













編輯按註:以下文章為投稿並發表於DZone的2024趨勢報告,數據工程:豐富數據管道、擴展人工智能、加速分析。
本文探討如何利用實時數據流來驅動可行動的洞見,並通過人工智能自動化和向量數據庫來為系統未來做準備。它深入研究了不斷進化的架構和工具,這些工具使企業能在數據驅動的世界中保持靈活性和競爭力。
實時數據流:演進和關鍵考慮
實時數據流已從傳統的批量處理發展而來,在批量處理中,數據以間隔方式處理,導入延遲,現在則持續處理生成的數據,能夠對關鍵事件做出即時反應。通過整合人工智能、自動化和向量數據庫,企業可以進一步提升其能力,使用實時見解來預測結果、優化運作,並有效地管理大規模、複雜的數據集。
實時流的必要性
需要對生成的數據立即進行處理,特別是在欺詐偵測、日誌分析或客戶行為追蹤等場景中。實時流式傳輸讓組織能夠即時捕獲、處理和分析數據,從而能夠迅速對動態事件做出反應,優化決策,並實時提升客戶體驗。
實時數據來源
實時數據來自各種不斷生成數據的系統和設備,這些數據通常數量龐大且格式複雜,難以處理。實時數據的來源通常包括:
- 物联网設備和傳感器
- 服務器日誌
- 應用程序活動
- 線上廣告
- 數據庫變更事件
- 網站點擊流
- 社交媒體平台
- 交易數據庫
有效地管理和分析這些數據流需要一個健壯的基礎設施,能夠處理非結構化和半結構化數據;這讓企業能夠提取有價值的見解並做出實時決策。
當代數據管道的關鍵挑戰
當代的數據管道 面临多種挑戰,包括維護數據質量、確保準確的數據轉換,以及最小化管道停機時間:
- 數據質量不佳可能導致錯誤的見解。
- 數據轉換複雜且需要精確的編腳本。
- 經常性的系統中斷會干擾運作,使得故障容錯系統變得必要。
此外,數據治理對確保數據一致性和可靠性在整個流程中至關重要。可擴展性是另一個關鍵問題,因為管道必須處理波動的數據量,適當的監控和警示對避免意外故障和確保順暢運作至關重要。
先進的實時數據流架構和應用場景
本節展示了現代數據系統處理和分析移動中數據的能力,為組織提供了在千分之一秒內對動態事件做出反應的工具。
建立實時數據管道的步驟
為了創建一個有效的實時數據管道,遵循一系列結構化的步驟以確保數據流、處理和可擴展性是至關重要的。以下共享的表1概述了構建健壯的實時數據管道的關鍵步驟:
表1。建立實時數據管道的步驟
| step | activities performed |
|---|---|
| 1. 數據引入 | 設置一個系統以實時從各種來源捕捉數據流 |
| 2. 數據處理 | 清洗、驗證和轉換數據,確保其適合分析 |
| 3. 流處理 | 配置消費者以連續地拉取、處理和分析數據 |
| 4. 儲存 | 將處理過的數據以適當的格式存儲,供下游使用 |
| 5. 監控與擴展 | 實現工具以監控管道性能並確保其能夠隨著數據需求的增加而擴展 |
主流開源流式處理工具
為了建立堅固的實時數據管道,有多種主流開源工具可用於數據接入、存儲、處理和分析,它們各自在高效管理和處理大規模數據流中發揮關鍵作用。
開源數據接入工具:
- Apache NiFi,以其最新的2.0.0-M3版本,提供了增強的擴展性和實時處理能力。
- Apache Airflow用於編排複雜的工作流程。
- Apache StreamSets提供持續數據流監控和處理。
- Airbyte簡化了數據提取和加載,使其成為管理多樣化數據接入需求的一個強勁選擇。
開源數據存儲工具:
- Apache Kafka 因其高可擴展性、容錯性和速度而被廣泛用於構建實時管道和流應用程序。
- Apache Pulsar 是一個分佈式消息系統,具有強大的可擴展性和耐用性,非常適合處理大規模消息。
- NATS.io 是一個高性能的消息系統,常見於物联网和云原生應用程序中,為微服務架構設計,並為實時數據需求提供輕量級、快速的通信。
- Apache HBase 是一個建立在 HDFS 之上的分佈式數據庫,提供強一致性和高通量,非常適合在 NoSQL 環境中存儲大量實時數據。
開源數據處理工具:
- Apache Spark 以其內存集群計算脫穎而出,為批处理和流應用程序提供快速處理。
- Apache Flink 設計用於高性能力分佈式流處理,並支持批处理任務。
- Apache Storm以其每秒處理超過一百萬筆記錄的能力而聞名,使其具有極高的速度和可擴展性。
- Apache Apex提供統一的流和批處理。
- Apache Beam提供一種與多種執行引擎如Spark和Flink兼容的靈活模型。
- Apache Samza,由LinkedIn開發,與Kafka整合良好,並著重於可擴展性和容錯的流處理。
- Heron,由Twitter開發,是一個實時分析平台,與Storm高度兼容但提供更好的性能和資源隔離,使其適合於高速的規模化流處理。
開源數據分析工具:
- Apache Kafka允許高吞吐量、低延時的實時數據流處理。
- Apache Flink提供強大的流處理能力,適合於需要分佈式、有狀態計算的應用程序。
- Apache Spark Streaming與更廣泛的Spark生態系統整合,能夠在同一個平臺上處理實時和批量數據。
- Apache Druid與Pinot作為實時分析數據庫,提供OLAP功能,能夠對大數據集進行實時查詢,使其特別適用於仪表板和商業智能應用。
實施應用案例
實時數據管道的現實世界實施展示了這些架構在各行各業關鍵應用中提升性能、決策制定和運營效率的多種方式。
為高頻交易系統提供金融市場數據流
在高頻交易系統中,毫秒之差可能決定盈利與損失,Apache Kafka或Apache Pulsar用於高吞吐量數據引入。Apache Flink或Apache Storm負責低延遲處理,確保交易決策能夠即時做出。這些管道必須支持極端可縮放性和故障容錯,因為任何系統停機或處理延遲都可能導致錯過交易機會或造成金融損失。
物聯網和實時傳感器數據處理
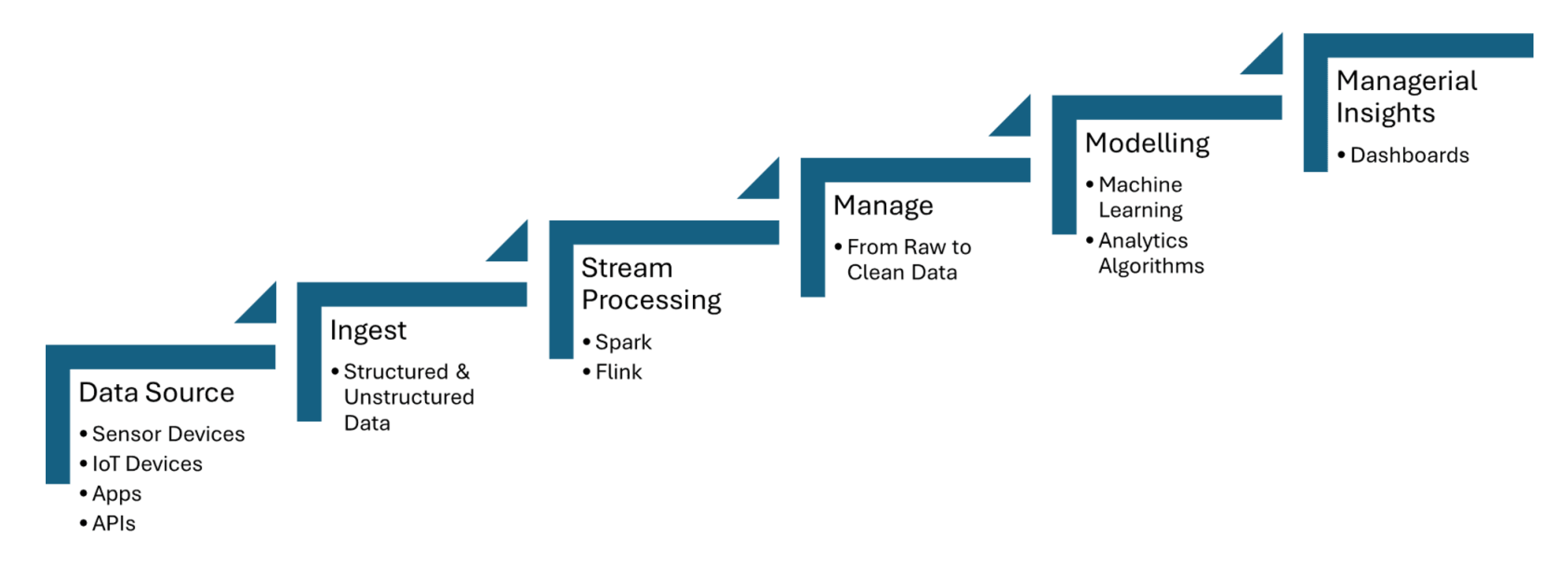
實時數據管道從IoT傳感器中匯入數據,這些傳感器捕捉如溫度、壓力或運動等信息,並在最小延遲下處理數據。Apache Kafka用於處理傳感器的數據匯入,而Apache Flink或Apache Spark Streaming則實現實時分析與事件偵測。以下共享的圖1展示了從數據源到儀表板的IoT流處理步驟:
圖1。IoT流處理
從交易數據流進行欺詐偵測
交易數據使用如Apache Kafka的工具實時匯入,它能夠處理來自多個來源的大量流動數據,例如銀行交易或支付閘道。流處理框架如Apache Flink或Apache Spark Streaming用於應用機器學習模型或基於規則的系統,以偵測交易模式中的異常,如不尋常的消費行為或地理位置的差異。
AI自動化如何驅動智能管道與向量數據庫
智能工作流利用實時數據處理和向量數據庫來提升決策質量、優化運作,並改善大型數據環境的效率。
數據管道自動化
數據管道自動化能夠在無需人工干預的情況下,高效地處理大規模數據吸入、轉換和分析任務。Apache Airflow 確保任務在正確的時間以正確的順序自動觸發。Apache NiFi 促進自動化數據流管理,實現實時數據吸入、轉換和路徑。Apache Kafka 確保數據持續且高效地被處理。
管道編排框架
管道編排框架對於以結構化和高效的方式自動化和管理數據工作流至關重要。Apache Airflow 提供了如依賴性管理和監控等功能。Luigi 重點在於構建複雜的批處理管道。Dagster 和 Prefect 提供動態管道管理與增強的錯誤處理。
自適應管道
自適應管道設計用於動態調整變化的數據環境,例如數據量、結構或來源波動。Apache Airflow 或 Prefect 能夠通過自動化任務依賴性和基於當前管道條件的調度,實現實時反應。這些管道可以利用 Apache Kafka 這樣的框架進行可擴展的數據流,以及 Apache Spark 進行自適應數據處理,確保高效的資源使用。
流式管道
一個用于填充向量數據庫以進行實時檢索增強生成(RAG)的流式管線可以完全使用像Apache Kafka和Apache Flink這樣的工具來构建。處理過的流式數據然後被轉換成嵌入向量並存儲在向量數據庫中,從而實現高效的語義搜索。這種實時架構確保了大型語言模型(LLMs)能夠訪問最新、與上下文相關的信息,從而提高基于RAG的應用程序(如聊天機器人或推薦引擎)的準確性和可靠性。
數據流作為生成式AI的數據織布
實時數據流使能實時地摄取、處理和檢索大量數據,這些數據是LLMs生成準確且最新的回應所必需的。當Kafka在進行流式傳輸時,Flink則實時處理這些數據流,確保在數據被送入向量數據庫之前進行豐富和與上下文相關的處理。
未來之路:數據管線的未來證實
實時數據流、AI 自動化以及向量數據庫的整合為企業帶來了轉型的潛力。對於 AI 自動化,將實時數據流與如TensorFlow或PyTorch的框架整合,能夠實現實時決策和持續的模型更新。對於實時情境數據的檢索,利用如Faiss或Milvus的數據庫有助於快速進行語義搜索,這對於像 RAG 這樣的應用至關重要。
結論
關鍵的觀察點包括 Apache Kafka 和 Apache Flink 在可擴展、低延遲數據流中的重要作用,以及 TensorFlow 或 PyTorch 在實時 AI 自動化中的應用,还有 FAISS 或 Milvus 在像 RAG 這樣的應用中進行快速語義搜索的能力。確保數據質量、使用如 Apache Airflow 的工具自動化工作流程,並實施強大的監控和故障容許機制將幫助企業在數據驅動的世界中保持靈活性,並優化其決策能力。
額外資源:
- AI Automation Essentials 由 Tuhin Chattopadhyay,DZone Refcard 撰寫。
- Apache Kafka 完全指南 作者:Sudip Sengupta,DZone 參考卡
- 大型語言模型入門 作者:Tuhin Chattopadhyay,DZone 參考卡
- 向量數據庫入門 作者:Miguel Garcia,DZone 參考卡
這是來自 DZone 2024 趋勢報告的摘錄,
數據工程:豐富數據管道,擴展人工智能,加速分析。
Source:
https://dzone.com/articles/the-data-pipeline-movement