













المستندات الكبيرة تعالج مواجهة معالجة اللغة الطبيعية (NLP) لتمثيل معنى النص كمتجه. هذا التمثيل لكلمات النص يُعتبر إدخالًا.
الحد الأقصى للأحرف: المشكلة الأكبر في توجيه الـ LLM
حاليًا، من أكبر المشكلات في توجيه الـ LLM هو الحد الأقصى للأحرف. عند إطلاق GPT-3، كان الحد لكل من التحرير والإخراج مجتمعين هو 2,048 حرف. مع GPT-3.5، ارتفع هذا الحد إلى 4,096 حرف. الآن، يأتي GPT-4 بنوعين. أحدهما بحد أقصى 8,192 حرف والآخر بحد أقصى 32,768 حرف، حوالي 50 صفحة نص.
إذن، ماذا يمكنك فعله عندما ترغب في توجيه سياق أكبر من هذا الحد؟ بالطبع، الحل الوحيد هو تقليل طول السياق. لكن كيف يمكنك تقليله وفي الوقت نفسه إبقاء جميع المعلومات ذات الصلة؟ الحل: تخزين السياق في قاعدة بيانات متجهة وايجاد السياق الذي يهم باستخدام سؤال بحث للتشابه.
ما هي الإدخالات المتجهة؟
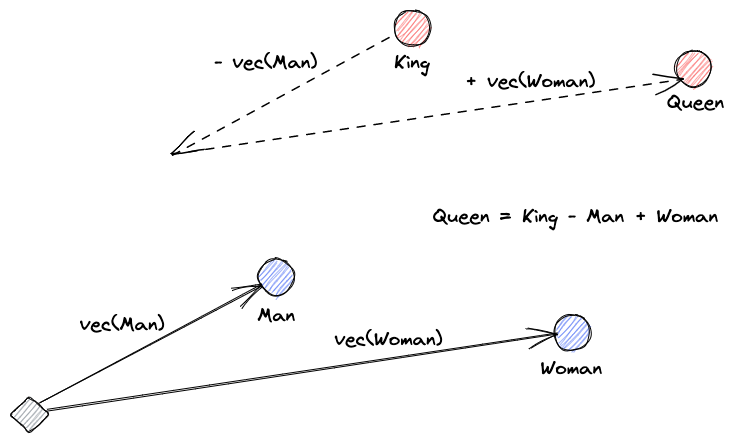
دعونا نبدأ بشرح ما هي الإدخالات المتجهة. تعريف روي كينز هو: “الإدخالات هي تحولات تعلمها لجعل البيانات أكثر فائدة.” تعلم شبكة العصبية التحويل لتحويل النص إلى فضاء متجه يحتوي على المعنى الفعلي. هذا أكثر فائدة لأنه يمكنه إيجاد المرادفات والعلاقات النحوية والدلالية بين الكلمات. يساعدنا هذا الرسم البياني على فهم كيف يمكن لهذه المتجهات ترميز المعنى:
ماذا تفعل قواعد بيانات المتجهات؟
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
بحث التشابه
يمكننا إيجاد تشابه المتجهات عن طريق حساب بعد متجه عن جميع المتجهات الأخرى. ستكون أقرب الجيران النتائج الأكثر تشابهًا بالنسبة لمتجه الاستعلام. هذه هي طريقة عمل الفهارس المسطحة في قواعد بيانات المتجهات. لكن هذا ليس فعالًا جدًا. في قاعدة بيانات كبيرة، قد يستغرق هذا وقتًا طويلاً.
لتحسين أداء البحث، يمكننا محاولة حساب المسافة فقط لنصف مجموعة المتجهات. هذا النهج، المعروف بالجيران الأقرب تقريبيًا (ANN)، يحسن السرعة لكنه يضحي بجودة النتائج. تشمل بعض الفهارس ANN الشهيرة التوافق المحلي الحساس (LSH)، العالم الصغير القابل للتنقل الهرمي (HNSW)، أو الفهرسة العكسية للملف (IVF).
دمج مخازن المتجهات والنماذج الكبيرة لللغة
في هذا المثال، قمت بتنزيل توثيق Numpy بالكامل (يزيد عن 2000 صفحة) كملف PDF من هذا عنوان URL.
يمكننا كتابة رمز Python لتحويل وثيقة السياق إلى تطورات وحفظها في مخزن متجه. سنستخدم LangChain لتحميل الوثيقة وتقسيمها إلى قطع و Faiss (بحث تشبه Facebook AI) كقاعدة بيانات متجه.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")الآن، يمكننا استخدام هذه القاعدة لإجراء استعلام بحث تشابه لإيجاد صفحات ربما تكون ذات صلة بموجزنا. ثم، نستخدم القطع الناتجة لملء سياق موجزنا. سنستخدم LangChain لتسهيل ذلك:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)سؤالنا للنموذج هو “كيفية حساب الوسيط لمصفوفة.” على الرغم من أن السياق الذي نعطيه له يفوق حد العبارات، لكننا تجاوزنا هذه القيود وحصلنا على إجابة:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".هذه مجرد حل ذكي لمشكلة جديدة جداً. ومع تطور النماذج اللغوية الكبيرة، ربما يتم حل مشاكل مثل هذه دون الحاجة إلى هذه الأنواع من الحلول الذكية. ومع ذلك، أنا متأكد من أن هذا التطور سيفتح الباب لقدرات جديدة قد تحتاج إلى حلول ذكية أخرى للتحديات التي قد تجلبها.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data