













פרוייקט ה-SOLAR-10.7B מייצג קפיצה משמעותית בפיתוח מודלים של שפות גדולים, בעליה חדשה בגישה להגברה של המודלים האלה בדרך יעילה ויעילה.
המאמר מתחיל בהסבר מהו מודל SOLAR-10.7 B, ואחר כך מדגים את הביצועים שלו בהשוואה למודלים שפה גדולים אחרים ומתחיל בתהליך השימוש בגירסה המיוחדת והמאווררת של המודל. לבסוף, הקורא יבין את היישומים המעשיים של הגירסה המאווררת SOLAR-10.7 B-Instruct ומגבלותיו.
מה זה סולאר-10.7B?
סולאר-10.7B הוא מודל עם 10.7 ביליון פרמטרים שפורשה צוות בעלי עסקים ב-Upstage AI בדרום קוריאה.
מבוסס על הארכיטקטורה Llama-2, המודל מעבר על מודלים שפה גדולים אחרים עם עד 30 ביליון פרמטרים, כולל מודל Mixtral 8X7B.
עבור יותר מידע על Llama-2, המאמר שלנו Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model מעביר מדריך בשלבים לטיפול בטירוף Llama-2, בשימוש בגישות חדשות כדי להתגבר על מגבלות הזיכרון והחישובים עבור טווח רחב יותר של גישה למודלים השפה הגדולים הפתוחים.
בניין היסוד החזק של SOLAR-10.7B, מודל SOLAR 10.7B-Instruct מאוורר בהתחמקות על סמך ההוראות המורכבות. הגירסה הזו מראה ביצועים משוכחים, מציגה את ההסתגלנות של המודל ואת היעילות של האווררה בהשג
לסוף הסיפור, SOLAR-10.7B מביא שיטה שנקראת העלה בגודל, ובנוסף נחקור אותה בחלק הבא.
שיטת העלה בגודל
השיטה החדשנית הזו מאפשרת לנו להרחיב את עומק הרשת העצבית של המודל בלי צריך להגביר את המשאבים המתמעטים באופן יחסי. אסטרטגיית זו מתגברת על שיעור היעילות ועל הביצועים הכלליים של המודל.
רכיבים עיקריים של העלה בגודל
העלה בגודל מבוסס על שלושה רכיבים עיקריים: (1) משקלי מיסטרל 7B, (2) פרמביק למה 2, ו (3) התחנון הממוצע.
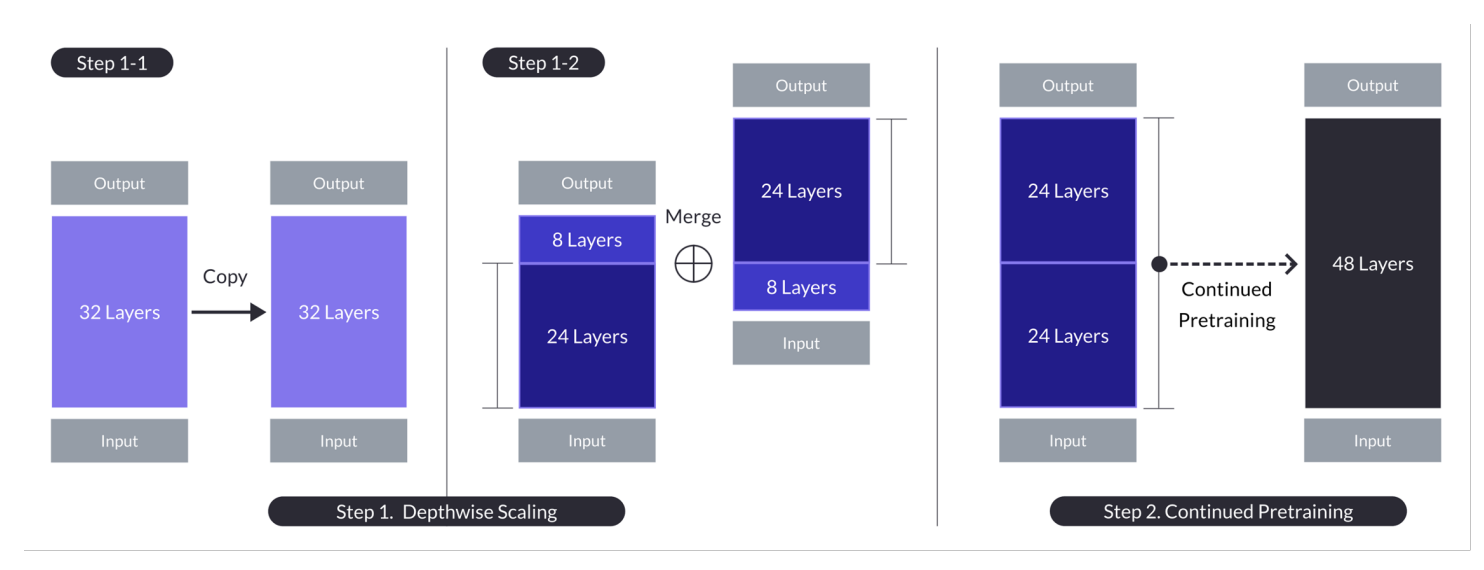
העלה בגודל עבור מקרה בו n = 32, s = 48, ו m = 8. העלה בגודל משיגה דרך תהליך כפול של סקלינג על פי עומק ואחר כך התחנון הממוצע. (מקור)
מודל בסיס:
- משמש ארכיטקטורה של מעבר 32 שכבות, בדיוק את המודל למה 2, שמורשה עם משקלים מוקדמת ממיסטרל 7B.
- נבחר בגלל התאמה וביצועים, כדי לנצל משאבים קהילתיים ולהביא שינויים חדשניים לשיפור יכולתים מעולות.
- משמש כבסיס לסקלינג על פי עומק ולהתחנון הממוצע לעלה באופן יעיל.
סקלינג על פי עומק:
- מוסיף על המודל הבסיסי על ידי הגדרת ספירת השכבות המוטלת בהגדרה עבור המודל המוג
- כולל שכפול של מודל הבסיס, הסרת השכבות האחרונות m מהמקור והשכבות הראשונות m מהשכפול, ואז חיבורן ליצירת מודל עם s שכבות.
- תהליך זה יוצר מודל מותאם בגודל עם מספר שכבות מותאם כך שיתאים בין 7 ל-13 מיליארד פרמטרים, תוך שימוש בבסיס של n=32 שכבות, הסרת m=8 שכבות להשגת s=48 שכבות.
המשך אימון מקדים:
- מטפל בירידה הראשונית בביצועים לאחר ההגדלה בעומק על ידי המשך אימון מקדים למודל המותאם.
- התאוששות מהירה בביצועים נצפתה במהלך האימון המקדים המתמשך, מה שיוחס להפחתת הטרוגניות וסתירות במודל.
- המשך אימון מקדים הוא חיוני לשחזור ולפוטנציאלית אף להתעלות על ביצועי מודל הבסיס, תוך ניצול מבנה המודל המוגדל בעומק ללמידה יעילה.
סיכומים אלו מדגישים את האסטרטגיות המרכזיות והתוצאות של גישת הגדלת העומק, תוך התמקדות בניצול מודלים קיימים, הגדלה דרך התאמת עומק, ושיפור ביצועים דרך אימון מקדים מתמשך.
גישה רב-ממדית זו, SOLAR-10.7B, משיגה ובמקרים רבים אף עולה על יכולות של מודלים גדולים בהרבה. יעילות זו הופכת אותה לבחירה מובילה למגוון יישומים ספציפיים, ומציגה את עוצמתה וגמישותה.
כיצד פועל מודל ההנחיות SOLAR 10.7B?
SOLAR-10.7B הוראה ממושכת בהבנה וביישום הוראות מורכבות, והיא שווה מאוד בסיטואציות בהן חשיבה דיוקנית ומגיבות מהירה להוראות אדם חשובות. היכולת זו היא לבסוף על פי הפיתוח של מערכות AI יותר אינטואיטיביות ומאלתרות.
- SOLAR 10.7B הוראה מתוצאת העדכון המדורי של SOLAR 10.7B המודל בכדי לעבוד על הוראות בפורמט QA.
- העדכון העיקרי משתמש במידע פתוח בין המקורות המקוריים למאגרי המתכונות המתכוננות לעיבוד העיתונים המתמטיים כדי לשכל את היכולת המתמטית הנדסה של המודל.
- הגרסה הראשונית של SOLAR 10.7B הוא יוצר על ידי השלמת המשקלים של Mistral 7B כדי לחזק את היכולת הלמידית שלו עבור עיבוד מידע יעיל ואיכותי.
- הבסיס של SOLAR 10.7B הוא הארכיטקטורה Llama2, הסיפקת קלט של מהירות ודיוק.
במצב כללי, העדכון המושלם של SOLAR-10.7B יותר חשוב מהביצועים המורגלים, ההסתגלות והפוטנציאל לשימוש רחב, שמובילים את התחומים של עיבוד השפה הטבעית והמערכות הממשכתות.
יישומות פוטנציאליים של העדכון המושלם של SOLAR-10.7B
לפני שינוי ליישום הטכני, בואו נחשוב על כמה מהיישומות הפוטנציאליים של העדכון המושלם של SOLAR-10.7B.
הם כאן בתחום החינוך האישי וההורא
- חינוך והדרכה מותאמים אישית: SOLAR-10.7B-Instruct יכול לחולל מהפכה בתחום החינוך באמצעות מתן חוויות למידה מותאמות אישית. הוא יכול להבין שאילתות מורכבות של תלמידים, להציע הסברים מותאמים אישית, משאבים ותרגילים. יכולת זו הופכת אותו לכלי אידיאלי לפיתוח מערכות הדרכה חכמות המותאמות לסגנונות ולצרכי הלמידה האישיים, ומשפרות את מעורבות והישגי התלמידים.
- תמיכה בלקוחות משופרת: SOLAR-10.7B-Instruct יכול להפעיל צ'אטבוטים מתקדמים ועוזרים וירטואליים המסוגלים להבין ולפתור שאילתות לקוחות מורכבות בדיוק גבוה. יישום זה לא רק משפר את חוויית הלקוח על ידי מתן תמיכה בזמן ובעלת רלוונטיות, אלא גם מפחית את העומס על נציגי שירות הלקוחות האנושיים על ידי אוטומציה של שאילתות שגרתיות.
- יצירת תוכן אוטומטית וסיכום: עבור יוצרי מדיה ותוכן, SOLAR-10.7B-Instruct מציע את היכולת לאוטומציה של יצירת תוכן כתוב, כגון מאמרי חדשות, דוחות וכתיבה יצירתית. בנוסף, הוא יכול לסכם מסמכים נרחבים לפורמטים תמציתיים וקלים להבנה, מה שהופך אותו לבלתי יסולא בפז עבור עיתונאים, חוקרים ואנשי מקצוע הזקוקים ליכולת להטמיע ולדווח על כמויות גדולות של מידע במהירות.
דוגמאות אלו מדגישות את הגמישות והפוטנציאל של SOLAR-10.7B-Instruct להשפיע ולשפר את היעילות, הנגישות וחוויית המשתמש במגוון רחב של תעשיות.
מדריך שלב אחר שלב לשימוש ב-SOLAR-10.7B Instruct
יש לנו מספיק רקע על מודל SOLAR-10.7B, ועכשיו הגיע הזמן להתחיל לעבוד.
סעיף זה מטרה לספק את כל ההוראות להרצה של מודל SOLAR 10.7 Instruct v1.0 – GGUF מאפסטייג'
הקודים מושפעים מהתיעוד הרשמי על Hugging Face. השלבים המרכזיים מוגדרים בהמשך:
- התקנה וייבוא של הספריות הנחוצות
- הגדרת מודל SOLAR-10.7B לשימוש מ-Hugging Face
- הרצת השערות של המודל
- ייצור התוצאה מבקשת המשתמש
התקנת הספריות
הספריות המרכזיות המשמשות הן transformers ו-accelerate.
- הספרייה transformers מספקת גישה למודלים מוכנסים מראש, והגירסה שמוצהרת כאן היא 4.35.2.
- הספרייה accelerate מעוצבת לפשט את ריצת מודלי למידה מכנית על חומרה שונה (מעבדים, גרפיקה) מבלי להבין מעמדית במיוחד את התכונות של החומרה.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
ייבוא ספריות
עכשיו, ברגע שההתקנה הושלמה, אנחנו ממשיכים עם ייבוא הספריות הנחוצות הבאות:
- torch הוא הספרייה של PyTorch, ספריית למידה מכנית פתוחה ופופולרית שנמצאת בשימוש ביישומים כמו ראייה מחשבית ו-NLP.
- AutoModelForCausalLM משמש לטעינת מודל מוכנס לגיאום לשפה ספורטיבי, ו-AutoTokenizer אחראי להמרת טקסט לפורמט שהמודל יכול להבין (טוקניזציה).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
תצורת GPU
המודל בשימוש הוא גרסה 1 של מודל SOLAR-10.7B מ-Hugging Face.
נדרש משאב GPU להאצת תהליך הטעינה וההסקה של המודל.
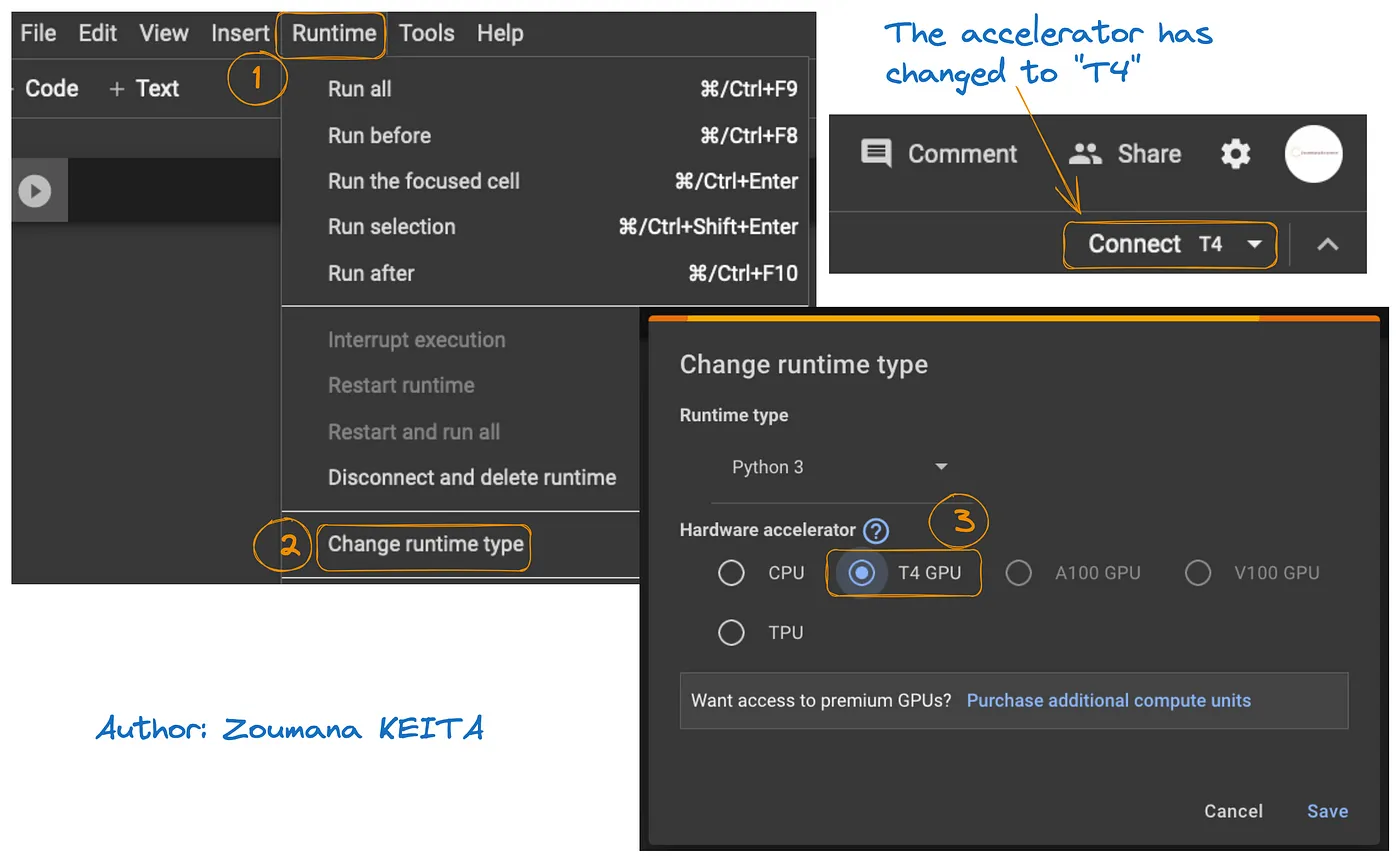
הגישה ל-GPU ב-Google Colab מודגמת בתרשים הבא:
- מכרטיסיית Runtime, בחר ב-Change runtime
- לאחר מכן, בחר ב-T4 GPU מקטע חומרת המאיץ ו-Save את השינויים
זה יחליף את זמן הריצה המוגדר כברירת מחדל ל-T4:
ניתן לבדוק את המאפיינים של זמן הריצה על ידי הפעלת הפקודה הבאה מ-מחברת Colab.
!nvidia-smi
מאפייני GPU
הגדרת המודל
הכל מוכן; אנחנו יכולים להמשיך עם הטעינה של המודל כפי שמפורט להלן:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID הוא מחרוזת המזהה באופן ייחודי את המודל המאומן מראש שאנחנו רוצים להשתמש בו. במקרה הזה, "Upstage/SOLAR-10.7B-Instruct-v1.0" מצוין.
- AutoTokenizer.from_pretrained(model_ID) טוען מאמן-מילים מאומן מראש על ה-model_ID המצוין, ומכין אותו לעיבוד טקסט קלט.
- AutoModelForCausalLM.from_pretrained() טוען את מודל שפת הסיבתיות עצמו, עם device_map="auto" לשימוש אוטומטי בחומרה הזמינה הטובה ביותר (ה-GPU שהגדרנו), ו-torch_dtype=torch.float16 לשימוש במספרים צפים בעלי 16 ביט לשמירת זיכרון ולהאצת החישובים.
הסקת המודל
לפני יצירת תגובה, טקסט הקלט (הבקשה של המשתמש) מעוצב ומאומן.
- user_request מכיל את השאלה או הקלט עבור המודל.
- conversation מעצב את הקלט כחלק משיחה, מתייג אותו עם תפקיד (למשל, 'user').
- apply_chat_template מיישם תבנית שיחה על הקלט, מכין אותו עבור המודל בפורמט שהוא מבין.
- tokenizer(prompt, return_tensors="pt") ממיר את הפקודה לטוקנים ומציין את סוג הטנסור ("pt" עבור טנסורים של PyTorch), ו-.to(model.device) מבטיח שהקלט נמצא על אותו מכשיר (CPU או GPU) כמו המודל.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
יצירת תוצאה
הקטע הסופי משתמש במודל ליצירת תגובה לשאלה הקלט ולאחר מכן מפענח ומדפיס את הטקסט שנוצר.
- model.generate() יוצר טקסט על בסיס הקלטים המסופקים, עם use_cache=True להאצת היצירה על ידי שימוש חוזר בתוצאות מחושבות קודמות. max_length=4096 מגביל את האורך המקסימלי של הטקסט הנוצר.
- tokenizer.decode(outputs[0]) ממיר את הטוקנים שנוצרו חזרה לטקסט קריא.
- print הצהרה מציגה את התשובה שנוצרה לשאלת המשתמש.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
הביצוע המוצלח של הקוד לעיל יוצר את התוצאה הבאה:

על ידי החלפת בקשת המשתמש עם הטקסט הבא, אנו מקבלים את התגובה שנוצרה
user_request = "Tell me a story about the universe"

מגבלות של מודל SOLAR-10.7B
למרות כל היתרונות של SOLAR-10.7B, יש לו מגבלות כמו לכל מודל שפה גדול אחר, והעיקריות שבהן מודגשות להלן:
- חקירת היפרפרמטרים מעמיקה: הצורך בחקירה מעמיקה יותר של ההיפרפרמטרים של המודל במהלך הגדלת העומק (DUS) הוא מגבלה מרכזית. זה גרם להסרת 8 שכבות מהמודל הבסיסי בשל מגבלות חומרה.
- דרישות חישוביות גבוהות: המודל דורש משאבי חישוב משמעותיים, וזה מגביל את השימוש בו על ידי יחידים וארגונים עם יכולות חישוב נמוכות יותר.
- פגיעות להטיה: הטיה פוטנציאלית בנתוני האימון עלולה להשפיע על ביצועי המודל לשימושים מסוימים.
- חשש סביבתי: האימון וההרצה של המודל דורשים צריכת אנרגיה משמעותית, וזה יכול לעורר חששות סביבתיים.
סיכום
מאמר זה חקר את מודל SOLAR-10.7B, תוך הדגשת תרומתו לבינה מלאכותית באמצעות גישת הגדלת העומק. הוא תיאר את פעולת המודל ואת היישומים הפוטנציאליים שלו, וסיפק מדריך מעשי לשימוש בו, מהתקנה ועד ליצירת תוצאות.
למרות יכולותיו, המאמר גם התייחס למגבלות של מודל SOLAR-10.7B, תוך הבטחת פרספקטיבה מאוזנת למשתמשים. ככל שהבינה המלאכותית ממשיכה להתפתח, SOLAR-10.7B מהווה דוגמה לצעדים שנעשו לקראת כלים נגישים ומגוונים יותר בבינה מלאכותית.
עבורם שמחפשים להיכנס יותר לעומק הפוטנציאל של המערכת החישובית החדשנית הזו, ההדרכה שלנו הוריד את ההדרכה לFLAN-T5: מדריך ואימוץ מתוכננים מעניקה מדריך מלא לאימוץ מודל FLAN-T5 למשימה של תשובות לשאלות בעזרת ספריית השינויים ולביצוע השערה מותאמת למצבים מעשיים בעזרת אינפרציה מותאמת. ניתן גם למצוא את ההדרכה שלנו לאימוץ GPT-3.5 ואת ההדרכה המקודמת על אימוץ מודל משלך של LlaMA 2.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial