













LLMsは自然言語処理(NLP)を行い、テキストの意味をベクトルとして表現します。このテキストの単語の表現は埋め込みです。
トークンの制限:LLMプロンプティングの最大の問題
現在、LLMプロンプティングの最大の問題の一つはトークンの制限です。GPT-3がリリースされたとき、プロンプトと出力の合計の制限は2,048トークンでした。GPT-3.5では、この制限が4,096トークンに増加しました。現在、GPT-4は2つのバリアントで提供されています。1つは8,192トークンの制限があり、もう1つは32,768トークンの制限があり、約50ページのテキストに相当します。
それで、この制限を超えるようなコンテキストでプロンプトを行いたい場合、どうすればいいのでしょうか?もちろん、唯一の解決策はコンテキストを短くすることです。しかし、どのように短くしながら関連する情報をすべて保持することができるのでしょうか?解決策:コンテキストをベクトルデータベースに保存し、類似性検索クエリで関連するコンテキストを見つける。
ベクトル埋め込みとは何か?
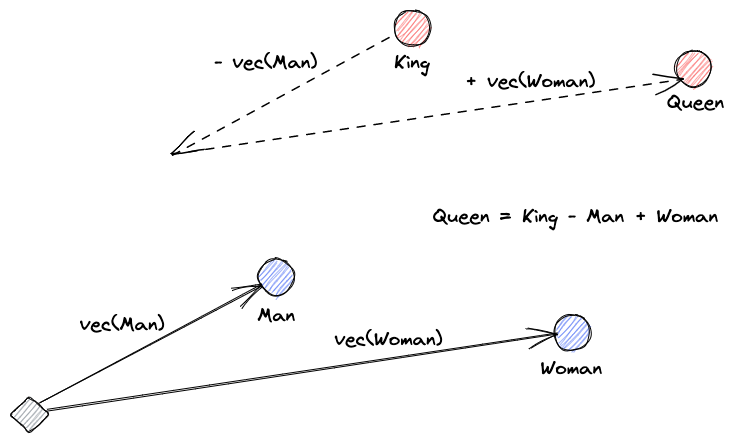
まずはベクトル埋め込みが何かを説明しましょう。ロイ・ケインズの定義は次の通りです:「埋め込みは、データをより有用にするための学習された変換です。」ニューラルネットワークは、テキストを実際の意味を含むベクトル空間に変換することを学習します。これはより有用であるため、同義語や単語間の構文的および意味的な関係を見つけることができます。この図は、それらのベクトルがどのように意味をエンコードできるかを理解するのに役立ちます:
ベクトルデータベースは何をするのか?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
類似性検索
ベクトルの類似性を見つけるために、ベクトルが他のすべてのベクトルからの距離を計算することができます。最も近い隣人は、クエリベクトルに最も類似した結果になります。これがベクトルデータベースのフラットインデックスの動作方法です。しかし、これは非常に効率的ではありません。大規模なデータベースでは、これは非常に長い時間がかかる可能性があります。
検索のパフォーマンスを向上させるために、ベクトルのサブセットだけの距離を計算しようとすることができます。このアプローチは、近似最近傍(ANN)と呼ばれ、速度は向上しますが、結果の品質は犠牲になります。人気のあるANNインデックスには、局所的感度ハッシング(LSH)、階層的可航性小世界(HNSW)、または逆ファイルインデックス(IVF)があります。
ベクトルストアとLLMsの統合
この例では、URLからPDFとしてNumpyのドキュメント全体(2000ページ以上)をダウンロードしました。
Pythonコードを書いて、コンテキストドキュメントを埋め込みに変換し、ベクトルストアに保存できます。ドキュメントを読み込み、チャンクに分割するためにLangChainを使用し、ベクトルデータベースとしてFaiss(Facebook AI Similarity Search)を使用します。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")このデータベースを使用して、プロンプトに関連するページを見つけるための類似性検索クエリを実行できます。次に、結果のチャンクを使用してプロンプトのコンテキストを埋めます。LangChainを使用して簡単に行うことができます。
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)モデルに対する私たちの質問は、「配列の中央値を計算する方法」です。私たちが与えるコンテキストはトークンの制限をはるかに超えていますが、この制限を克服し、答えを得ることができました。
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".これは、非常に新しい問題に対するひとつの巧妙な解決策に過ぎません。LLMが進化し続けることで、この種の巧妙な解決策なしでこのような問題が解決されるかもしれません。しかし、この進化が新たな機能性を引き出し、それらがもたらす課題に対して他の新たな巧妙な解決策を必要とすることは確かです。
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data