













Estatuto de Problema
El “por qué” de esta solución AI es muy importante y prevalece en varios campos.
Imagina que tienes varios documentos PDF escaneados:
- Donde los clientes hacen algunas selecciones manuales, agregar firma/fechas/información del cliente
- Tienes varias páginas de documentación escrita que han sido escaneadas y buscas una solución que obtenga texto de estos documentos
O
- Buscas simplemente una vía respaldada por AI que proporcione un mecanismo interactivo para consultar documentos que no tienen un formato estructurado
Lidiar con documentos escaneados/mixtos/sin estructurar puede ser complicado, y extraer información crucial de ellos podría ser manual, por lo tanto, propenso a errores y complejo.
La solución de abajo aprovecha el poder de OCR (Reconocimiento Óptico de Caracteres) y LLM (Modelos de Lenguaje Grande) para obtener texto de tales documentos y consultarlos para obtener información estructurada de confianza.
Arquitectura de Alta Nivel
Interfaz de Usuario
- La interfaz de usuario permite subir documentos PDF/escaneados (se puede expandir aún más a otros tipos de documentos).
- Streamlit se está aprovechando para la interfaz de usuario:
- Es un marco de Python de código abierto y extremadamente fácil de usar.
- Mientras se realizan cambios, reflejan en las aplicaciones en ejecución, haciendo de esto un mecanismo de prueba rápido.
- El soporte de la comunidad para Streamlit es bastante fuerte y está creciendo.
- Cadena de conversación:
- Esto es fundamental para incorporar chatbots que pueden responder a preguntas secundarias y proporcionar historial de chat.
- Usamos LangChain para la interfaz con el modelo de IA que utilizamos; para este proyecto, hemos probado con OpenAI y Mistral AI.
Servicio de Backend
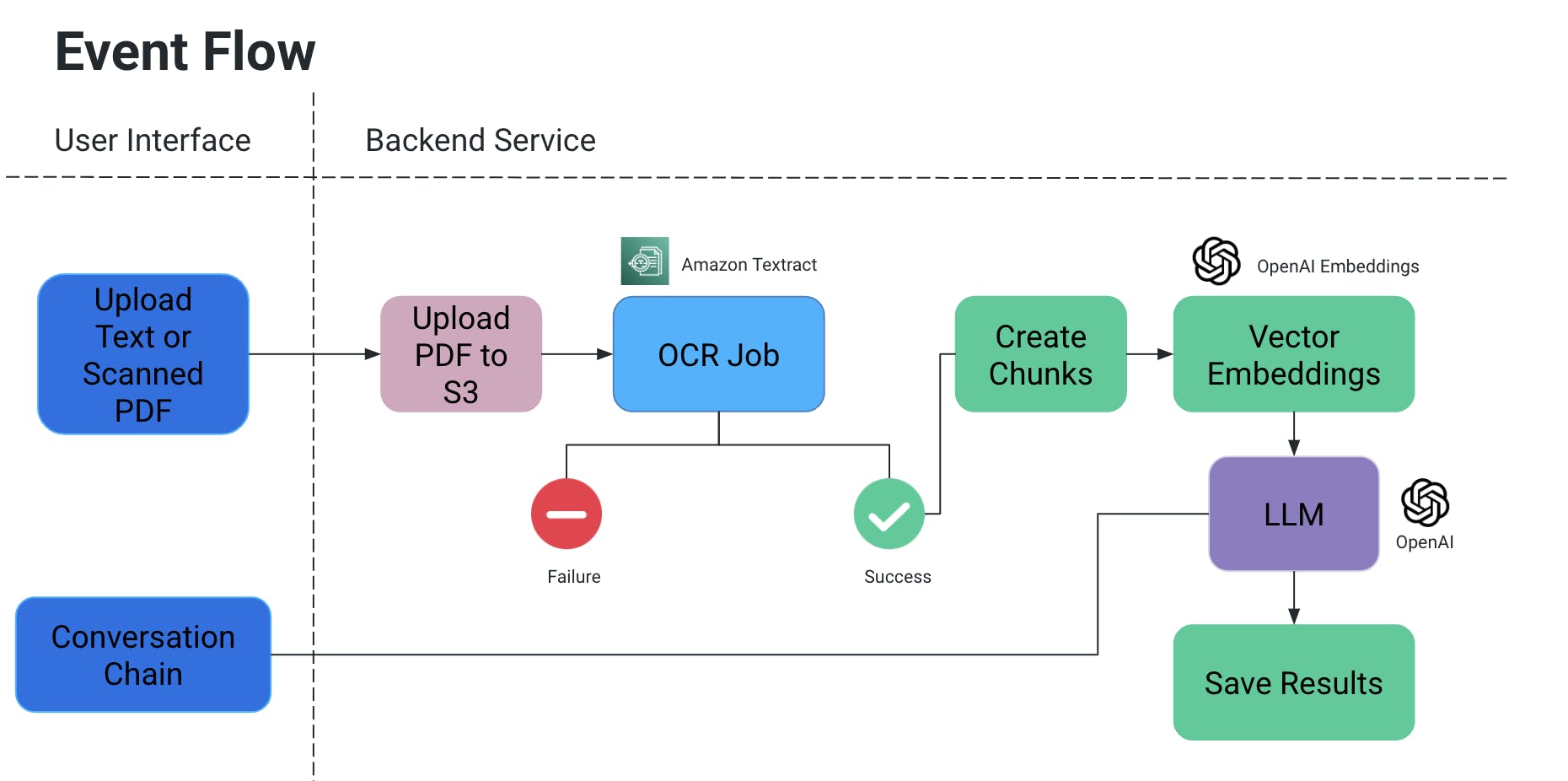
Flujo de eventos
- El usuario sube un documento PDF/escaneado, que a continuación se sube a una cesta S3.
- Un servicio OCR luego recupera este archivo de la cesta S3 y lo procesa para extraer texto de este documento.
- Se crean trozos de texto a partir de la salida anterior, y se crean vectorias asociadas para ellos.
- Esto es muy importante porque no quieres que se pierda el contexto cuando se dividen los trozos: podrían dividirse en medio de una oración, sin alguna puntuación el significado podría perderse, etc.
- Así que para contrarrestarlo, creamos trozos superpuestos.
- El gran modelo de lenguaje que utilizamos toma estas incrustaciones como entrada y tenemos dos funcionalidades:
- Generar una salida específica:
- Si tenemos un tipo específico de información que necesita ser extraída de los documentos, podemos proporcionar consultas en código al modelo de IA, obtener datos y almacenarlos en un formato estructurado.
- Evitamos las alucinaciones de la IA añadiendo explícitamente consultas in-code con condiciones para no inventar ciertos valores y utilizar sólo el contexto del documento.
- Podemos almacenarlo como un archivo en S3/localmente O escribirlo en una base de datos.
- Chat
- Aquí proporcionamos la vía para que el usuario final inicie un chat con la IA para obtener información específica en el contexto del documento.
- Generar una salida específica:
Tarea de OCR
- Estamos utilizando Amazon Textract para la reconocición óptica de estos documentos.
- Funciona muy bien con documentos que también tienen tablas/formularios, etc.
- Si estás trabajando en una POC, aprovechar la versión gratuita de este servicio.
Embeddings vectoriales
- Una manera muy fácil de entender las representaciones vectoriales es traducir palabras o frases en números que capturan el significado y las relaciones de este contexto
- Imagina que tienes la palabra “anillo”, que es un adorno: en términos de la palabra misma, una de sus coincidencias cercanas es “cantar”. Sin embargo, en términos del significado de la palabra, preferiríamos que se ajustara a algo como “joyería”, “dedo”, “piedras preciosas”, o quizás algo como “cuello”, “círculo”,等等.
- Así que al crear la representación vectorial de “anillo”, básicamente estamos llenándola de montones de información sobre su significado y relaciones.
- Esta información, junto con las representaciones vectoriales de otras palabras/frases en un documento, asegura que se elija el significado correcto de la palabra “anillo” en contexto.
- Usamos OpenAIEmbeddings para crear representaciones vectoriales.
LLM
- Hay múltiples modelos de lenguaje grande que se pueden usar para nuestro escenario.
- En el marco de este proyecto, se ha realizado una prueba con OpenAI y Mistral AI.
- Leer más aquí sobre las API Keys para OpenAI.
- Para MistralAI, se ha aprovechado de HuggingFace.
Casos de Uso y Pruebas
Realizamos las siguientes pruebas:
- Se leyeron firmas y fechas/textos escritos a mano utilizando OCR.
- Opciones seleccionadas a mano en el documento
- Selecciones digitales realizadas sobre el documento
- Se procesó datos no estructurados para obtener contenido tabular (agregar a archivo de texto/BD, etc.)
Escala futura
Podemos ampliar aún más los casos de uso para el proyecto mencionado anteriormente para incorporar imágenes, integrar con repositorios de documentación como Confluence/Drive, etc., para extraer información relacionada con un tema específico de varias fuentes, agregar una vía más fuerte para realizar un análisis comparativo entre dos documentos, etc.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data