













Editor’s Note: The following is an article written for and published in DZone’s 2024 Trend Report, Инженерия данных: Обогащение данных в трубопроводах, расширение ИИ и ускорение аналитики.
Эта статья исследует основные стратегии использования потоковой передачи данных в реальном времени для получения действий insights, а также обеспеченияfuture proof систем через автоматизацию ИИ и векторные базы данных. Она углубляется в эволюционирующие архитектуры и инструменты, которые позволяют бизнесам оставаться гибкими и конкурентоспособными в мире, управляемом данными.
Потоковая передача данных в реальном времени: Эволюция и ключевые аспекты
Потоковая передача данных в реальном времени эволюционировала из традиционной batch обработки, где данные обрабатывались с интервалами, что приводило к задержкам, до непрерывной обработки данных по мере их генерации, что позволяетInstant responses к критическим событиям. Интегрируя ИИ, автоматизацию и векторные базы данных, компании могут进一步提升 свои возможности, используя insights в реальном времени для предсказания результатов, оптимизации операций и эффективного управления крупномасштабными сложными dataset.
Необходимость потоковой передачи в реальном времени
Необходимо действовать с данными сразу же после их возникновения, особенно в таких сценариях, как обнаружение мошенничества, анализ логов или отслеживание поведения клиентов. Реальное время стриминга позволяет организациям захватывать, обрабатывать и анализировать данныеInstantaneamente, позволяя им быстро реагировать на динамические события, оптимизировать принятие решений и улучшать опыт клиентов в реальном времени.
Источники реальных данных
Реальные данные起源于 различных систем и устройств, которые постоянно генерируют данные, часто в больших количествах и в форматах, которые могут быть сложными для обработки. Источники реальных данных часто включают:
- Устройства и датчики IoT
- Логи серверов
- Активность приложений
- Онлайн-реклама
- События изменений в базах данных
- Потоки кликов на веб-сайтах
- Платформы социальных сетей
- Транзакционные базы данных
Эффективное управление и анализ этих потоков данных требует robust инфраструктуры, способной обрабатывать неструктурированные и semi-structured данные; это позволяет бизнесам извлекать ценные инсайты и принимать решения в реальном времени.
Критические проблемы в современных каналах данных
Современные каналы данныхканалы данных сталкиваются с несколькими проблемами, включая поддержаниекачества данных, обеспечениеточных преобразований иминимизацию простоев канала:
- Плохое качество данных может привести к ошибочным инсайтам.
- Преобразования данных сложны и требуют точного скриптинга.
- Частые простои нарушают работу, делая системы с容忍имостью к сбоям必需ыми.
Additionally, управление данными является критически важным для обеспечения консистентности данных и надежности в процессах. Масштабируемость – это другая ключевая проблема, так как管道 должны справляться с колеблющимися объемами данных, и правильное мониторинг и оповещение имеют решающее значение для предотвращения неожиданных сбоев и обеспечения бесперебойной работы.
Продвинутые архитектуры и сценарии применения потоковой обработки данных в реальном времени
Этот раздел демонстрирует возможности современных систем обработки данных для обработки и анализа данных в движении, предоставляя организациям инструменты для реагирования на динамические события в миллисекунды.
Шаги для создания потоковой обработки данных в реальном времени
Для создания эффективной потоковой обработки данных в реальном времени необходимо следовать серии структурированных шагов, которые обеспечивают гладкий поток данных, их обработку и масштабируемость. Таблица 1, приведенная ниже, описывает ключевые шаги, входящие в создание robust потоковой обработки данных в реальном времени:
Таблица 1. Шаги для создания потоковой обработки данных в реальном времени
| step | activities performed |
|---|---|
| 1. Ввод данных | Настроить систему для capture данных из различных источников в реальном времени |
| 2. Обработка данных | Очистка, проверка и преобразование данных для обеспечения их готовности к анализу |
| 3. Обработка потоков | Настроить потребителей для извлечения, обработки и анализа данных непрерывно |
| 4. Хранение | Сохранить обработанные данные в подходящем формате для downstream использования |
| 5. Monitoring и масштабирование | Реализовать инструменты для мониторинга производительности конвейера и обеспечения его масштабируемости в соответствии с растущими потребностями в данных |
Ведущие инструменты Open-Source для потоковой передачи
Для создания устойчивых реальных-time данных конвейеров доступны несколько ведущих инструментов open-source для съема, хранения, обработки и аналитики данных, каждый из которых играет ключевую роль в эффективном управлении и обработке大规模 данных потоков.
