













I linguaggi di modellazione (LLMs) fanno uso del Natural Language Processing (NLP) per rappresentare il significato del testo come un vettore. Questa rappresentazione delle parole del testo è un’embedding.
Il Limite dei Token: Il Problema Maggiore nel Prompting degli LLM
Attualmente, uno dei maggiori problemi con il prompting degli LLM è il limite dei token. Quando è stato rilasciato GPT-3, il limite per sia il prompt che l’output combinati era di 2.048 token. Con GPT-3.5, questo limite è aumentato a 4.096 token. Ora, GPT-4 viene in due varianti. Una con un limite di 8.192 token e un’altra con un limite di 32.768 token, circa 50 pagine di testo.
Quindi, cosa puoi fare quando potresti voler fare un prompt con un contesto più grande di questo limite? Ovviamente, l’unica soluzione è rendere il contesto più breve. Ma come puoi renderlo più breve e allo stesso tempo avere tutte le informazioni rilevanti? La soluzione: archiviare il contesto in un database di vettori e trovare il contesto rilevante con una query di ricerca per somiglianza.
Cosa Sono gli Embedding Vettoriali?
Cominciamo spiegando cosa sono gli embedding vettoriali. La definizione di Roy Keynes è: “Gli embedding sono trasformazioni apprese per rendere i dati più utili.” Una rete neurale impara a trasformare il testo in uno spazio vettoriale che contiene il suo vero significato. Questo è più utile perché può trovare sinonimi e le relazioni sintattiche e semantiche tra le parole. Questa illustrazione ci aiuta a capire come quei vettori possano codificare il significato:
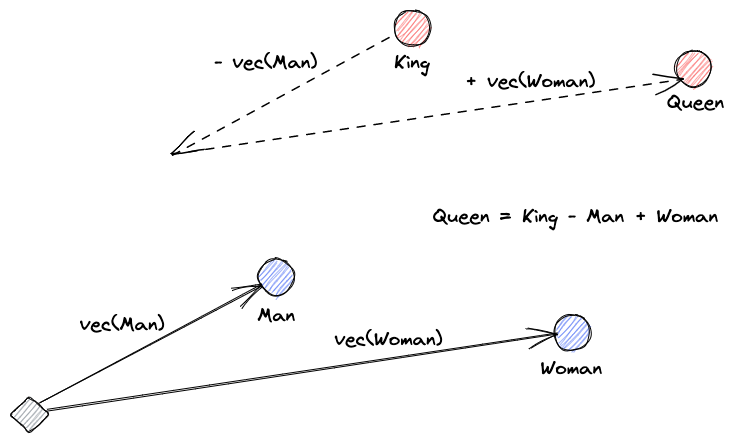
Cosa Fanno i Database di Vettori?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Ricerca per Somiglianza
Possiamo trovare la somiglianza tra vettori calcolando la distanza di un vettore da tutti gli altri vettori. I vicini più vicini saranno i risultati più simili al vettore di query. Questo è il modo in cui funzionano gli indici flat nei database vettoriali. Ma questo non è molto efficiente; in un grande database, potrebbe richiedere molto tempo.
Per migliorare le prestazioni della ricerca, possiamo provare a calcolare la distanza solo per un sottoinsieme dei vettori. Questo approccio, chiamato vicini più vicini approssimativi (ANN), migliora la velocità ma sacrifica la qualità dei risultati. Alcuni indici ANN popolari sono Hashing Sensibile Locale (LSH), Small Worlds Navigabili Gerarchici (HNSW) o Indice File Invertito (IVF).
Integrazione di Archivi Vettoriali e LLMs
Per questo esempio, ho scaricato l’intera documentazione di Numpy (con oltre 2000 pagine) come PDF da questo URL.
Possiamo scrivere codice Python per trasformare il documento di contesto in embedding e salvarli in un archivio vettoriale. Useremo LangChain per caricare il documento e dividerlo in chunk e Faiss (Facebook AI Similarity Search) come database vettoriale.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Ora, possiamo utilizzare questo database per eseguire una query di ricerca per similitudine per trovare pagine che potrebbero essere correlate al nostro prompt. Quindi, usiamo i chunk risultanti per riempire il contesto del nostro prompt. Useremo LangChain per facilitarlo:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)La nostra domanda per il modello è: “Come calcolare la mediana di un array”. Anche se il contesto che gli diamo supera di gran lunga il limite dei token, abbiamo superato questa limitazione e abbiamo ottenuto una risposta:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".Questa è solo una soluzione intelligente per un problema molto nuovo. Mentre i LLM continuano a evolversi, forse problemi come questo saranno risolti senza bisogno di questo tipo di soluzioni intelligenti. Tuttavia, sono certo che questa evoluzione aprirà la porta a nuove capacità che potrebbero richiedere altre nuove soluzioni intelligenti per i challenge che potrebbero presentare.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data