













Il progetto SOLAR-10.7B rappresenta un importante balzo in avanti nella sviluppo di grandi modelli di linguaggio, introdurre un nuovo approcio alla scala di questi modelli in un modo efficace e efficiente.
Questo articolo comincia spiegando cos’è il modello SOLAR-10.7B prima di evidenziare le sue prestazioni rispetto ad altri grandi modelli di linguaggio e immergersi nel processo di utilizzo della sua versione fine-tuned specializzata. Alla fine, il lettore comprenderà le applicazioni potenziali del fine-tuned SOLAR-10.7B-Instruct model e i suoi limiti.
Cos’è SOLAR-10.7B?
SOLAR-10.7B è un modello con 10,7 miliardi di parametri sviluppato da un team presso Upstage AI in Corea del Sud.
Basato sull’architettura Llama-2, questo modello supera altri grandi modelli di linguaggio con fino a 30 miliardi di parametri, incluso il modello Mixtral 8X7B.
Per ulteriori informazioni su Llama-2, il nostro articolo Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model fornisce un guida passo-passo per la fine-tuning di Llama-2, utilizzando nuovi approcchi per superare le limitazioni di memoria e calcolo per un migliore accesso ai grandi modelli di linguaggio open-source.
Inoltre, sulla base della solida base di SOLAR-10.7B, il modello SOLAR 10.7B-Instruct è fine-tuned con enfasi sulla risoluzione di istruzioni complesse. Questa variante dimostra prestazioni migliori, mostrando l’adattabilità del modello e l’efficacia del fine-tuning nell’ raggiungimento di obiettivi specializzati.
Finalmente, SOLAR-10.7B introduce un metodo chiamato Depth Up-Scaling, e lo esploreremo ulteriormente nella sezione seguente.
Il metodo Depth Up-Scaling
Questo metodo innovativo consente l’espansione della profondità della rete neurale del modello senza richiedere un corrispondente aumento delle risorse computazionali. Tale strategia migliora sia l’efficienza che le prestazioni complessive del modello.
Elementi essenziali del Depth Up-Scaling
Il Depth Up-Scaling si basa su tre componenti principali: (1) Pesi Mistral 7B, (2) Framework Llama 2 e (3) Pre-addestramento continuo.
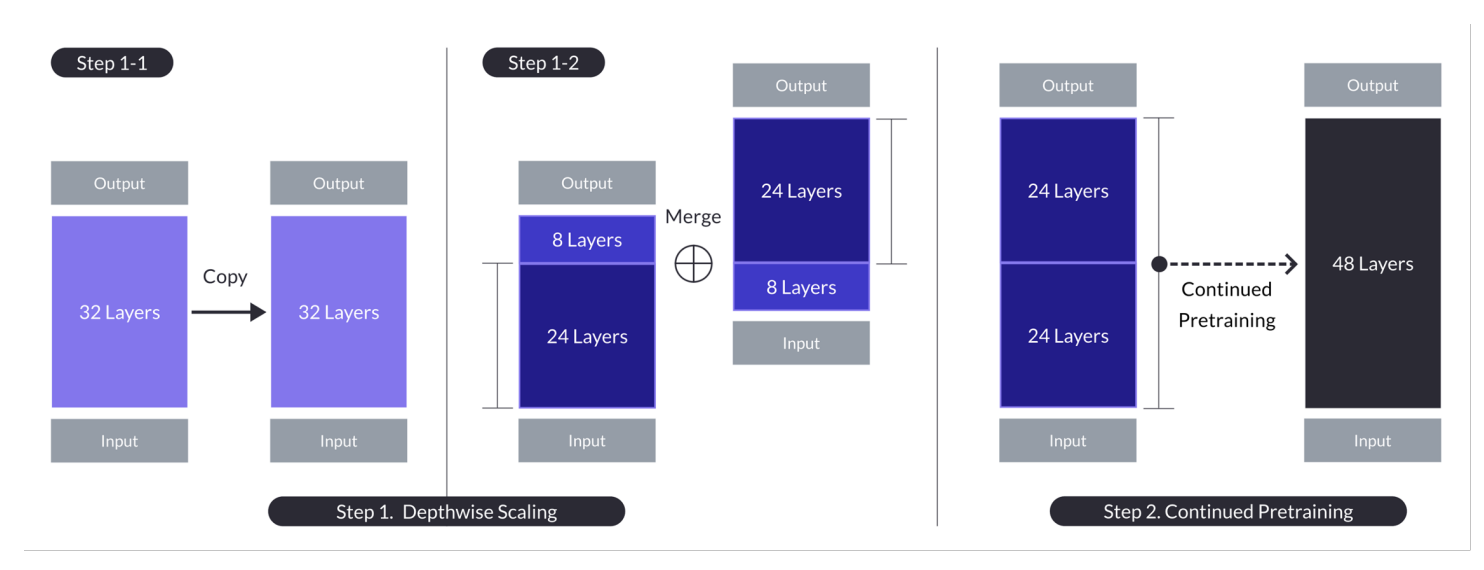
Depth up-scaling per il caso con n = 32, s = 48 e m = 8. Depth up-scaling è ottenuto attraverso un processo a due stadi di scaling in profondità seguito da pre-addestramento continuo. (Fonte)
Modello di base:
- Utilizza un’architettura transformer a 32 strati, specificamente il modello Llama 2, inizializzato con pesi pre-addestrati da Mistral 7B.
- Scelto per la sua compatibilità e prestazioni, con l’obiettivo di sfruttare le risorse della comunità e introdurre modifiche innovative per capacità migliorate.
- Serve come base per lo scaling in profondità e il successivo pre-addestramento per scalare in modo efficiente.
Scaling in profondità:
- Scala il modello base impostando un conteggio di strati target per il modello scalato, considerando le capacità hardware.
- Coinvolge la duplicazione del modello base, la rimozione degli ultimi m strati dall’originale e dei primi m strati dal duplicato, quindi concatenandoli per formare un modello con s strati.
- Questo processo crea un modello scalato con un numero di strati regolato per adattarsi tra 7 e 13 miliardi di parametri, utilizzando specificamente una base di n=32 strati, rimuovendo m=8 strati per raggiungere s=48 strati.
Pretraining Continuato:
- Affronta il calo iniziale delle prestazioni dopo la scalatura in profondità continuando a pre-addestrare il modello scalato.
- È stato osservato un rapido recupero delle prestazioni durante il pre-addestramento continuato, attribuito alla riduzione dell’eterogeneità e delle discrepanze nel modello.
- Il pre-addestramento continuato è cruciale per recuperare e potenzialmente superare le prestazioni del modello base, sfruttando l’architettura del modello scalato in profondità per un apprendimento efficace.
Queste sintesi evidenziano le strategie chiave e i risultati dell’approccio Depth Up-Scaling, concentrandosi sulla valorizzazione dei modelli esistenti, sulla scalatura tramite regolazione della profondità e sul miglioramento delle prestazioni attraverso il pre-addestramento continuato.
Questo approccio multifacetico SOLAR-10.7B raggiunge e, in molti casi, supera le capacità di modelli molto più grandi. Questa efficienza lo rende una scelta primaria per una gamma di applicazioni specifiche, dimostrando la sua forza e flessibilità.
Come Funziona il Modello Istruzione SOLAR 10.7B?
SOLAR-10.7B instruct eccelle nell’interpretare e esecutare istruzioni complesse, rendendolo incredibilmente prezioso in scenari in cui l’apprendimento preciso e la risposta alle comandi umani sono cruciali. Questa capacità è essenziale per lo sviluppo di sistemi AI più intuitivi e interattivi.
- SOLAR 10.7B instruct è il risultato della raffinatura del modello originale SOLAR 10.7B per seguire le istruzioni in formato QA.
- La raffinatura utilizza principalmente dataset open source unitamente a dataset di matematica sintetizzati per migliorare le abilità matematiche del modello.
- La prima versione di SOLAR 10.7B instruct è creata integrando i pesi di Mistral 7B per rafforzare le sue capacità di apprendimento per l’elaborazione informativa efficiente e effective.
- Il cuore di SOLAR 10.7B è l’architettura Llama2, che offre un mix di velocità e accuratezza.
Nell’insieme, l’importanza del modello SOLAR-10.7B raffinato sta nei suoi incrementati risultati, nella sua adattabilità e nel suo potenziale per l’applicazione diffusa, spingendo avanti i campi della processing naturale del linguaggio e dell’intelligenza artificiale.
Applicazioni potenziali del modello SOLAR-10.7B raffinato
Prima di approfondire l’implementazione tecnica, esploriamo alcune delle potenziali applicazioni di un modello SOLAR-10.7B raffinato.
Ecco alcuni esempi di educazione personalizzata e di tutoraggio, di supporto clienti migliorato e di creazione automatica di contenuti.
- Educazione personalizzata e tutoraggio: SOLAR-10.7B-Instruct può rivoluzionare il settore educativo fornendo esperienze di apprendimento personalizzate. È in grado di comprendere domande studenti complessi, offrendo spiegazioni personalizzate, risorse e esercizi. Questa capacità lo rende un strumento ideale per lo sviluppo di sistemi di tutoraggio intelligenti che si adattano agli stili e alle necessità di apprendimento individuali, migliorando l’impegno e i risultati degli studenti.
- Migliore assistenza clienti: SOLAR-10.7B-Instruct può alimentare chatbot e assistenti virtuali avanzati capaci di comprendere e risolvere domande clienti complesse con alta accuratezza. Questa applicazione non solo migliora l’esperienza del cliente fornendo supporto tempestivo e rilevante, ma anche riduce il carico di lavoro dei rappresentanti dell’assistenza clienti umani automatizzando le domande routine.
- Creazione e sintesi automatica di contenuti: Per i creatori di media e contenuti, SOLAR-10.7B-Instruct offre la capacità di automatizzare la generazione di contenuti scritti, come articoli di news, rapporti e scrittura creativa. Inoltre, può riassumere documenti estesi in formati concisi e facili da comprendere, rendendolo prezioso per giornalisti, ricercatori e professionisti che hanno bisogno di assimilare e riportare rapidamente grandi volumi di informazioni.
Questi esempi sottolineano la versatilità e il potenziale di SOLAR-10.7B-Instruct per influenzare e migliorare l’efficienza, l’accessibilità e l’esperienza utente in un vasto spettro di settori.
Guida step-by-step all’utilizzo di SOLAR-10.7B-Instruct
Habbiamo già sufficienti informazioni sul modello SOLAR-10.7B, e ora è il momento di mettere le mani in pasta.
Questa sezione mira a fornire tutte le istruzioni per eseguire il modello SOLAR 10.7 Instruct v1.0 – GGUF da upstage.
I codici sono ispirati alla documentazione ufficiale su Hugging Face. I passaggi principali sono definiti di seguito:
- Installare ed importare le librerie necessarie
- Definire il modello SOLAR-10.7B da utilizzare da Hugging Face
- Eseguire l’infereza del modello
- Generare il risultato sulla base delle richieste utente
Installazione delle librerie
Le principali librerie utilizzate sono transformers e accelerate.
- La libreria transformers fornisce accesso a modelli pre-addestrati, e la versione specificata qui è 4.35.2.
- La libreria accelerate è progettata per semplificare l’esecuzione di modelli di apprendimento automatico su diversi hardware (CPU, GPU) senza dover comprendere a fondo le specificità dell’hardware.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
Importare librerie
Ora che l’installazione è completata, procediamo importando le seguenti librerie necessarie:
- torch è la libreria PyTorch, una popolare libreria open-source di apprendimento automatico utilizzata per applicazioni come computer vision e NLP.
- AutoModelForCausalLM viene utilizzato per caricare un modello pre-addestrato per la modellizzazione linguistica causale, e AutoTokenizer è responsabile della conversione del testo in un formato comprensibile dal modello (tokenizzazione).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
Configurazione GPU
Il modello utilizzato è la versione 1 del modello SOLAR-10.7B di Hugging Face.
Una risorsa GPU è necessaria per accelerare il processo di caricamento e inferenza del modello.
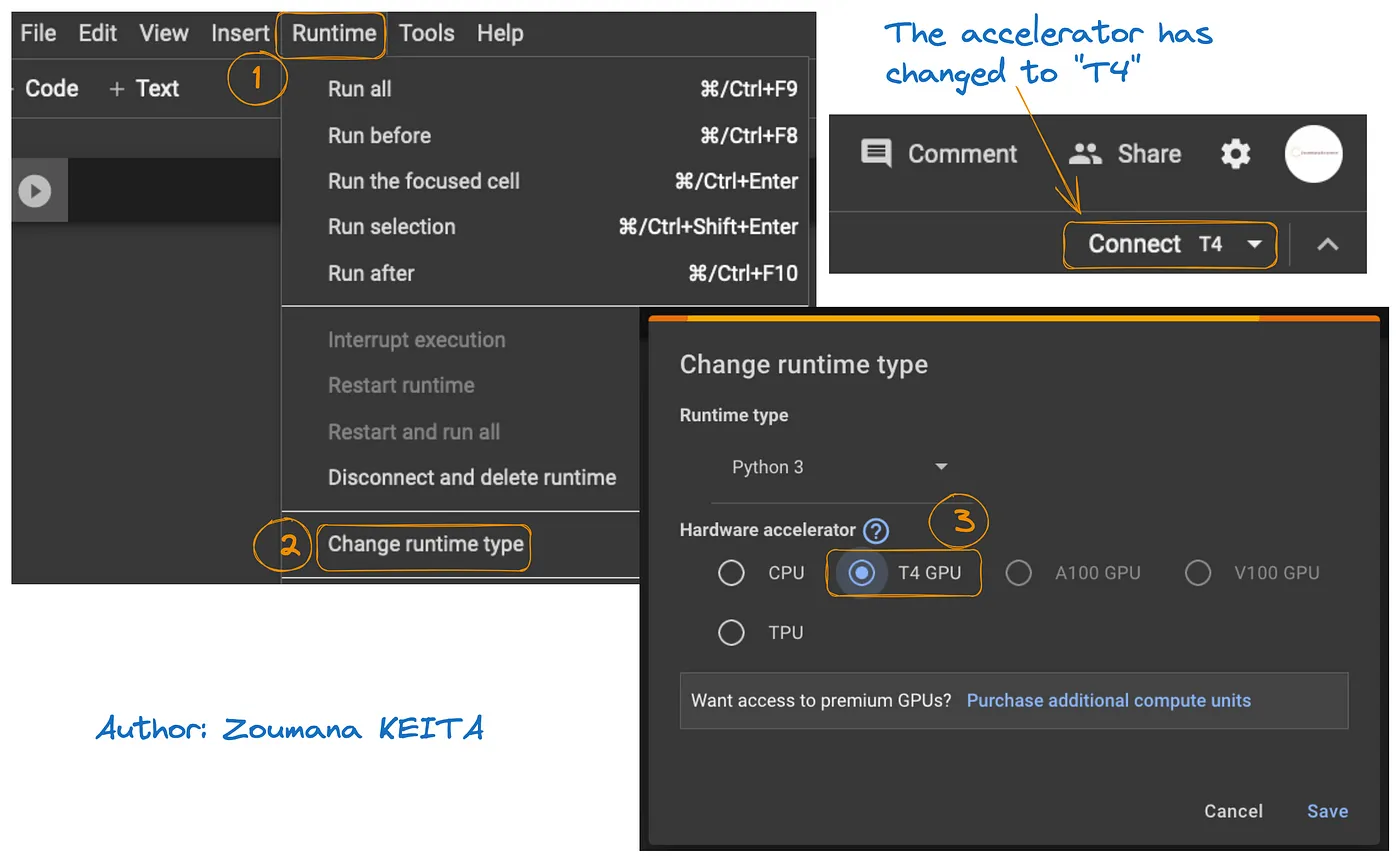
L’accesso alla GPU su Google Colab è illustrato nel grafico seguente:
- Dalla scheda Runtime, seleziona Change runtime
- Quindi, scegli T4 GPU dalla sezione Hardware accelerator e Save le modifiche
Questo cambierà il runtime predefinito in T4:
Possiamo controllare le proprietà del runtime eseguendo il seguente comando dal notebook Colab.
!nvidia-smi
GPU properties
Definizione del modello
Tutto è pronto; possiamo procedere con il caricamento del modello come segue:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID è una stringa che identifica in modo univoco il modello pre-addestrato che vogliamo utilizzare. In questo caso, è specificato “Upstage/SOLAR-10.7B-Instruct-v1.0”.
- AutoTokenizer.from_pretrained(model_ID) carica un tokenizer pre-addestrato sul model_ID specificato, preparandolo per elaborare l’input di testo.
- AutoModelForCausalLM.from_pretrained() carica il modello di linguaggio causale stesso, con device_map=”auto” per utilizzare automaticamente l’hardware migliore disponibile (la GPU che abbiamo configurato), e torch_dtype=torch.float16 per utilizzare numeri in virgola mobile a 16 bit per risparmiare memoria e potenzialmente accelerare i calcoli.
Inferenza del modello
Prima di generare una risposta, il testo di input (richiesta dell’utente) viene formattato e tokenizzato.
- richiesta_utente contiene la domanda o l’input per il modello.
- conversazione imposta l’input come parte di una conversazione, etichettandolo con un ruolo (ad esempio, ‘utente’).
- applica_template_chat applica un template conversazionale all’input, preparandolo per il modello in un formato che questo comprende.
- tokenizer(prompt, return_tensors=”pt”) converte il prompt in token e specifica il tipo di tensore (“pt” per tensori PyTorch), e .to(model.device) garantisce che l’input sia sulla stessa scheda (CPU o GPU) del modello.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
Generazione del risultato
La sezione finale utilizza il modello per generare una risposta alla domanda input e poi decodifica e stampa il testo generato.
- model.generate() genera testo sulla base degli input forniti, con use_cache=True per velocizzare la generazione reutilizzando risultati precedentemente calcolati. max_length=4096 limita la lunghezza massima del testo generato.
- tokenizer.decode(outputs[0]) converte i token generati in testo leggibile da esseri umani.
- print stato visualizza la risposta generata alla domanda dell’utente.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
L’esecuzione corretta del codice sopra genera il seguente risultato:

Sostituendo la richiesta utente con il testo seguente, otteniamo la risposta generata
user_request = "Tell me a story about the universe"

Limitazioni del modello SOLAR-10.7B
Malgrado tutti i benefici della SOLAR-10.7B, questo modello, come ogni altro grande modello di linguaggio, ha le sue limitazioni, e le principali sono indicate qui sotto:
- Esplorazione approfondita degli hyperparametri: la necessità di una più approfondita esplorazione degli hyperparametri del modello durante l’Up-Scaling in Profondità (DUS) è una limitazione chiave. Ciò ha causato la rimozione di 8 layer dal modello di base a causa di limitazioni hardware.
- Demando computazionale elevato: il modello richiede significativamente risorse computazionali, limitando l’uso da parte di individui e organizzazioni con capacità computazionali inferiori.
- Vulnerabilità alla bias: potenziali bias nei dati di addestramento potrebbero influenzare il rendimento del modello per alcuni casi d’uso.
- Preoccupazione ambientale: l’addestramento e l’inferenza del modello richiedono una significativa consumazione energetica, che può sollevare preoccupazioni ambientali.
Conclusione
Questo articolo ha esplorato il modello SOLAR-10.7B, evidenziaendo il suo contributo all’intelligenza artificiale attraverso l’approcio dell’Up-Scaling in Profondità. Ha illustrato le operazioni del modello e le sue potenziali applicazioni, e fornito una guida pratica per il suo uso, dalla installazione alla generazione dei risultati.
Anche se dispone di capacità, l’articolo ha anche affrontato le limitazioni del modello SOLAR-10.7B, garantendo una prospettiva completa per gli utenti. Con l’evoluzione continua dell’AI, SOLAR-10.7B esemplifica i progressi fatti verso strumenti AI più accessibili e versatili.
Il tutorial FLAN-T5: Guida e Raffinamento, offerto da coloro che desiderano approfondire i potenziali dell’IA, fornisce una guida completa al raffinamento di un modello FLAN-T5 per un compito di risposta alle domande utilizzando la libreria transformers e l’esecuzione di inferenza ottimizzata in un scenario reale. Potrete anche trovare il nostro tutorial Raffinamento GPT-3.5 e il nostro codice-along su raffinare il vostro proprio modello LlaMA 2.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial