













פיאלובר לשימוש ברפליקת מכונת וירטואלית יכול להיות חלק משיקום במקרי אסון כדי לשחזר נתונים ופעולות עם הפרעה מינימלית לתהליכי עבודה רגילים. תהליך פיאלובר של מכונות וירטואליות צריך להיות מתואר בתוך מערכת ההמשך העסקית ושחזור במקרי אסון (BCDR) של הארגון. בואו נסתכל על סוגי פיאלובר של מכונות וירטואליות ועל מקרי השימוש בפרטיות יותר.
מהו פיאלובר?
פיאלובר הוא התהליך של המשכת הפעלת מכונה וירטואלית (VM) על מערכת משנית (ולעיתים במיקום משני) לאחר כשל של המערכת הראשית. המערכת המשנית מכילה את כל הנתונים הנדרשים לתחזוקת פעילות העסק. מערכת בהקשר זה יכולה להיות שרת, מסד נתונים, מכונה וירטואלית וכו'.
בסביבות וירטואליות, ישנם שני שיטות פיאלובר נפוצות:
- שימוש ברפליקת מכונת וירטואלית (רגילה ממוקמת על שרת וירטואליזציה אחר) משמשת לביצוע פיאלובר במקרה של כשל של מכונה וירטואלית ראשית
- שימוש באשף פיאלובר (אין דרושה שכפול)
Failover מחייב פחות זמן לשחזור עומסי עבודה בהשוואה לשחזור מגיבוי ו, כתוצאה מכך, ניתן להשיג יעד זמן שחזור (RTO) נמוך יותר. מקשה את שיבוץ מכונות וירטואליות או שיבוץ לא מסיר את הצורך ליצור גיבויים של מכונות וירטואליות. גיבוי (רגילים כלל) שימושי כאשר נדרש לשחזר נתונים מנקודת השחזור הישנה.
בואו נעבור על מונחי הכשל במכונות וירטואליות הבסיסיים לשחזור פוגע במרקם.
מילון כשל
- כשל: כל בעיה עם חומרה או תוכנה כתוצאה מתרסקות מערכת, הפסקת חשמל, בעיות רשת, התקפת רנסום, וכו ', שמביאה להורדת מערכת.
- מערכת ראשית: המערכת שפועלת בפעולות חיוניות בסביבת הייצור.
- מערכת משנית: המערכת המשנית והמתנה, שמתעדכנת באופן קבוע עם עותקים של המערכת הראשית. המערכת המשנית יכולה להיות מאוחסנת במקום או במיקום רחוק.
- שיבוץ: התהליך הבסיסי להתכונן לשחזור מכונות וירטואליות. השיבוץ יוצר עותק מדויק, כלומר, רפליקה, של המכונה הראשית לנקודה נתונה בזמן.
- שחזור מכונות וירטואליות: שחזור הוא התהליך של החלפה חזרה למערכת הראשית מהמכונה הרפליקה לאחר שהתרחש האירוע.
סוגי כשל
יש שלושה סוגים של כשל:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- פעולה חילופית בלתי תוכננית היא פעולה חילופית שנערכת כאשר אירעה כשל בלתי צפוי שמוביל לקריטיות של מכונה וירטואלית או לכיבוי האתר הראשי במלואו. הכשל יכול להיגרם על ידי אחת ממספר רב של אסונות טבעיים, תאונות (השבתת החשמל), תקיפת תוכנות זדונית או כל אירוע אחר. במקרה של חילוף לא תוכנן מראש, צריך להכין מראש את השרתים המארחים והשכפולים.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
- ניתן לעמוד בזמני שחזור המשובצים (RTOs) וזמני שחזור הנתונים (RPOs)
- הכל פועל כשורה ויכול לתפקד בצורה חלקה כשזה נדרש
- כל הצוותים המעורבים בשחזור מצב חירום מבינים את התפקידים והאחריות שלהם
סדר החילוף
במהלך חילוף מכונה וירטואלית, סדר הפעולות וסדר ההפעלה של המכונה וירטואלית הם חיוניים להבטיח שחזור מוצלח של זרימות העבודה. עליהם להיות מוגדרים בשלב הפיתוח של תוכנית שחזור מצב חירום של הארגון שלך. סדר הפעולות צריך לכלול את התלות בין שירותים שונים הרצים על מכונות וירטואליות שונות.
לדוגמה, האימות של קצת השירותים והיישומים שרצים על מכונות וירטואליות עשוי להשתמש ב-Active Directory, שרץ על מכונה וירטואלית אחרת. שרת מסד נתונים עשוי לרוץ על המכונה וירטואלית הראשונה, שרתי יישום על השנייה ושרת האינטרנט על השלישית.
ה-VM עם שרת פעיל של Active Directory חייבת להתחיל תחילה. לאחר מכן יכולים להתחיל ה-VMs עם שירותים שמשתמשים ב-Active Directory לאימות. ה-VM עם שרת בסיס הנתונים חייב להתחיל לפני ה-VM עם שרת היישום, משום ששרת היישום מתחבר לבסיס הנתונים. לאחר שה-VMs עם שרת בסיס הנתונים ושרת היישום הופעלו, יכול ה-VM עם שרת האינטרנט להתחיל.הפתרונות העיקריים לשחזור כשירות הינם:
פתרונות גיבוי עיקריים
הפתרונות העיקריים המשמשים בסביבות וירטואליות הם:
- אשף חילופי פעילות
- חילוף עם שימוש בגיבויי VM
בואו נשקול כל אחד מהם
פתרון 1. אשף חילופי פעילות
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
בתרשים הראשון למטה, ניתן לראות אשף שבו שני המארחים (גם נקראים צמתים) פועלים כראוי. ה-VMs רצים על המארחים, וקבצי ה-VM ממוקמים על אחסון משותף שנגיש על ידי שני המארחים.
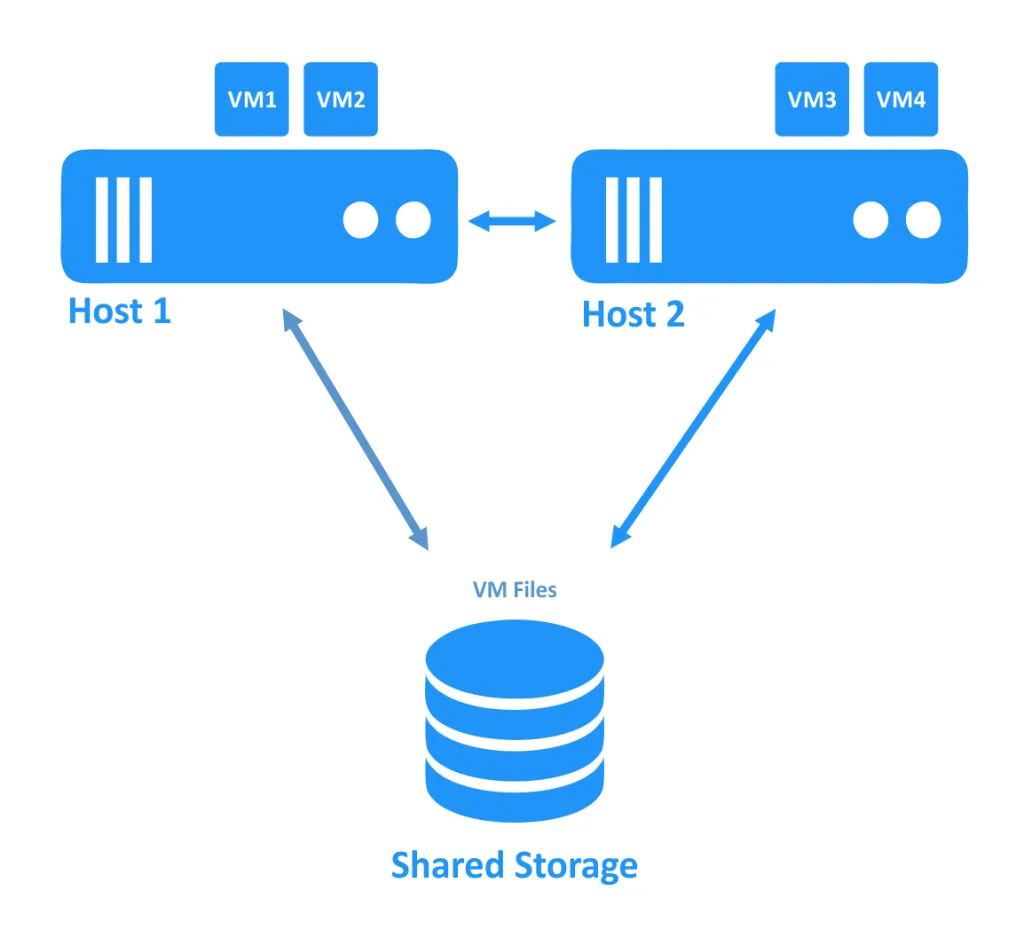
כאשר אחד מהמארחים נופל, הבעלות על חיבור ה-VM (שפעל על הצומת הלא פעילה) מועברת לצומת אחר שעדיין פעיל. זהו תהליך הפישוט. ייתכן ויהיה צורך לאתחל את ה-VM הנמצא בזמינות גבוהה.
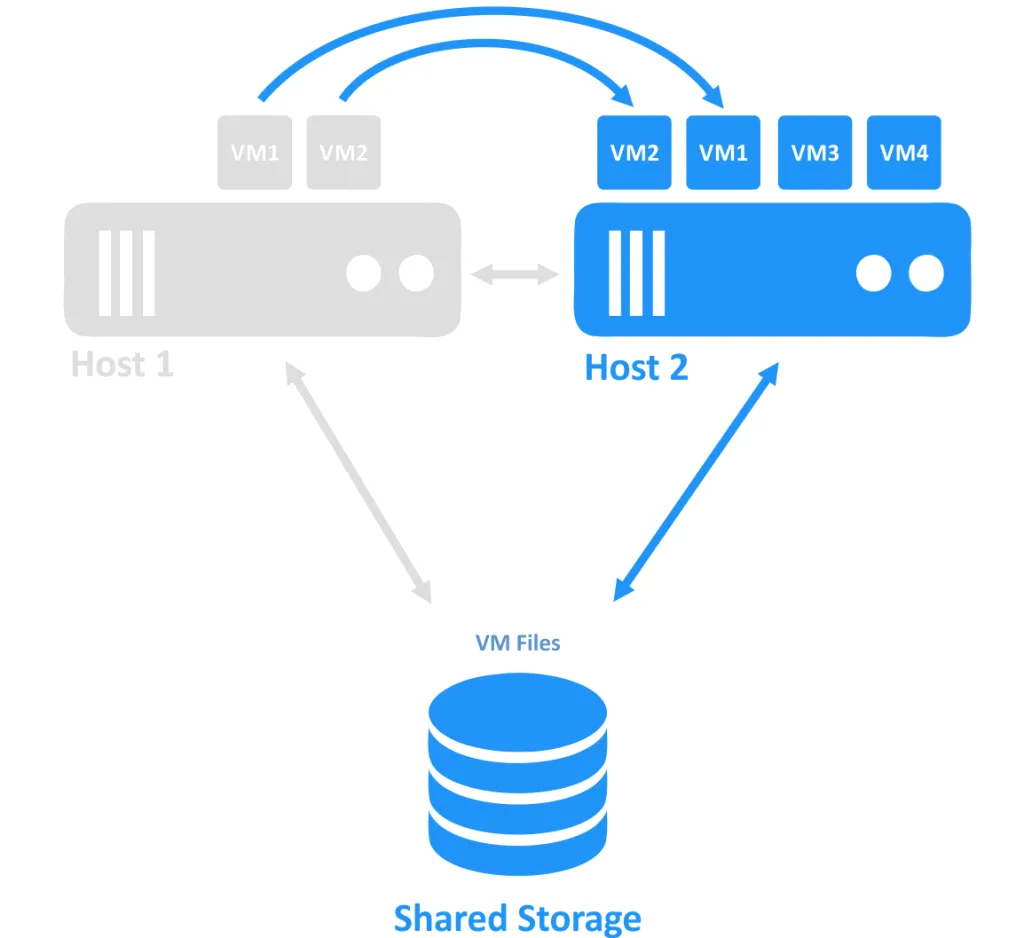
דרישות אשף חילופי פעילות
עליכם לעמוד בדרישות הבאות על מנת לבנות אשף חילופי פעילות:
- אחסון משותף המחובר למארחים באמצעות רשת מיידית מוקצה עם נמוך זמן תגובה. יש להשתמש במערכת קבצים מאוחדת כדי להבטיח כי מארחים מרובים יכולים לגשת באופן סוחף לנתונים הנמצאים באחסון.
- המארחים עליהם רצים ה-VMs חייבים לכלול את אותו חומרה או לפחות חומרה ממשפחת החומרה זהה. המעבדים חייבים לתמוך באותם סטים של הוראות כדי להבטיח תאימות כדי שה-VMs ירוצו כראוי לאחר העברתם ממארח אחד לאחר במהלך פעולת העברת גיבוי.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
מקרי שימוש
אשכולות גיבוי משמשים לשחזור של VMs מכשל שרת, ומספקים זמינות גבוהה ל-VMs הקריטיים. אם אחד מהמארחים (הנקראים גם צמתים) בתוך אשכול נכשל, אז ה-VMs שהיו רצים על המארח שנכשל הם עוברים (גיבוי) למארחים בריאים אחרים. בהתאם להגדרותיך, ה-VMs שעברו גיבוי יכולים להיות מועברים חזרה למארח עליו הם רצו לפני האירוע לאחר שהתקלה נפתרה.
יתרונות
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- בעת גיבוי, אין איבוד נתונים כמעט. הזמן הלא פעיל כללית מוגבל לזמן שנדרש לטעון את ה-VM, מערכת ההפעלה (OS) והתוכנה הרצה על ה-VM.
- התכונה עמידות תקלות הכלולה באשכול הזמינות הגבוהה של VMware מבטיחה גיבוי של VM ללא זמן עצירה וללא איבוד נתונים.
חסרונות
A failover cluster does not protect against:
- כשגרם לתקלות תוכנה של מכונות וירטואליות (VMs), יתכן כי תוכניות באגים או וירוסים יגרמו להתמוטטות במערכת ה-VM.
- מחיקה בשגיאה של קבצים בתוך ה-VM.
- כשיש כשל באחסון משותף. האשכול נכשל כאשר האחסון המשותף נכשל. האחסון המשותף הוא רכיב חיוני באשכול; הדיסקים הווירטואליים ששייכים ל-VMs בתוך אשכול מאוחסנים באחסון משותף.
- A disaster that makes the whole physical site unavailable.
למידע נוסף על מהו אשכול עמידה, קרא את מדריך השלמות על אשכול VMware.
פתרון 2. עמידה באמצעות דומייני VM
עמידת VM המשתמשת בדומיינים VM יכולה להתבצע על ידי יישומים מתמחים, שיכולים לשכפל את ה-VMs ולהפעיל את הדומיינים כאשר נדרש על ידי המנהל. בנוסף לתוכנת הגנת נתונים, יש לך מארחי ESXi או Hyper-V (תלוי בסביבתך) שהוכנו מראש להפעיל את דומייני ה-VM כאשר ה-VMים המקוריים נכשלים.
בתרשים שבהמשך, ניתן לראות שני מארחים המחוברים זה לזה דרך הרשת. ה-VMs משתמשות בדיסקים של המארחים. ה-VMים המקוריים רצוניים על המארח הראשון, והדומיינים של ה-VM, שהם העתקים מדיווחים של ה-VMים בנקודה ספציפית בזמן, ממוקמים על המארח השני במצב מופעל כבוי.
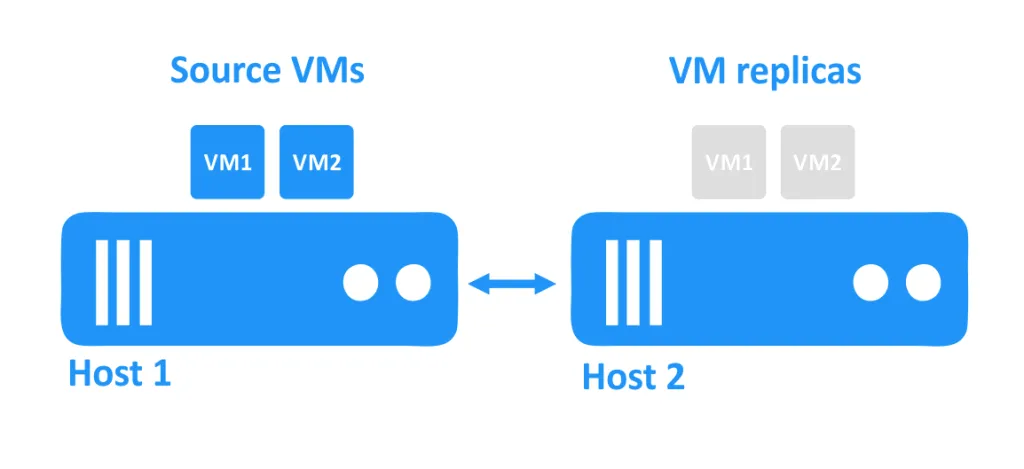
כאשר אחד המארחים נופל, ה-VMים שהיו פועלים על המארח ההוא מפסיקים להיות נגישים. הדומיינים של ה-VMים שנמצאים על מארח אחר מופעלים על ידי המנהל.
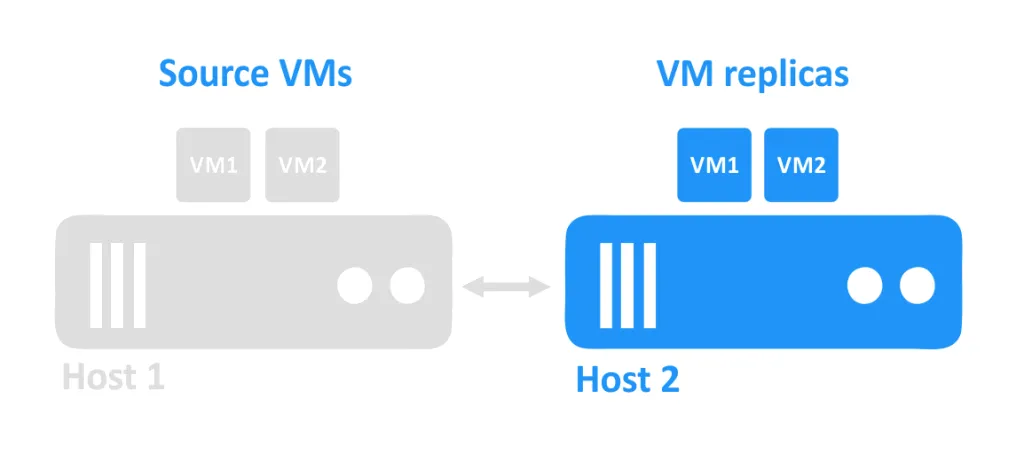
דרישות של פריסת VM
הדרישות הבסיסיות לשיבוץ VM הן שתי או יותר מארחים ופתרון שיבוץ. VM מקור שרץ על המארח הראשון משובץ אל המארח השני. הרפליקה של VM נמצאת על המארח השני.
שימושים
שימוש בשיבוץ של רפליקות VM יכול להתבצע כאשר מתרחשת תקלת חומרה או תוכנה. כשלי מארח ESXi או Hyper-V הם דוגמא לכשלי חומרה. דוגמאות לכשלי תוכנה יכולות להיות עדכונים נכשלים, באגי תוכנה, התקפות וירוסים, או מחיקת קבצים בטעות על ידי משתמש.
יתרונות
היתרון העיקרי של הפעלת גיבוי על רפליקה של VM הוא האפשרות להפעלת גיבוי לאתר רחוק. כאשר נוצרת רפליקה של VM, הנתונים שהועתקו מ-VM מקור יכולים להישלח דרך חיבור רשת (עם רוחב פס מוגבל) אל אתר רחוק. האתר הרחוק יכול להימצא במשרד סמוך או בצד השני של העולם. הרפליקה של VM יכולה גם להימצא באתר הייצור הראשי.
חסרונות
רשימת החסרונות של הפעלת גיבוי באמצעות רפליקות VM:
- ישנה תקופת דחיה קצרה בין כשל להפעלת הרפליקה על המארח השני.
- ההפעלה מחדש חייבת להתבצע באופן ידני.
- הנתונים שנכתבו מאז הרפליקציה האחרונה יכולים להיאבד במהלך ההפעלה הלא תוכניתית. רפליקציית VM נכון לרוב אינה תהליך בזמן אמת (סינכרוני), מאחר שרפליקציה סינכרונית מטילה העמסה משמעותית על המשאבים. הרפליקציה נעשית בדרך כלל במרווחי זמן רגילים תלויים בהגדרות הנבחרות שלך.
- הגדרות הרשת של ה-VMs חייבות (לעיתים קרובות) להשתנות בעת כשל במעבר לאתר אחר. רשתות ה-VMs של האתר המרוחק עשויות להיות שונות מאלו של האתר הראשי. לכן, כתובות ה-IP עשויות גם להיות שונות, וחייבות להיבדק ולהשתנות יחד עם ההגדרות הרשתיות האחרות במהלך המעבר במקרה של כשל.
אשכולות נגד כשל ב-VM בהתאמה לשימוש בשיקולים רפליקציה
| מעבר עם אשכול | מעבר באמצעות רפליקה | |
| מטרה | זמינות גבוהה | שחזור תקלות |
| הגנה נגד | כשלי חומרה בלבד | כשלי חומרה ותוכנה |
| ניהול | מופעל אוטומטית | מופעל ידנית |
| משך השבת (RTO) | המעבר יותר מהיר, כך שהשבת של ה-VM קצרה (RTO קצר) | המעבר לוקח יותר זמן, כך שהשבת של ה-VM ארוכה יותר |
| דרישות | יותר דרישות | פחות דרישות |
| מחיר הפתרון | פתרונות אשכול נהיים כלל יותר יקרים | פתרונות רפליקציה יותר יעילים מבחינת עלויות |
| אובדן נתונים (RPO) | אובדן נתונים קרוב לאפס (RPO נמוך מאוד) | אובדן נתונים תלוי בתדירות הרפליקציה |
שימוש משולב באשכולות ורפליקות לשחזור לאחר כשל תקלה של מכונות וירטואליות
פתרונות לשחזור בעת כשל של קראסטר ורפליקה מsometimes נראים כאלטרנטיבות, אך ניתן להשתמש בהם יחד כדי להשלים אחד את השני. בואו נסתכל על דוגמאות לכיצד השימוש בשני פתרונות לשחזור יכול לעזור להגן על המכונות הווירטואליות שלך נגד כשלי שרת ורמה-אתר.
- דוגמה 1: באפשרותך לשכפל את המכונות הווירטואליות הרצות בתוך קלאסטר אל מארח באתר רחוק. ועוד, אתה יכול לשכפל את המכונות הווירטואליות הרצות בתוך קלאסטר אחד לקלאסטר אחר. כך, אם מארח נכשל, הקלאסטר של השחזור תומך בשמירה על המכונות הווירטואליות האלו במצב מקוון. אם כל האתר חווה הפרעה, אז ניתן לשחזר את הרפליקות של המכונות הווירטואליות השמורות באתר רחוק.
- דוגמה 2: וירוס פוגע בקבצים בתוך כמה מכונות וירטואליות. קלאסטר של שחזור לא יכול להגן על כשלים כאלה. אך אם יש לך רפליקות של מכונות וירטואליות עם מספר נקודות שחזור מרובות, תוכל לשחזר כל מכונה לנקודת זמן לפני שהקבצים שלהן נפגעו או נמחקו.
שימוש בפתרון NAKIVO לשחזור אוטומטי של מכונות ווירטואליות של VMware לרפליקה
NAKIVO Backup & Replication הוא פתרון גיבוי ושחזור מצב חירום שיכול להגן על מכונות וירטואליות הרצות במסגרת אשכול, לשכפל מכונות וירטואליות, להחליף לשכפולים ולמקם רצפיים דורשים DR מורכבים. ניתן לתמוך באשכולות כמו גם במארחים עצמאיים של ESXi או Hyper-V כנקודות מקור ויעד לשכפול. הפתרון מעקב אוטומטי באופן אוטומטי אחר המארח שבו מכונה וירטואלית מתגוררת כך שהוא יכול לשכפל את ה-VM הזה. זה מועיל מכיוון ש-VM יכולות להעביר את המארח ממארח אחד אל אחר בתוך אשכול לאחר אירועי כשלים או אירועי יישוב משקל (תצורת אשכול נהוגה בדרך כלל יחד עם יישוב משקל). על כן, התוכנה שאתה משתמש בה לשכפול של VM מאשכול חייבת להיות מסוגלת לעקוב אחר המארח שבו מתגוררת ה-VM.
פתרון NAKIVO יכול לשנות את הגדרות הרשת של VM באופן אוטומטי לאחר כשל; פשוט השתמש במאפייני מיפוי רשת ו-Re-IP בעת הגדרת עבודת שכפול או כשל.
נשקול דוגמה של כשל VM אוטומטי (עם מיפוי רשת ו-Re-IP) ב-NAKIVO Backup & Replication. נתחיל ביצירת שכפול של VM.
הגדרת שכפול נדרשת לכשל של VM
בלוח בקרת העבודות, לחץ על יצירה > עבודת שכפול VMware vSphere אם יש לך סביבה וירטואלית של VMware. שים לב שאתה יכול ליצור עבודת שכפול עבור VM של Microsoft Hyper-V או מופע Amazon EC2 באותו הדרך.
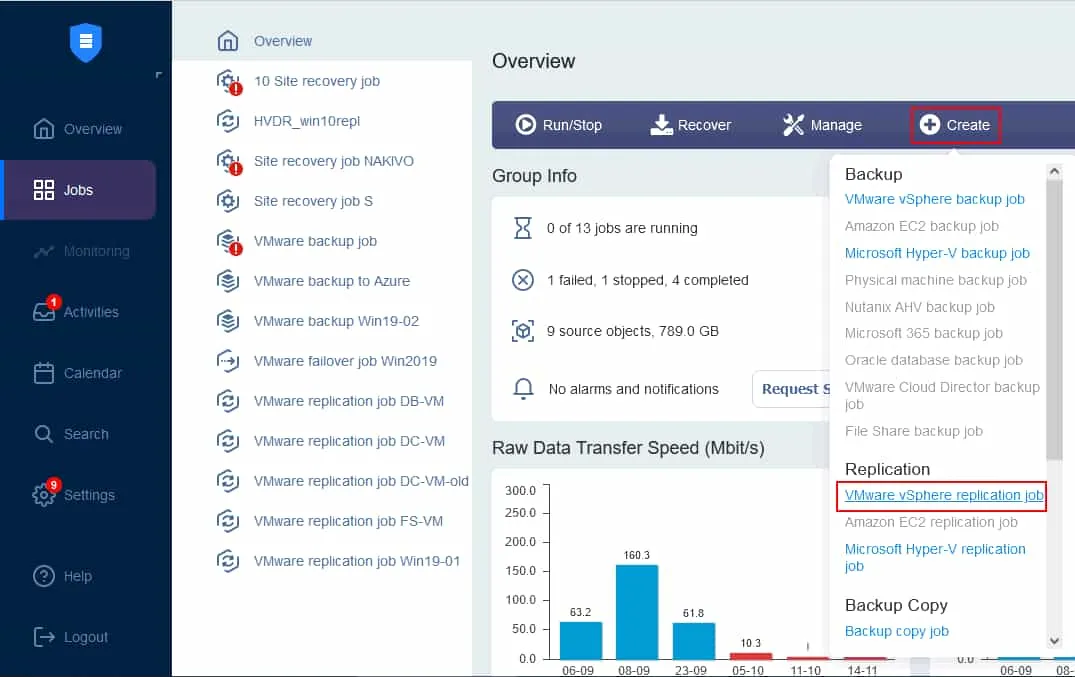
אשף עבודת השכפול מופעל.
- בחר את המכונות הווירטואליות שברצונך לשכפל. בדוגמה זו, מכונת ה-Virtual Machine שבשמה Server2019, הפועלת עם מערכת ההפעלה Windows Server 2019 כאורח, תשוכפל. לחץ הבא.
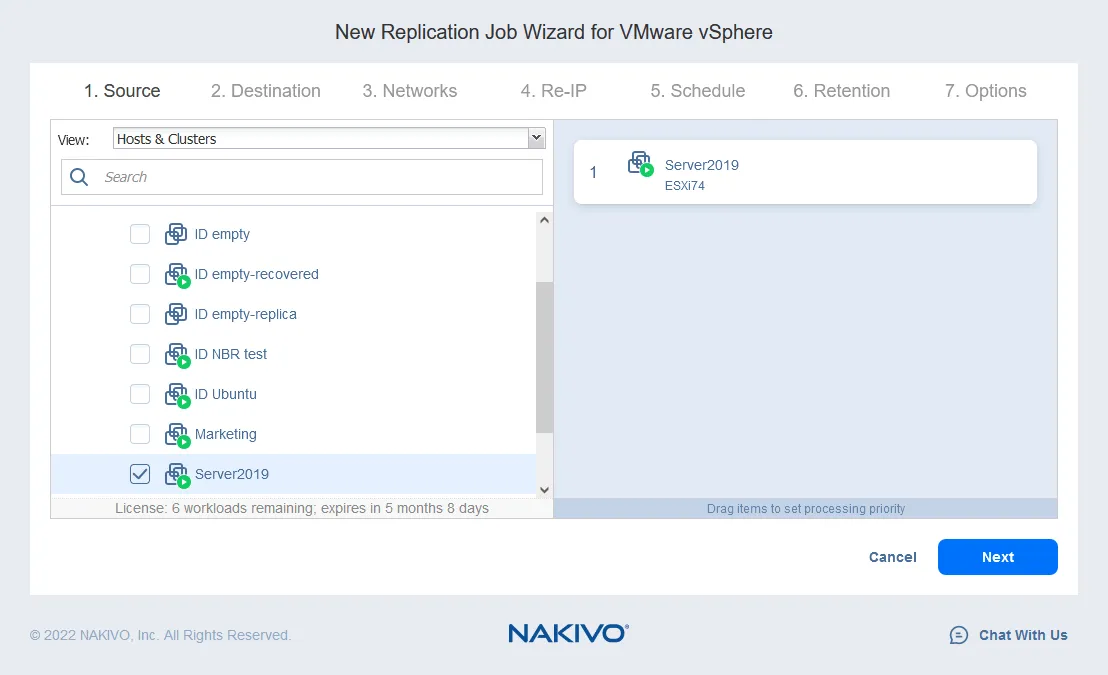
- בחר מארח יעד לריצת מכונת ה-Virtual Machine של השכפול (10.10.10.90 במקרה שלנו). בחר את אחסון הנתונים המחובר למארח הנבחר למקום המיקום של קבצי ה-VM. לחץ הבא.
- אפשר להגדיר מיפוי רשת ואפשרויות Re-IP בעת הגדרת עבודת שכפול או עבודת גיבוי חילופית. במדריך זה, מיפוי רשת ו-Re-IP יתווספו מאוחר יותר בעת הגדרת עבודת גיבוי חילופית. לכן, באפשרותך לדלג על שלב זה זמנית וללחוץ רק על הבא.
- הגדרת ה-IP תוסבר במהלך הגדרת משימת כשל במעבר לווירטואלי במדריך זה. לחץ על הבא.
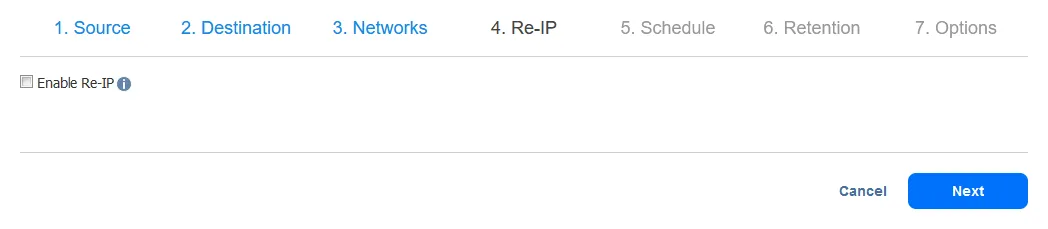
- בחר את הגדרות הזמנים שלך. לחץ על הבא כאשר אתה מוכן.
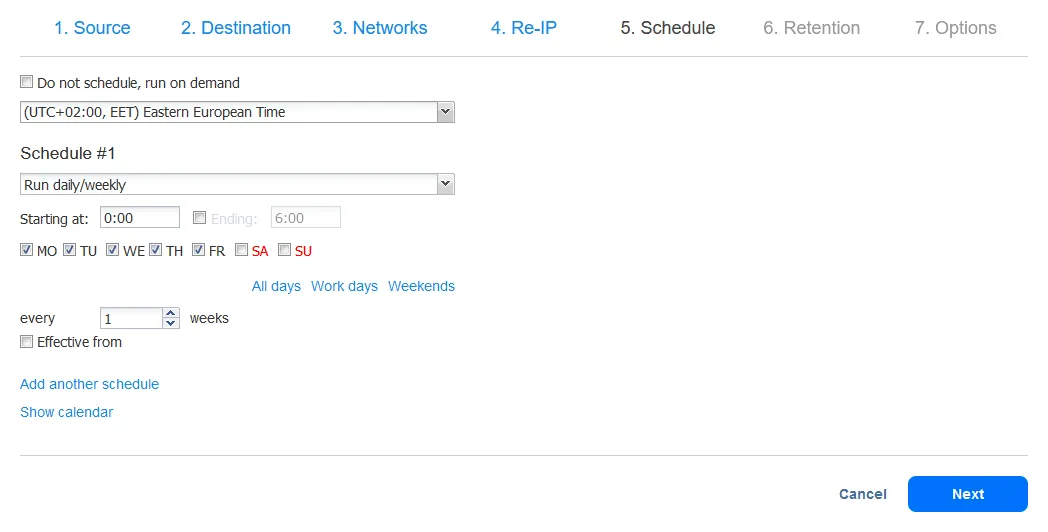
- הגדר את הגדרות השמירה. זכור שאתה יכול להגדיר את מדיניות השמירה דוד-אבא-ילד בשלב זה. לחץ על הבא.
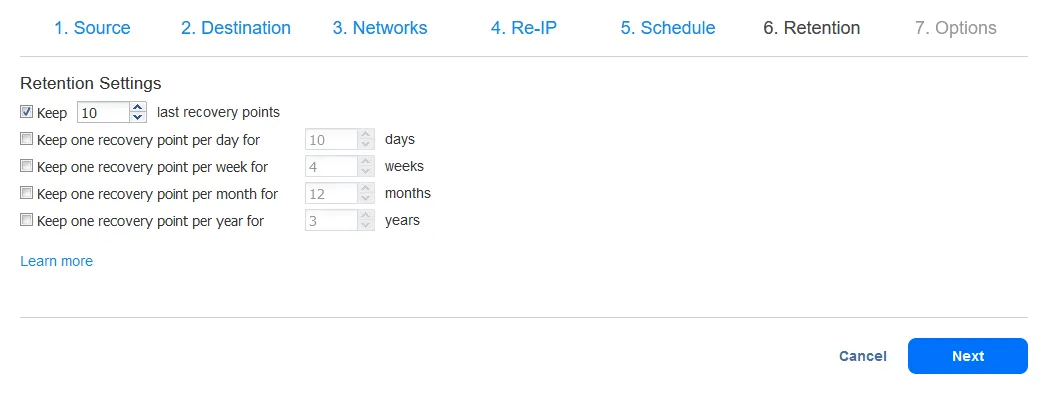
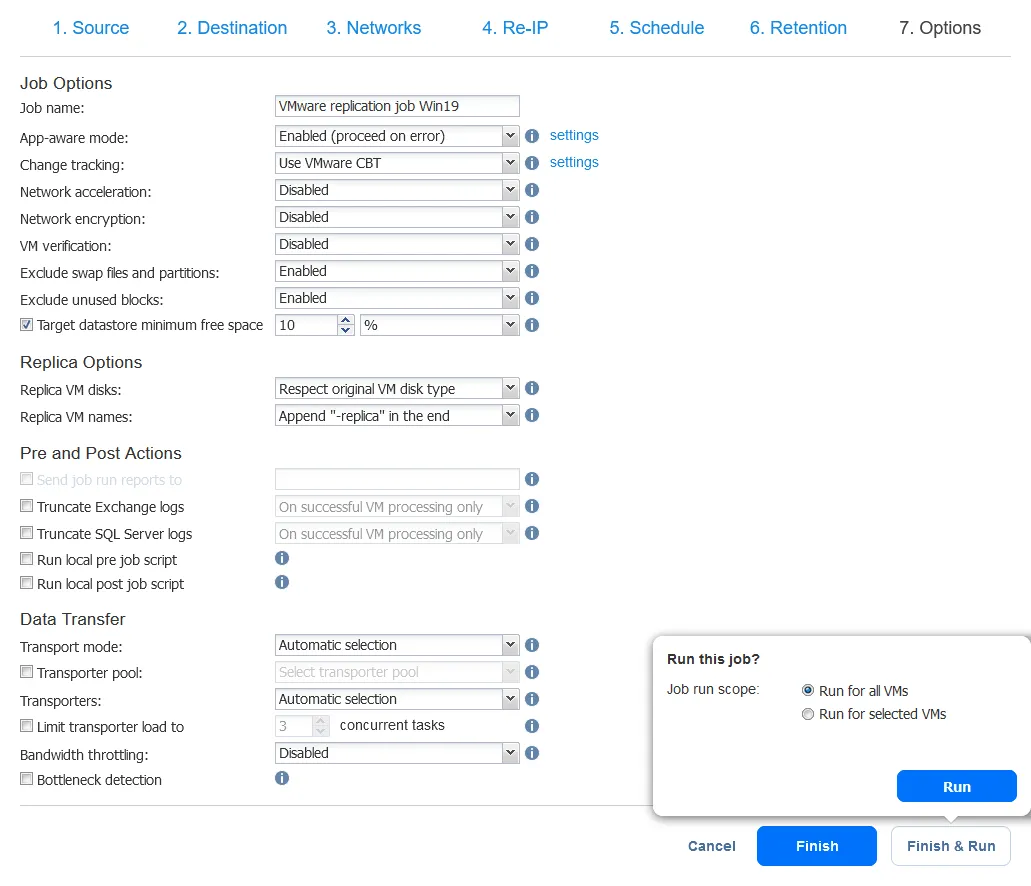
- בחר אפשרויות העבודה לשיבוץ ולחץ על סיום או על כפתור סיום והפעלה. המתן בזמן שהשיבוץ נוצר.
מגדיר חידוש דחיפות VM
עכשיו שיש לך שיבוץ VM שנוצר, תוכל לבצע חידוש דחיפות VM לשיבוץ זה.
בדף הבית בלוח המחוונים, לחץ על שחזור > שחזור מלא של VMware (חידוש דחיפות שיבוץ VM). סוכן אשף השחזור החדש ייפתח.
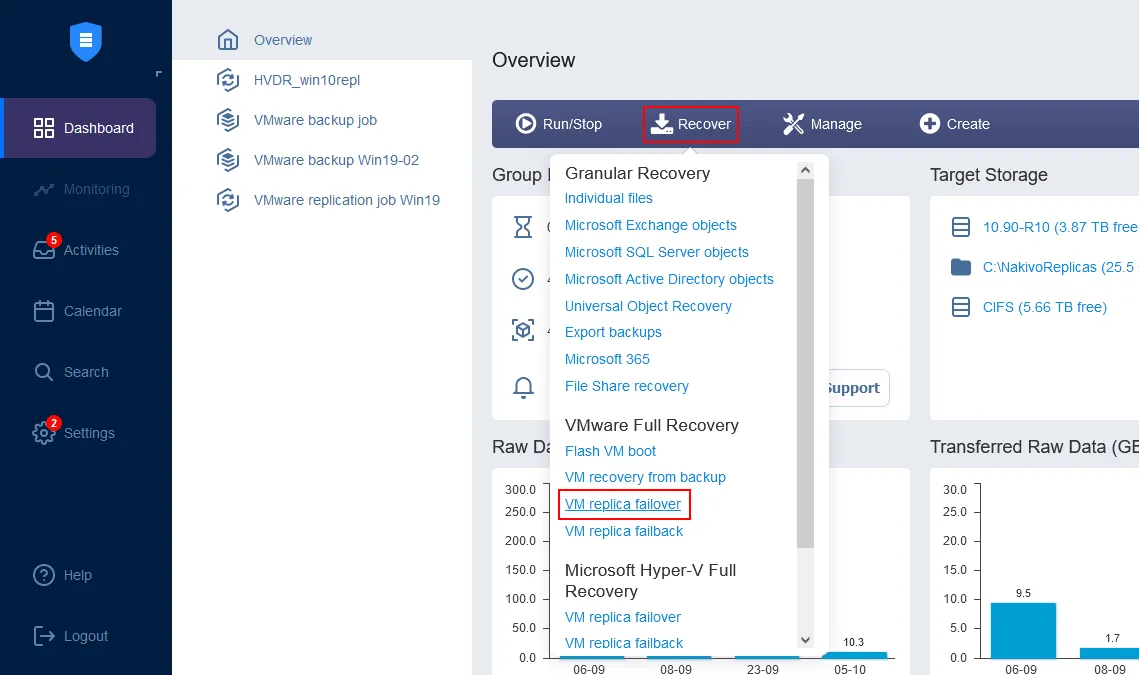
- בחלון השמאלי, בחר את השיבוץ של VM שישמש לחידוש דחיפות. במדריך זה, השיבוץ Server2019-replica, שנוצר לאחרונה, נבחר. בחלון הימני, בחר נקודת שחזור. נקודת השחזור האחרונה נבחרת כברירת מחדל בפתרון. לחץ הבא.
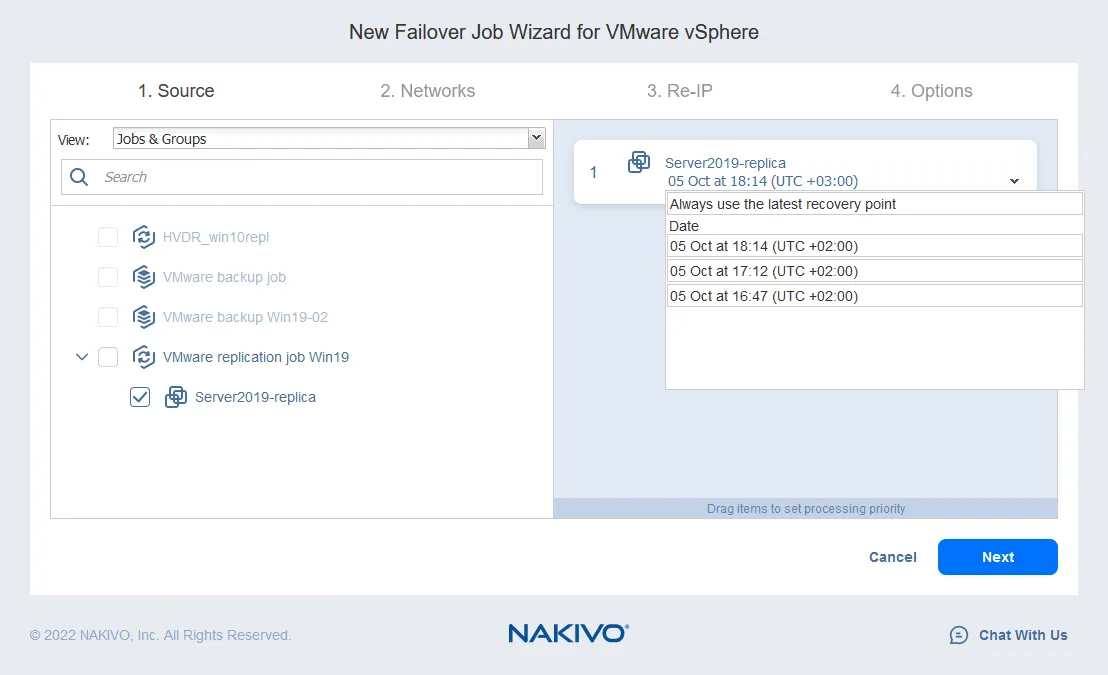
- מיפוי רשת מסייע בשינוי הרשת אליה ה-VM מחוברת. ה-ESXi המקורי והיעד כנראה מגדירים שונות לגבי מתגי הווירטואלי. מאחר שהרפליקה של ה-VM היא העתק מדויק של ה-VM המקורית, הרשתות הווירטואליות אליהן מחוברת ה-VM המקורית מתוודרות ברפליקת ה-VM.
בדרך כלל, כדאי לבדוק את הגדרות הרשת של רפליקת ה-VM ולשנות אותן באופן ידני. NAKIVO Backup & Replication יכול למפות את הרשת המקורית לרשת יעד באופן אוטומטי. אתה רק צריך להגדיר את מיפוי הרשת בעת הגדרת משימת השכפול או השחזור.
- כדי לאפשר מיפוי רשת, סמן את תיבת הסימון. אם יצרת כבר כלל מיפוי רשת, ניתן ללחוץ על הוסף מיפוי קיים. אם לא קיימים כללים למיפוי רשת, לחץ על צור מיפוי חדש.
-
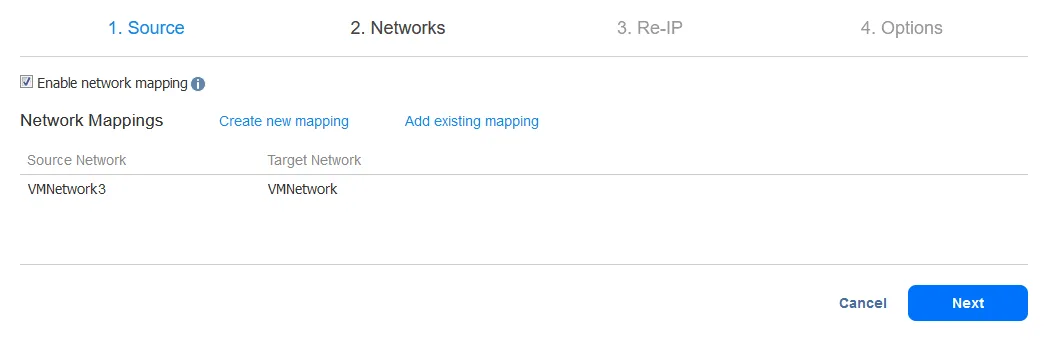
כדי ליצור כלל מיפוי רשת חדש, בחר את הרשת המקורית והרשת היעד. הרשת המקורית היא הרשת אליה ה-VM המקורית מחוברת. הרשת היעד (המטרה) היא הרשת אליה יש להתחבר רפליקת ה-VM.
הערה: שם הרשת של ה-VM אינו תואם לכתובת ה-IP או לכתובת הרשת.
לחץ על שמור כדי לשמור את כלל מיפוי הרשת, ואז לחץ על הבא כדי להמשיך בהגדרה.
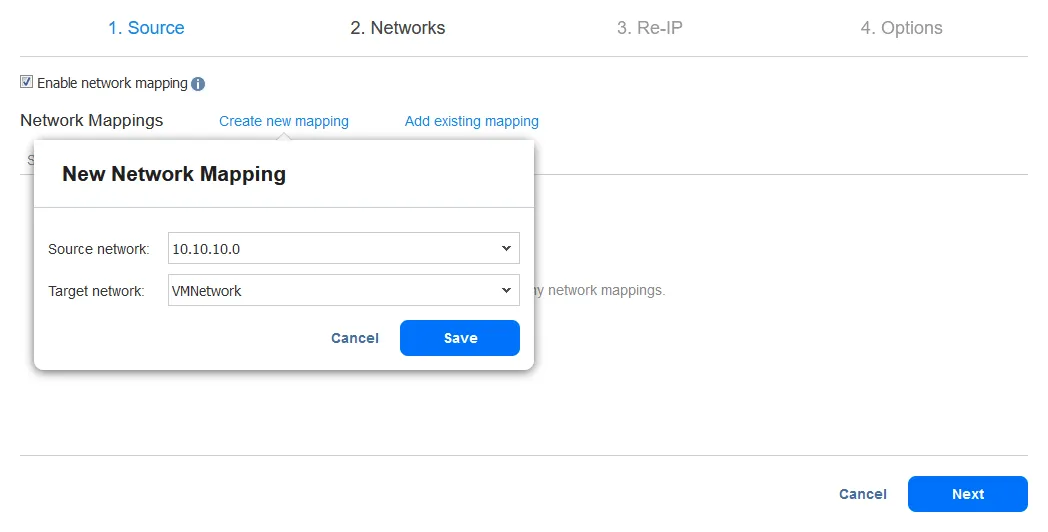
- התכונה של השינוי ב-IP מאפשרת לך לשנות את הגדרות ה-IP של רפליקת ה-VM. ניתן להשתמש בה בכתובות IP סטטיות. בחר בתיבת הסימון של אפשר שינוי ב-IP אם ברצונך לאפשר אפשרות זו ואז צור כלל לשינוי ב-IP או הוסף כלל קיים. לחץ על צור כלל חדש אם לא נוצרו כללים עד כה. תפתח תפריט קופץ.
- כדי לאפשר מיפוי רשת, סמן את תיבת הסימון. אם יצרת כבר כלל מיפוי רשת, ניתן ללחוץ על הוסף מיפוי קיים. אם לא קיימים כללים למיפוי רשת, לחץ על צור מיפוי חדש.
- הגדרות ה-VM המקוריות הם כתובת ה-IP ומסכת הרשת שיש לשנות.
הגדרות היעד הן ההגדרות שיש ליישם עבור רפליקת ה-VM כאשר יתרחש כישלון. בדוגמה זו, התו [*] מכסה את האוקטט האחרון. התו [*] מציין כל מספר בין 1 ל-254. אם כתובות ה-IP המקוריות הן, לדוגמה, 10.10.10.1, 10.10.10.96 ו-10.10.10.222, אז הכתובות היעד ה