













In der Ära der Echtzeitdaten ist die Fähigkeit, Streaming-Informationen zu verarbeiten und zu analysieren, für Unternehmen entscheidend geworden. Apache Kafka, eine leistungsstarke verteilte Event-Streaming-Plattform, steht oft im Mittelpunkt dieser Echtzeit-Pipelines. Der Umgang mit rohen Datenströmen kann jedoch komplex sein. Hier kommt Streaming SQL ins Spiel: Es ermöglicht den Nutzern, Kafka-Themen mit der Einfachheit von SQL abzufragen und zu transformieren.
Was ist Streaming SQL?
Streaming SQL bezieht sich auf die Anwendung von Structured Query Language (SQL) zur Verarbeitung und Analyse von Daten in Bewegung. Im Gegensatz zu traditionellem SQL, das statische Datensätze in Datenbanken abfragt, verarbeitet Streaming SQL kontinuierlich Daten, während sie durch ein System fließen. Es unterstützt Operationen wie Filtern, Aggregieren, Verbinden und Fensterung in Echtzeit.
Mit Kafka als Rückgrat der Echtzeitdaten-Pipelines ermöglicht Streaming SQL den Nutzern, Kafka-Themen direkt abzufragen, was die Analyse und Nutzung der Daten erleichtert, ohne komplexen Code schreiben zu müssen.
Schlüsselelemente von Streaming SQL auf Kafka
1. Apache Kafka
Kafka speichert und streamt Echtzeitevents über Themen. Produzenten schreiben Daten in Themen, und Verbraucher abonnieren sie, um diese Daten zu verarbeiten oder zu analysieren. Die Haltbarkeit, Skalierbarkeit und Fehlertoleranz von Kafka machen es ideal für Streaming-Daten.
2. Kafka Connect
Kafka Connect erleichtert die Integration mit externen Systemen wie Datenbanken, Objektspeichern oder anderen Streaming-Plattformen. Es ermöglicht eine nahtlose Erfassung oder den Export von Daten zu/von Kafka-Themen.
3. Streaming-SQL-Engines
Verschiedene Tools ermöglichen Streaming-SQL auf Kafka, darunter:
- ksqlDB: Eine auf Kafka Streams aufgebaute, Kafka-native Streaming-SQL-Engine.
- Apache Flink SQL: Ein vielseitiges Stream-Processing-Framework mit erweiterten SQL-Funktionen.
- Apache Beam: Bietet SQL für die Stapel- und Stream-Verarbeitung und ist kompatibel mit verschiedenen Runnern.
- Spark Structured Streaming: Unterstützt SQL für die Echtzeit- und Stapeldatenverarbeitung.
Wie funktioniert Streaming-SQL?
Streaming-SQL Engines verbinden sich mit Kafka, um Daten aus Themen zu lesen, diese in Echtzeit zu verarbeiten und Ergebnisse an andere Themen, Datenbanken oder externe Systeme auszugeben. Der Prozess beinhaltet typischerweise die folgenden Schritte:
- Definition von Datenströmen: Benutzer definieren Ströme oder Tabellen, indem sie Kafka-Themen als Quellen angeben.
- Ausführen von Abfragen: SQL-Abfragen werden ausgeführt, um Operationen wie Filterung, Aggregation und Verknüpfung von Strömen durchzuführen.
- Ergebnisse ausgeben: Die Ergebnisse können zurück in Kafka-Themen oder externe Ziele wie Datenbanken oder Dashboards geschrieben werden.
Flussdiagramm
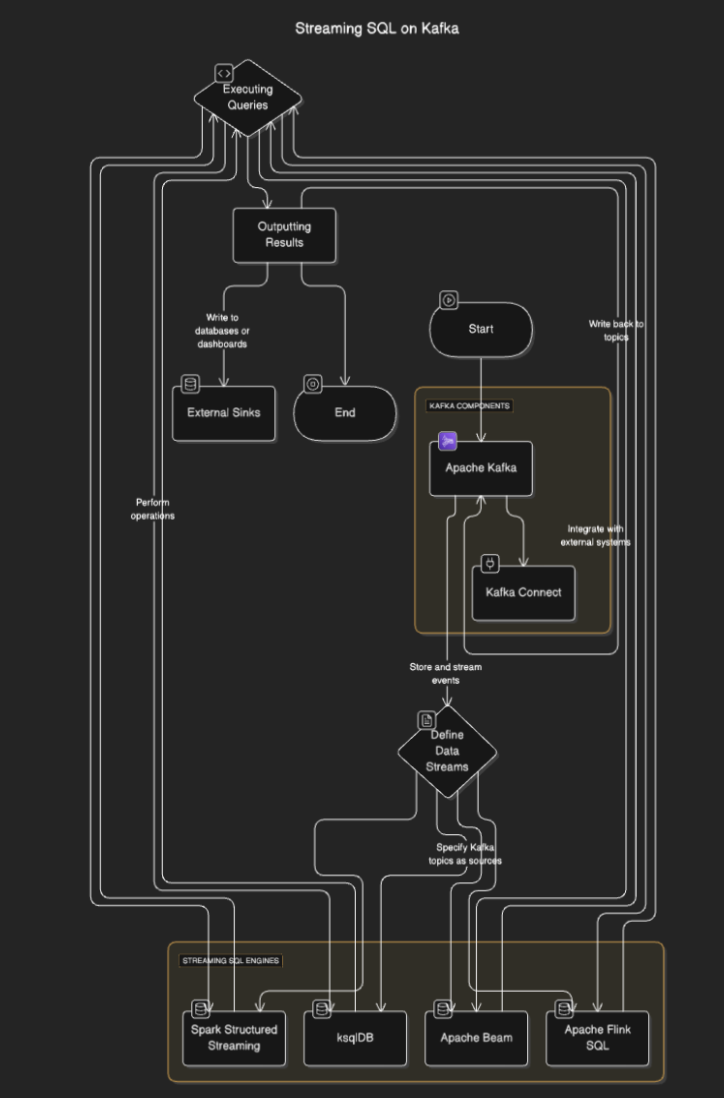
Streaming-SQL-Tools für Kafka
ksqlDB
ksqlDB ist speziell für Kafka entwickelt und bietet eine SQL-Schnittstelle zur Verarbeitung von Kafka-Themen. Es vereinfacht Operationen wie das Filtern von Nachrichten, das Verknüpfen von Streams und das Aggregieren von Daten. Zu den wichtigsten Funktionen gehören:
- Deklarative SQL-Abfragen: Definieren Sie Echtzeit-Transformationen ohne Codierung.
- Materialisierte Ansichten: Speichern Sie Abfrageergebnisse für schnelle Nachschlagevorgänge.
- Kafka-Nativ: Optimiert für die Verarbeitung mit geringer Latenz.
Beispiel:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink ist ein leistungsstarkes Stream-Verarbeitungs-Framework, das SQL-Funktionen für Batch- und Streaming-Daten bietet. Es unterstützt komplexe Operationen wie die Verarbeitung von Ereigniszeiten und erweiterte Fensterfunktionen.
Beispiel:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark Structured Streaming
Spark Structured Streamingermöglicht SQL-basierte Streamverarbeitung und integriert sich gut mit anderen Spark-Komponenten. Es eignet sich ideal für komplexe Datenpipelines, die Stapel- und Streamverarbeitung kombinieren.
Beispiel:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
Anwendungsfälle für Streaming-SQL auf Kafka
- Echtzeitanalyse. Überwachen von Benutzeraktivitäten, Verkäufen oder IoT-Sensordaten mit Live-Dashboards.
- Datentransformation. Bereinigen, filtern oder anreichern von Daten, während sie durch Kafka-Themen fließen.
- Betrugserkennung. Identifizieren verdächtiger Transaktionen oder Muster in Echtzeit.
- Dynamische Warnungen. Auslösen von Warnungen, wenn bestimmte Schwellenwerte oder Bedingungen erfüllt sind.
- Datenpipeline-Anreicherung. Verknüpfen von Streams mit externen Datensätzen, um angereicherte Datenausgaben zu erstellen
Vorteile von Streaming-SQL auf Kafka
- Vereinfachte Entwicklung. SQL ist vielen Entwicklern vertraut und reduziert die Lernkurve.
- Echtzeitverarbeitung. Ermöglicht sofortige Einblicke und Maßnahmen auf Streaming-Daten.
- Skalierbarkeit. Die Nutzung der verteilten Architektur von Kafka gewährleistet Skalierbarkeit.
- Integration. Integriert sich einfach in bestehende Kafka-basierte Pipelines.
Herausforderungen und Überlegungen
- State-Management. Komplexe Abfragen erfordern möglicherweise die Verwaltung großer Zustände, was sich auf die Leistung auswirken könnte.
- Abfrageoptimierung. Stellen Sie sicher, dass Abfragen effizient sind, um Hochdurchsatzströme zu bewältigen.
- Tool-Auswahl. Wählen Sie die richtige SQL-Engine basierend auf Ihren Anforderungen (z.B. Latenz, Komplexität).
- Fehlertoleranz. Streaming-SQL-Engines müssen Knotenausfälle behandeln und die Datenkonsistenz sicherstellen.
Fazit
Streaming-SQL auf Kafka ermöglicht es Unternehmen, Echtzeitdaten mit der Einfachheit von SQL zu nutzen. Tools wie ksqlDB, Apache Flink und Spark Structured Streaming machen es möglich, robuste, skalierbare und latenzarme Datenpipelines ohne tiefgehende Programmierkenntnisse zu erstellen.
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka