













Problemstellung
Die „Warum“-Frage bei dieser AI-Lösung ist sehr wichtig und wird in vielen Bereichen angewendet.
Stellen Sie sich vor, Sie haben mehrere Scan-PDF-Dokumente:
- Wo Kunden manuelle Auswahlen treffen, Unterschrift/Daten/Kundeninformationen hinzufügen
- Sie haben mehrere Seiten geschriebene Dokumente, die Scan- und Textauszüge gewünscht sind
ODER
- Sie suchen einfach eine von AI unterstützte Möglichkeit, um auf nicht strukturierte Dokumente zuzugreifen
Behandlung von gescannten/gemischten/unstrukturierten Dokumenten kann schwierig sein, und die Extraktion wichtiger Informationen kann manuell sein, daher fehleranfällig und kompliziert.
Die untenstehende Lösung nutzt die Leistung von OCR (optisches Zeichenerkennung) und LLM (große Sprachmodelle), um Text aus solchen Dokumenten zu erhalten und sie abzufragen, um strukturiert vertrauenswürdige Informationen zu erhalten.
Hoheitsarchitektur
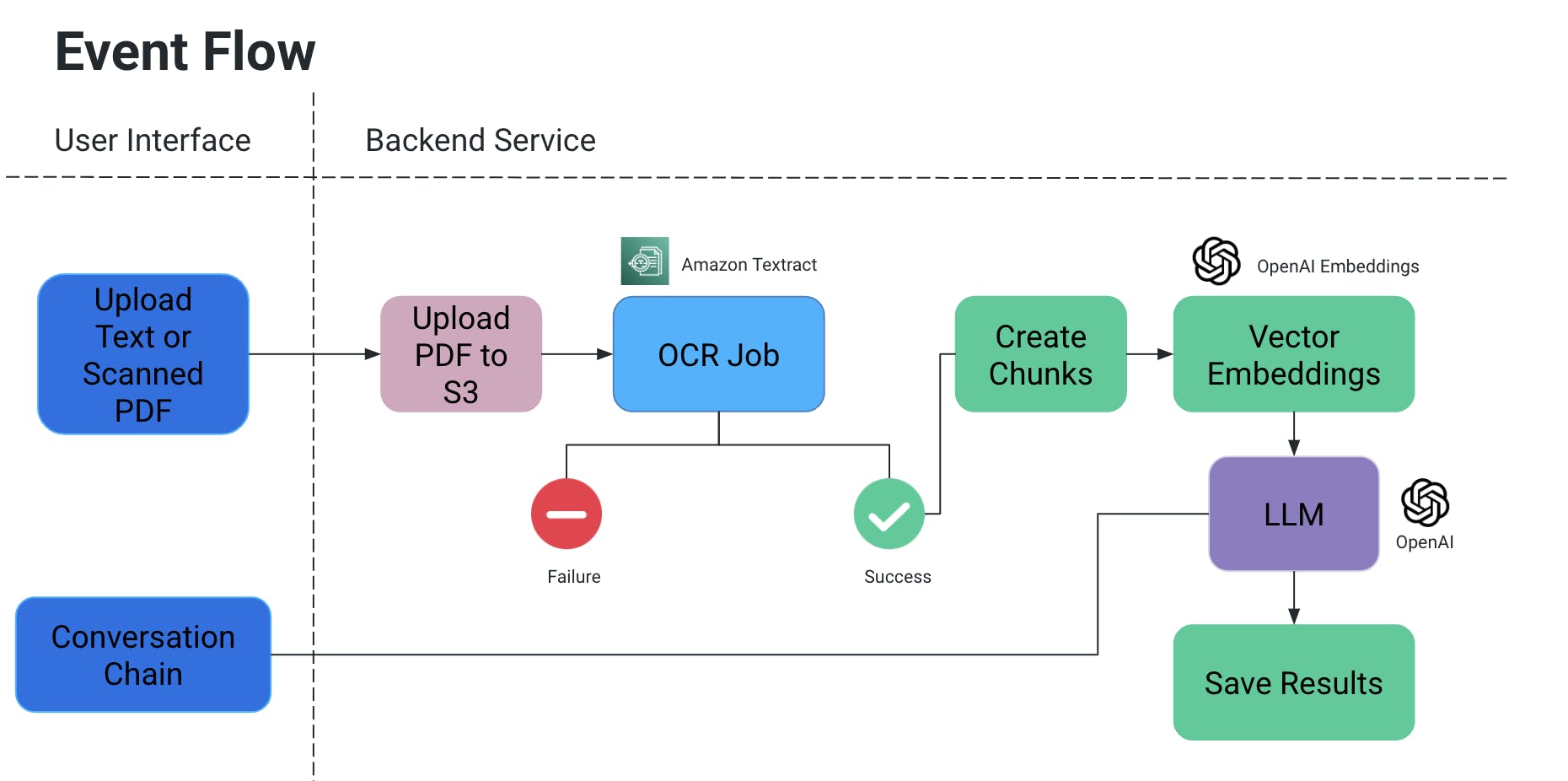
Benutzeroberfläche
- Die Benutzeroberfläche ermöglicht das Hochladen von PDF- und gescannten Dokumenten (sie kann auch auf andere Dokumenttypen erweitert werden).
- Streamlit wird für die Benutzeroberfläche verwendet:
- Es handelt sich um ein Open-Source-Python-Framework und ist extrem einfach zu bedienen.
- Wenn Änderungen vorgenommen werden, spiegeln sie sich in den laufenden Anwendungen wider, was dies zu einem schnellen Testmechanismus macht.
- Die Community-Unterstützung für Streamlit ist ziemlich stark und wächst weiter.
- Konversationskette:
- Dies ist im Wesentlichen erforderlich, um Chatbots einzubinden, die Folgefragen beantworten und den Chatverlauf bereitstellen können.
- Wir nutzen LangChain als Schnittstelle zu dem von uns verwendeten KI-Modell; für dieses Projekt haben wir mit OpenAI und Mistral AI getestet.
Backenddienst
Ereignisschlauf
- Der Benutzer uploadt ein PDF/scannertes Dokument, das anschließend in ein S3-Bucket hochgeladen wird.
- Ein OCR-Dienst holt dann diese Datei aus dem S3-Bucket und verarbeitet es, um Text aus diesem Dokument herauszukriegen.
- Aus dem obigen Ergebnis werden Textabschnitte erstellt und für sie werden zugehörige Vektormodellierungskoordinaten erstellt.
- Das ist jetzt sehr wichtig, weil du beim Zerteilen der Teile kein Kontext verlieren willst: sie könnten mitten in einer Phrase geteilt werden, ohne einige Zeichen könnte die Bedeutung verloren gehen, usw.
- Um dies zu kompensieren, erstellen wir Überschneidungsteile.
- Das große Sprachmodell, das wir verwenden, nimmt diese Einbettungen als Eingabe, und wir haben zwei Funktionalitäten:
- Generieren Sie eine spezifische Ausgabe:
- Wenn wir eine bestimmte Art von Informationen aus Dokumenten herausziehen müssen, können wir dem KI-Modell eine Abfrage im Code bereitstellen, Daten erhalten und sie in einem strukturierten Format speichern.
- Vermeiden Sie KI-Halluzinationen, indem Sie explizit In-Code-Abfragen mit Bedingungen hinzufügen, um bestimmte Werte nicht zu erfinden und nur den Kontext des Dokuments zu verwenden.
- Wir können es als Datei in S3/lokal speichern ODER in eine Datenbank schreiben.
- Chat
- Hier bieten wir die Möglichkeit für den Endnutzer, einen Chat mit der KI zu initiieren, um spezifische Informationen im Kontext des Dokuments zu erhalten.
- Generieren Sie eine spezifische Ausgabe:
OCR-Auftrag
- Wir verwenden Amazon Textract für die optische Erkennung dieser Dokumente.
- Es funktioniert sehr gut mit Dokumenten, die auch Tabellen/Formulare usw. enthalten.
- Wenn du an einer POC arbeitest, nutze die kostenlose Ebene für diesen Dienst.
Vektormodellierung
- Ein sehr einfacher Weg, um Vektor Embeddings zu verstehen, besteht darin, Wörter oder Sätze in Zahlen zu übertragen, die die Bedeutung und Beziehungen dieses Kontexts
- denken Sie mal an das Wort „Ring“, das ein Schmuckstück ist: was es sich selbst angeht, ist „sing“ eine seiner nahen Übereinstimmungen. Aber was es bedeutet, würde wir es mit etwas wie „Schmuck“, „Finger“, „Edelsteine“ oder vielleicht etwas wie „Hülle“, „Kreis“ usw. passend machen wollen.
- Daher, wenn wir die Vektor Embeddings von „Ring“ erzeugen, füllen wir es im Prinzip mit Tonschaften von Informationen über ihre Bedeutung und Beziehungen auf.
- Diese Informationen, zusammen mit den Vektor Embeddings anderer Wörter/Aussagen in einem Dokument, gewährleisten, dass die korrekte Bedeutung des Wortes „Ring“ im Kontext ausgewählt wird.
- Wir haben OpenAIEmbeddings verwendet, um Vektor Embeddings zu erzeugen.
LLM
- Es gibt mehrere große Sprachmodelle, die für unser Szenarium verwendet werden können.
- Im Rahmen dieses Projekts wurden Tests mit OpenAI und Mistral AI durchgeführt.
- Lesen Sie hier mehr über API Keys für OpenAI.
- Für MistralAI wurde HuggingFace verwendet.
Anwendungsfälle und Tests
Wir haben folgende Tests durchgeführt:
- Unterschriften und handschriftliche Daten/Texte wurden mit OCR gelesen.
- Handselektierte Optionen im Dokument
- Digitale Selektionen, die über dem Dokument vorgenommen wurden
- Unstrukturierte Daten wurden geparst, um tabellarischen Inhalt zu erhalten (in Textdatei/DB einfügen, etc.)
Zukunftsmöglichkeiten
Wir könnten die Anwendungsfälle für das oben genannte Projekt weiter erweitern, um Bilder zu integrieren, mit Dokumentationsspeicher wie Confluence/Drive zu integrieren etc., um Informationen zu einem bestimmten Thema aus mehreren Quellen zu ziehen, eine stärkere Möglichkeit hinzuzufügen, um eine vergleichende Analyse zwischen zwei Dokumenten durchzuführen, usw.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data