













Effiziente Datenverarbeitung ist für Geschäfte und Organisationen entscheidend, die auf große Datenanalyse angewiesen sind, um informierte Entscheidungen zu treffen. Ein Schlüsselfaktor, der die Leistung der Datenverarbeitung erheblich beeinflusst, ist die Daten Speicherung Format. Dieser Artikel untersucht die Auswirkungen verschiedener Speicherformate, insbesondere Parquet, Avro und ORC auf die Abfrageleistung und Kosten in großen Daten Umgebungen auf Google Cloud Platform (GCP). Der Artikel stellt Benchmarks bereit, diskutiert Kostenimplikationen und bietet Empfehlungen für die Wahl des richtigen Formats auf der Basis von bestimmten Anwendungsfällen an.
Einführung in Speicherformate in Big Data
Daten Speicherformate sind das Rückgrat jedes Big Data Verarbeitungsumfeldes. Sie definieren, wie Daten gespeichert, gelesen und geschrieben werden, was direkt die Speicher Effizienz, die Abfrageleistung und die Daten Retrieval Geschwindigkeiten beeinflusst. Im Big Data Ökosystem werden columnar Formate wie Parquet und ORC sowie row-basierte Formate wie Avro wegen ihrer optimierten Leistung für bestimmte Arten von Abfragen und Verarbeitungsaufgaben breit verwendet.
- Parquet: Parquet ist ein columnar Speicherformat, das für read-heavy Operationen und Analysen optimiert ist. Es ist in Bezug auf Kompression und Kodierung sehr effizient, was es ideal für Szenarien macht, in denen Leistung und Speicher Effizienz priorisiert werden.
- Avro: Avro ist ein row-basiertes Speicherformat, das für Daten Serialisierung entwickelt wurde. Es ist bekannt für seine Fähigkeiten zur Schemaevolution und wird oft für write-heavy Operationen verwendet, bei denen Daten schnell serialisiert und deserialisiert werden müssen.
- ORC (Optimized Row Columnar): ORC ist ein kolumnenbasiertes Speicherformat, das Parquet ähnelt, aber optimiert ist für sowohl Lesen als auch Schreibvorgänge. ORC zeichnet sich durch eine hohe Effizienz im Hinblick auf die Kompression aus, was die Speicherkosten senkt und die Datenabfrage beschleunigt.
Forschungsziel
Das Hauptziel dieser Forschung besteht darin, zu untersuchen, wie unterschiedliche Speicherformate (Parquet, Avro, ORC) die Abfrageleistung und die Kosten in großdatenbezogenen Umgebungen beeinflussen. Dieser Artikel soll Benchmarks basierend auf verschiedenen Abfragetypen und Datenmengen bereitstellen, um Data Engineers und Architekten zu helfen, das für ihre spezifischen Anwendungsfälle am besten geeignete Format auszuwählen.
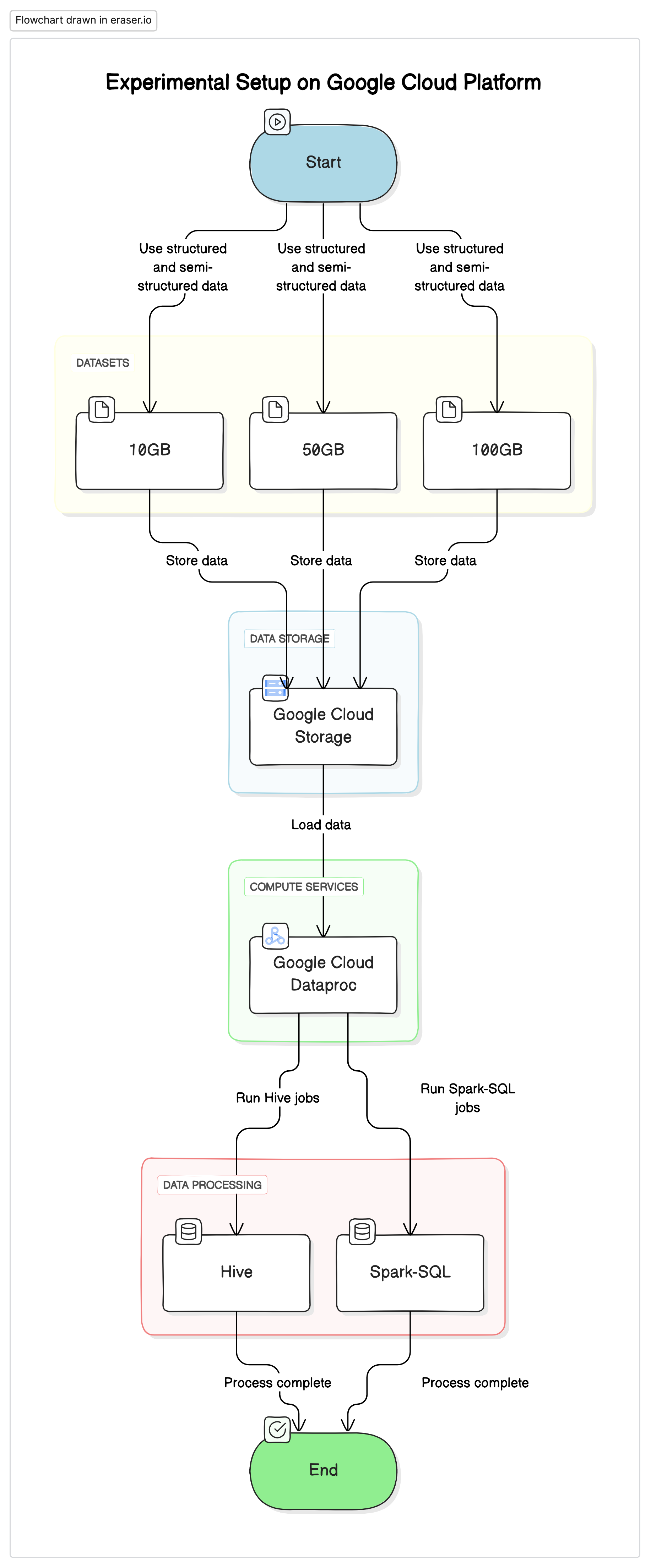
Experimentelle Setup
Um diese Forschung durchzuführen, haben wir eine standardisierte Einrichtung auf der Google Cloud Platform (GCP) verwendet, mit Google Cloud Storage als Datenlager und Google Cloud Dataproc für den Ausführung von Hive und Spark-SQL-Jobs. Die in den Experimenten verwendeten Daten bestanden aus einer Mischung von strukturierten und halbstrukturierten Datensets, um reale Szenarien zu simulieren.
Kritische Komponenten
- Google Cloud Storage: Verwendet wurde, um Datensets in verschiedenen Formaten (Parquet, Avro, ORC) zu speichern
- Google Cloud Dataproc: Ein verwalteter Service für Apache Hadoop und Apache Spark, der für die Ausführung von Hive und Spark-SQL-Jobs verwendet wurde.
- Datensets: Drei Datensets unterschiedlicher Größe (10GB, 50GB, 100GB) mit gemischten Datentypen.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
Testabfragen
- Einfache SELECT-Abfragen:Grundlegende Abfrage aller Spalten aus einer Tabelle
- Filterabfragen:SELECT-Abfragen mit WHERE-Klauseln, um bestimmte Zeilen zu filtern
- Aggregationsabfragen:Abfragen, die GROUP BY und Aggregationsfunktionen wie SUM, AVG usw. verwenden
- Verbindungsabfragen:Abfragen, die zwei oder mehr Tabellen auf einer gemeinsamen Schlüsselbasis verbinden
Ergebnisse und Analyse
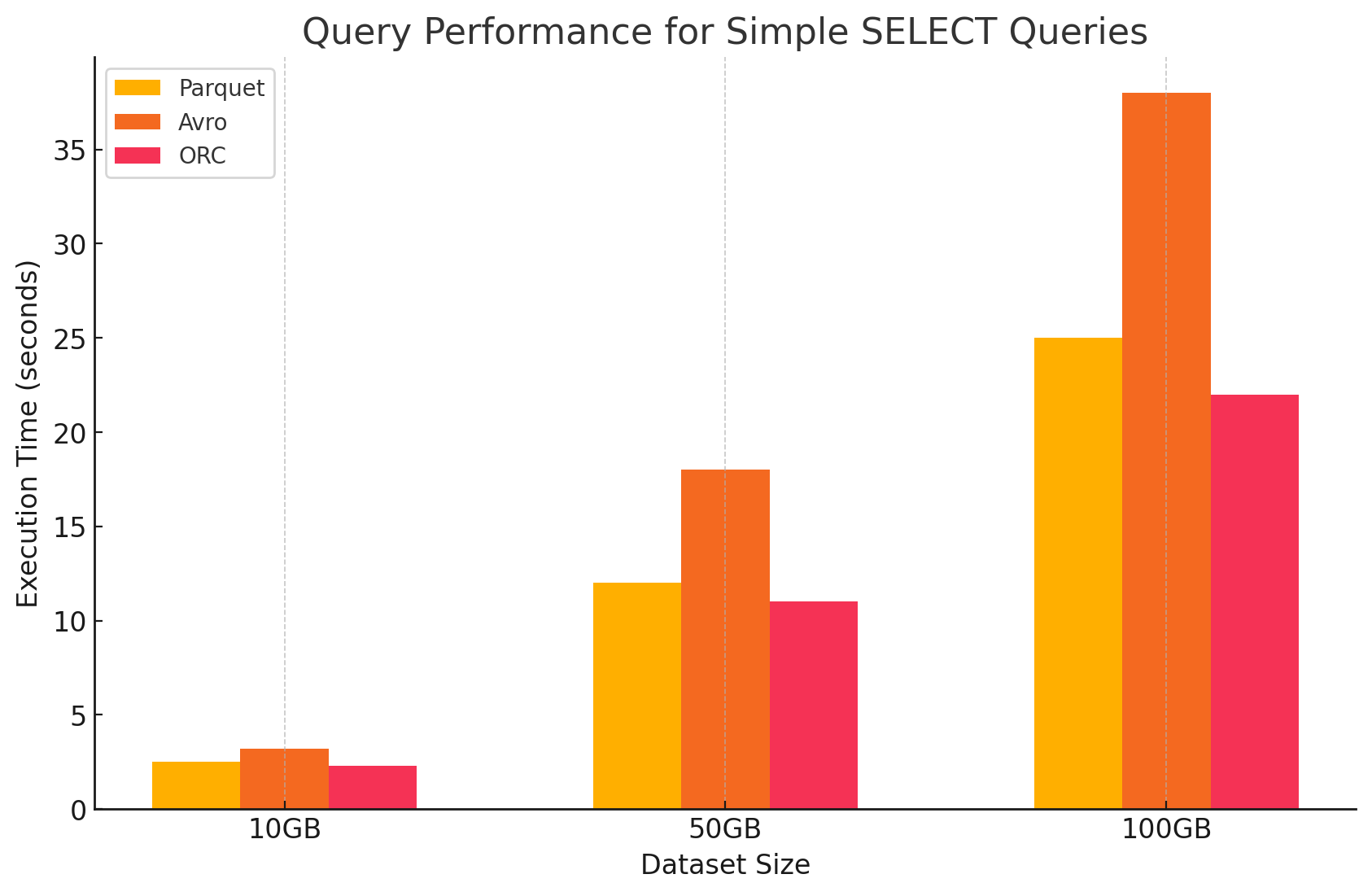
1. Einfache SELECT-Abfragen
- Parquet:Das Format mit columnaren Speicherung erwies sich durch eine hervorragende Leistung bei der schnellen Scan-Funktion für bestimmte Spalten. Parquet-Dateien sind hoch komprimiert, was die Datenmenge, die von der Platte gelesen wird, verringert und die Abfrageausführungszeiten beschleunigt.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro:Avro zeigte mittlere Leistung. Da es ein row-basiertes Format ist, wurde die gesamte Zeile gelesen, auch wenn nur bestimmte Spalten benötigt wurden. Dies führt zu mehr I/O-Operationen und verlangsamt die Abfrageleistung im Vergleich zu Parquet und ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC:ORC zeigte eine ähnliche Leistung wie Parquet, aber mit leicht besserer Kompression und optimierten Speichertechniken, die die Lesegeschwindigkeit verbesserten. ORC-Dateien sind auch columnar und somit geeignet für SELECT-Abfragen, die nur bestimmte Spalten abfragen.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
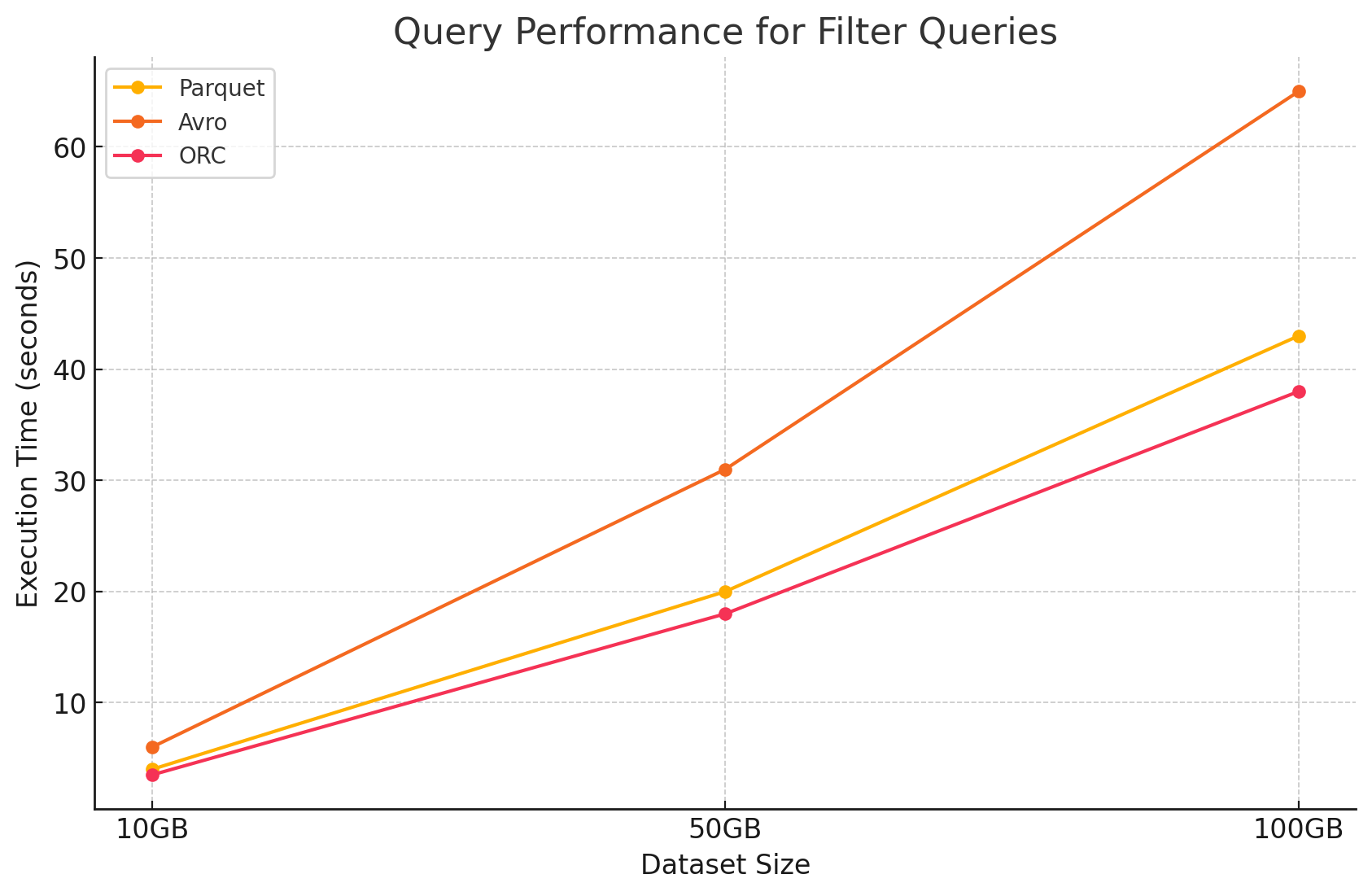
2. Filterabfragen
- Parquet:Durch seine columnare Natur und die Fähigkeit, irrelevante Spalten schnell zu überspringen, behielt Parquet seine Leistungsvorteile. Die Leistung wurde jedoch leicht durch das扫描 mehr Zeilen, um Filter anzuwenden, beeinträchtigt.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro:Die Leistung sank weiter ab, da es notwendig war, gesamte Zeilen zu lesen und Filter über alle Spalten anzuwenden, was die Verarbeitungszeit verlängerte.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC:ORC übertrumpfte Parquet leicht bei Filterabfragen dank seiner Prädikat-Down-Push-Funktion, die es ermöglicht, direkt auf Speicher-Ebene zu filtern, bevor die Daten in den Arbeitsspeicher gelesen wurden.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
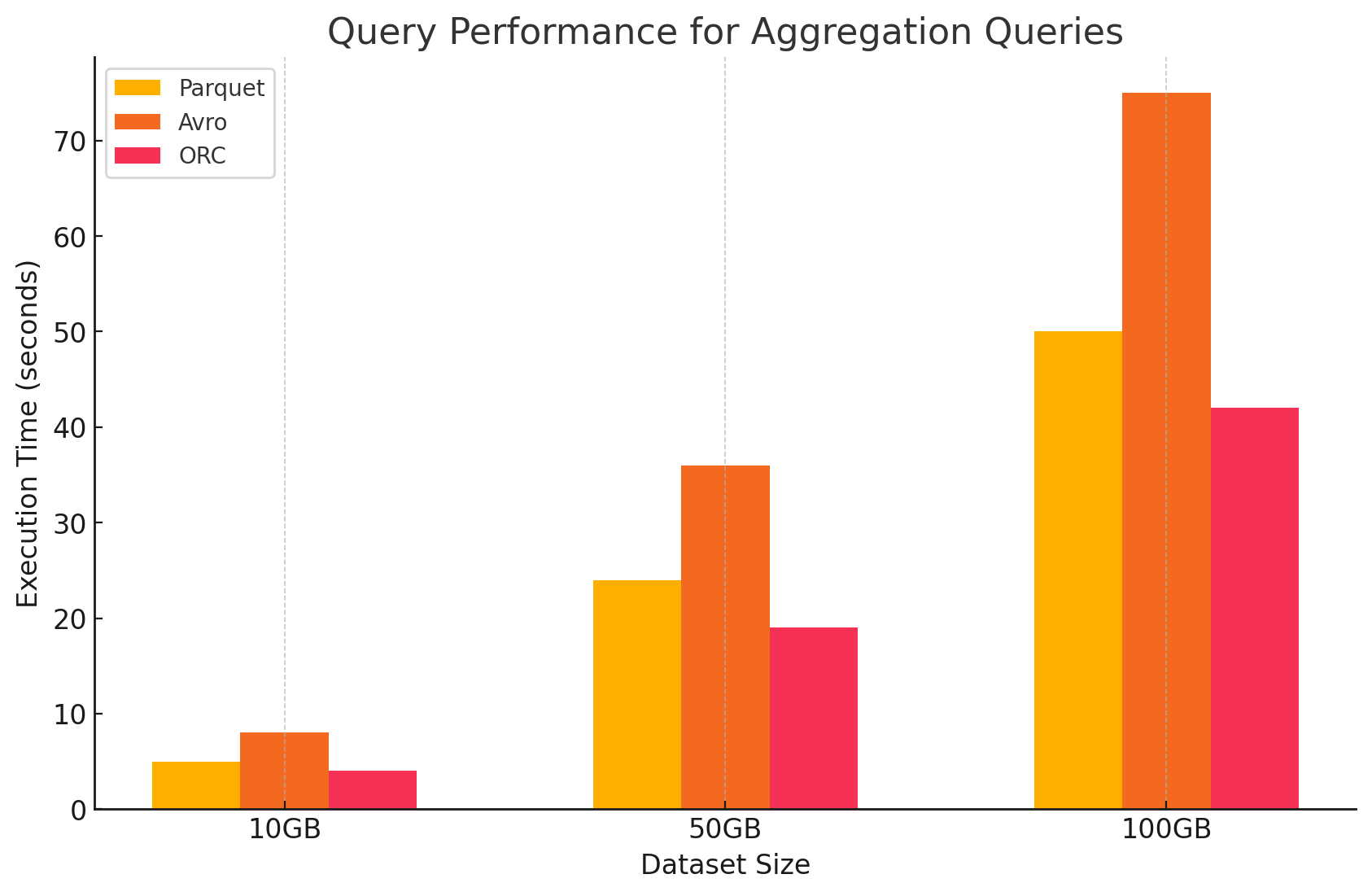
3. Aggregationsabfragen
- Parquet:Parquet zeigte eine gute Leistung, aber etwas weniger effizient als ORC. Der kolumnenbasierte Format besitzt Vorteile bei Aggregationsoperationen, indem er schnell auf die notwendigen Spalten zugreifen kann, aber Parquet fehlen einige integrierte Optimierungen, die ORC bietet.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro:Avro hinkte wegen seines row-basierten Speicherverfahrens hinterher, das jedes Mal alle Spalten für jede Zeile scannen und verarbeiten erforderte, was die Rechenlast erhöhte.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC:ORC übertraf sowohl Parquet als auch Avro bei Aggregationsabfragen. ORC’s fortschrittliche Indizierung und integrierte Komprimierungsalgorithmen ermöglichten schnellere Datenzugriffe und verringerten I/O-Operationen, was ihn sehr für Aggregationstasks geeignet machte.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
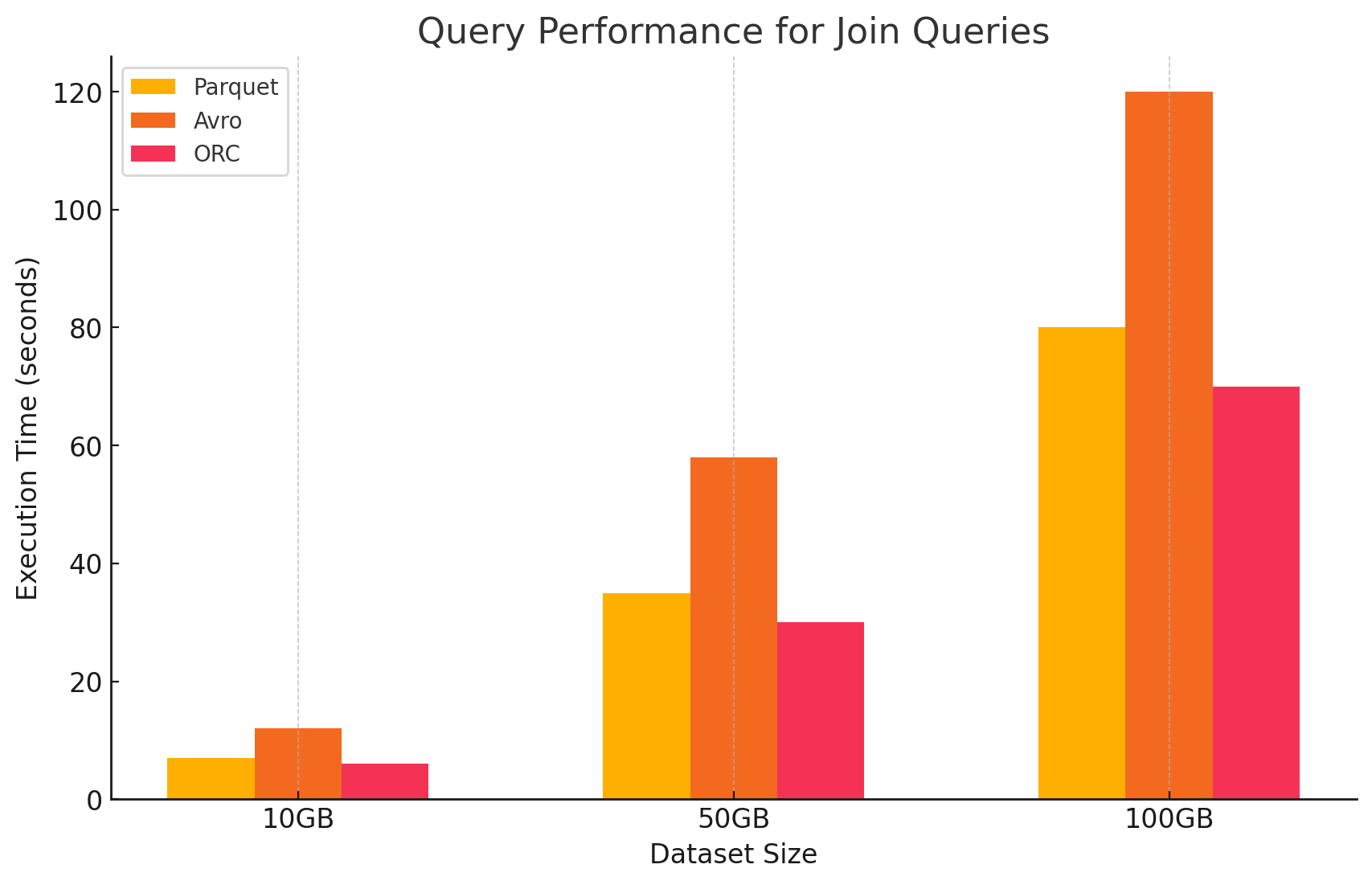
4. Verbindungsabfragen
- Parquet:Parquet zeigte eine gute Leistung, aber weniger effizient als ORC bei Verbindungsoperationen aufgrund seiner nicht optimierten Datenlese für Verbindungsbedingungen.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC:ORC herausragte in Verbindungsabfragen, indem es von fortschrittlicher Indizierung und Prädikat-Down-Push-Fähigkeiten profitierte, die die verarbeiteten und gescannten Daten während der Verbindungsoperationen minimierten.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro: Avro hat es schwer mit Join-Operationen, vor allem aufgrund des hohen Overheads beim Lesen von kompletten Zeilen und der fehlenden Spaltenoptimierungen für Join-Schlüssel.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
Impact des Speicherformats auf Kosten
1. Speichereffizienz und Kosten
- Parquet und ORC (Spaltenformate)
- Komprimierung und Speicherkosten: Sowohl Parquet als auch ORC sind Spaltenformate, die hohe Kompressionsraten bieten, besonders für Datensätze mit vielen wiederholten oder ähnlichen Werten innerhalb von Spalten. Diese hohe Kompression verringert die gesamte Datengröße und senkt somit die Speicherkosten, insbesondere in Cloudumgebungen, wo der Speicher auf GB-Basis abgerechnet wird.
- Optimal für Analyse-Arbeitslasten: Aufgrund ihrer spaltenorientierten Natur sind diese Formate ideal für Analyse-Arbeitslasten, bei denen nur bestimmte Spalten häufig abgefragt werden. Dies bedeutet, dass weniger Daten aus dem Speicher gelesen werden, was sowohl I/O-Operationen als auch assoziierte Kosten reduziert.
- Avro (zeilenbasierter Format)
- Kompression und Speicherkosten:Avro bietet typischerweise niedrigere Kompressionsraten als spaltenbasierte Formate wie Parquet und ORC, da es Daten zeilenweise speichert. Dies kann zu höheren Speicherkosten führen, insbesondere für große Datensets mit vielen Spalten, da alle Daten in einer Zeile gelesen werden müssen, auch wenn nur wenige Spalten benötigt werden.
- Besser geeignet für schreibintensive Workloads:Obwohl Avro aufgrund der niedrigen Kompression höhere Speicherkosten verursachen kann, ist es besser geeignet für schreibintensive Workloads, bei denen Daten kontinuierlich geschrieben oder angehängt werden. Die Kosten, die mit der Speicherung verbunden sind, könnten durch die Effizienzgewinne bei der Datenserialisierung und Deserialisierung ausgeglichen werden.
2. Datenverarbeitungserfolg und -kosten
- Parquet und ORC (spaltenorientierte Formate)
- Geringere Verarbeitungskosten:Diese Formate sind optimiert für lesens intensive Operationen, was sie sehr effizient für die Abfrage großer Datensets macht. Da sie nur die relevanten Spalten, die für eine Abfrage erforderlich sind, lesen, reduzieren sie die verarbeiteten Datenmenge. Dies führt zu niedrigeren CPU-Auslastungen und schnelleren Abfrageausführungzeiten, was die Rechenkosten in einer Cloudumgebung, in der Rechenressourcen entsprechend der Nutzung abgerechnet werden, erheblich reduzieren kann.
- Erweiterte Funktionen zur Kostenoptimierung:ORC besitzt insbesondere Funktionen wie bedingte Abfrageverzögerung (predicate push-down) und integrierte Statistiken, die es dem Abfrageengine ermöglichen, unnötige Daten zu überspringen. Dies reduziert weitere I/O-Operationen und verbessert die Abfrageleistung, optimierend somit die Kosten.
- Avro (row-based Formate)
- Hohe Verarbeitungskosten: Da Avro ein zeilenbasiertes Format ist, erfordert es im Allgemeinen mehr I/O-Operationen, um ganze Zeilen zu lesen, selbst wenn nur einige Spalten benötigt werden. Dies kann zu erhöhten Rechenkosten aufgrund höherer CPU-Auslastung und längerer Query-Ausführungszeiten führen, insbesondere in umfangreichen Leseumgebungen.
- Effizient für Streaming und Serialisierung: Obwohl Avro bei Abfragen höhere Verarbeitungskosten verursacht, ist es gut geeignet für Streaming- und Serialisierungsaufgaben, wo schnelle Schreibgeschwindigkeiten und Schema-Evolution wichtiger sind.
3. Kostenanalyse mit Preisdetails
- Um die Kostenwirkung jedes Speicherformats zu quantifizieren, führten wir ein Experiment mit GCP durch. Wir berechneten die Kosten für Speicher und Datenverarbeitung für jedes Format auf der Grundlage der Preismodelle von GCP.
- Google Cloud Speicherkosten
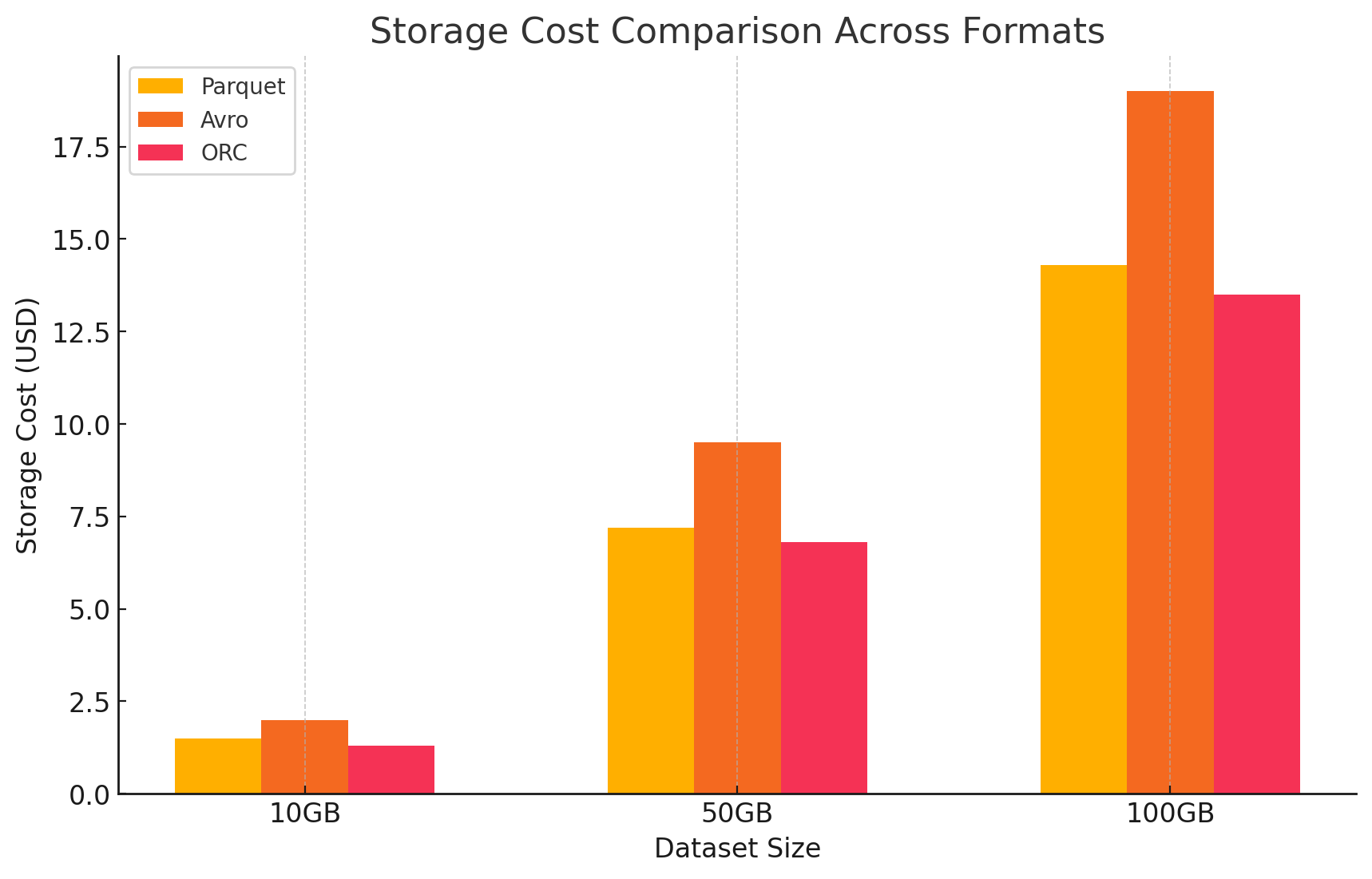
- Speicherkosten: Dies berechnet sich auf der Basis der im jeweiligen Format gespeicherten Datenmenge. GCP berechnet monatliche Kosten pro GB für Daten, die in Google Cloud Storage gespeichert sind. Die von jedem Format erreichten Komprimierungsraten haben direkten Einfluss auf diese Kosten. Columnar-Formate wie Parquet und ORC haben typischerweise bessere Komprimierungsraten als row-basierte Formate wie Avro, was zu niedrigeren Speicherkosten führt.
- Hier ist ein Beispiel, wie die Speicherkosten berechnet wurden:
- Parquet: Die hohe Komprimierung führte zu einer verringerten Datengröße und senkte die Speicherkosten
- ORC: Ähnlich wie Parquet reduzierte ORC’s fortschrittliche Komprimierung die Speicherkosten effizient
- Avro: Die niedrige Komprimierungsleistung verursachte höhere Speicherkosten im Vergleich zu Parquet und ORC
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
- Datenverarbeitungskosten
- Die Datenverarbeitungskosten wurden berechnet, basierend auf den Rechenressourcen, die für die Durchführung verschiedener Abfragen mit Dataproc auf GCP notwendig sind. GCP berechnet die Kosten für die Nutzung von Dataproc auf der Grundlage der Größe des Clusters und der Dauer, für die die Ressourcen verwendet werden.
- Rechnungskosten für Rechnungskosten:
- Parquet und ORC: Aufgrund ihrer effizienten kolumnenbasierten Speicherung konnten diese Formate das verarbeitete Datenvolumen verringern, was zu geringeren Rechnungskosten führte. Schnellere Abfrageausführungstzeiten trugen ebenfalls zum Kostenersparnis bei, insbesondere für komplexe Abfragen mit großen Datensets.
- Avro: Avro erforderte wegen seines datenzeilenbasierten Formats mehr Rechenressourcen, was zu einer Erhöhung des verarbeiteten Datenvolumens führte. Dies führte zu höheren Kosten, insbesondere für operationen mit hohem Leseverhalten.
Schlussfolgerung
Die Wahl des Speicherformats in großdatenbetriebenen Umgebungen hat einen bedeutenden Einfluss sowohl auf die Abfrageleistung als auch auf die Kosten. Die oben genannten Forschungen und Experimente zeigen die folgenden Schlüsselpunkte auf:
- Parquet und ORC: Diese kolumnenbasierten Formate bieten hervorragende Komprimierung, was die Speicherkosten reduziert. Ihre Fähigkeit, nur die notwendigen Spalten effizient zu lesen, verbessert die Abfrageleistung erheblich und verringert die Datenverarbeitungskosten. ORC übertrifft Parquet in bestimmten Abfragetypen leicht aufgrund seiner fortschrittlichen Indizes und Optimierungsfeatures, making it an excellent choice for mixed workloads that require both high read and write performance.
- Avro: Während Avro nicht so effizient ist, was die Komprimierung und die Abfrageleistung angeht, wie Parquet und ORC, so zeichnet es sich durch schnelle Schreiboperationen und -evolution aus. Dieser Format ist ideal für Szenarien mit Datenserialisierung und Streaming, wo die Schreibleistung und Flexibilität anstatt der Leseeffizienz Priorität haben.
- Kosteneffizienz: In einer Cloudumgebung wie GCP, wo die Kosten eng mit Speicher- und Rechenzeiteinsatz verbunden sind, kann die richtige Formatwahl zu erheblichen Kosteneinsparungen führen. Für Analytiklasten, die hauptsächlich auf Lesen basieren, sind Parquet und ORC die am besten geeigneten Optionen. Für Anwendungen, die eine schnelle Datenaufnahme und eine flexible Schemaverwaltung benötigen, ist Avro eine geeignete Wahl, obwohl ihre höheren Speicher- und Rechenzeiteinsparungen kosten.
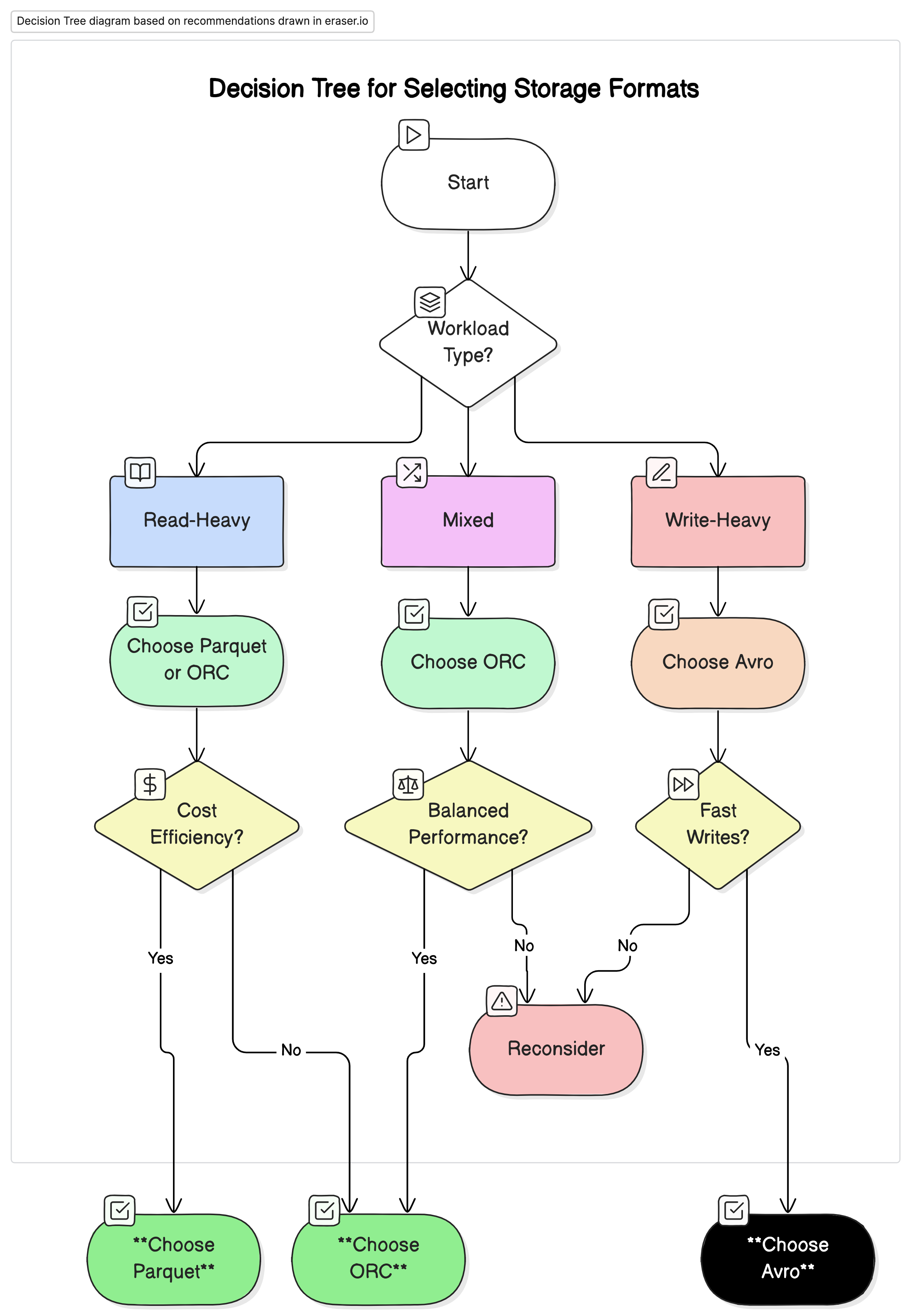
Empfehlungen
Basierend auf unserer Analyse empfehlen wir folgendes:
- Für leistungsstarke lesende analytische Workloads: Parquet oder ORC. Diese Formate bieten aufgrund Ihrer hohen Komprimierung und optimierten Abfragerenditen eine überlegene Leistung und Kostenwirksamkeit.
- Für schreibstarke Workloads und Serialisierung: Nutzen Sie Avro. Es ist besser geeignet für Szenarien, in denen schnelle Schreiboperationen und Schemaevolution von Bedeutung sind, wie z.B. Datenströme und Nachrichtensysteme.
- Für gemischte Workloads: ORC bietet ausgewogene Leistung für Lese- und Schreiboperationen und ist daher eine ideale Wahl für Umgebungen mit unterschiedlichen Datenworkloads.
Letzte Gedanken
Die Wahl des richtigen Speicherformats für Big-Data-Umgebungen ist entscheidend für die Optimierung von Leistung und Kosten. Die Kenntnis der Stärken und Schwächen jedes Formats ermöglicht es Dateningenieuren, ihre Datenarchitektur auf spezielle Anwendungsfälle abzustimmen, um Effizienz und Kosten zu maximieren. Angesichts des weiter wachsenden Datenvolumens werden informierte Entscheidungen über Speicherformate immer wichtiger für die Wartung skalierbarer und kostenwirksamer Datenlösungen.
Durch sorgfältige Bewertung der Leistungs- und Kostenimplikationen, die in diesem Artikel dargestellt sind, können Organisationen den Speicherformat wählen, das am ehesten zu ihren operationellen Bedürfnissen und finanziellen Zielen passt.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc