













La disponibilidad de las máquinas virtuales es esencial para garantizar la continuidad del negocio. Cuando los servicios que se ejecutan en máquinas virtuales críticas para el negocio y la misión se vuelven inaccesibles, las empresas pueden perder dinero y la confianza de los clientes. Para restaurar la disponibilidad de las máquinas virtuales inmediatamente después de un fallo, se deben utilizar técnicas de conmutación por error apropiadas.
La conmutación por error a una réplica de máquina virtual puede ser parte de la recuperación ante desastres para restaurar datos y operaciones con una interrupción mínima en los flujos de trabajo regulares. El proceso de conmutación por error de la máquina virtual debe describirse en la continuidad del negocio y recuperación ante desastres (BCDR) de una organización. Veamos con más detalle los tipos y casos de uso de la conmutación por error de la máquina virtual.
¿Qué es una conmutación por error?
La conmutación por error es el proceso de reanudar una máquina virtual (VM) en un sistema secundario (y a veces en una ubicación secundaria) tras un fallo del sistema primario. El sistema secundario contiene todos los datos necesarios para mantener las operaciones comerciales. Un sistema en este contexto puede ser un servidor, una base de datos, una máquina virtual, etc.
En entornos virtuales, hay dos métodos comunes de conmutación por error:
- Utilizar una réplica de máquina virtual (generalmente ubicada en otro servidor de virtualización) se utiliza para realizar la conmutación por error si una VM primaria falla
- Utilizar un clúster de conmutación por error (no se requiere replicación)
La recuperación de funcionamiento necesita menos tiempo para restaurar cargas de trabajo en comparación con la recuperación a partir de un respaldo, y como resultado, se puede alcanzar un objetivo de tiempo de recuperación (RTO) más bajo. Sin embargo, el uso de replicación de VM o agrupación no elimina la necesidad de crear respaldos de VM. Un respaldo (generalmente comprimido) es útil cuando necesita recuperar datos desde el punto de recuperación anterior.
Vamos a revisar la terminología básica de fallo de VM para la recuperación de desastres basada en replicación.
Glosario de fallo de VM
- Fallo: Cualquier problema con hardware o software como resultado de un fallo del sistema, apagón de energía, problemas de red, ataque con criptoware, etc., que tumba a un sistema fuera de línea.
- Sistema primario: El sistema que ejecuta operaciones en vivo en el entorno de producción.
- Sistema secundario: El sistema redundante de standby, que se actualiza regularmente con copias del sistema primario. El sistema secundario puede estar ubicado en el sitio o en una ubicación remota.
- Replicación: El proceso fundamental para preparar el fallo de la VM. La replicación crea una copia exacta, es decir, réplica, de la VM primaria para un momento determinado en tiempo.
- Fallo de VM: El fallo de vuelta es el proceso de cambiar de vuelta hacia el sistema primario desde la VM de réplica después de resolver el incidente.
Tipos de fallo
Hay tres tipos de fallo:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- Un failover no planificado es un failover realizado cuando ocurre una falla inesperada que resulta en una máquina virtual crítica o en todo el sitio primario desconectado. La falla puede ser causada por cualquiera de una serie de desastres naturales, accidentes (un corte de energía), un ataque de malware, u otro incidente. Para un failover no planificado, los hosts y las réplicas deben estar preparados de antemano.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
La Secuencia de Failover
Durante un failover de VM, la secuencia de acciones y el orden de inicio de las VM son esenciales para garantizar la reanudación exitosa de los flujos de trabajo. Deben definirse en la etapa de desarrollo del plan de recuperación ante desastres de su organización. La secuencia debe capturar las dependencias entre los diferentes servicios que se ejecutan en diferentes VMs.
Por ejemplo, la autenticación para algunos servicios y aplicaciones que se ejecutan en VMs puede estar utilizando Active Directory, que se está ejecutando en otra VM. Un servidor de bases de datos podría estar ejecutándose en la primera VM, un servidor de aplicaciones en la segunda y el servidor web en la tercera.
El VM con el Servidor de Directorio Activo debe iniciarse primero. Luego se pueden iniciar los VMs con servicios que utilizan Directorio Activo para la autenticación. El VM con el servidor de base de datos debe iniciarse antes que el VM con el servidor de aplicaciones, porque el servidor de aplicaciones se conecta a la base de datos. Una vez que se hayan iniciado los VMs con el servidor de base de datos y el servidor de aplicaciones, se puede iniciar el VM con el servidor web.
Soluciones Principales de Conmutación por Fallo
Las principales soluciones utilizadas en entornos virtuales son:
- clúster de conmutación por fallo
- conmutación por fallo utilizando réplicas de VM
Vamos a considerar cada una de ellas.
Solución 1. Clúster de conmutación por fallo
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
En el primer diagrama a continuación, se puede ver un clúster en el que ambos hosts (también llamados nodos) están funcionando correctamente. Los VMs se están ejecutando en hosts, y los archivos de VM están ubicados en almacenamiento compartido que es accesible por ambos hosts.
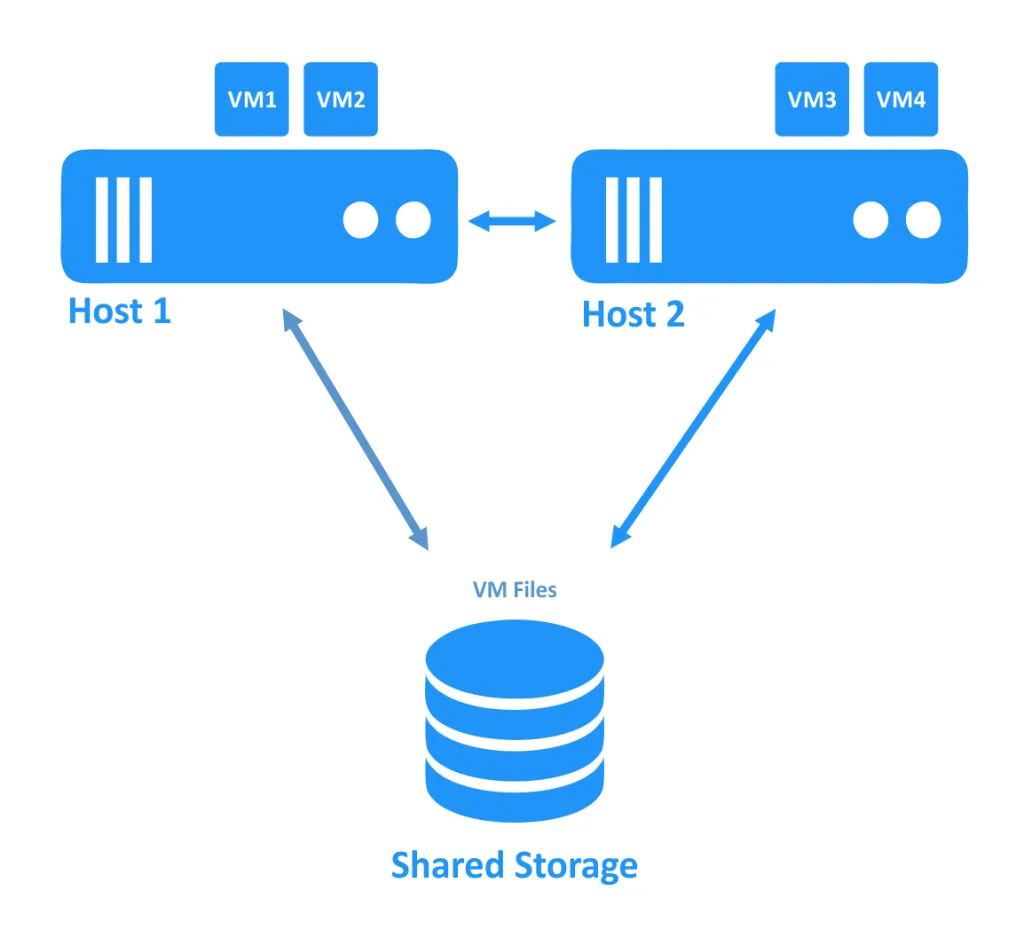
Cuando uno de los hosts se cae, la propiedad de la conexión al VM (que se estaba ejecutando en el nodo desconectado) se transfiere a otro nodo que todavía está en línea. Este es el proceso de conmutación por fallo. Puede ser necesario reiniciar un VM altamente disponible.
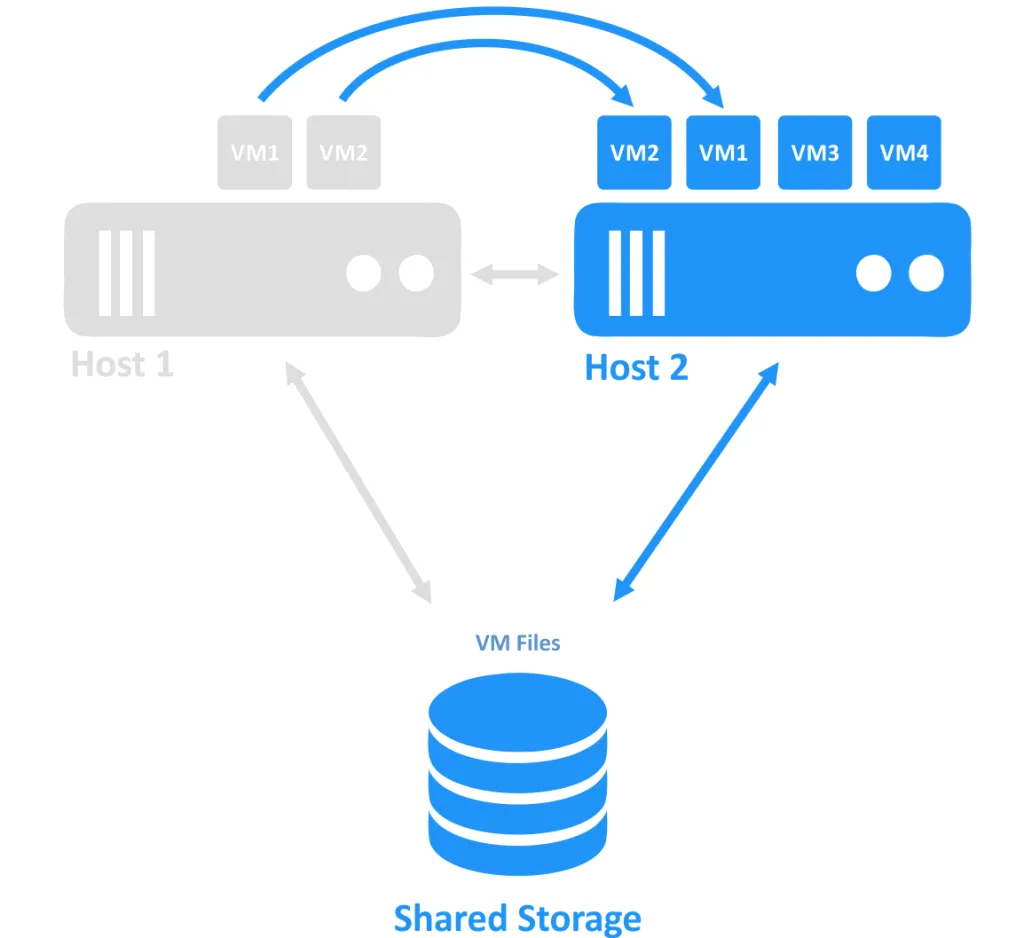
Requisitos de clúster de conmutación por fallo
Los siguientes requisitos deben cumplirse para construir un clúster de conmutación por fallo:
- Almacenamiento compartido conectado a los hosts con una red de alta velocidad dedicada y baja latencia. Se debe utilizar un sistema de archivos en clúster para garantizar que varios hosts puedan acceder simultáneamente a los datos ubicados en el almacenamiento.
- Los hosts en los que se ejecutan las VM deben tener el mismo hardware o, al menos, hardware de la misma familia. Los procesadores deben admitir los mismos conjuntos de instrucciones para garantizar la compatibilidad para que las VM funcionen correctamente después de la migración de un host a otro durante el failover.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
Casos de uso
Los clústeres de failover se utilizan para recuperar VM de fallas del servidor, proporcionando alta disponibilidad para VM críticas. Si uno de los hosts (que se llaman nodos) dentro de un clúster falla, entonces las VM que se ejecutaban en el host fallido migran (failover) a otros hosts saludables. Dependiendo de su configuración, las VM que se transfirieron pueden migrarse de nuevo al host en el que se ejecutaban antes del incidente una vez que se resuelva la falla.
Ventajas
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- Tras el failover, experimentas una pérdida de datos casi nula. El tiempo de inactividad suele limitarse al tiempo que lleva cargar la VM, el sistema operativo (SO) y el software que se ejecuta en la VM.
- La función de Tolerancia a Fallos que se incluye en el clúster de Alta Disponibilidad de VMware asegura el failover de VM sin tiempo de inactividad y sin pérdida de datos.
Desventajas
A failover cluster does not protect against:
- Fallo del software de las máquinas virtuales. Los errores de software o los virus pueden causar un bloqueo del sistema en una máquina virtual.
- Eliminación accidental de archivos dentro de la máquina virtual.
- Fallo del almacenamiento compartido. El clúster falla si el almacenamiento compartido falla. El almacenamiento compartido es un componente crucial del clúster; los discos virtuales que pertenecen a las máquinas virtuales dentro de un clúster se almacenan en el almacenamiento compartido.
- A disaster that makes the whole physical site unavailable.
Para obtener más información sobre qué es un clúster de conmutación por error, lee la guía completa sobre el agrupamiento de VMware.
Solución 2. Conmutación por error utilizando réplicas de máquinas virtuales
La conmutación por error de la máquina virtual basada en réplicas de máquinas virtuales puede ser ejecutada por aplicaciones especializadas, que pueden replicar las máquinas virtuales y arrancar las réplicas cuando sean indicadas por el administrador. Además del software de protección de datos, necesitas hosts ESXi o Hyper-V (dependiendo de tu entorno) que hayan sido preparados de antemano para ejecutar las réplicas de máquinas virtuales cuando las máquinas virtuales de origen fallen.
En el diagrama a continuación, puedes ver dos hosts conectados entre sí a través de la red. Las máquinas virtuales están utilizando los discos de los hosts. Las máquinas virtuales de origen se están ejecutando en el primer host, y las réplicas de máquinas virtuales, que son copias exactas de las máquinas virtuales de origen en un punto particular en el tiempo, se encuentran en el segundo host en un estado apagado.
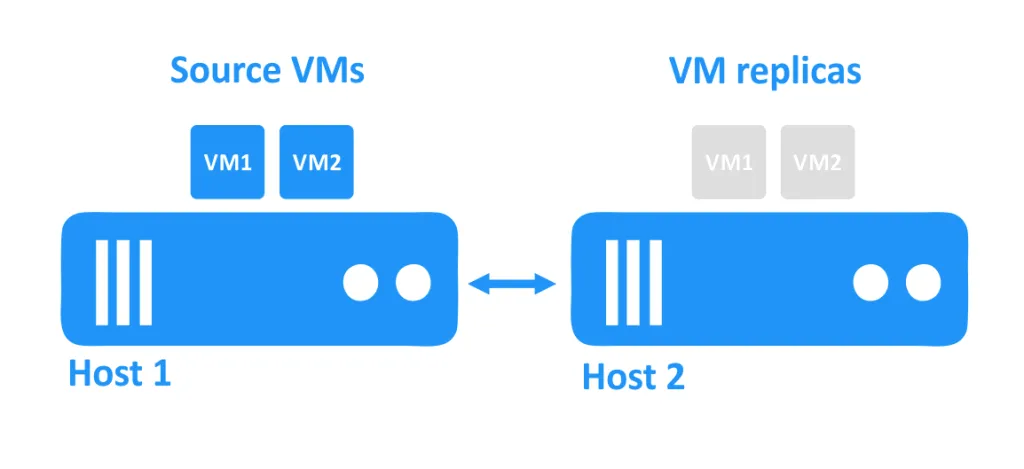
Cuando uno de los hosts se cae, las máquinas virtuales que se estaban ejecutando en ese host también se vuelven inaccesibles. Las réplicas de máquinas virtuales que se encuentran en otro host son entonces encendidas por el administrador.
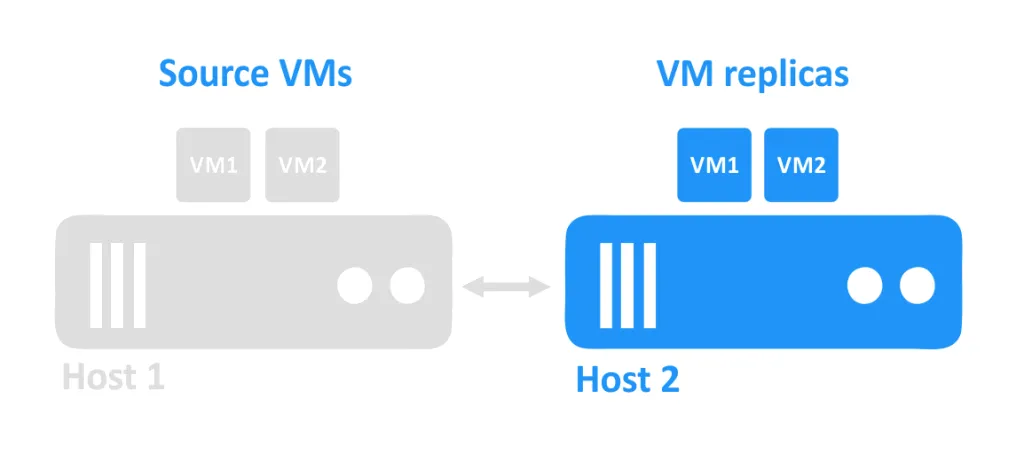
Requisitos de replicación de máquinas virtuales.
Los requisitos básicos para la replicación de MV son dos o más hosts y una solución de replicación. Una MV de origen que se ejecuta en el primer host se replica en el segundo host. La réplica de la MV se encuentra en el segundo host.
Casos de uso
El failover utilizando réplicas de MV se puede utilizar cuando ocurre una falla de hardware o software. Los fallos de host de ESXi o Hyper-V son un ejemplo de falla de hardware. Ejemplos de fallas de software pueden ser actualizaciones fallidas, errores de software, ataques de virus o eliminación accidental de archivos por parte de un usuario.
Ventajas
La principal ventaja del failover de MV a una réplica es la posibilidad de failover a un sitio remoto. Cuando se crea una réplica de MV, los datos copiados de una MV de origen pueden transmitirse a través de una conexión de red (con ancho de banda limitado) a un sitio remoto. El sitio remoto podría estar ubicado en una oficina cercana o al otro lado del mundo. La réplica de la MV también puede estar ubicada en el sitio de producción primario.
Desventajas
La lista de desventajas para un failover utilizando réplicas de MV:
- Existe un breve período de inactividad entre una falla y el inicio de la réplica en el segundo host.
- El failover debe ser iniciado manualmente.
- Los datos escritos desde la última replicación pueden perderse durante un failover no planificado. La replicación de MV a menudo no es un proceso en tiempo real (sincrónico), ya que la replicación síncrona coloca una carga significativa en los recursos. La replicación generalmente se realiza a intervalos regulares dependiendo de la configuración elegida.
- La configuración de red de las MV debe cambiarse (a menudo) al ocurrir un failover a otro sitio. Las redes de las MV del sitio remoto pueden diferir de las redes del sitio principal. Por lo tanto, las direcciones IP también podrían ser diferentes, y deben ser verificadas y modificadas junto con otras configuraciones de red durante un failover.
Clustering vs Replicación para Failover de MV
| Failover con clustering | Failover utilizando una réplica | |
| Propósito | Disponibilidad alta | Recuperación ante desastres |
| Protección contra | Solo fallas de hardware | Fallas de hardware y software |
| Administración | Iniciado automáticamente | Iniciado manualmente |
| Duración de inactividad (RTO) | El failover es más rápido, por lo que la inactividad de la MV es corta (RTO corto) | El failover lleva más tiempo, por lo que la inactividad de la MV es más larga |
| Requisitos | Más requisitos | Menos requisitos |
| Precio de la solución | Las soluciones de clustering suelen ser más costosas | Las soluciones de replicación son más rentables |
| Pérdida de datos (RPO) | Pérdida de datos cercana a cero (RPO muy bajo) | La pérdida de datos depende de la frecuencia de replicación |
Uso combinado de clústers y réplicas para el recuperación ante fallos de VM
Las soluciones de recuperación de clústers y réplicas a menudo se consideran alternativas, sin embargo, pueden utilizarse para complementarse. Veamos algunos ejemplos de cómo el uso de ambas soluciones de recuperación puede ayudar a proteger las VM contra fallos tanto a nivel de servidor como a nivel de sitio.
- Ejemplo 1: Puedes replicar las VM que se ejecutan en un clúster a un anfitrión en un sitio remoto. Además, puedes replicar las VM que se ejecutan en un clúster a otro clúster. Así, si un anfitrión falla, el clúster de recuperación mantiene esas VM en línea. Si todo el sitio experimenta una interrupción, entonces puedes recuperar a las réplicas de VM almacenadas en un sitio remoto.
- Ejemplo 2: Un virus daña archivos dentro de algunas VM. Un clúster de recuperación no puede proteger contra esos fallos. Sin embargo, si tienes réplicas de VM con varios puntos de recuperación, puedes restaurar cada VM a un momento anterior antes de que sus archivos fuesen dañados o eliminados.
El uso de la solución de NAKIVO para la recuperación automatizada de VMware VM a réplica
NAKIVO Backup & Replicación es una solución de copia de seguridad y recuperación de desastres que puede proteger VMs en funcionamiento dentro de un clúster, replicar VMs, fallar sobre réplicas y orquestar secuencias complejas de DR. Se admiten clústeres así como hosts ESXi o Hyper-V independientes como puntos de origen y destino para la replicación. La solución automáticamente rastrea el anfitrión en el que reside una VM para poder replicar esa VM. Esto es útil porque las VMs pueden migrar de un anfitrión a otro dentro de un clúster después de eventos de fallo en reversa o de balanceo de carga (un clúster se configura generalmente en conjunto con el balanceo de carga). Es por eso que el software que utilizas para replicar una VM de un clúster debe ser capaz de rastrear el anfitrión en el que reside la VM.
La solución NAKIVO puede cambiar automáticamente los ajustes de red de la VM en caso de fallo; simplemente use las características de Mapeo de Red y Re-IP al configurar un trabajo de replicación o de fallo.
Consideremos un ejemplo de Fallo Automático de VM (con Mapeo de Red y Re-IP) en NAKIVO Backup & Replicación. Empezaremos creando una réplica de VM.
Configuración de replicación necesaria para el fallo de VM
En el panel de trabajos, haga clic en Crear > Trabajo de replicación de VMware vSphere si dispone de un entorno virtual de VMware. Tenga en cuenta que puede crear un trabajo de replicación para una instancia de Microsoft Hyper-V o una instancia de Amazon EC2 de la misma manera.
Se inicia el asistente de trabajo de replicación.
- Seleccione las máquinas virtuales que desea replicar. En este ejemplo, la VM Server2019, que está ejecutando el sistema operativo Windows Server 2019 como sistema operativo invitado, será replicada. Haga clic en Siguiente.
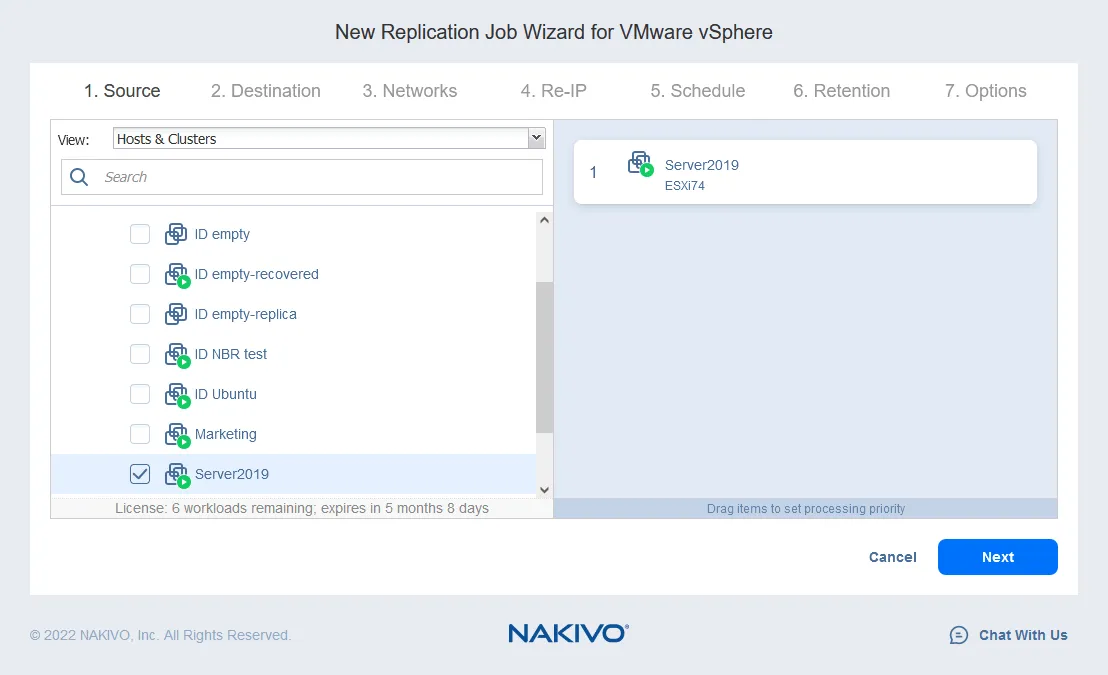
- Seleccione un host de destino para que la réplica de la VM se ejecute (en nuestro caso, 10.10.10.90). Seleccione el almacén de datos montado en el host seleccionado para ubicar los archivos de la VM. Haga clic en Siguiente.
- Puede configurar la asignación de red y las opciones de Re-IP al configurar un trabajo de replicación o un trabajo de failover. En este recorrido, la asignación de red y Re-IP se configurarán más tarde cuando se configure el trabajo de failover. Por lo tanto, puede omitir este paso por el momento y simplemente hacer clic en Siguiente.
- La configuración de re-IP se explicará durante la configuración del trabajo de conmutación por error de la máquina virtual en este tutorial. Haz clic en Siguiente.
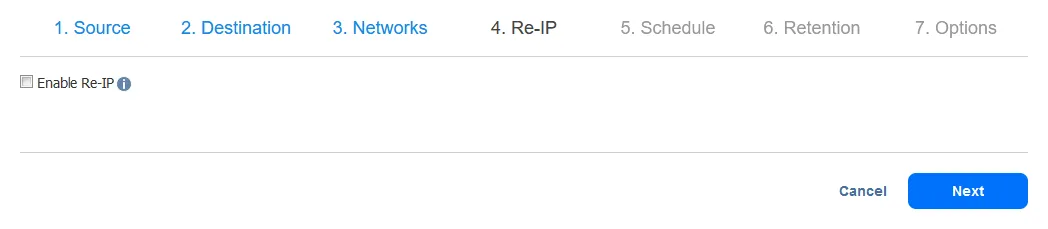
- Selecciona tus ajustes de programación. Haz clic en Siguiente cuando hayas terminado.
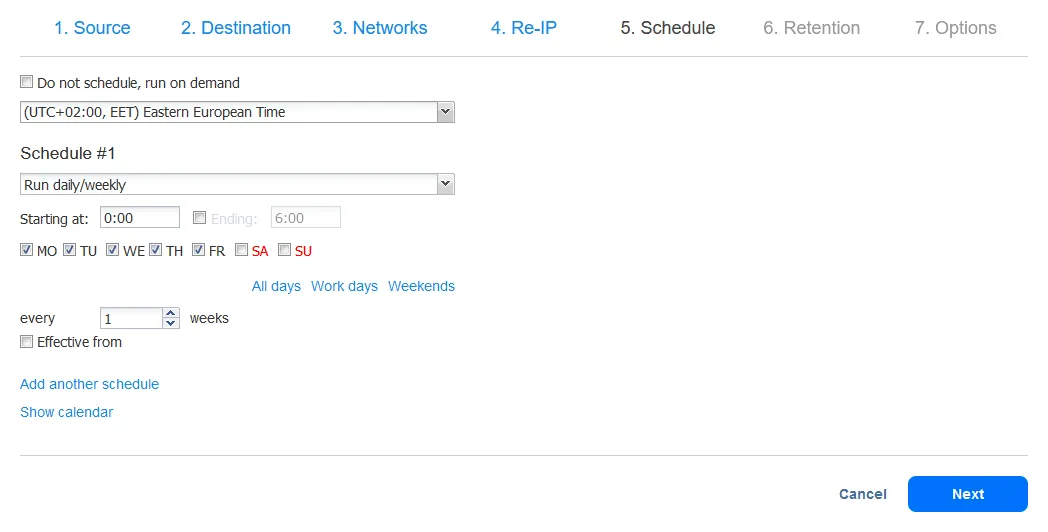
- Establece los ajustes de retención. Recuerda que puedes configurar la política de retención abuelo-padre-hijo en este paso. Haz clic en Siguiente.
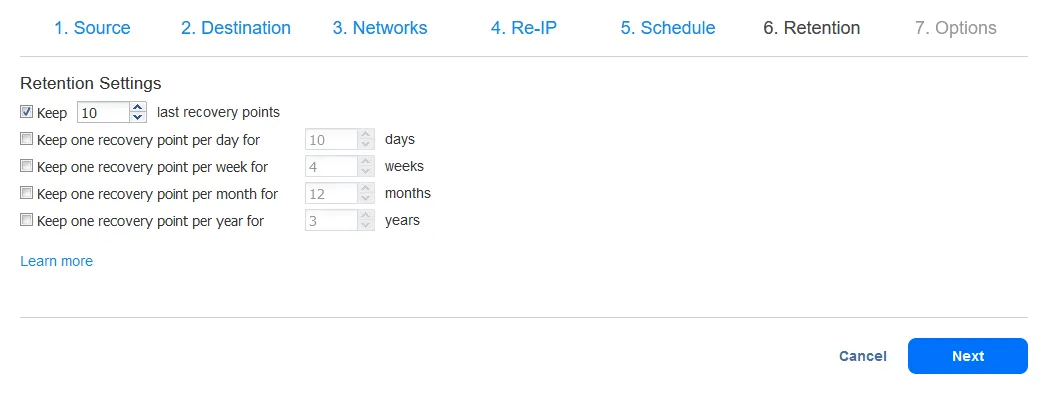
- Seleccione las opciones del trabajo de replicación y haga clic en Finalizar o en el botón Finalizar y Ejecutar. Espere mientras se crea la réplica.
Configurando el failover de la máquina virtual
Ahora que tiene una réplica de VM creada, puede realizar un failover de VM a esta réplica.
En la página de inicio del panel de control, haga clic en Recuperar > Recuperación Completa de VMware (failover de réplica de VM). Se abrirá el Asistente para Nuevo Trabajo de Failover.
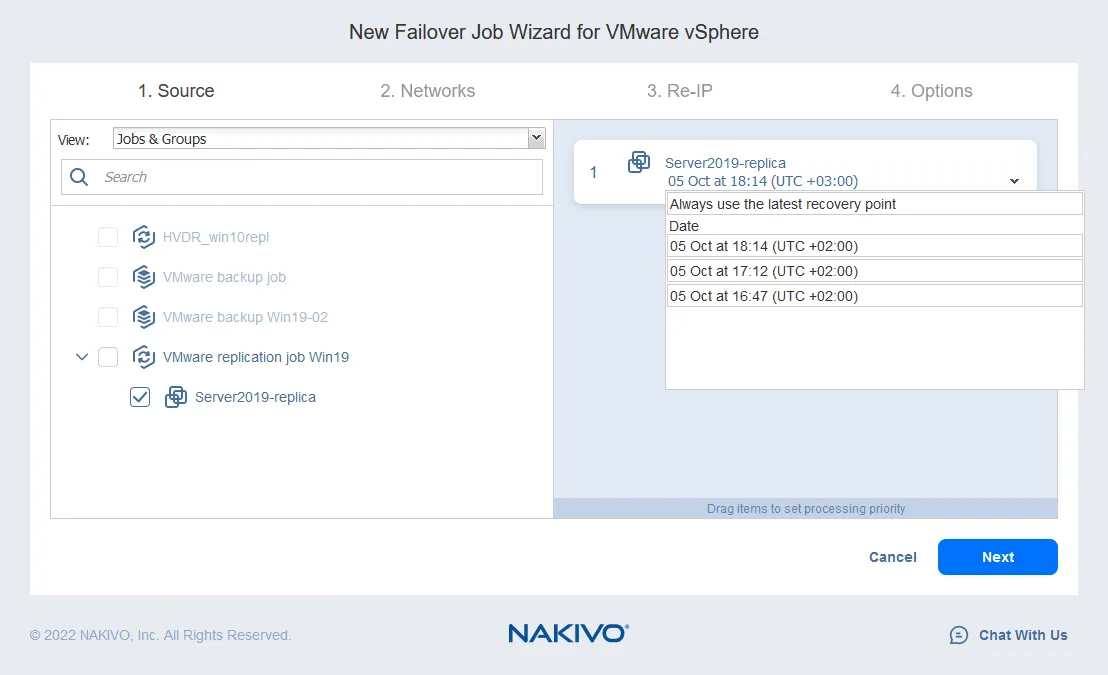
- En el panel izquierdo, seleccione la réplica de VM que se usará para el failover. En este recorrido, se selecciona la Server2019-replica, que acaba de ser creada. En el panel derecho, seleccione un punto de recuperación. El último punto de recuperación se selecciona de forma predeterminada en la solución. Haga clic en Siguiente.
- El mapeo de red te ayuda a cambiar la red a la que está conectada la VM. Es probable que los hosts ESXi de origen y destino tengan configuraciones de conmutador virtual diferentes. Dado que una réplica de VM es una copia exacta de la VM de origen, las redes virtuales a las que está conectada la VM de origen se conservan en la réplica de VM.
Generalmente, debes verificar la configuración de red de una réplica de VM y cambiar la red manualmente. NAKIVO Backup & Replication puede mapear automáticamente la red de origen a una red de destino. Solo necesitas configurar el mapeo de red al configurar el trabajo de replicación o failover.
Para habilitar el mapeo de red, selecciona la casilla de verificación. Si has creado previamente una regla de mapeo de red, puedes hacer clic en Agregar mapeo existente. Si no hay reglas de mapeo de red, haz clic en Crear nuevo mapeo.
Para crear una nueva regla de mapeo de red, selecciona la red de origen y la red de destino. La red de origen es la red a la que está conectada la VM de origen. La red de destino es la red a la que debe estar conectada la réplica de VM.
Nota: El nombre de la red de la VM no es el mismo que la dirección IP o la dirección de red.
Haz clic en Guardar para guardar la regla de mapeo de red, y luego haz clic en Siguiente para continuar con la configuración.
La función de Re-IP te permite cambiar la configuración de IP de la réplica de VM. Se puede utilizar para direcciones IP estáticas. Selecciona la casilla de verificación Habilitar Re-IP si deseas habilitar esta opción y luego crea una regla de Re-IP o agrega una regla existente. Haz clic en Crear nueva regla si no hay reglas creadas anteriormente. Aparecerá un menú emergente.
La configuración de la VM de origen son la dirección IP y la máscara de red que deben cambiarse.
La configuración de destino son los ajustes que se aplicarán a la réplica de VM cuando ocurra el failover. En este ejemplo, el carácter [*] cubre el último octeto. El [*] significa cualquier número del 1 al 254. Si las direcciones IP de origen son, por ejemplo, 10.10.10.1, 10.10.10.96 y 10.10.10.222, las direcciones de destino serían 192.168.10.1, 192.168.10.96 y 192.168.10.222 respectivamente. El último octeto de la dirección IP se conserva.
Haz clic en Guardar para guardar tu regla de Re-IP y proceder.
Después de agregar la regla de Re-IP, tu pantalla debería verse así:
Ahora selecciona las VM para las cuales se deben aplicar las reglas de Re-IP. El trabajo de failover en este ejemplo contiene solo una réplica de VM, así que selecciona la casilla de verificación correspondiente.
Luego selecciona las credenciales para cada VM. Haz clic en Gestionar credenciales > Agregar credenciales para agregar nuevas credenciales. Las credenciales agregadas pueden seleccionarse de la lista desplegable.
Nota: Las credenciales son necesarias para que NAKIVO Backup & Replication acceda a la configuración de red del sistema operativo dentro de la VM y aplique el script que cambia esos ajustes. VMware Tools debe estar instalado en las VM de VMware vSphere, e Integration Services de Hyper-V debe estar instalado en las VM de Microsoft Hyper-V.
Cuando hayas configurado todos estos ajustes, haz clic en Siguiente.
Ahora, configura las opciones del trabajo de failover de VM. Puedes seleccionar la casilla de verificación Apagar las VM de origen. Puede ser útil para evitar conflictos de direcciones IP si tanto las VM de origen como las réplicas utilizan la misma red o tienen las mismas direcciones IP. Después de configurar todas las opciones, haz clic en Finalizar y ejecutar.
Espera hasta que el trabajo de failover de VM esté completo.
Ahora puedes asegurarte de que la réplica de VM esté funcionando. Ve a Configuración > Inventario y haz clic en el botón Actualizar todo. Después de actualizar, puedes ver que la VM Server2019-replica ya está ejecutándose en el host ESXi de destino. También puedes gestionar las credenciales, las reglas de mapeo de red y las reglas de Re-IP desde esta página (la página de Inventario).
Conclusión
El failover de VM es útil para escenarios de recuperación ante desastres con muchas máquinas virtuales o para recuperar incluso una sola VM para garantizar la continuidad operativa y la alta disponibilidad. Sin embargo, es importante entender que cualquier plan de recuperación ante desastres debe estar acompañado de una estrategia de copia de seguridad sólida para una protección de datos más confiable y eficiente.
Considera el uso de NAKIVO Backup & Replication, una solución de protección de VM rápida, confiable y asequible, para proteger las VM utilizando el método de failover a réplica. La solución también admite copias de seguridad y recuperación granular para entornos virtuales, físicos, en la nube y de SaaS desde una interfaz web centralizada.