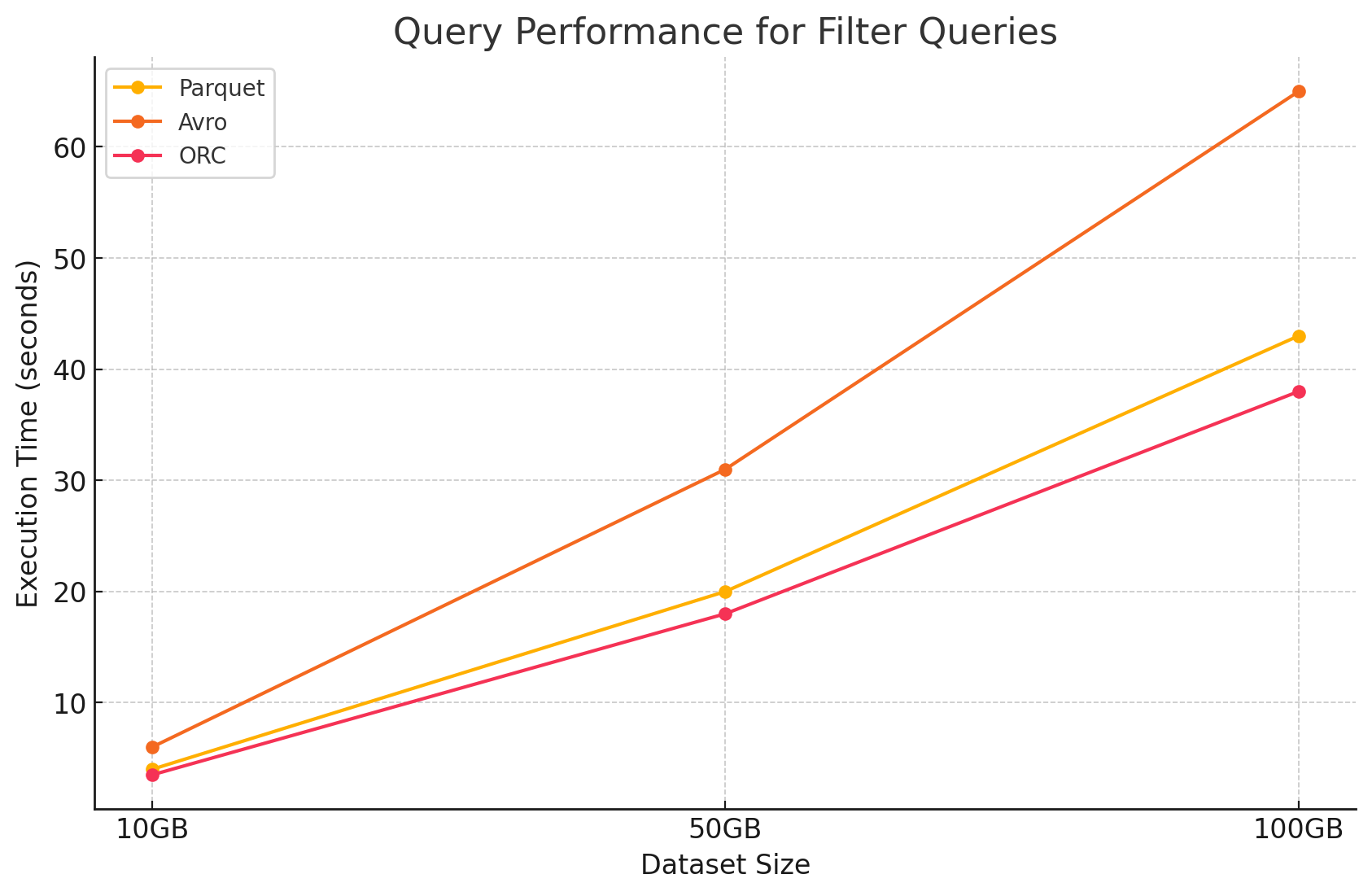
2. 絞り込みクエリ
- Parquet:列単位の特性と不要な列を迅速にスキャンできる能力により、Parquetはパフォーマンス上の利点を維持しました。しかし、フィルターを適用するためにより多くの行をスキャンする必要があり、パフォーマンスは少し影響を受けました。
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro:完全な行を読み取る必要と、すべての列に対してフィルターを適用するために、処理時間が増大し、パフォーマンスが低下しました。
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC:このプロダクトは、フィルタークエリにおいてParquetを少し上回る性能を示しました。これは、データをメモリに読み込まれる前にストレージレベルで直接フィルターリングを行うことができるプロパティを持っているためです。
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
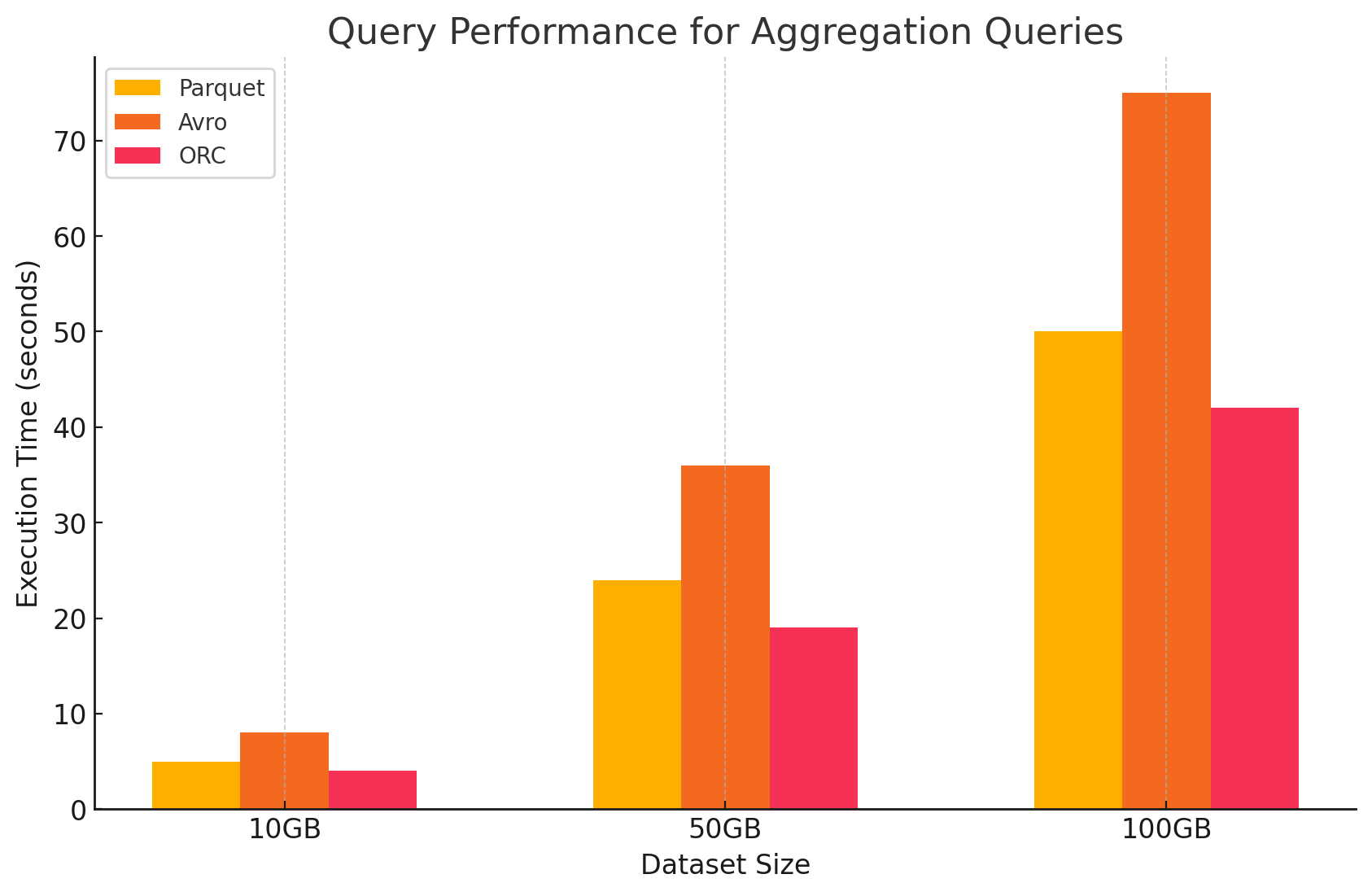
3. 聚合クエリ
- Parquet:Parquetは聚合操作に優れていましたが、ORCに比べて少し効率が低いです。列形式は必要な列に素早くアクセスすることで聚合操作に優れていますが、ParquetはORCが提供しているいくつかの内蔵最適化を欠いています。
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro:Avroは行ベースのストレージにより、行ごとに全列をスキャンして処理する必要があり、計算オーバーヘッドを増やしました。
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC:ORCはParquetとAvroを上回る性能を示した聚合クエリです。ORCの高度なインデックス化と内蔵の圧縮アルゴリズムにより、データアクセスを速くし、I/O操作を減らし、聚合作業に非常に適しています。
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
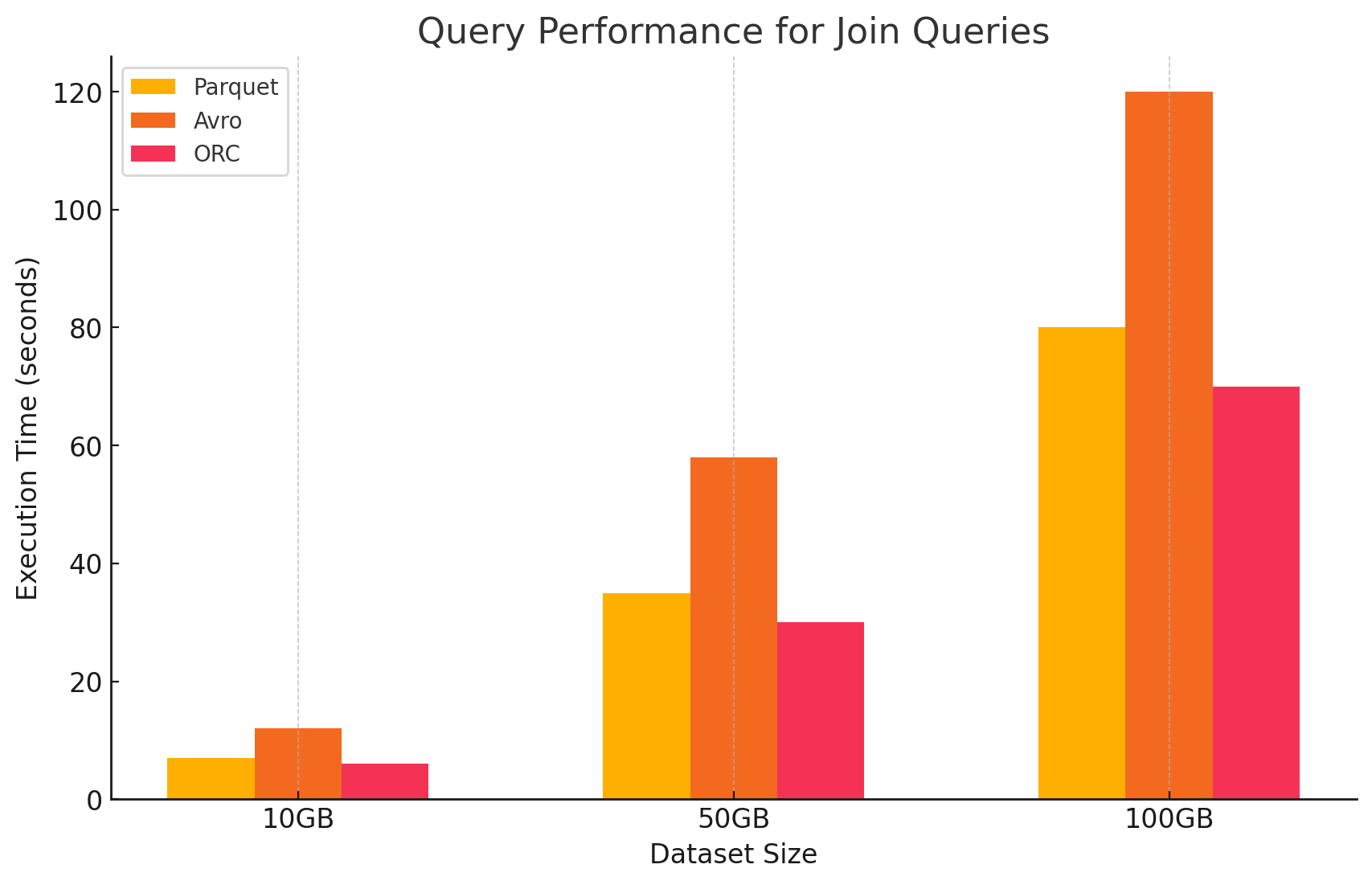
4. 結合クエリ
- Parquet:Parquetは結合操作で良い性能を示しましたが、結合条件に最適化されていないデータ読み取りにより、ORCに比べて効率が低いです。
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC:ORCは結合クエリに優れており、高度なインデックス化とプロパティの推し下げ機能により、結合操作中にスキャンと処理されるデータを最小限にします。
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro: Avroでの結合操作には相当な困難があり、これは結合キーに対する列式最適化の缺乏と、完全な行を読むための高いオーバーヘッドによるものです。
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
ストレージ形式によるコストの影響
1. ストレージ効率とコスト
- ParquetとORC(列式フォーマット)
- 圧縮とストレージコスト:ParquetとORCは高い圧縮率を提供する列式ストレージフォーマットであり、列内で多くの繰り返しや似た値があるデータセットに特に効果的です。この高い圧縮はデータサイズを縮小させ、クラウド環境ではGBごとに料金を請求されるストレージにおいてストレージコストを低減させます。
- アナリティックスワークロードに最適:列の性質を利用しており、これらのフォーマットは分析ワークロードに最適であり、列ごとに頻繁にクエリされることは少ないためです。これはストレージからのデータ読み取りを減らし、I/O操作とその関連コストを削減します。
- Avro(行ベースのフォーマット)
- 圧縮と保存コスト:Avroは、データを行ごとに保存するため、ParquetやORCなどの列ベースのフォーマットより低い圧縮率を提供します。これは、多くの列がある大きなデータセットにおいて、一行のすべてのデータを読む必要があり、必要なのはほんの数列だけであってもですので、より高い保存コストを引き起こすことがあります。
- 書き込み重のワークロードにより適しています:Avroは、低い圧縮率により保存コストが高くなるかもしれませんが、データが連続的に書き込まれるか、追記される重いワークロードにはより適しています。保存に関するコストは、データのシリアライズとデシリアライズの効率向上によって補償されることができます。
2. データ処理パフォーマンスとコスト
- パーキットとORC(列式フォーマット)
- 処理コストの削減:これらのフォーマットは、読み取りに優化されており、大規模のデータセットに対するクエリの効率性が高い。クエリに必要な列だけを読み取ることができるため、処理されるデータ量を减少する。これにより、CPUの使用量を低下させ、クエリの実行時間を高速化させ、 computational cost in a cloud environment where compute resources are billed based on usage significantly reduce computational costs.
- コスト最適化のための高度な機能:ORCには、プレディケート・プッシュダウンと組み込まれた統計情報などの機能が含まれていて、クエリエンジンが不要なデータを読み飛ばすことができる。これにより、I/O操作をさらに减少させ、クエリパフォーマンスを高速化させ、コストを最適化する。
- Avro(行ベースのフォーマット)
- 処理コストが高い: Avroは行ベースのフォーマットであり、必要なのは少数の列であっても全行を読むために一般的により多くのI/O操作が必要です。これは、特に読み込み重い環境ではCPU使用率が高く、クエリ実行時間が長くなり、計算コストが高まる原因となります。
- ストリーミングとシリアライズに効率的: クエリの処理コストが高いとはいえ、Avroは書き込み速度の速さとスキーマの進化に関する重要性が高いストリーミングとシリアライズのタスクに適しています。
3. 費用詳細付きのコスト分析
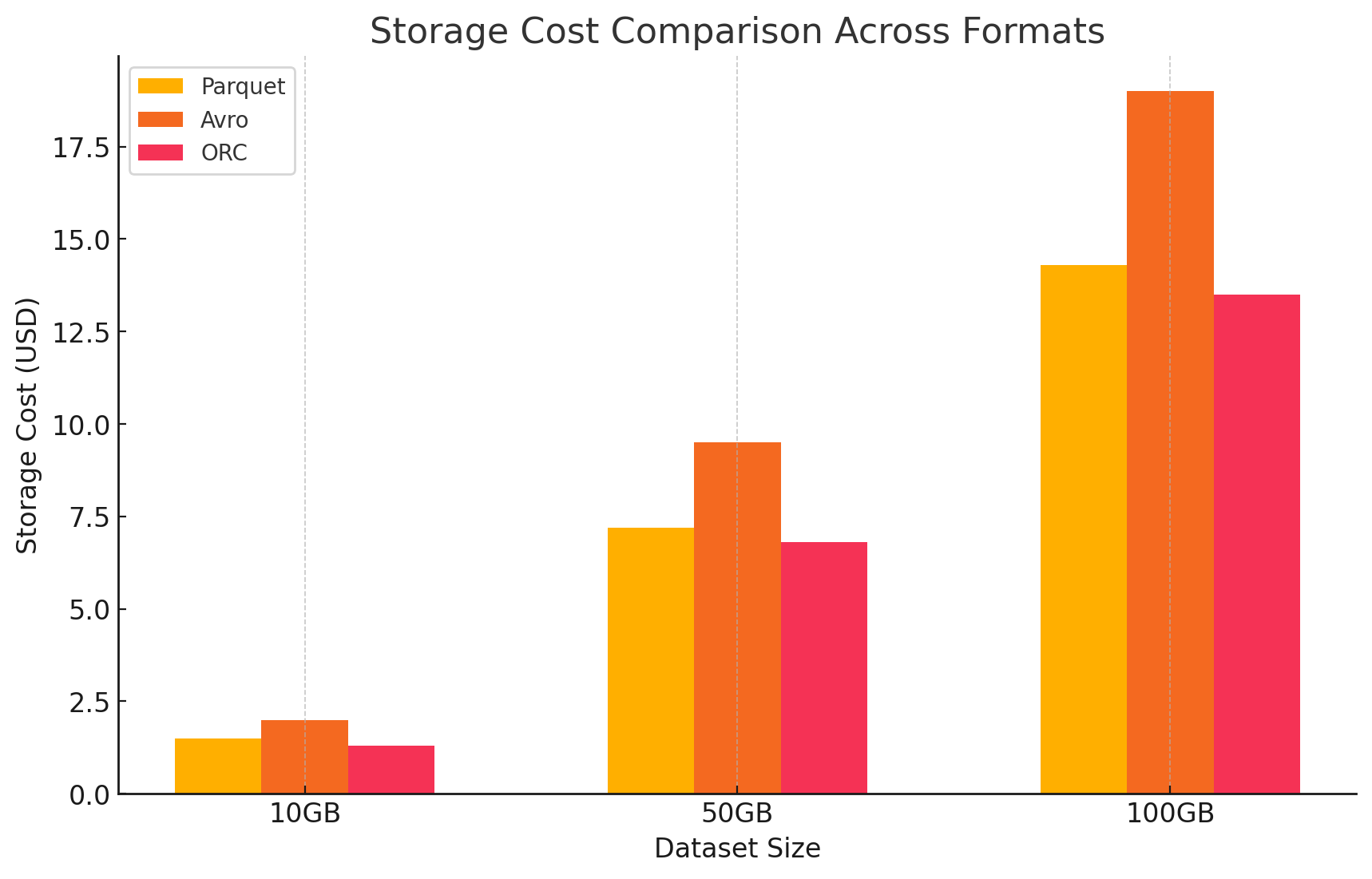
- 各ストレージフォーマットによるコスト影響を量化するために、GCPを使用した実験を行いました。それぞれのフォーマットについて、GCPの価格モデルに基づいてストレージとデータ処理に関連するコストを計算しました。
- Google Cloud ストレージコスト
- ストレージコスト: これは各形式で保存されているデータ量に基づいて計算されます。GCPは、Google Cloud Storageに保存されたデータに対して1GBあたりの月額料金を課します。各形式によって達成される圧縮率は、これらのコストに直接影響を与えます。ParquetやORCのような列形式は、Avroのような行形式よりも通常より良い圧縮率を持つため、より低いストレージコストが得られます。
- 以下はストレージコストが計算される方法のサンプルです:
- Parquet: 高い圧縮率でデータサイズが縮小され、ストレージコストが低減されました
- ORC: Parquetと同様に、ORCの高度な圧縮も効果的にストレージコストを低減しました
- Avro: 低い圧縮効率がParquetとORCに比べて高いストレージコストをもたらしました
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
- データ処理费用
- データ処理费用は、GCP上でDataprocを使用してさまざまなクエリを実行するために必要な計算資源に基づいて計算されました。GCPは、クラスタの大きさとリソースを使用した時間の長さに基づいてDataprocの使用について料金を請求します。
- 計算费用:
- ParquetとORC:効率的な列式ストレージを提供することで、これらの形式はデータの読み取りと処理量を減少させ、計算费用を低減しました。より速いクエリ実行時間は、特に大規模のデータセットによる複雑なクエリにおいて節約のために貢献しました。
- Avro:Avroは、行式の形式であるため、データの読み取りと処理量を増大させるために较多の計算資源が必要でした。読み取りに重的な操作においては、より高いコストになりました。
結論
大規模データ環境でのストレージ形式の選択は、クエリパフォーマンスとコストに多大な影響を与えます。上記の研究と実験では、以下の主要な要点が示されています。
- ParquetとORC:これらの列式格式は優れた圧縮を提供し、ストレージコストを減少させます。必要な列だけを効率よく読み取ることで、クエリパフォーマンスを向上させ、データ処理コストを減少させます。ORCは、高度なインデックスングと最適化機能により、特定のクエリタイプでParquetを上回るパフォーマンスを提供し、高い読み取りと書き込みパフォーマンスが必要なミックスワークロードに最適な選択肢です。
- Avro:AvroはParquetやORCと比べて圧縮とクエリパフォーマンスには劣るが、高速な書き込み操作とスキーマの変更が必要なケースでは優れています。この格式は、書き込みパフォーマンスと柔軟性を重视するデータ序列化とストリーミングのシーンに適しています。
- コスト効率:GCPなどのクラウド環境では、コストはストレージと計算使用に密接に関連しています。適切な格式を選ぶことで大幅なコスト節約が可能です。分析ワークロードは主に読み取り重であるため、ParquetとORCは最もコスト効率の高い選択肢です。アプリケーションは、高速なデータの取り込みと柔軟なスキーマ管理を必要としている場合、Avroを選ぶことが適切であり、その高いストレージと計算コストにもかかわらずです。
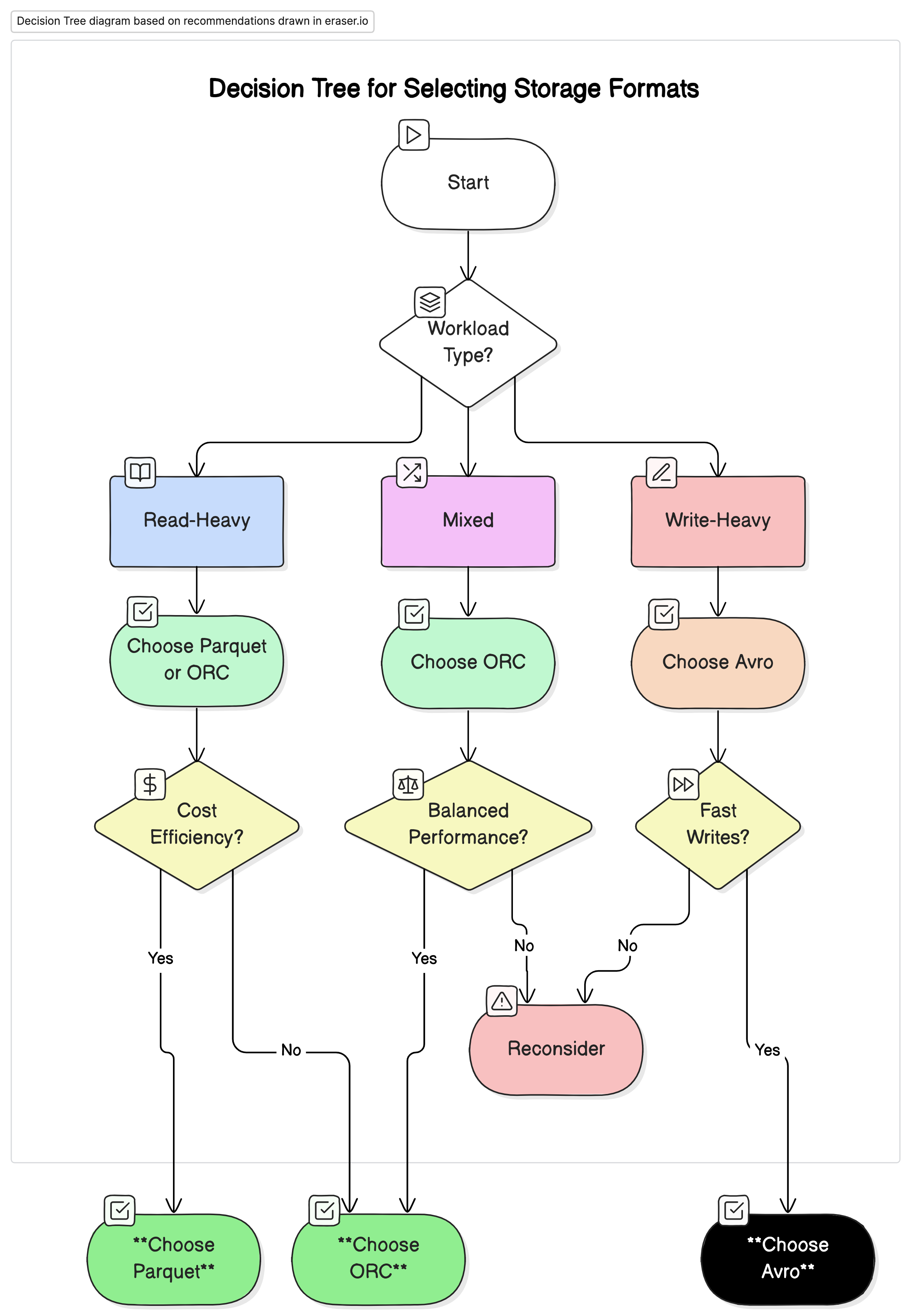
推奨
私たちの分析に基づいて、以下の推奨をする:
- 読み込み重い分析ワークロードには:ParquetまたはORCを使用してください。これらのフォーマットは、高い圧縮率と最適化されたクエリパフォーマンスによって、優れたパフォーマンスとコスト効率を提供します。
- 書き込み重いワークロードやシリアライゼーションには:Avroを使用してください。これは、データストリーミングやメッセージングシステムなど、迅速な書き込みとスキーマの進化が重要なシーンに適しています。
- 読み書き混合のワークロードには:ORCは読み込みと書き込み操作の両方に平衡したパフォーマンスを提供するため、データワークロードが変わる環境に最適な選択です。
最終的な考え方
ビッグデータ環境に最適なストレージフォーマットを選択することは、パフォーマンスとコストの最適化に非常に重要です。各フォーマットの強みと弱点を理解することで、データエンジニアは特定のユースケースに合わせてデータアーキテクチャをカスタマイズすることができ、効率を最大化し、費用を最小化します。データ量が持続的に成長する中で、ストレージフォーマットに関する知識に基づいた決断は、拡張性とコスト効率のあるデータソリューションを維持する上でますます重要になるでしょう。
この記事で示されたパフォーマンスベンチマークとコスト的影响を慎重に評価することによって、組織は自身の運営ニーズと財務目標と最も一致するストレージフォーマットを選べる。
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc