













Le projet SOLAR-10.7B représente une avancée significative dans le développement de grands modèles de langue, en introduisant une nouvelle approche pour échelle ces modèles de manière efficace et efficiente.
Cet article commence par expliquer ce que le modèle SOLAR-10.7 B est avant de mettre en avant ses performances par rapport à d’autres grands modèles de langue et de plonger dans le processus d’utilisation de sa version fine-tuned spécialisée. Enfin, le lecteur comprendra les applications potentiels du modèle SOLAR-10.7 B-Instruct fine-tuned et ses limitations.
Qu’est-ce que SOLAR-10.7B ?
SOLAR-10.7B est un modèle de 10,7 milliards de paramètres développé par une équipe à Upstage AI en Corée du Sud.
Basé sur l’architecture Llama-2, ce modèle dépasse d’autres grands modèles de langue avec jusqu’à 30 milliards de paramètres, y compris le modèle Mixtral 8X7B.
Pour en savoir plus sur Llama-2, notre article Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model fournit un guide pas à pas pour fine-tuner Llama-2, en utilisant de nouvelles approches pour surmonter les limitations de mémoire et de calcul pour mieux accéder aux grands modèles de langue open-source.
De plus, en s’appuyant sur la solide base de SOLAR-10.7B, le modèle SOLAR 10.7B-Instruct est fine-tuned en mettant l’accent sur le suivi d’instructions complexes. Cette variante montre une performance améliorée, montrant l’adaptabilité du modèle et l’efficacité du fine-tuning pour atteindre des objectifs spécialisés.
La méthode SOLAR-10.7B introduit une méthode appelée Depth Up-Scaling, et探索ons cela plus en détail dans la section suivante.
La méthode Depth Up-Scaling
Cette méthode innovante permet d’augmenter la profondeur de réseau de neurones du modèle sans nécessiter une augmentation proportionnelle des ressources computationnelles. Cette stratégie améliore à la fois l’efficacité et la performance globale du modèle.
Éléments essentiels de Depth Up-Scaling
Le Depth Up-Scaling se base sur trois composants principaux : (1) Poids de Mistral 7B, (2) Structure de Llama 2, et (3) Pré-entrainement continu.
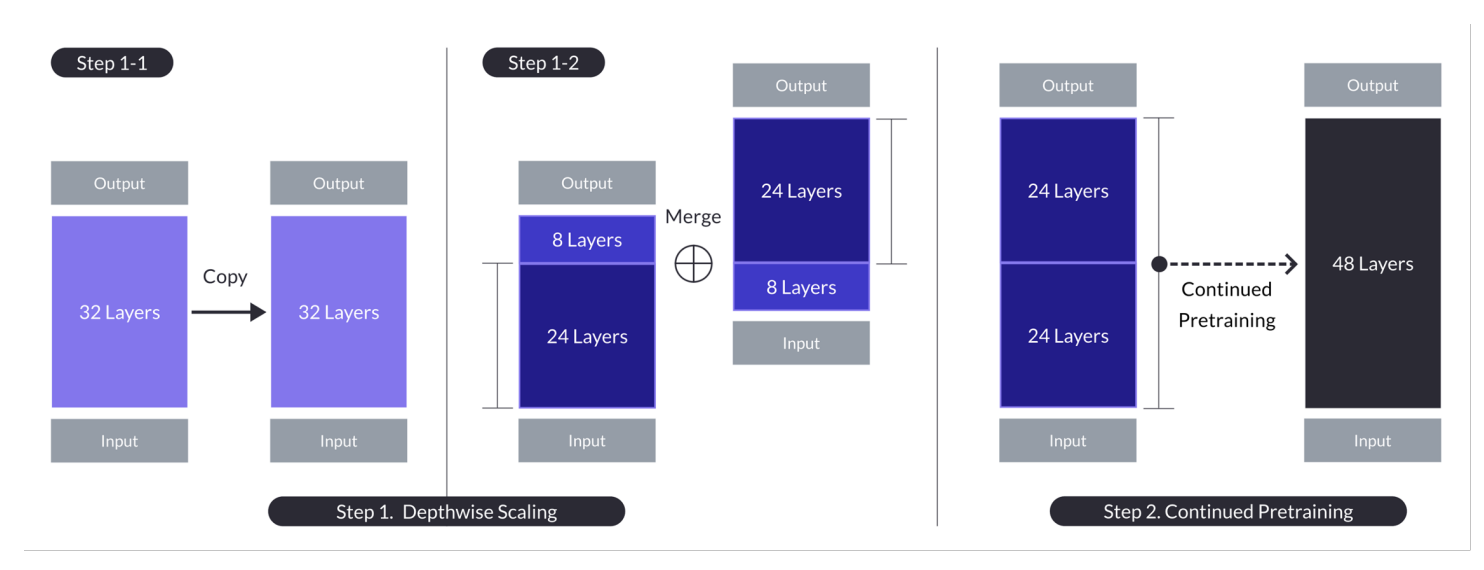
Le depth up-scaling pour le cas où n = 32, s = 48, et m = 8. Le depth up-scaling est réalisé par un processus en deux étapes de mise à l’échelle par profondeur suivie d’un pré-entrainement continu. (Source)
Modèle de base :
- Utilise une architecture de transformeur à 32 couches, spécifiquement le modèle Llama 2, initialisé avec des poids pré-entraînés de Mistral 7B.
- Choisi pour sa compatibilité et ses performances, visant à utiliser les ressources communautaires et à introduire des modifications novatrices pour améliorer les capacités.
- Il sert de fondation pour la mise à l’échelle par profondeur et un pré-entrainement ultérieur pour une scaling up efficace.
Mise à l’échelle par profondeur :
- Met à l’échelle le modèle de base en définissant un nombre cible de couches pour le modèle mis à l’échelle, en tenant compte des capacités matérielles.
- Involue dans la duplication du modèle de base, en enlevant les dernières m couches du original et les premières m couches de la copie, avant de les concaténer pour former un modèle avec s couches.
- Ce processus crée un modèle à échelle ajustée avec un nombre de couches modifié pour s’ajuster entre 7 et 13 milliards de paramètres, en utilisant spécifiquement une base de n=32 couches, en enlevant m=8 couches pour atteindre s=48 couches.
Continuité de l’entraînement préalable:
- Adresse la baisse initiale des performances après le réglage par échelle de profondeur en continuant à pré-entraîner le modèle à échelle.
- Une récupération rapide des performances a été observée pendant la poursuite de l’entraînement préalable, qui a été attribuée à la réduction de l’hétérogénéité et des disparités dans le modèle.
- La poursuite de l’entraînement préalable est essentielle pour retrouver et potentiellement dépasser les performances du modèle de base, en tirant parti de l’architecture du modèle à échelle de profondeur pour un apprentissage efficace.
Ces résumés mettent en évidence les principales stratégies et résultats de l’approche de mise à échelle par profondeur, en se concentrant sur l’utilisation des modèles existants, le réglage par l’ajustement de la profondeur, et l’amélioration des performances par la poursuite de l’entraînement préalable.
Cette approche multifacettes SOLAR-10.7B atteint et, dans de nombreux cas, dépasse les capacités de modèles beaucoup plus grands. Cette efficacité en fait une choix de premier ordre pour une gamme d’applications spécifiques, montrant sa force et sa flexibilité.
Comment fonctionne le modèle d’instructions SOLAR 10.7B ?
SOLAR-10.7B instruct excels à interpréter et à exécuter des instructions complexes, ce qui en fait une ressource extrêmement précieuse dans les situations où une compréhension précise et une réponse rapide aux commandes humaines sont cruciaux. Cette capacité est essentielle pour développer des systèmes d’IA plus intuitifs et interactifs.
- SOLAR 10.7B instruct est le résultat du raffinement du modèle initial SOLAR 10.7B pour suivre des instructions au format QA.
- Le raffinement utilise principalement des jeux de données open-source ainsi que des jeux de données de mathématiques synthétisées pour améliorer les compétences mathématiques du modèle.
- La première version du SOLAR 10.7B instruct est créée en intégrant les poids de Mistral 7B pour renforcer ses capacités d’apprentissage pour un traitement informatisé efficace et efficient.
- La structure de base du SOLAR 10.7B est l’architecture Llama2, qui offre un compromis entre vitesse et précision.
Au total, l’importance du modèle SOLAR-10.7B raffiné se situe dans sa performance améliorée, son adaptabilité et son potentiel pour une large application, propulsant les domaines du traitement naturel du langage et de l’intelligence artificielle.
Applications potentielles du modèle SOLAR-10.7B raffiné
Avant de plonger dans l’implémentation technique, explorerons certaines des applications potentielles d’un modèle SOLAR-10.7B raffiné.
Voici quelques exemples de pédagogie personnalisée et de tutorat, d’assistance clientèle améliorée et de création automatisée de contenu.
- Éducation personnalisée et tutorat : SOLAR-10.7B-Instruct peut révolutionner le secteur éducatif en offrant des expériences d’apprentissage personnalisées. Il peut comprendre les demandes complexes des élèves, en fournissant des explications, des ressources et des exercices adaptés. Cette capacité en fait un outil idéal pour développer des systèmes d’encadrement intelligent adaptés aux styles et besoins d’apprentissage individuels, améliorant ainsi l’engagement et les résultats des élèves.
- Meilleur support client : SOLAR-10.7B-Instruct peut équiper des chatbots avancés et des assistants virtuels capables de comprendre et résoudre des demandes clientnelles complexes avec une haute précision. Cette application non seulement améliore l’expérience client en fournissant un soutien opportun et pertinent, mais aussi réduit le fardeau des représentants du service client en automatisant les demandes routinières.
- Création et résumé automatisés de contenu : Pour les créateurs de médias et de contenu, SOLAR-10.7B-Instruct offre la capacité de générer automatiquement du contenu écrit, tels que les articles de presse, les rapports et la création littéraire. De plus, il peut résumer les documents longs en formats courts et faciles à comprendre, ce qui est précieux pour les journalistes, les chercheurs et les professionnels qui ont besoin d’assimiler et de rapporter rapidement des quantités importantes d’information.
Ces exemples mettent en évidence la versatilité et le potentiel de SOLAR-10.7B-Instruct pour impacter et améliorer l’efficacité, l’accessibilité et l’expérience utilisateur dans un large éventail d’industries.
Guide pas à pas pour l’utilisation de SOLAR-10.7B Instruct
Nous avons suffisamment de connaissances sur le modèle SOLAR-10.7B, et il est temps de nous engager dans des activités pratiques.
Cette section vise à fournir toutes les instructions nécessaires pour exécuter le modèle SOLAR 10.7 Instruct v1.0 – GGUF depuis l’avant-scène.
Les codes sont inspirés par la documentation officielle de Hugging Face. Les principaux étapes sont définies ci-dessous :
- Installer et importer les bibliothèques nécessaires
- Définir le modèle SOLAR-10.7B à utiliser à partir de Hugging Face
- Exécuter l’inférence du modèle
- Générer le résultat à partir de la demande de l’utilisateur
Installation des bibliothèques
Les principales bibliothèques utilisées sont transformers et accelerate.
- La bibliothèque transformers permet d’accéder aux modèles pré-entraînés, et la version spécifiée ici est 4.35.2.
- La bibliothèque accelerate est conçue pour simplifier l’exécution de modèles de machine learning sur différents matériels (CPU, GPU) sans avoir à comprendre en profondeur les spécificités du matériel.
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
Importer les bibliothèques
Maintenant que l’installation est complétée, nous procédons à l’importation des bibliothèques suivantes nécessaires :
- torch est la bibliothèque PyTorch, une bibliothèque de machine learning open source populaire utilisée pour des applications telles que la vision par ordinateur et le traitement du langage naturel.
- AutoModelForCausalLM est utilisé pour charger un modèle pré-entraîné pour le modèle causal du langage, et AutoTokenizer est chargé de convertir le texte en une forme que le modèle peut comprendre (tokenisation).
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
Configuration du GPU
Le modèle utilisé est la version 1 du modèle SOLAR-10.7B de Hugging Face.
Une ressource GPU est nécessaire pour accélérer le chargement du modèle et le processus d’inférence.
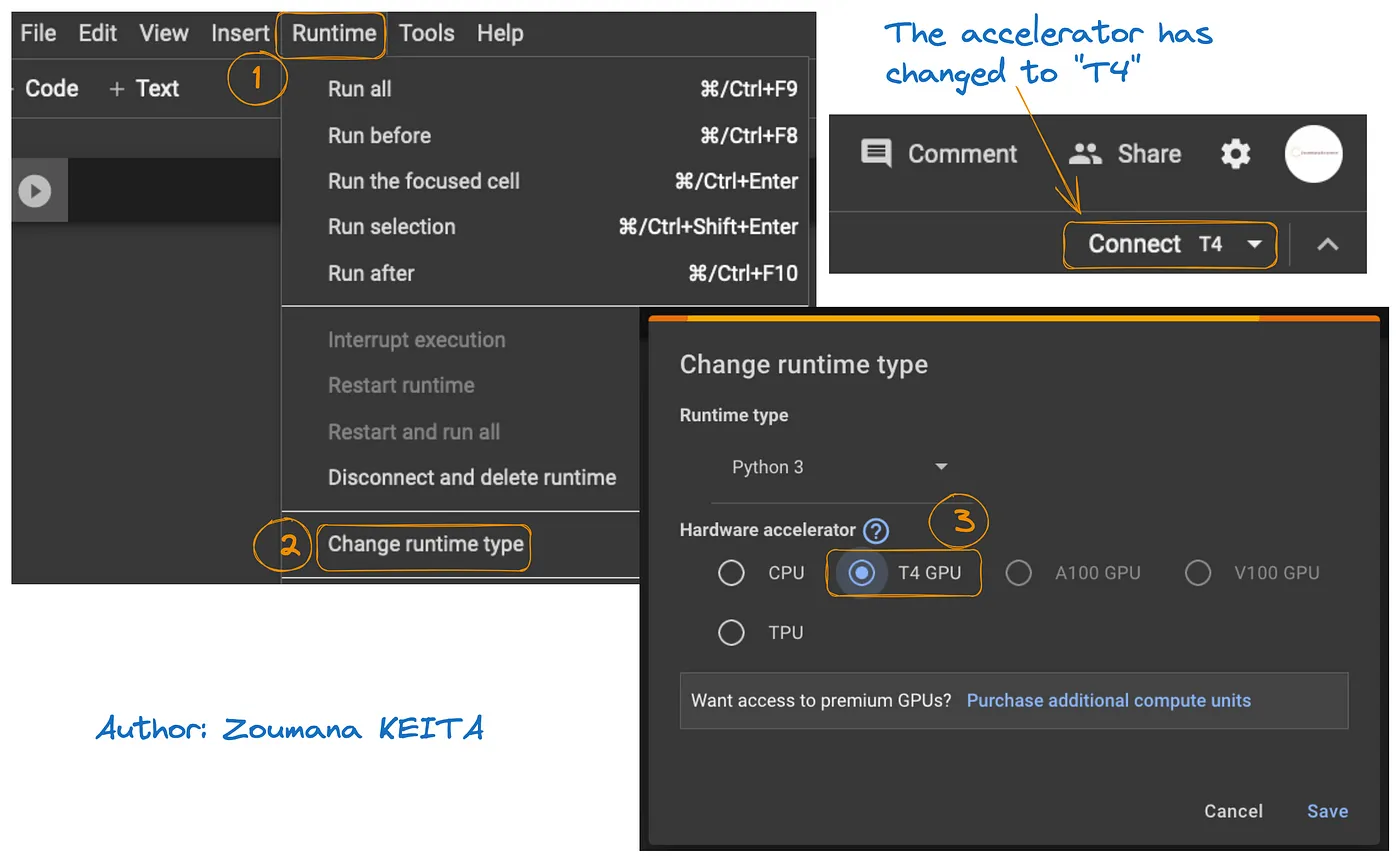
L’accès au GPU sur Google Colab est illustré dans le graphique ci-dessous :
- À partir de l’onglet Exécution, sélectionnez Changer l’environnement d’exécution
- Ensuite, choisissez T4 GPU dans la section du matériel d’accélération et Enregistrer les modifications
Cela basculera l’environnement d’exécution par défaut vers T4 :
Nous pouvons vérifier les propriétés de l’environnement d’exécution en exécutant la commande suivante depuis le bloc-notes Colab.
!nvidia-smi
Propriétés du GPU
Définition du modèle
Tout est prêt, nous pouvons continuer avec le chargement du modèle comme suit :
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID est une chaîne qui identifie de manière unique le modèle pré-entraîné que nous voulons utiliser. Dans ce cas, « Upstage/SOLAR-10.7B-Instruct-v1.0 » est spécifié.
- AutoTokenizer.from_pretrained(model_ID) charge un tokeniseur pré-entraîné sur le modèle spécifié par model_ID, le préparant pour le traitement de l’entrée texte.
- AutoModelForCausalLM.from_pretrained() charge le modèle de langage causal lui-même, avec device_map= »auto » pour utiliser automatiquement le meilleur matériel disponible (le GPU que nous avons configuré), et torch_dtype=torch.float16 pour utiliser des nombres à virgule flottante 16 bits pour économiser de la mémoire et potentiellement accélérer les calculs.
Inférence du modèle
Avant de générer une réponse, le texte d’entrée (demande de l’utilisateur) est formaté et tokenisé.
- user_request contient la question ou l’entrée pour le modèle.
- conversation formate l’entrée en tant que partie d’une conversation, en l’associant à un rôle (par exemple, ‘utilisateur’).
- apply_chat_template applique un modèle de conversation à l’entrée, la préparant dans un format compréhensible par le modèle.
- tokenizer(prompt, return_tensors= »pt ») convertit l’invite en jetons et spécifie le type de tenseur (« pt » pour les tenseurs PyTorch), et .to(model.device) assure que l’entrée est sur le même périphérique (CPU ou GPU) que le modèle.
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
Génération de résultats
La dernière section utilise le modèle pour générer une réponse à la question d’entrée et la décode puis l’affiche.
- model.generate() génère du texte basé sur les entrées fournies, avec use_cache=True pour accélérer la génération en réutilisant les résultats précédemment calculés. max_length=4096 limite la longueur maximale du texte généré.
- tokenizer.decode(outputs[0]) convertit les jetons générés en texte lisible par l’homme.
- print affiche la réponse générée à la question de l’utilisateur.
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
La réussite de l’exécution du code ci-dessus génère le résultat suivant:

En remplaçant la demande de l’utilisateur par le texte suivant, nous obtenons la réponse générée
user_request = "Tell me a story about the universe"

Limitations du modèle SOLAR-10.7B
Malgré tous les avantages du SOLAR-10.7B, il présente comme tout modèle de langue grand des limitations, les principales sont soulignées ci-dessous:
- Exploration approfondie des hyperparamètres : la nécessité d’une exploration plus approfondie des hyperparamètres du modèle pendant l’Up-Scaling de Profondeur (DUS) est une limitation clé. Cela a entraîné la suppression de 8 couches du modèle de base en raison de limitations matérielles.
- Demande de calcul importante : le modèle requiert considérablement de ressources de calcul, ce qui limite son utilisation par des individus et des organisations dotées de capacités de calcul moindres.
- Vulnérabilité au biais : un potentiel biais dans les données d’entraînement pourrait impacter la performance du modèle pour certains cas d’utilisation.
- Préoccupation environnementale : l’entraînement et l’inferrence du modèle nécessitent une consommation d’énergie significative, ce qui peut susciter des préoccupations environnementales.
Conclusion
Cet article a exploré le modèle SOLAR-10.7B, en mettant en évidence sa contribution à l’intelligence artificielle par son approche d’up-scaling de profondeur. Il a décrit le fonctionnement du modèle et ses applications potentielles, et a fourni une guide pratique pour son utilisation, de l’installation à la génération de résultats.
Malgré ses capacités, l’article a également abordé les limitations du modèle SOLAR-10.7B, offrant une perspective complète aux utilisateurs. Comme l’IA continue à évoluer, SOLAR-10.7B illustre les progrès réalisés vers des outils d’IA plus accessibles et polyvalents.
Pour ceux qui souhaitent plonger plus profondément dans les potentiels de l’IA, notre tutoriel, FLAN-T5 Tutorial : Guide et Ajustement Fin, offre un guide complet pour l’ajustement fin d’un modèle FLAN-T5 pour une tâche de réponse à des questions en utilisant la bibliothèque transformers et en exécutant une inférence optimisée dans un scénario réel. Vous pouvez également trouver notre tutoriel d’ajustement fin de GPT-3.5 et notre codage en parallèle sur l’ajustement fin de votre propre modèle LlaMA 2.
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial