













Les LLM effectuent un traitement du langage naturel (NLP) pour représenter le sens du texte sous forme de vecteur. Cette représentation des mots du texte est un embedding.
La Limite de Jetons : Le Plus Gros Problème de l’Incitation LLM
Actuellement, l’un des plus gros problèmes avec l’incitation LLM est la limite de jetons. Lorsque GPT-3 a été publié, la limite pour l’invite et la sortie combinées était de 2 048 jetons. Avec GPT-3.5, cette limite a augmenté à 4 096 jetons. Maintenant, GPT-4 se décline en deux variantes. L’une avec une limite de 8 192 jetons et l’autre avec une limite de 32 768 jetons, soit environ 50 pages de texte.
Que pouvez-vous donc faire lorsque vous voudriez faire une invite avec un contexte plus grand que cette limite ? Bien sûr, la seule solution est de raccourcir le contexte. Mais comment pouvez-vous le raccourcir tout en conservant toutes les informations pertinentes ? La solution : stocker le contexte dans une base de données vectorielle et trouver le contexte pertinent avec une requête de recherche de similarité.
Qu’est-ce que les Embeddings Vectoriels ?
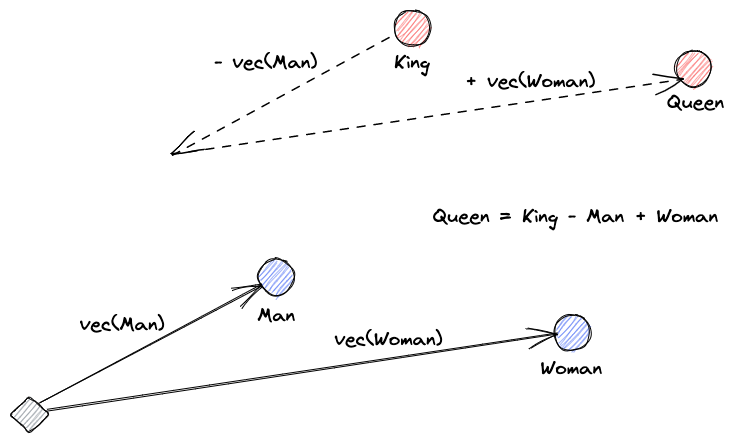
Commençons par expliquer ce que sont les embeddings vectoriels. La définition de Roy Keynes est : « Les embeddings sont des transformations apprises pour rendre les données plus utiles. » Un réseau neuronal apprend à transformer le texte dans un espace vectoriel qui contient son sens réel. C’est plus utile car il peut trouver des synonymes et les relations syntaxiques et sémantiques entre les mots. Cette image nous aide à comprendre comment ces vecteurs peuvent encoder le sens :
Que Font les Bases de Données Vectorielles ?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Recherche de Similarité
Nous pouvons trouver la similarité des vecteurs en calculant la distance d’un vecteur par rapport à tous les autres vecteurs. Les voisins les plus proches seront les résultats les plus similaires au vecteur de requête. C’est ainsi que fonctionnent les index plats dans les bases de données vectorielles. Mais ce n’est pas très efficace ; dans une grande base de données, cela pourrait prendre beaucoup de temps.
Pour améliorer les performances de la recherche, nous pouvons essayer de calculer la distance pour seulement un sous-ensemble des vecteurs. Cette approche, appelée voisins approximatifs les plus proches (ANN), améliore la vitesse mais sacrifie la qualité des résultats. Certains index ANN populaires sont le Locally Sensitive Hashing (LSH), les Hierarchical Navigable Small Worlds (HNSW) ou l’Inverted File Index (IVF).
Intégration des vecteurs de stockage et des LLM
Pour cet exemple, j’ai téléchargé l’ensemble de la documentation Numpy (avec plus de 2000 pages) au format PDF à partir de cette URL.
Nous pouvons écrire du code Python pour transformer le document de contexte en embeddings et les enregistrer dans un vecteur de stockage. Nous utiliserons LangChain pour charger le document et le diviser en chunks, et Faiss (Facebook AI Similarity Search) comme base de données vectorielle.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Maintenant, nous pouvons utiliser cette base de données pour effectuer une requête de recherche de similarité afin de trouver les pages qui pourraient être liées à notre invite. Ensuite, nous utilisons les chunks résultants pour remplir le contexte de notre invite. Nous utiliserons LangChain pour faciliter les choses :
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)Notre question pour le modèle est : « Comment calculer la médiane d’un tableau ». Même si le contexte que nous lui donnons dépasse largement la limite de jetons, nous avons surmonté cette limitation et obtenu une réponse :
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".Voici une solution astucieuse pour un problème très récent. Au fur et à mesure que les LLM continueront d’évoluer, peut-être que des problèmes comme celui-ci seront résolus sans avoir besoin de ce genre de solutions astucieuses. Cependant, je suis sûr que cette évolution ouvrira la porte à de nouvelles capacités qui pourraient nécessiter d’autres nouvelles solutions astucieuses pour relever les défis qu’elles apporteront.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data