













介绍
随着模型复杂性的增加和透明度的缺乏,模型可解释性方法在近年来变得越来越重要。模型理解是研究的热点话题,也是采用机器学习的各个领域实践应用的关注焦点。
Captum 为学术界和开发者提供前沿技术,如集成梯度,这使得识别影响模型输出的元素变得简单。Captum 使 ML 研究人员能够更轻松地使用 PyTorch 模型构建可解释性方法。
通过更容易地识别影响模型输出的许多元素,Captum 可以帮助模型开发者创建更好的模型并修复提供意外结果的模型。
算法描述
Captum 是一个允许实现各种可解释性方法的库。可以将 Captum 的归因算法分为三个广泛类别:
- 主要归因:确定每个输入特征对模型输出的贡献。
- 层次贡献度:对特定层中的每个神经元评估其对模型输出的贡献。
- 神经元贡献度:一个隐藏神经元的激活由评估每个输入特征的贡献来确定。
以下是Captum中目前实现的主要、层次和神经元归因方法的简要概述。还包括了噪声通道的描述,它可以用来平滑任何归因方法的结果。
Captum提供了衡量模型解释可靠性的指标以及其归因算法。目前,他们提供了不忠度和敏感度指标,以帮助评估解释的准确性。
主要归因技术
集成梯度
假设我们有一个深度网络的正式表示,F: Rn → [0, 1]。
设x ∈ Rn为当前输入,x′ ∈ Rn为基线输入。
在图像网络中,基线可能是黑色图像,而在文本模型中,它可能是零嵌入向量。
从基线x′到输入x,我们在实数空间Rn中的所有点计算梯度。通过累积这些梯度,可以生成积分梯度。积分梯度被定义为从基线x′到输入x的直接路径上梯度的路径积分。
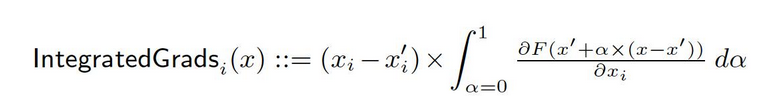
这两个基本假设:敏感性和实现不变性,构成了这种方法的基础。请参阅原论文以了解更多关于这些公理的信息。
梯度SHAP
合作博弈论中的Shapley值用于计算梯度SHAP值,其通过梯度方法进行计算。梯度SHAP对每个输入样本多次添加高斯噪声,然后在基线和输入之间的路径上随机选择一个点来确定输出的梯度。因此,最终的SHAP值表示梯度的期望值 *(输入 – 基线)。SHAP值的近似是在输入特征独立且解释模型在输入和提供的基线之间是线性的前提下进行的。
DeepLIFT
可以使用DeepLIFT(一种反向传播技术)根据输入及其匹配的参考(或基线)之间的差异来归因于输入变化。DeepLIFT试图通过比较参考输入之间的差异来解释参考输出之间的差异。DeepLIFT利用乘数的概念来“责怪”单个神经元对输出差异的贡献。对于给定的输入神经元x(与参考的差异为∆x),和我们希望计算其贡献的目标神经元t(与参考的差异为∆t),我们定义乘数m∆x∆t为:
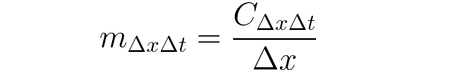
DeepLIFT SHAP
DeepLIFT SHAP是基于合作游戏理论中的Shapley值建立的DeepLIFT扩展。DeepLIFT SHAP为每个输入-基线对计算DeepLIFT归因,并使用基线分布平均每个输入示例的结果归因。DeepLIFT的非线性规则有助于将网络的非线性函数线性化,该方法对线性化网络的SHAP值近似也适用。在此方法中,输入特征同样被假定为独立的。
显著性
通过显著性计算输入的归属是一个简单的过程,它生成了输出关于输入的梯度。在输入处使用一阶泰勒网络展开,梯度是模型线性表示中每个特征的系数。这些系数的绝对值可以用来表示一个特征的相关性。你可以在原始论文中找到关于显著性方法的更多信息。
输入X梯度
输入X梯度是显著性方法的一个扩展,它计算输出关于输入的梯度并乘以输入特征值。这种方法的一个直观考虑是线性模型;梯度仅仅是每个输入的系数,输入与系数的乘积对应于特征对线性模型输出的总贡献。
引导反向传播和去卷积
梯度计算是通过引导反向传播和去卷积完成的,尽管ReLU函数的反向传播被覆盖,使得只传播非负梯度。在引导反向传播中,ReLU函数应用于输入梯度,而在去卷积中,它直接应用于输出梯度。通常,这些方法与卷积网络一起使用,但它们也可以用于其他类型的神经网络架构。
引导性GradCAM
引导性反向传播属性计算中,引导性GradCAM属性(引导性GradCAM)与放大(层)GradCAM属性的元素级乘积相结合。属性计算是针对给定的层进行的,并放大以适应输入大小。这种技术主要关注卷积神经网络。然而,任何可以与输入在空间上对齐的层都可能被提供。通常,会提供最后一个卷积层。
特征失活
为了计算属性,使用了称为“特征失活”的技术,它采用了一种基于扰动的方法,在计算输出差异之前,将每个输入特征的“基线”或“参考值”(如0)替换为已知值。将输入特征分组和失活是逐一进行的好方法,许多不同的应用都可以从中受益。通过分组和失活图像的段,我们可以确定段的相对重要性。
特性排列
特性排列是一种基于扰动的方法,它会在一个批次内随机重新排列每个特征,并计算由此修改引起的输出(或损失)的变化。与特征删除类似,特性也可以按组而非单独地一起处理。请注意,与Captum中可用的其他算法相比,这个算法是唯一一个当它被提供了一个多个输入示例的批次时,可能提供正确归因的算法。其他算法只需要一个示例作为输入。
遮蔽
遮蔽是一种基于扰动的归因计算方法,它用给定的基线/参考值替换每个连续的矩形区域,并计算输出的差异。对于位于多个区域(超矩形)的特征,相应的输出差异会被平均计算该特征的归因。遮蔽在图像等情况下非常有用,因为连续矩形区域内的像素很可能高度相关。
Shapley值采样
归因技术Shapley值 基于合作博弈论。这种技术考虑输入特征的每种排列,并逐一将它们添加到指定的基线中。在添加每个特征后输出的差异对应于其贡献,这些差异在所有排列上求和以确定归因。
Lime
最广泛使用的可解释性方法之一是Lime,它通过在输入示例周围采样数据点并使用在这些点上的模型评估来训练一个可解释的替代模型,比如一个线性模型。
KernelSHAP
内核SHAP是一种使用LIME框架计算Shapley值的技术。通过设置损失函数、加权核和适当正则化项,可以在LIME框架中更有效地获得Shapley值。
层属性技术
层导电性
层导电性是一种通过结合神经元的激活以及神经元对输入的偏导数和输出对神经元的偏导数,建立更全面神经元重要性的方法。通过隐藏神经元,导电性在集成梯度(IG)的属性流程基础上进行构建。在原始论文中,隐藏神经元y的总导电度定义如下:
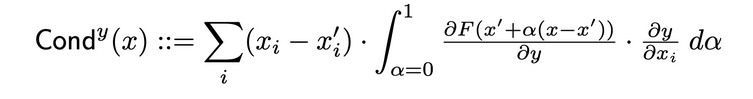
内部影响
使用内部影响,可以估计从基线输入到提供的输入路径上梯度的积分。这项技术类似于应用综合梯度,涉及对层(而不是输入)进行梯度积分。
层梯度X激活
层梯度X激活是网络中隐藏层的输入X梯度技术的等效物…
它将层的激活与目标输出的梯度(针对指定层)元素逐个相乘。
GradCAM
GradCAM是一种通常应用于最后一层卷积层的卷积神经网络层归因技术。GradCAM计算目标输出的梯度(相对于指定层),平均每个输出通道(输出维度2),并将每个通道的平均梯度乘以层激活。在输出应用ReLU以确保从所有通道的结果之和中只返回非负的归因。
神经元贡献技术
神经元导电性
导电性将神经元激活与神经元相对于输入和输出相对于神经元的偏导数结合在一起,提供了关于神经元相关性的更全面的画面。为了确定特定神经元的导电性,人们检查每个通过该神经元的输入的IG属性流动。以下是原始论文对给定输入属性i的神经元y的导电性的正式定义:
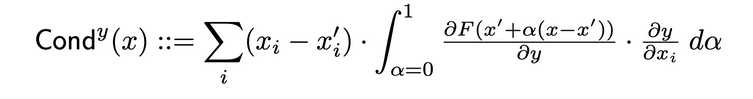
根据这个定义,需要注意的是,对神经元导电性(跨所有输入特征)求和总是等于该特定神经元所在层的导电性。
神经元梯度
神经元梯度方法是网络中单个神经元显著性方法的等效物。
它简单地计算了神经元输出相对于模型输入的梯度。
这种方法,如同Saliency,可以被视为在给定输入处对神经元的输出进行一阶泰勒展开,其中梯度对应于模型线性表示中每个特征的系数。
神经元集成梯度
可以使用称为“神经元集成梯度”的技术,估计从基线输入到感兴趣输入之间的路径上,针对特定神经元的输入梯度的积分。假设输出仅仅是所识别的神经元的输出,积分梯度与这种方法等效。您可以在原始论文此处找到有关集成梯度方法的更多信息。
神经元梯度SHAP
神经元GradientSHAP是针对特定神经元的GradientSHAP的等效物。神经元GradientSHAP多次向每个输入样本添加高斯噪声,选择基线与输入之间的路径上的随机点,并计算目标神经元相对于每个随机点的梯度。生成的SHAP值接近预测的梯度值 *(输入 – 基线)。
神经元DeepLIFT SHAP
神经元DeepLIFT SHAP是针对特定神经元的DeepLIFT的等效物。使用基线分布,DeepLIFT SHAP算法计算每个输入-基线对的神经元DeepLIFT归因,并平均生成的归因值每个输入示例。
噪声隧道
噪声隧道是一种可以与其他方法结合使用的归因技术。噪声隧道多次计算归因,每次向输入添加高斯噪声,然后根据所选类型合并结果归因。以下支持的噪声隧道类型有:
- 平滑梯度: 返回采样属性的平均值。使用高斯核平滑指定属性技术是一种近似这个过程的方法。
- 平方平滑梯度:返回平方采样属性的平均值。
- 方差梯度: 返回采样属性的方差。
指标
不忠实度
不忠实度衡量了模型解释在输入扰动的量级上与预测函数对这些输入扰动的改变之间的平均平方误差。不忠实度的定义如下:
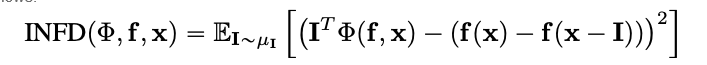
从众所周知的属性技术,如集成梯度,这是一个在计算上更高效且扩展的概念Sensitivy-n。后者分析了属性之和与预测函数在其输入和预定义基线上的差异之间的相关性。
敏感度
敏感度,它被定义为使用蒙特卡洛抽样近似的方法对微小输入扰动进行解释变化的程度,其测量方法如下:

默认情况下,我们从L-无穷球的一个子空间中抽样,以近似敏感度,默认半径为球体半径。用户可以改变球体半径和抽样函数。
预训练ResNet模型的模型解释
本教程展示了如何使用模型解释方法对选定的图像上的预训练ResNet模型进行解释,并通过覆盖在每个像素上的方式可视化归因。在本教程中,我们将使用解释算法集成梯度、GradientShape、使用层梯度Cam的Attribution和Occlusion。
在开始之前,您必须拥有一个Python环境,其中包括:
- Python 3.6或更高版本
- PyTorch 1.2或更高版本(推荐使用最新版本)
- TorchVision 0
- .6或更高版本(推荐使用最新版本)
- Captum(推荐使用最新版本)
根据您是使用Anaconda还是pip虚拟环境,以下命令将帮助您设置Captum:
使用conda时:
conda install pytorch torchvision captum -c pytorch
使用 `pip`:
pip install torch torchvision captum
让我们导入库。
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
加载预训练的Resnet模型并将其设置为评估模式
model = models.resnet18(pretrained=True)
model = model.eval()
ResNet在ImageNet数据集上进行训练。下载并读取内存中的ImageNet数据集类别/标签列表。
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
现在我们已经完成了模型,我们可以下载图片进行分析。
在我的情况下,我选择了一张猫的图片。

您的图片文件夹必须包含cat.jpg文件。正如我们下面可以看到的,Image.open()打开并识别给定的图像文件,np.asarry()将其转换为数组。
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
在下面的代码中,我们将为图像定义转换器和归一化函数。为了训练我们的ResNet模型,我们使用了ImageNet数据集,这需要图像具有特定的大小,并将通道数据归一化到特定的值范围内。transforms.Compose()将多个转换组合在一起,transforms.Normalize() normalizes a tensor image with mean and standard deviation.
模型期望输入是224x224的三通道图像
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# ImageNet标准化
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
# unsqueeze在指定位置插入一个大小为1的新维度,并返回一个新的张量。
input = input.unsqueeze(0)
现在,我们将预测输入图像的类别。可以问的问题是:“我们的模型认为这幅图像代表什么?”
#调用我们的模型
output = model(input)
##应用softmax()函数
output = F.softmax(output, dim=1)
# torch.topk返回给定输入张量在给定维度上的最大k个元素。这里的K是1
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
#将其转换为键值对字典的预测标签,将其转换为字符串以获取预测标签
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
输出:
Predicted: tabby ( 0.5530276298522949 )
的事实证明,ResNet认为我们的一只猫的图像实际上是一只猫,这是得到了验证。但是什么让模型认为这是一只猫的图像呢?为了解决这个问题,我们将咨询Captum。
综合梯度的特征归因
Captum中的各种特征归因技术之一是综合梯度。综合梯度通过估计模型输出关于输入的梯度的积分,为每个输入特征分配一个相关性得分。
在我们的案例中,我们将选取输出向量的特定组件——即表示模型对其选择类别的信心——并使用集成梯度来确定输入图像的哪些方面导致了这个输出。这将允许我们确定产生这个结果时图像的哪些部分最为重要。
获得集成梯度的 Importance Map 之后,我们将使用 Captum 捕获的可视化工具提供一个清晰易懂的 Importance Map 描述。
集成梯度将计算模型对预测类别 pred_label_idx 的输出梯度,相对于输入图像像素,沿着从黑色图像到我们的输入图像的路径。
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
# 创建集成梯度对象并获取属性
integrated_gradients = IntegratedGradients(model)
# 请求算法将我们的输出目标分配给
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
输出:
Predicted: tabby ( 0.5530276298522949 )
让我们通过将后者叠加在图像上来查看图像及其伴随的归因。Captum 提供的 visualize_image_attr() 方法提供了一系列可能性,以便根据您的喜好定制归因数据的展示方式。在这里,我们传递了一个自定义的 Matplotlib 颜色映射(参见 LinearSegmentedColormap())。
#结果可视化自定义颜色映射
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
#使用可视化辅助方法visualize_image_attr显示原始图像以供比较
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
输出:
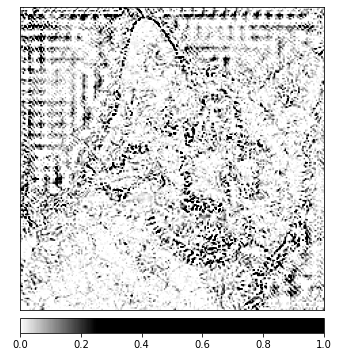
您应该能够在上面所示的图像中注意到,集成梯度算法给出最强信号的区域是图像中猫周围的区域。
让我们通过使用集成梯度来计算归因,然后通过使用由噪声隧道生成的多张图像来平滑它们。
后者通过添加标准差为1的高斯噪声来修改输入,进行了10次修改(nt_samples=10)。噪声隧道使用smoothgrad_sq方法使归因在所有nt_samples的噪声样本之间保持一致。
smoothgrad_sq的值是nt_samples样本中归因的平方的平均值。visualize_image_attr_multiple()通过归一化指定符号的归因值(正、负、绝对值或所有)来可视化给定图像的归因,然后使用所选模式在matplotlib图表中显示它们。
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
输出:

从上面的图片中我可以看出,模型集中在猫的头部。
让我们通过使用GradientShap来结束。GradientShap是一种可能用于计算SHAP值的梯度方法,它也是一个了解全局行为的好工具。它是一个线性解释模型,通过使用参考样本的分布来解释模型的预测。它随机选择输入和基线之间的输入,以确定期望的梯度。
基线是从提供的基线分布中随机选择的。
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
# 图像基线分布的定义
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
输出:

使用Layer GradCAM的层贡献
您可以借助层归因(Layer Attribution)来关联模型内部隐藏层的活动与输入特征。
我们将应用一个层归因算法来研究模型中包含的卷积层之一的活动。
GradCAM负责计算目标输出相对于指定层的梯度。然后,这些梯度按每个输出通道(输出维度的2)求平均,并将层激活乘以每个通道的平均梯度。
然后,将所有通道的结果相加。由于卷积层的活动通常在空间上与输入相对应,因此GradCAM归因通常会上采样,并用于遮罩输入。值得注意的是,GradCAM是专门为卷积神经网络(convnets)开发的。层归因的设置与输入归因相同,不同之处在于,除了模型之外,您必须提供一个模型内部的隐藏层,您希望对其进行分析。与之前讨论的内容相似,当我们调用attribute()时,我们指定了感兴趣的目标类别。
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
为了更准确地比较输入图像与归因数据,我们将使用位于LayerAttribution基类中的interpolate()函数进行上采样。
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
输出:
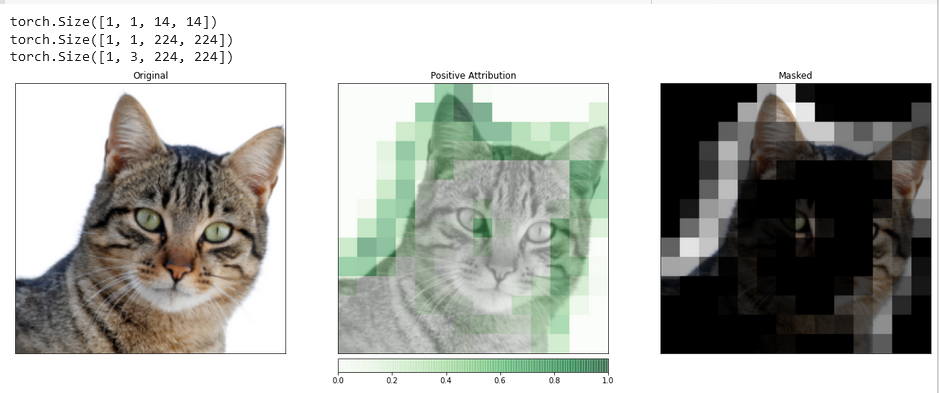
此类可视化具有提供关于隐藏层如何响应您提供的输入的独特见解的潜力。
特征归因与遮蔽
基于梯度的方法有助于我们通过直接计算输入变化对输出的影响来理解模型。
被称为基于扰动归因的技术采用了一种更直接的方法来解决这个问题,通过修改输入来量化这种变化对输出的影响。其中一种策略被称为遮蔽。
它涉及替换输入图像的片段,并分析这种变化如何影响输出产生的信号。
在下面,我们将配置遮蔽归因。就像卷积神经网络的配置一样,你可以选择目标区域的尺寸和步长长度,这决定了单个测量的间距。
我们将使用visualize_image_attr_multiple()函数来查看我们的遮蔽归因结果。这个函数将显示每个区域的正负归因的热图,并用正归因区域遮盖原始图像。
遮盖提供了对模型识别的“猫样”特征最明显的区域的直观了解。
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
输出:
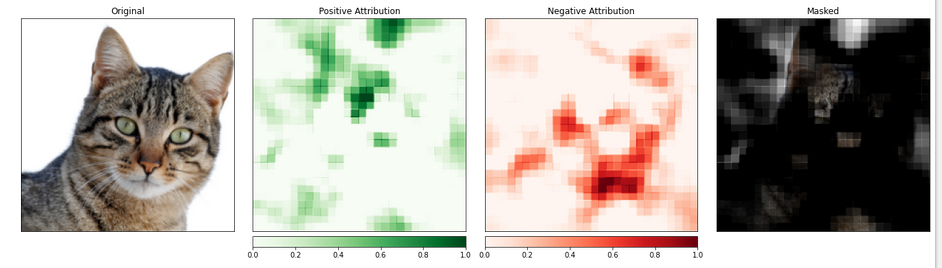
包含猫的图像部分似乎被赋予了更高的重要性。
结论
Captum 是一个适用于 PyTorch 的模型可解释性库,它既多功能又简单。它提供了最先进的技术,用于理解特定神经元和层如何影响预测。
它主要有三种归属技术:基本归属技术、层归属技术和神经元归属技术。
参考文献
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf