













מודלים גדולים למדבקות טקסט (LLMs) מבצעים עיבוד שפה טבעית (NLP) כדי לייצג את המשמעות של הטקסט כווקטור. הייצוג של מילים בטקסט זהו הטלה.
המגבלת הטוקן: הבעיה הגדולה ביותר של מדבקות LLM
כיום, אחת הבעיות הגדולות ביותר עם מדבקות LLM היא מגבלת הטוקן. כש-GPT-3 הושק, המגבלה לטקסט המדבק והפלט יחד הייתה 2,048 טוקנים. עם GPT-3.5, המגבלה עלתה ל-4,096 טוקנים. כעת, GPT-4 מגיע בשני גרסאות. אחת עם מגבלה של 8,192 טוקנים ואחרת עם מגבלה של 32,768 טוקנים, כ-50 עמודים של טקסט.
אז, מה אפשר לעשות כשעשוי להיות רצון לבצע מדבקה עם ה语境 גדול מהמגבלה זו? כמובן, הפתרון היחיד הוא להקטין את ה语境. אבל איך ניתן להקטין אותו ובמקביל לשמור על כל המידע הרלוונטי? הפתרון: לאחסן את ה语境 במסד נתונים וקטורי ולמצוא את ה语境 הרלוונטי עם חיפוש דמיון שאילתא.
מהם הטלות וקטוריות?
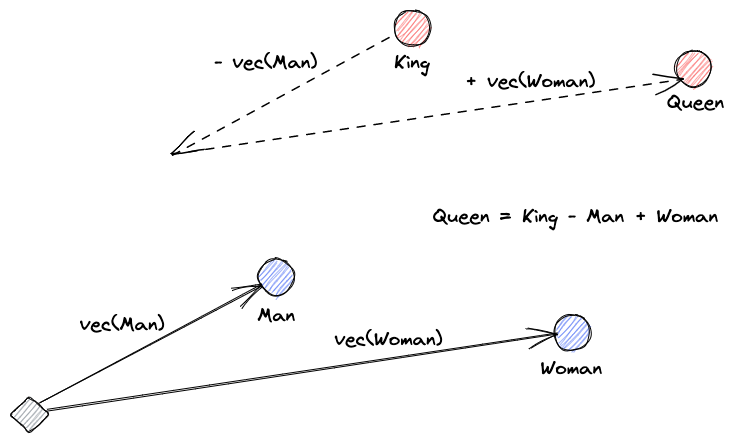
בואו נתחיל בלהסביר מהם הטלות וקטוריות. ההגדרה של רוי קינס היא: "הטלות הן העברות נלמדות כדי להפוך את הנתונים לשימושיים יותר." רשת עצבית לומדת להעביר את הטקסט למרחב וקטורי המכיל את המשמעות האמיתית שלו. זה שימושי יותר כיוון שהוא יכול למצוא מילים נרדפות והקשרים סинטקטיביים וסמנטיים בין מילים. התמונה הזו עוזרת לנו להבין איך וקטורים אלה יכולים לקודד משמעות:
מה עושים מסדי נתונים וקטוריים?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
חיפוש דמיון
ניתן למצוא את הדמיון בין וקטורים על ידי חישוב המרחק של וקטור מכל שאר הוקטורים. השכנים הקרובים ביותר יהיו התוצאות הכי דומות לוקטור השאילתה. כך פועלים מדיניות שטוחות במסדי נתונים וקטוריים. אך זה אינו יעיל במיוחד; במסד נתונים גדול, זה עשוי לקחת הרבה זמן.
כדי לשפר את ביצועי החיפוש, ניתן לנסות לחשב את המרחק רק עבור קבוצה חלקית של הוקטורים. הגישה הזו, המכונה שכנים קרובים מספרים מערכתיים (ANN), משפרת את המהירות אך מקדישה את איכות התוצאות. כמה מדיניות פופולריות ANN הן Locally Sensitive Hashing (LSH), Hierarchical Navigable Small Worlds (HNSW), או Inverted File Index (IVF).
שילוב מאגרי וקטורים ו-LLMs
לשם דוגמה זו, הורדתי את כל התיעוד של Numpy (עם יותר מ-2000 עמודים) כ-PDF מהכתובת הזו:URL.
אנו יכולים לכתוב קוד פייתון להפיכת המסמך הקשור להקשר לטקסטים ולשמור אותם במאגר וקטור. נשתמש ב-LangChain לטעינת המסמך ולחלוקתו לנתחים וב-Faiss (Facebook AI Similarity Search) כמסד נתונים וקטורי.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")כעת, ניתן להשתמש במסד הנתונים זה לביצוע שאילתת חיפוש דמיון כדי למצוא עמודים שעשויים להיות קשורים להקשר שלנו. לאחר מכן, נשתמש בנתחים המתקבלים למלאת ההקשר של ההקשר שלנו. נשתמש ב-LangChain כדי להקל:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)השאלה שלנו למודל היא, "כיצד לחשב את החציון של מערך". למרות שההקשר שניתן לו גדול מעבר לגבולות הטוקן, עלינו להתגבר על המגבלה הזו וקיבלנו תשובה:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".זו רק פתרון מתוחכם אחד לבעיה מאוד חדשה. כששפות הבדיקה האוטומטוניות ממשיכות להתפתח, אולי בעיות כאלה תופתרנה בלי צורך בפתרונות מתוחכמים כאלה. עם זאת, אני בטוח שההתפתחות הזו תשפיע על יכולות חדשות שעשויות להזדקק לפתרונות מתוחכמים חדשים נוספים לאתגרים שהן עשויות להביא.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data