Open-source инструменты для съема данных:
- Apache NiFi, с его последней версией 2.0.0-M3, предлагает улучшенную масштабируемость и возможности реального времени обработки.
- Apache Airflow используется для оркестрации сложных рабочих процессов.
- Apache StreamSets предоставляет мониторинг и обработку непрерывного потока данных.
- Airbyte упрощает извлечение и загрузку данных, делая его сильным выбором для управления различными потребностями съема данных.
Open-source инструменты для хранения данных:
- Apache Kafka广泛应用于构建实时管道和流应用程序,因其高可扩展性、容错性和速度而受到青睐。
- Apache Pulsar,一个分布式消息系统,提供了强大的可扩展性和持久性,非常适合处理大规模消息传递。
- NATS.io是一个高性能的消息系统,通常用于物联网和云原生应用程序,专为微服务架构设计,为实时数据需求提供轻量级、快速的通信。
- Apache HBase,一个构建在HDFS之上的分布式数据库,提供了强一致性和高吞吐量,非常适合在NoSQL环境中存储大量实时数据。
开源数据处理工具:
- Apache Spark以其内存集群计算而著称,为批处理和流应用程序提供快速处理。
- Apache Flink专为高性能分布式流处理而设计,并支持批处理作业。
- Apache Storm известен своей способностью обрабатывать более миллиона записей в секунду, что делает его极其 быстрым и масштабируемым.
- Apache Apex предлагает unified потоковую и batch обработку.
- Apache Beam предоставляет гибкую модель, которая работает с несколькими执行官ами, такими как Spark и Flink.
- Apache Samza, разработанный LinkedIn, хорошо интегрируется с Kafka и обрабатывает потоковые данные, делая акцент на масштабируемость и容忍ию к сбоям.
- Heron, разработанный Twitter, является платформой для реального времени аналитики, которая совместима со Storm, но предлагает лучшую производительность и изоляцию ресурсов, делая ее подходящей для высокоскоростной потоковой обработки в масштабе.
Open-source инструменты для аналитики данных:
- Apache Kafka позволяет высокопроизводительную, с низкой задержкой обработку потоковых данных в реальном времени.
- Apache Flink предлагает мощную потоковую обработку, идеальную для приложений, требующих распределенных,的状态ных вычислений.
- Apache Spark Streaming интегрирован с более широкой экосистемой Spark и обрабатывает данные в реальном времени и batch в одной и той же платформе.
- Apache Druid и Pinot служат в качестве аналитических баз данных в реальном времени, предлагая возможности OLAP, которые позволяют запрашивать большие наборы данных в реальном времени, делая их особенно полезными для панелей инструментов и приложений бизнес-аналитики.
Примеры реализации
Реальные-world реализации потоковых данных в реальном времени демонстрируют разнообразные способы, с помощью которых эти архитектуры обеспечивают работу критических приложений в различных отраслях, улучшая производительность, принятие решений и операционную эффективность.
Поток данных рыночной информации для систем高频 торговли
В системах高频 торговли, где миллисекунды могутDeterminиратъ разницу между прибылью и убытками, используется Apache Kafka или Apache Pulsar для высокопроизводственного Consumir данных. Apache Flink или Apache Storm обрабатывают малозадерживающие данные, чтобы обеспечить немедленные торговые решения. Эти pipe должны поддерживать extremную масштабируемость и toleratence к сбою, так как любая простои системы или задержка в обработке может привести к пропущенным возможностям торговли или финансовым потерям.
Обработка данных IoT и реального времени сенсоров
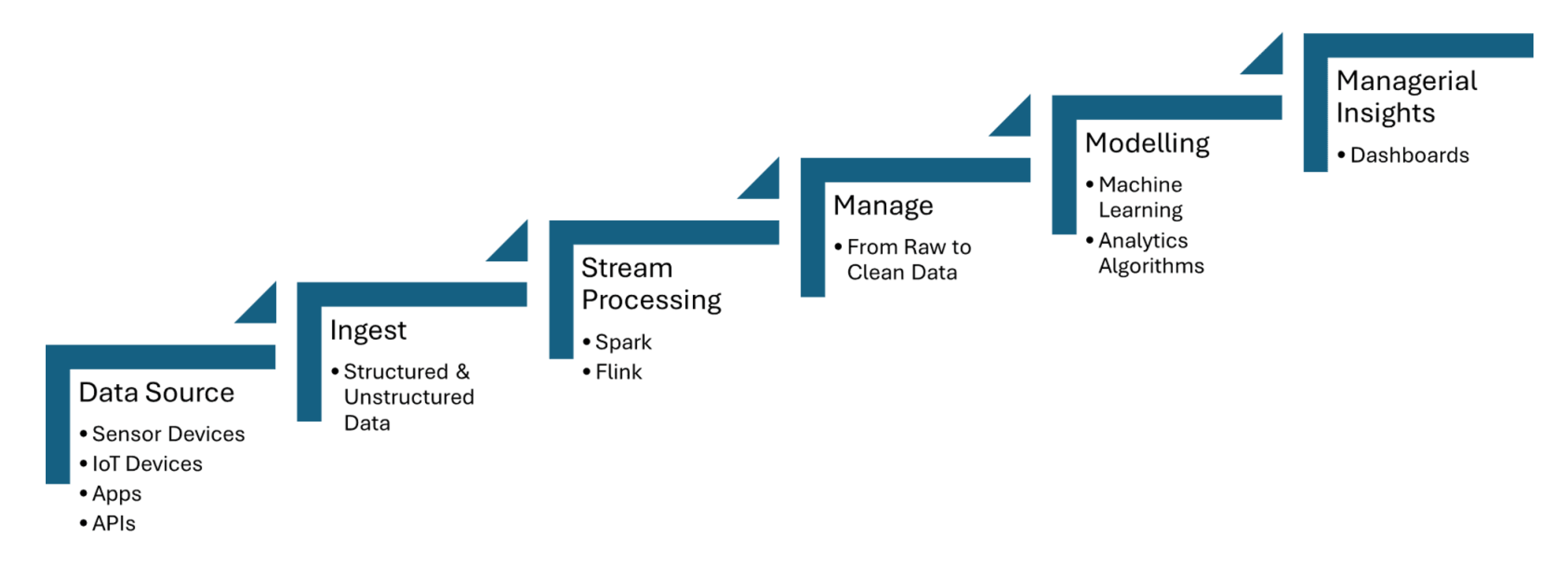
Реальные данные из каналов pipeline-ingestion поступают с датчиков IoT, которые capture информацию, такую как температура, давление или движение, и затем обрабатывают данные с минимальной задержкой. Apache Kafka используется для обработки поступления данных с датчиков, в то время как Apache Flink или Apache Spark Streaming позволяют проводить анализ в реальном времени и обнаружение событий. Рисунок 1, Shared_below, показывает шаги обработки потоковых данных для IoT от источников данных до визуализации:
Рисунок 1. Обработка потоковых данных для IoT
Обнаружение мошенничества по данным транзакций в потоковом режиме
Данные транзакций поступают в реальном времени с использованием таких инструментов, как Apache Kafka, который обрабатывает большие объемы потоковых данных из множества источников, таких как банковские транзакции или системы оплаты. Stream processing frameworks, такие как Apache Flink или Apache Spark Streaming, используются для применения моделей машинного обучения или rule-based систем, которые обнаруживают аномалии в шаблонах транзакций, такие как необычное поведение трат или географические несоответствия.
Как автоматизация ИИ способствует развитию intelligent pipelines и векторных баз данных
Интеллектуальные рабочие процессы используют обработку данных в реальном времени и векторные базы данных для улучшения принятия решений, оптимизации операций и повышения эффективности больших масштабов данныховых сред.
Автоматизация каналов данных
Автоматизация管道 данных позволяет эффективно обрабатывать задачи по поглощению, трансформации и анализу масштабных данных безручного вмешательства. Apache Airflow обеспечивает автоматическое запуска задач в правильное время и в правильной последовательности. Apache NiFi facilitates автоматическое управление потоком данных, обеспечивая реальное время поглощения, трансформации и routing данных. Apache Kafka обеспечивает непрерывную и эффективную обработку данных.
Frameworkы оркестрации管道ов
Frameworkы оркестрации管道ов必需ы для автоматизации и управления рабочими процессами данных структурированным и эффективным образом. Apache Airflow предлагает функции, такие как управление зависимостями и мониторинг. Luigi фокусируется на создании сложных管道ов из batch jobs. Dagster и Prefect предоставляют динамическое управление管道ами и улучшенную обработку ошибок.
Адаптивные管道ы
Адаптивные管道ы спроектированы для динамического соответствия изменениям в средах данных, таких как колебания объема данных, структуры или источников. Apache Airflow или Prefect позволяют для реальной реакции в реальном времени, автоматизируя зависимости задач и планирование на основе текущих условий管道а. Эти管道ы могут использовать frameworkы, такие как Apache Kafka для масштабируемого потокового данные и Apache Spark для адаптивной обработки данных, обеспечивая эффективное использование ресурсов.
Потоковые管道ы
Потоковая магистраль для заполнения векторной базы данных для реального времени retrieval-augmented generation (RAG) может быть полностью построена с использованием таких инструментов, как Apache Kafka и Apache Flink. Обработанные струйные данные затем преобразуются в嵌入динги и хранятся в векторной базе данных, что позволяет выполнять эффективный семантический поиск. Эта реальная архитектура обеспечивает, что большие языковые модели (LLMs) имеют доступ к актуальной, контекстуально значимой информации, улучшая точность и надежность приложений на основе RAG, таких как чат-боты или системы рекомендаций.
Потоковая передача данных в качестве данных Fabric для Generative AI
Реальное время потоковой передачи данных обеспечивает реальное время приема, обработки и retrieval vast amounts of data, которые LLMs требуют для генерации точных и актуальных ответов. В то время как Kafka помогает в потоковой передаче, Flink обрабатывает эти потоки в реальном времени, обеспечивая, что данные обогащены и контекстуально значимы перед тем, как они поступают в векторные базы данных.
Дорога впереди: Гарантияfuture Proofing данных магистралей
Интеграция потоковых данных в реальном времени, автоматизации ИИ и векторных баз данных предлагает трансформационный потенциал для бизнеса. Для автоматизации ИИ, интеграция потоковых данных в реальном времени с фреймворками, такими как TensorFlow или PyTorch, позволяет принимать решения в реальном времени и обновлять модели непрерывно. Для быстрого контекстного извлечения данных в реальном времени, использование баз данных, таких как Faiss или Milvus, помогает в быстром семантическом поиске, что критически важно для приложений, таких как RAG.
Заключение
Основные выводы включают ключевую роль инструментов, таких как Apache Kafka и Apache Flink, для масштабируемого потокового ввода данных с низкой задержкой, а также TensorFlow или PyTorch для автоматизации ИИ в реальном времени, и FAISS или Milvus для быстрого семантического поиска в приложениях, таких как RAG. Обеспечение качества данных, автоматизация рабочих процессов с помощью таких инструментов, как Apache Airflow, и внедрение robustных механизмов мониторинга и fault-tolerance помогут бизнесу оставаться гибким в мире, основанном на данных, и оптимизировать свои возможности для принятия решений.
Дополнительные ресурсы:
- Основы автоматизации ИИ Тухина Чаттопадхая, DZone Refcard
- Основы Apache Kafka Sudip Sengupta, DZone Refcard
- Начало работы с большими языковыми моделями Tuhin Chattopadhyay, DZone Refcard
- Начало работы с векторными базами данных Miguel Garcia, DZone Refcard
Это отрывок из отчета DZone за 2024 год,
Инженерия данных: Обогащение каналов данных, расширение ИИ и ускорение аналитики.
Source:
https://dzone.com/articles/the-data-pipeline-movement