













עיבוד נתונים יעיל הוא קריטי עבור עסקים וארגונים שנשענים על ניתוח נתוני עתק כדי לקבל החלטות מושכלות. גורם מרכזי המשפיע באופן משמעותי על הביצועים של עיבוד הנתונים הוא פורמט האחסון של הנתונים. מאמר זה בוחן את ההשפעה של פורמטים שונים של אחסון, במיוחד Parquet, Avro ו-ORC, על ביצועי השאילתות והעלויות בסביבות נתוני עתק ב-Google Cloud Platform (GCP). המאמר מספק מדדים, דן בהשלכות כלכליות, ומציע המלצות לבחירת הפורמט המתאים בהתבסס על מקרים שימושיים ספציפיים.
מבוא לפורמטי אחסון בנתוני עתק
פורמטי אחסון נתונים הם עמוד השדרה של כל סביבת עיבוד נתוני עתק. הם מגדירים כיצד הנתונים מאוחסנים, נקראים ונכתבים, ומשפיעים ישירות על יעילות האחסון, ביצועי השאילתות ומהירות שליפת הנתונים. במערכת האקולוגית של נתוני עתק, פורמטים עמודתיים כמו Parquet ו-ORC ופורמטים מבוססי שורות כמו Avro נמצאים בשימוש נרחב הודות לביצועים האופטימליים שלהם לסוגים ספציפיים של שאילתות ומשימות עיבוד.
- Parquet: Parquet הוא פורמט אחסון עמודתי המותאם לפעולות מרובות קריאה וניתוח נתונים. הוא יעיל מאוד מבחינת דחיסה וקידוד, מה שהופך אותו לאידיאלי עבור תרחישים בהם ביצועי קריאה ויעילות אחסון הם עדיפות.
- Avro: Avro הוא פורמט אחסון מבוסס שורות המיועד לסריאליזציה של נתונים. הוא ידוע ביכולת ההתפתחות של הסכימה שלו ומשמש לרוב עבור פעולות מרובות כתיבה בהן יש צורך בסריאליזציה ודסיריאליזציה מהירה של נתונים.
- ORC (Optimized Row Columnar): ORC הוא פורמט אחסון עמודתי דומה ל-Parquet אבל מותאם לפעולות קריאה וכתיבה, ORC הינו יעיל מבחינת הכיווץ, מוריד את עלויות האחסון ומאיץ את שיגור הנתונים.
מטרת המחקר
המטרה העיקרית של המחקר הזה היא להעריך איך פורמטים שונים של אחסון (Parquet, Avro, ORC) משפיעים על ביצועי שאילתות ועל העלויות בסביבות נתונים גדולים. המאמר מכוון לספק בדיקות בסיס לפי סוגי שאילתות שונים וגודלי נתונים שיעזרו למהנדסי נתונים וארכיטקטים לבחור את הפורמט המתאים ביותר לשימושים שלהם.
הקמת ניסוי
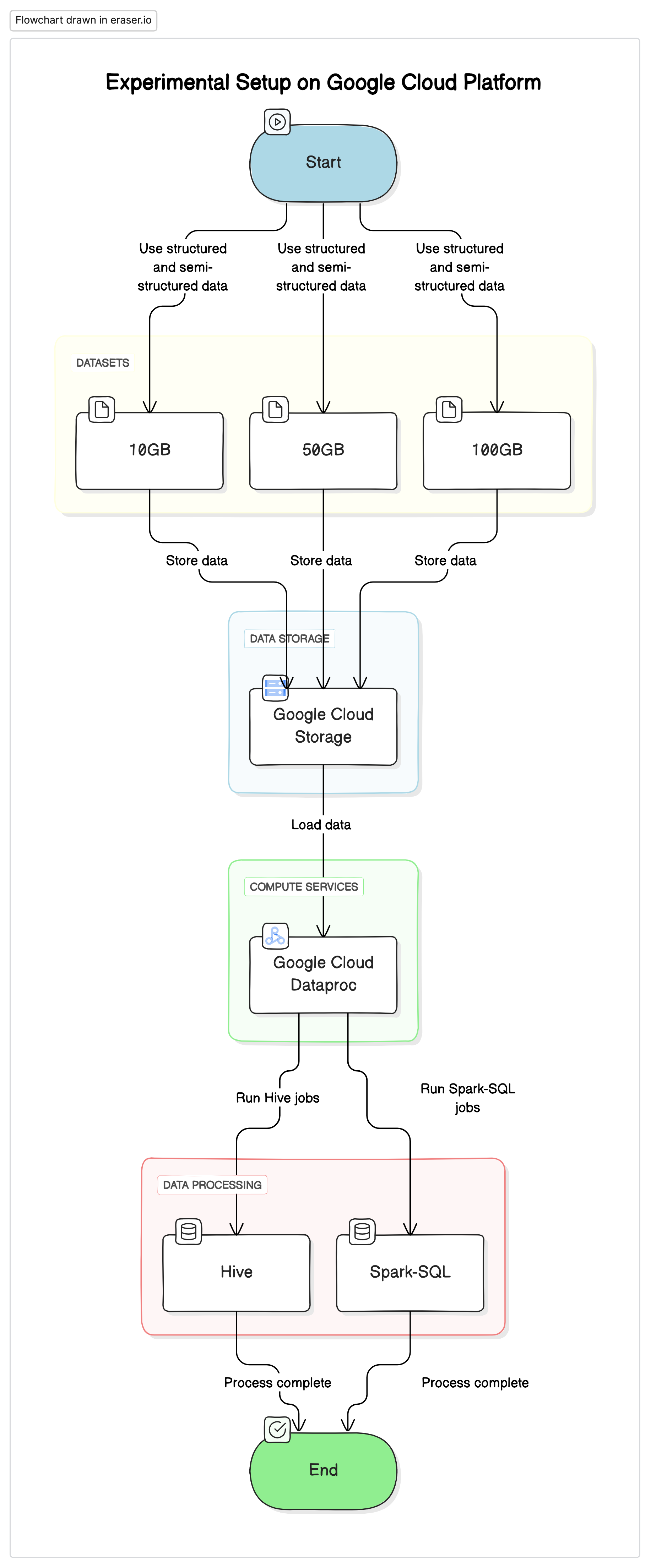
על מנת לבצע את המחקר הזה, השתמשנו בהקמה סטנדרטית על פלטפורמת Google Cloud (GCP) עם Google Cloud Storage כמאגר נתונים וGoogle Cloud Dataproc לריצת עבודות Hive ו-Spark-SQL. הנתונים ששומשו בניסויים היו מערבב של נתונים מבניים ולא מבניים כדי לחקות רצפים של רגעי חיים.
מרכיבים עיקריים
- Google Cloud Storage: שומש לאחסון קבצי נתונים בפורמטים שונים (Parquet, Avro, ORC)
- Google Cloud Dataproc: שירות ניהולי Apache Hadoop ו-Apache Spark ששומש לריצת עבודות Hive ו-Spark-SQL.
- נתונים: שלושה קבצי נתונים בגודלים שונים (10GB, 50GB, 100GB) עם סוגי נתונים מעורבבים.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
שאילתות בדיקה
- שאילתות SELECT פשוטות: שליפה בסיסית של כל העמודות מטבלה
- שאילתות סינון: שאילתות SELECT עם תנאי WHERE לסינון שורות ספציפיות
- שאילתות אגרגציה: שאילתות הכוללות GROUP BY ופונקציות אגרגטיביות כמו SUM, AVG וכדומה.
- שאילתות חיבור (Join): שאילתות שמחברות בין שתי טבלאות או יותר על בסיס מפתח משותף
תוצאות וניתוח
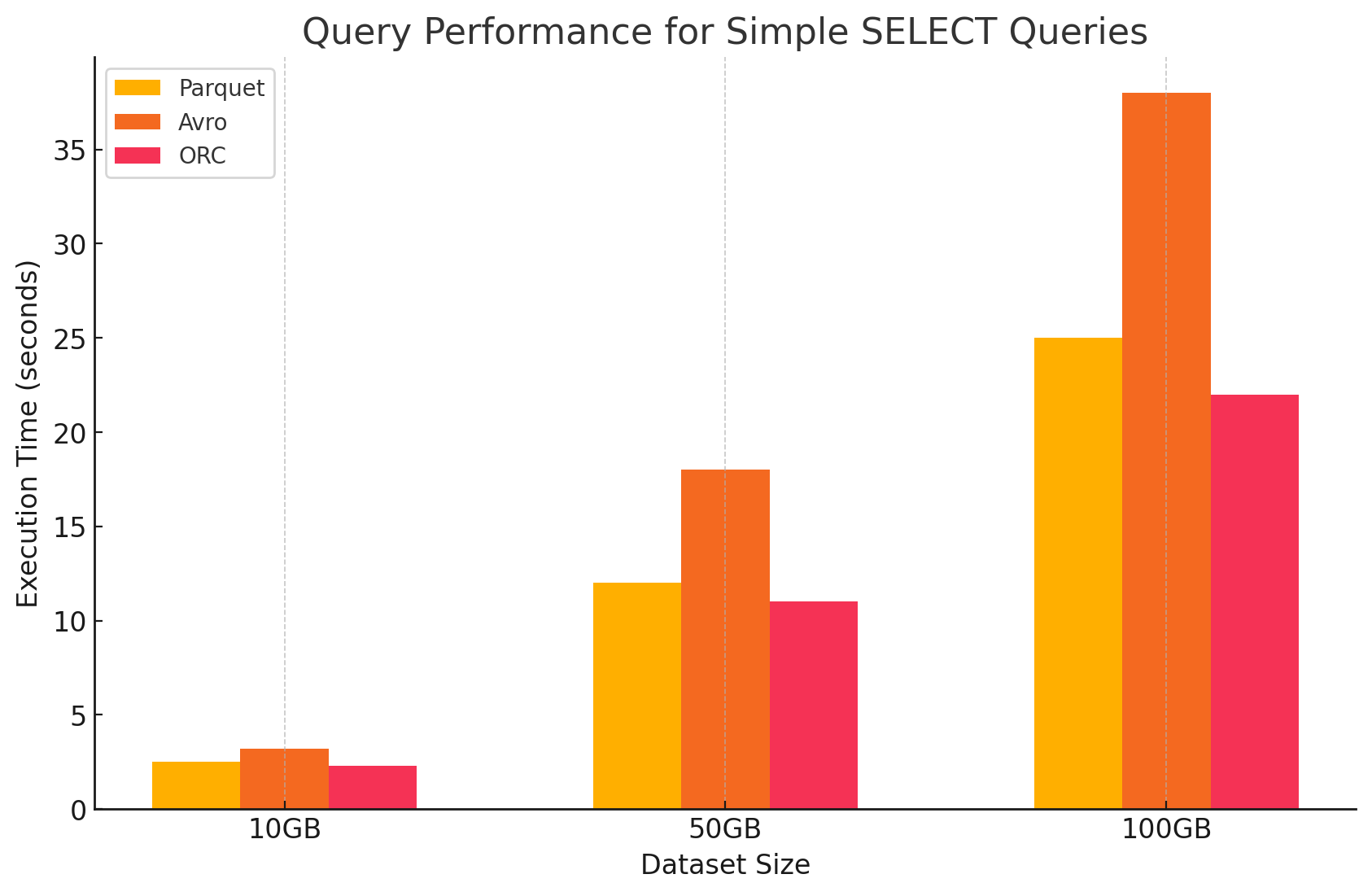
1. שאילתות SELECT פשוטות
- Parquet: ביצע באופן יוצא מן הכלל בזכות פורמט האחסון העמודתי שלו, שאיפשר סריקה מהירה של עמודות ספציפיות. קבצי Parquet דחוסים מאוד, מה שמקטין את כמות הנתונים שנקראים מהדיסק וכתוצאה מכך מתקצר זמן הביצוע של השאילתה.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro: ביצע באופן ממוצע. כפורמט מבוסס שורות, Avro דרש קריאת כל השורה, גם כאשר נדרשו רק עמודות ספציפיות. זה מגדיל את פעולות ה-I/O, מה שמוביל לביצועים איטיים יותר בהשוואה ל-Parquet ו-ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC: ORC הציג ביצועים דומים ל-Parquet, עם דחיסה מעט טובה יותר וטכניקות אחסון מותאמות ששיפרו את מהירות הקריאה. קבצי ORC גם הם עמודתיים, מה שהופך אותם למתאימים לשאילתות SELECT שמחזירות עמודות ספציפיות בלבד.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
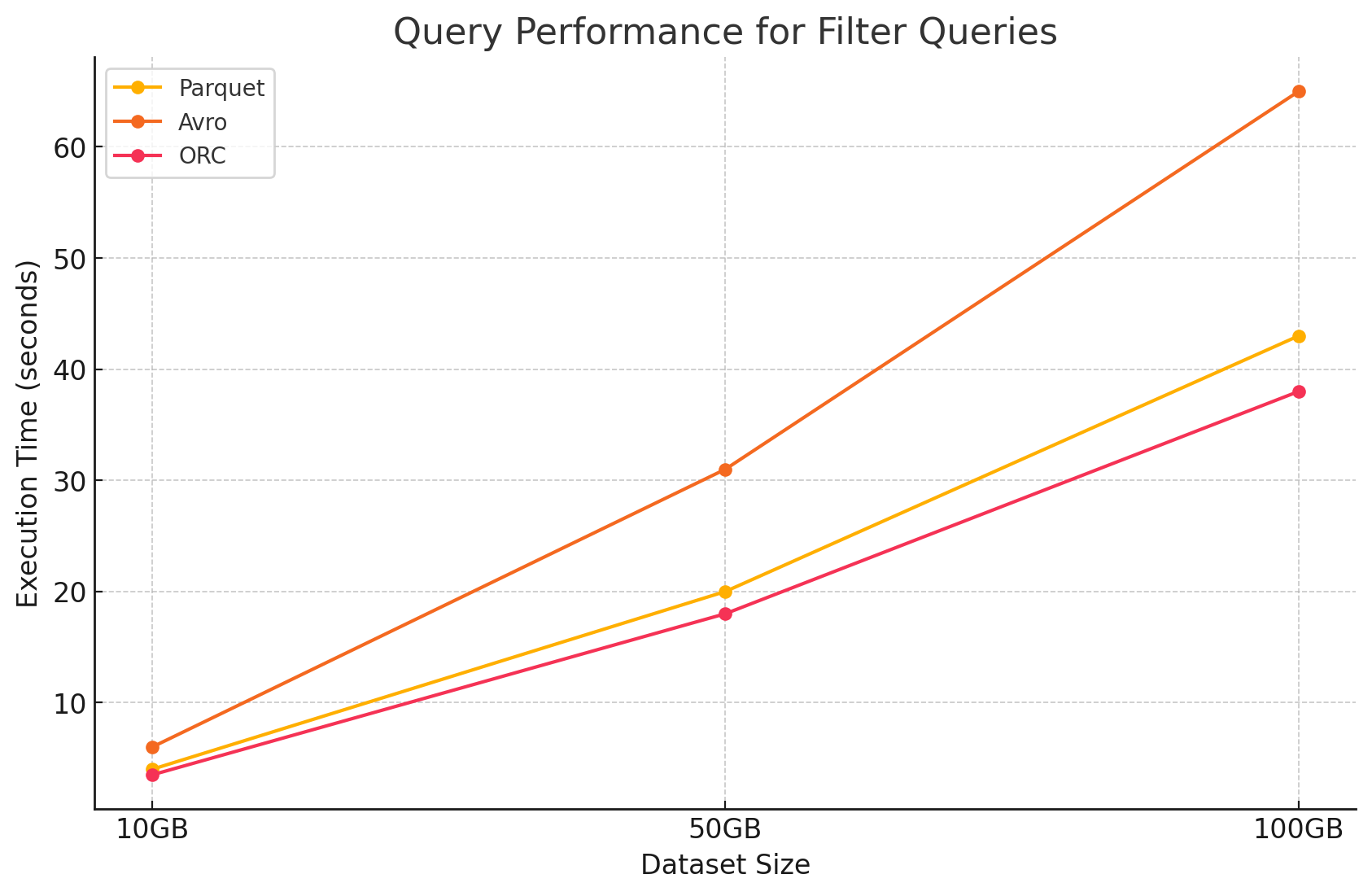
2. שאילתות סינון
- Parquet: Parquet שמר על יתרון הביצועים שלו בזכות טבעו העמודתי והיכולת לדלג במהירות על עמודות לא רלוונטיות. עם זאת, הביצועים הושפעו במעט מהצורך לסרוק יותר שורות כדי ליישם את הסינון.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro: הביצועים ירדו עוד יותר בשל הצורך לקרוא את כל השורות ולהחיל סינונים על כל העמודות, מה שהגדיל את זמן העיבוד.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC: ביצע טוב יותר מ-Parquet במעט בשאילתות סינון בזכות תכונת ה-predicate pushdown שלו, המאפשרת לסנן ישירות ברמת האחסון לפני שהנתונים נטענים לזיכרון.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
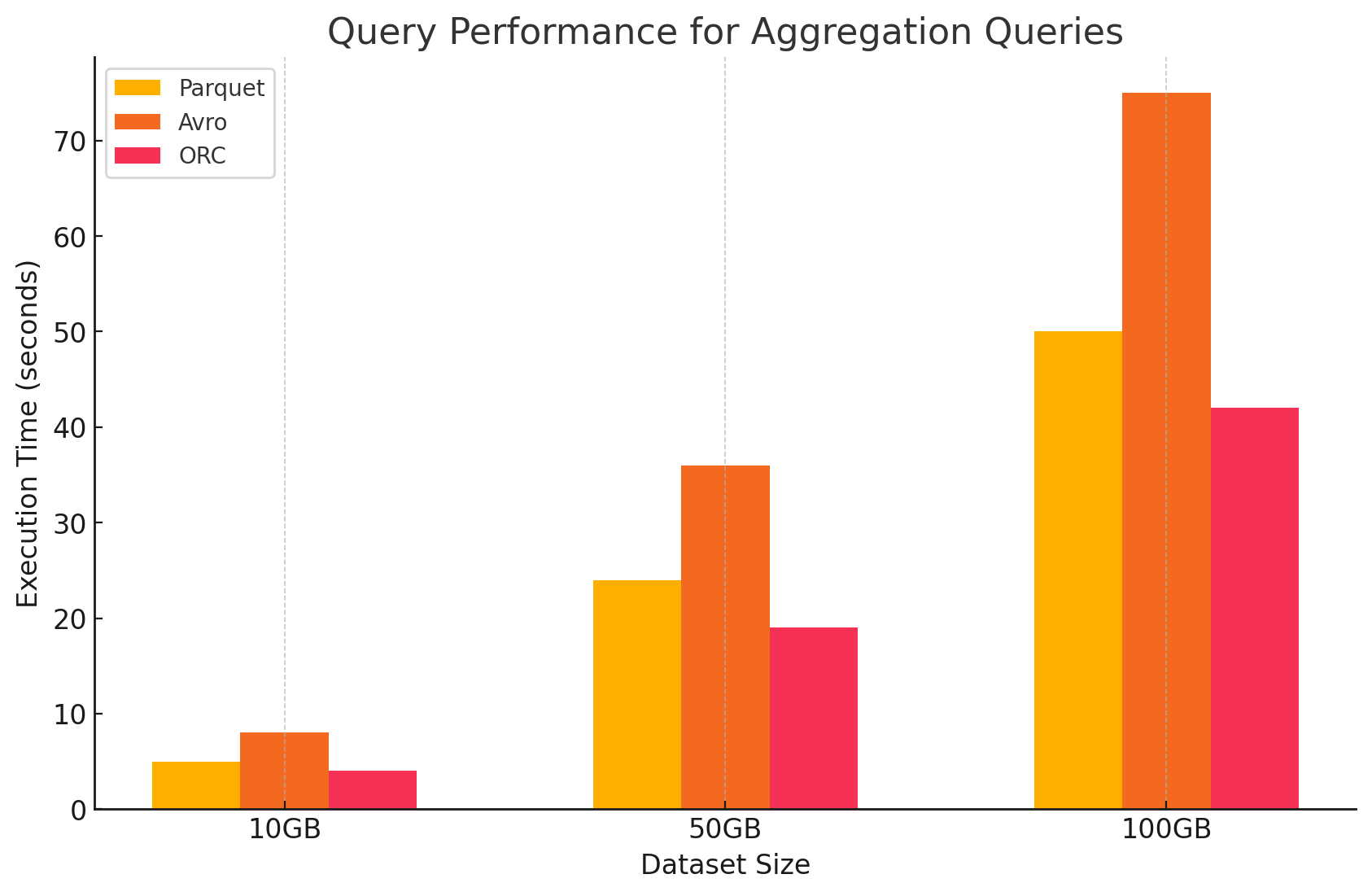
3. שאילתות אגרגציה
- Parquet: Parquet ביצע טוב, אך היה מעט פחות יעיל מ-ORC. הפורמט העמודתי מועיל לפעולות אגרגציה בכך שהוא ניגש במהירות לעמודות הנדרשות, אך Parquet חסר חלק מהאופטימיזציות המובנות ש-ORC מציע.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro: Avro פיגר מאחור בשל פורמט האחסון מבוסס השורות שלו, שחייב סריקה ועיבוד של כל העמודות עבור כל שורה, מה שהגביר את העומס החישובי.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC: ORC עלה בביצועיו הן על Parquet והן על Avro בשאילתות אגרגציה. תכונות האינדוקס המתקדמות ואלגוריתמי הדחיסה המובנים של ORC איפשרו גישה מהירה יותר לנתונים והפחיתו את פעולות ה-I/O, מה שהופך אותו למתאים מאוד למשימות אגרגציה.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
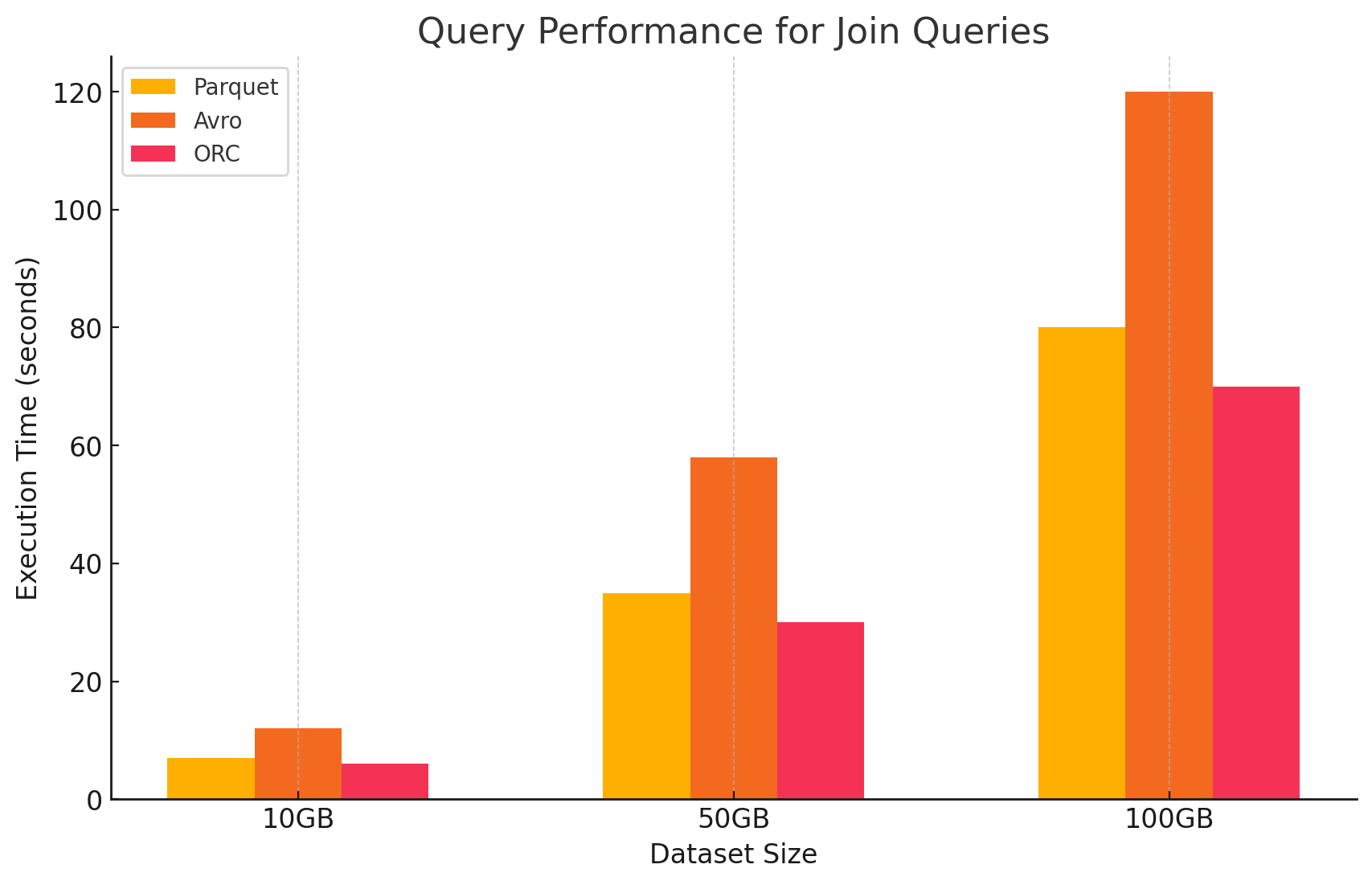
4. שאילתות חיבור (Join)
- Parquet: Parquet ביצע טוב, אך לא באותה מידה כמו ORC בפעולות חיבור, בשל קריאת נתונים פחות אופטימלית לתנאי החיבור.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC: ORC הצטיין בשאילתות חיבור, נהנה מתכונות אינדוקס מתקדמות ויכולות predicate pushdown, אשר צמצמו את כמות הנתונים הנסרקים והמעובדים במהלך פעולות החיבור.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro: ל-Avro היו קשיים משמעותיים בפעולות הצטרפות, בעיקר בשל התקורה הגבוהה של קריאת שורות מלאות והעדר אופטימיזציות עמודתיות עבור מפתחות הצטרפות.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
השפעת פורמט האחסון על עלויות
1. יעילות אחסון ועלות
- Parquet ו-ORC (פורמטים עמודתיים)
- דחיסה ועלות אחסון: גם Parquet וגם ORC הם פורמטים עמודתיים שמציעים יחסי דחיסה גבוהים, במיוחד עבור מערכי נתונים עם ערכים רבים שחוזרים על עצמם או דומים בתוך עמודות. דחיסה גבוהה זו מקטינה את גודל הנתונים הכולל, מה שמפחית את עלויות האחסון, במיוחד בסביבות ענן שבהן האחסון מחויב לפי GB.
- אופטימלי לעומסי עבודה אנליטיים: בשל אופיים העמודתי, פורמטים אלו אידיאליים לעומסי עבודה אנליטיים שבהם רק עמודות מסוימות נשאלות לעיתים קרובות. המשמעות היא שפחות נתונים נקראים מהאחסון, מה שמפחית גם את פעולות ה-I/O והעלויות הקשורות לכך.
- Avro (פורמט מבוסס-שורות)
- דחיסה ועלות אחסון: Avro בדרך כלל מספק יחסי דחיסה נמוכים יותר מאשר פורמטים עמודתיים כמו Parquet ו-ORC מכיוון שהוא מאחסן נתונים שורה אחר שורה. זה יכול להוביל לעלויות אחסון גבוהות יותר, במיוחד עבור מערכי נתונים גדולים עם עמודות רבות, מכיוון שיש לקרוא את כל הנתונים בשורה, גם אם רק כמה עמודות נדרשות.
- מתאים יותר לעומסי עבודה עם כתיבה כבדה: בעוד ש-Avro עשוי לגרום לעלויות אחסון גבוהות יותר בשל דחיסה נמוכה, הוא מתאים יותר לעומסי עבודה עם כתיבה כבדה שבהם נתונים נכתבים או מצורפים באופן רציף. העלות הקשורה לאחסון עשויה להתאזן על ידי הרווחים ביעילות בסריאליזציה ובדסיריאליזציה של הנתונים.
2. ביצועי עיבוד נתונים ועלות
- Parquet ו-ORC (פורמטים עמודתיים)
- הפחתת עלויות עיבוד: פורמטים אלו מותאמים לפעולות קריאה כבדות, מה שהופך אותם ליעילים במיוחד לשאילתות על מערכי נתונים גדולים. מכיוון שהם מאפשרים קריאה רק של העמודות הרלוונטיות לשאילתה, הם מפחיתים את כמות הנתונים המעובדים. זה מוביל לשימוש מופחת ב-CPU ולזמני ביצוע שאילתות מהירים יותר, מה שיכול להפחית משמעותית את עלויות החישוב בסביבת ענן שבה משאבי חישוב מחויבים על בסיס שימוש.
- תכונות מתקדמות לאופטימיזציית עלויות: ל-ORC, במיוחד, יש תכונות כמו דחיפת תנאים וסטטיסטיקות מובנות, שמאפשרות למנוע השאילתה לדלג על קריאת נתונים לא נחוצים. זה מפחית עוד יותר את פעולות ה-I/O ומאיץ את ביצוע השאילתה, מה שמייעל עלויות.
- פורמט Avro (מבוסס על שורות)
- עלויות עיבוד גבוהות: בגלל שAvro הוא פורמט מבוסס על שורות, הוא בדרך כלל דורש יותר פעולות I/O כדי לקרוא שורות שלמות למרות שנדרשות רק כמה עמודות. זה עשוי להוביל לעלויות חישוב גבוהות בגלל שימוש גבוה במעבד וזמני הרצה ארוכים של שאילתות, במיוחד בסביבות קשות קריאה.
- יעילות בזרימה וסריאליזציה: למרות עלויות עיבוד גבוהות עבור שאילתות, Avro מתאים היטב למשימות זרימה וסריאליזציה שבהן מהירות הכתיבה והתפתחות הסכמה הן חשובות יותר.
3. ניתוח עלויות עם פרטי מחיר
- כדי לכמת את ההשפעה הכספית של כל פורמט אחסון, ביצענו ניסוי באמצעות GCP.
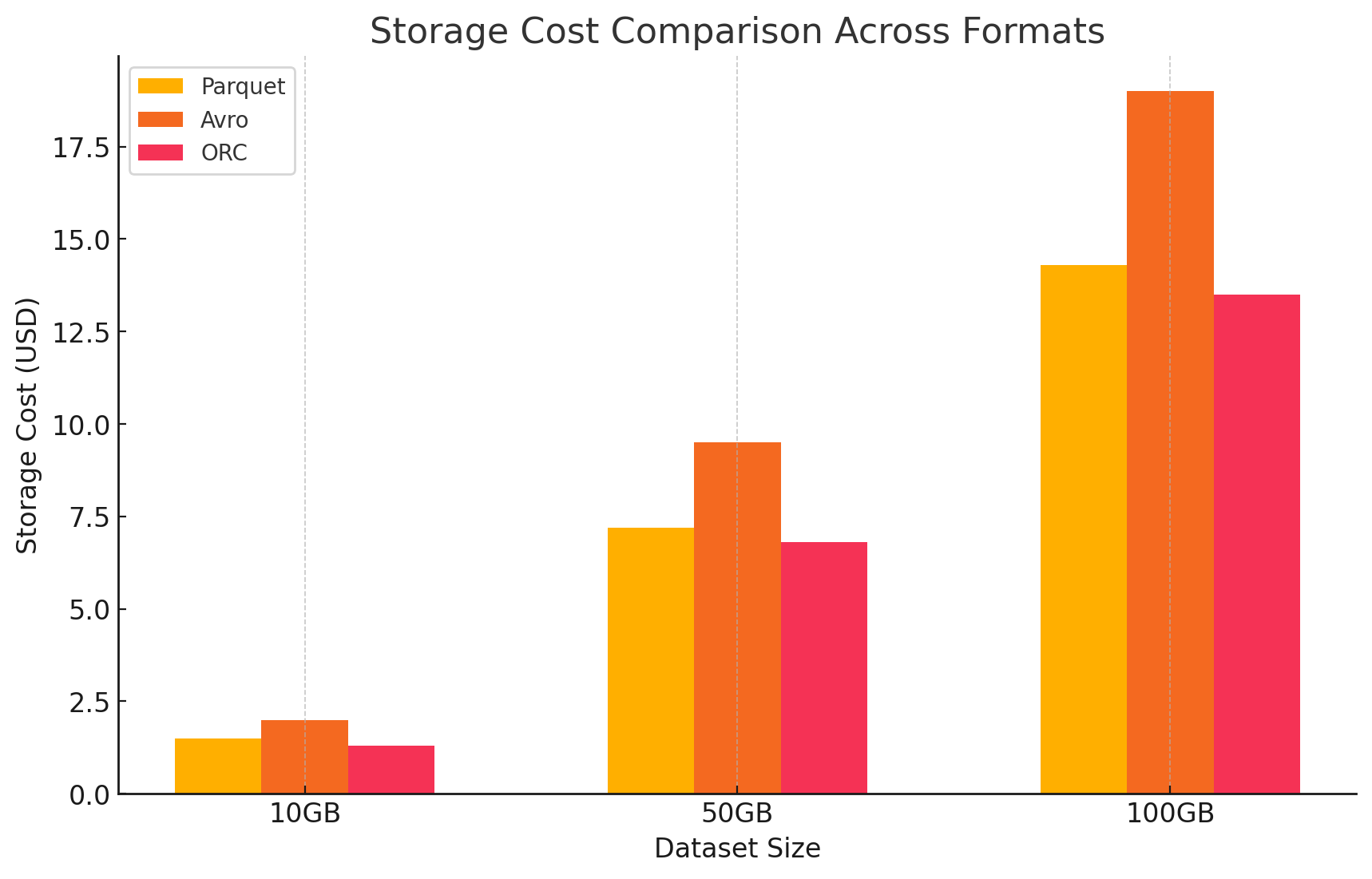
- עלויות האחסון בגוגל צ 'יילד
- עלויות אחסון: זה מוחשב על פי כמות המידע המאחסן בכל הפורמט. גוגל צ 'יילד מקבל תשלום על כל ג' יבי בחודש עבור מידע שמאחסן באחסון גוגל. שיעורים ההתדמידות של כל הפורמטים משפיעים ישירות על העלויות האלה. פורמטים עמודיים כמו פארקט ואורק בדרך כלל מקבלים שיעורים התדמידות טובים יותר מאותם עמודיים מבוססים על שורות כמו אברו, מובילה לעלויות אחסון נמוכות יותר.
- הנה דוגמא לאופן בו מוערכות עלויות האחסון:
- פארקט: ההתדמידות הגבוהה הוסיפה לגודל המידע, והורדתה את עלויות האחסון
- אורק: דומה לפארקט, ההתדמידות המתקדמות של אורק גם הורדתה את עלויות האחסון בצורה יעילה
- אברו: שיעור ההתדמידות הנמוך הוסיף לעלויות האחסון יחסית לפארקט ואורק
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
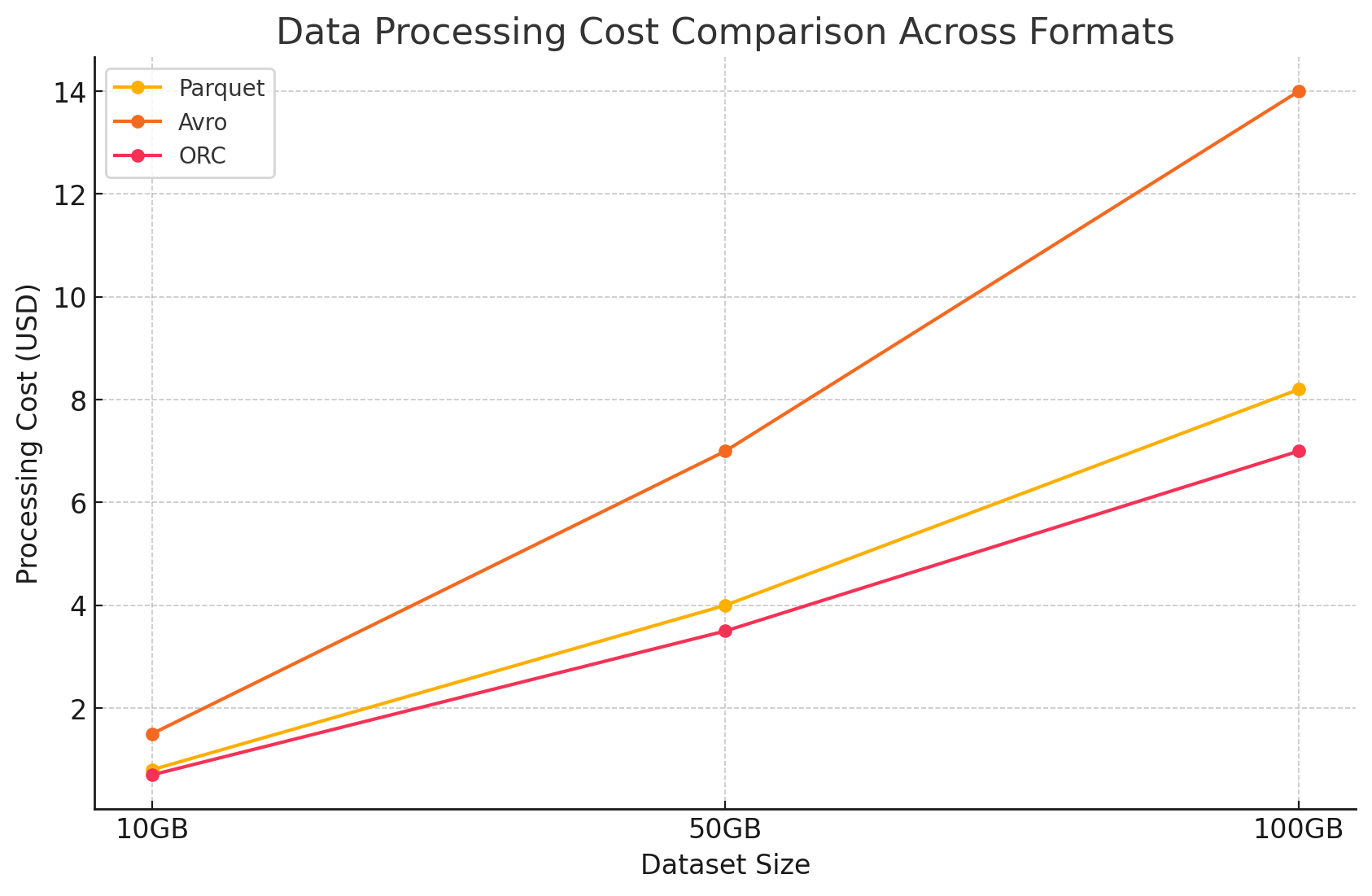
- עלויות עיבוד מידע
- עלויות עיבוד מידע נחשבו על פי המשאבים המערכתיים הדרושים על מנת לבצע מבחנים שונים בעזרת Dataproc על GCP. GCP מקבל שירותים על בסיס הגודל של הקבוצה ומה האורך של השימוש במשאבים.
- עלויות מחשבה:
- Parquet ו ORC:בעקבות האקסלציין העמודי שלהם, הפורמטים האלה צמצמו את מספר המידע שנקרא ונעבוד, שהוביל לעלויות מחשבה נמוכות. הזמן האקשר המהיר גם סייע לחסכונות, בעיקר למבחנים מורכבים שעם מספרים גדולים של מידע.
- Avro:Avro דרש משאבים מחשבה יותר בגלל הפורמט השורה-מבוסס, שגביר את מספר המידע שנקרא ונעבוד. זה הוביל לעלויות גבוהות, בעיקר בעיקר עבור פעילויות רדי-חזקות.
הסיכוי
הבחירה בפורמט אחסון בסביבות ביג דאטה משפיעה באופן משמעותי הן על ביצועי השאילתה והן על העלות. המחקר והניסוי הנ"ל מדגימים את הנקודות המרכזיות הבאות:
- Parquet ו-ORC: פורמטים עמודתיים אלו מספקים דחיסה מצוינת, שמפחיתה את עלויות האחסון. היכולת שלהם לקרוא ביעילות רק את העמודות הנדרשות משפרת מאוד את ביצועי השאילתה ומפחיתה את עלויות עיבוד הנתונים. ORC מתעלה מעט על Parquet בסוגי שאילתות מסוימים בזכות תכונות האינדוקס והאופטימיזציה המתקדמות שלו, מה שהופך אותו לבחירה מצוינת עבור עומסי עבודה מעורבים שדורשים גם ביצועי קריאה וגם כתיבה גבוהים.
- Avro: למרות ש-Avro אינו יעיל כמו Parquet ו-ORC מבחינת דחיסה וביצועי שאילתה, הוא מצטיין במקרים הדורשים פעולות כתיבה מהירות והתפתחות סכמות. פורמט זה אידיאלי לתרחישים הכוללים סריאליזציה של נתונים והזרמתם, שבהם ביצועי הכתיבה והגמישות מקבלים עדיפות על פני יעילות הקריאה.
- יעילות עלות: בסביבת ענן כמו GCP, שבה העלויות קשורות באופן הדוק לשימוש באחסון ובחישוב, הבחירה בפורמט הנכון יכולה להוביל לחיסכון משמעותי בעלויות. עבור עומסי עבודה אנליטיים המתמקדים בעיקר בקריאה, Parquet ו-ORC הם האפשרויות המשתלמות ביותר. עבור יישומים שדורשים קליטת נתונים מהירה וניהול סכמות גמיש, Avro הוא בחירה מתאימה למרות עלויות האחסון והחישוב הגבוהות יותר.
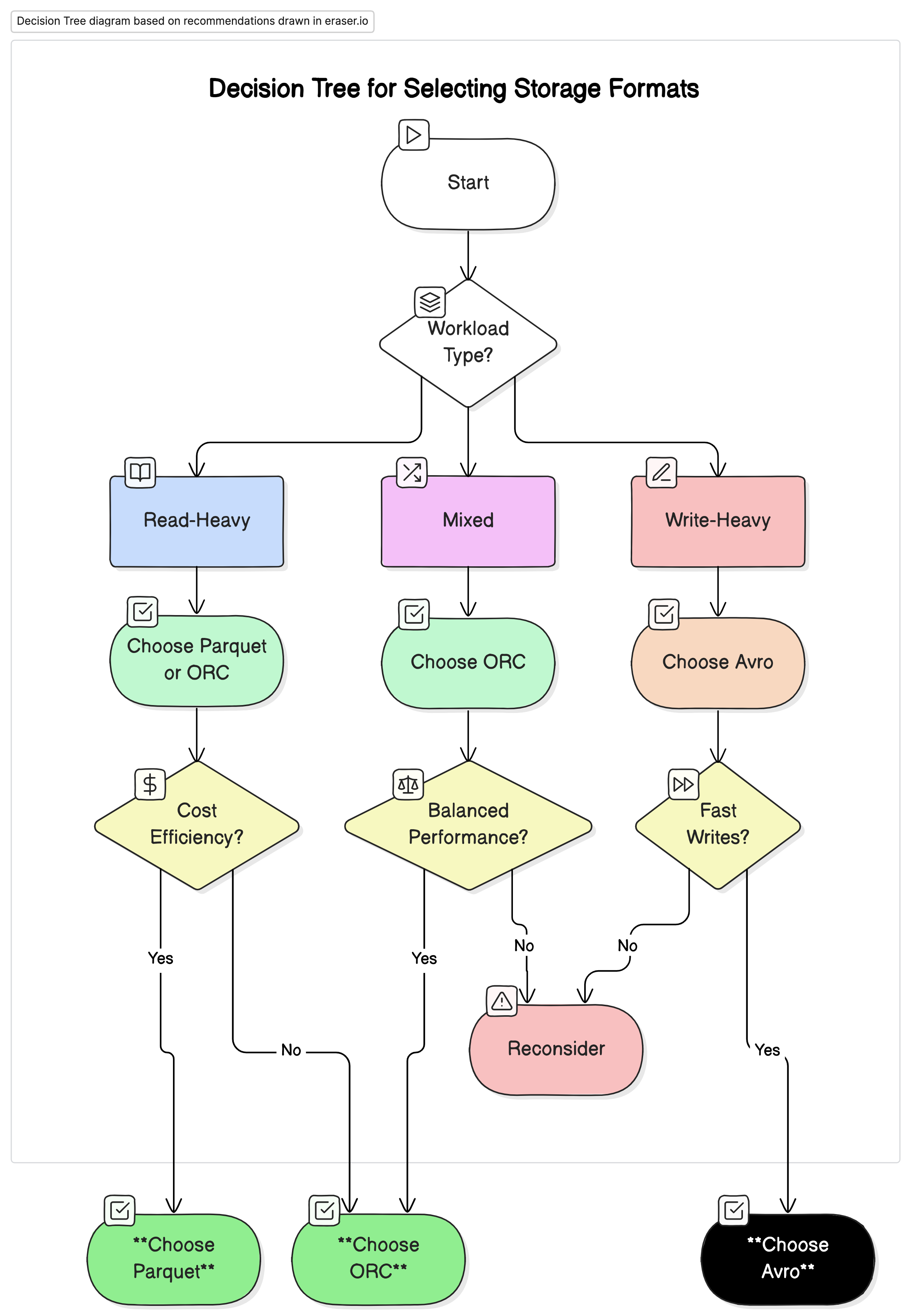
המלצות
בהתבסס על הניתוח שלנו, אנו ממליצים על הדברים הבאים:
- לעבודה נשואה בעיקרון: השתמש בParquet או ORC. הפורמטים האלו מציעים ביצועים ויעילות עלולים גבוהים בגלל הכיווץ הגבוה וביצועי שאילתות מותאמים.
- לעבודה נשואה בעיקרון בכתיבה והסדרה: השתמש ב Avro. הוא מתאים טוב יותר לנרטיבים בהם הכתיבה מהירה והתפתחות הסכמה היא חיונית, כמו במערכות הזרמת נתונים ומערכות מסרים.
- לעבודה משולבת: ORC מציע ביצועים מאוזנים לפעולות קריאה וכתיבה, הופך אותו לבחירה מועדפת בסביבות בהן עבודות הנתונים משתנות.
מחשבות סופיות
בחירת הפורמט הנכון לסביבות נתונים גדולים היא חשובה למען פיתוח הביצועים והעלות. הבנת החוזקות והחולשות של כל פורמט מאפשרת למהנדסי הנתונים להתאים את הארכיטקטורת הנתונים שלהם למקרים מסוימים, מקסימום את היעילות ומפחית את הוצאות. כשסכומי הנתונים ממשיכים לגדול, החלטות מודעות בנוגע לפורמטי איחסון יהפכו לחשובות יותר לשינוי הנתונים בצורה מדידה ויעילה.
על-ידי בדיקה יעילה של הבנקמרים המוצגים וההשלכות הפיסקליות במאמר זה, איגודים יכולים לבחור את הפורמט האחסון המתאים הטוב ביותר לצרכיהם ה operatiוליים ולמטרות הפיננסיות שלהם.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc