













編集者の注:以下は、DZoneの2024トレンドレポートに書かれ、発表された記事です。データエンジニアリング:データパイプラインを豊かにし、AIを拡張し、アナリティクスを迅速化する.
この記事では、リアルタイムデータストリーミングを活用して行動可能なインサイトを駆動させ、AI自動化とベクターダータベースを通じてシステムを将来に備える方法について探求します。また、企業がデータ駆動の世界で機敏で競争力を保つために力を貸す進化するアーキテクチャとツールについて詳述しています。
リアルタイムデータストリーミング:進化と主要な考慮事項
リアルタイムデータストリーミングは、データが間隔で処理され、遅延を引き起こす従来のバッチ処理から進化し、データが生成されるたびに処理を続け、重大なイベントに対する即時対応を可能にしました。AI、自動化、およびベクターダータベースを統合することで、企業はさらに能力を強化し、リアルタイムのインサイトを活用して予測、オペレーションの最適化、そして大規模で複雑なデータセットの効率的な管理を行うことができます。
リアルタイムストリーミングの必要性
データが生成されたと同時にそれに対応する必要があります。特に詐欺検知、ログ解析、顧客行動追跡のようなシナリオではその必要性が高まります。リアルタイムストリーミングにより、組織はデータを即座にキャプチャし、処理し、分析することができ、動的イベントに迅速に対応し、意思決定を最適化し、リアルタイムで顧客体験を向上させることができます。
リアルタイムデータのソース
リアルタイムデータは、多くの場合大量のデータを連続的に生成するさまざまなシステムやデバイスから発生します。リアルタイムデータのソースは以下の通りです:
- IoTデバイスおよびセンサー
- サーバーログ
- アプリ活動
- オンライン広告
- データベース変更イベント
- ウェブサイトクリックストリーム
- ソーシャルメディアプラットフォーム
- トランザクションデータベース
これらのデータストリームを効果的に管理し、分析するためには、非構造データおよび準構造データを処理できる強固なインフラが必要です;これにより企業は価値ある洞察を抽出し、リアルタイムで意思決定を行うことができます。
現代のデータパイプラインにおける重要な課題
現代のデータパイプラインは、データ品質の維持、正確な変換の確保、パイプラインのダウンタイムの最小化などのいくつかの課題に直面しています:
- データ品質の低さは誤った洞察を導く可能性があります。
- データ変換は複雑であり、正確なスクリプトを必要とします。
- 頻繁なダウンタイムは運営を妨げ、耐障害性のあるシステムが不可欠です。
また、データガバナンスは、データの一貫性と信頼性をプロセス全体で確保するために重要です。スケーラビリティもまた鍵となる問題であり、パイプラインは変動するデータ量を処理する必要があり、適切なモニタリングとアラートは予期せぬ障害を回避し、スムーズな運営を確保するために不可欠です。
高度なリアルタイムデータストリーミングアーキテクチャとアプリケーションシナリオ
この節では、現代のデータシステムがデータの動きを処理および分析する能力を示し、組織にミリ秒単位で動的イベントに対応するためのツールを提供しています。
リアルタイムデータパイプラインを構築する手順
効果的なリアルタイムデータパイプラインを構築するためには、データの流れ、処理、スケーラビリティをスムーズにする一連の構造化された手順を守ることが不可欠です。以下に共有するテーブル1は、強固なリアルタイムデータパイプラインを構築するための主要な手順を概括しています:
テーブル1。リアルタイムデータパイプラインを構築する手順
| step | activities performed |
|---|---|
| 1. データインジェスション | リアルタイムでさまざまなソースからのデータストリームをキャプチャするシステムを設定する |
| 2. データ処理 | データをクリーンアップし、検証し、変換して分析の準備を整える |
| 3. ストリーム処理 | コンシューマーを設定してデータを引き続き引き出し、処理、分析する |
| 4. ストレージ | 処理されたデータを適切な形式で下游の利用に保存する |
| 5. 監視とスケーリング | パイプラインのパフォーマンスを監視するツールを実装し、データの要求が増加するに伴ってスケーリングできるようにします |
主要なオープンソースストリーミングツール
強固なリアルタイムデータパイプラインを構築するためには、データのインgestion、ストレージ、処理、分析にそれぞれ重要な役割を果たすいくつかの主要なオープンソースツールが利用可能です。これらは大規模データストリームの管理と処理を効率的に行うのに役立ちます。
データインgestionのためのオープンソースツール:
- Apache NiFiは最新の2.0.0-M3バージョンで強化されたスケーリングとリアルタイム処理機能を提供します。
- Apache Airflowは複雑なワークフローのオーケストレーションに使用されます。
- Apache StreamSetsは連続的なデータフローの監視と処理を提供します。
- Airbyteはデータの抽出とロードを簡素化し、多様なデータインgestionニーズを管理する強力な選択肢です。
データストレージのためのオープンソースツール:
- Apache Kafkaはその高 expand 性、信頼性、そして速度の高さもあって、リアルタイムパイプラインやストリーミングアプリケーションの構築に広く使用されています。
- Apache Pulsarは分布式メッセージングシステムで、強力な expand 性と耐久性を持ち、大規模メッセージの処理に適しています。
- NATS.ioは高パフォーマンスなメッセージングシステムで、IoTやクラウドネイティブアプリケーションで一般的に使用され、マイクロサービスアーキテクチャに最適化され、リアルタイムデータのニーズに対応する軽量で高速な通信を提供しています。
- Apache HBaseはHDFS上に構築された分布式データベースで、強力な一貫性と高スループットを提供し、NoSQL環境での大量のリアルタイムデータの保存に適しています。
データ処理のためのオープンソースツール:
- Apache Sparkはメモリ内クラスター計算により、バッチ処理とストリーミングアプリケーションの両方に高速処理を提供しています。
- Apache Flinkは高パフォーマンスな分布式ストリームプロセッシングを目的に設計されており、バッチジョブもサポートしています。
- Apache Stormは1秒間に100万以上のレコードを処理できる能力で知られ、非常に高速で拡張可能です。
- Apache Apexは統一されたストリームとバッチ処理を提供しています。
- Apache Beamは、SparkやFlinkなどの複数の実行エンジンで動作する柔軟なモデルを提供しています。
- Apache SamzaはLinkedInによって開発され、Kafkaとよく統合され、スケーラビリティと耐故障性に焦点を当てたストリーム処理を行っています。
- HeronはTwitterによって開発されたリアルタイムアナリティクスプラットフォームで、Stormと非常に互換性が高く、パフォーマンスとリソースの隔離が向上していて、大規模な高速ストリーム処理に適しています。
データ分析のためのオープンソースツール:
- Apache Kafkaは、ハイスループットで低遅延のリアルタイムデータストリームを処理できます。
- Apache Flinkは強力なストリーム処理を提供し、分散型で状態を保持する計算を必要とするアプリケーションに適しています。
- Apache Spark Streamingは、より広範なSparkエコシステムと統合し、リアルタイムデータとバッチデータを同じプラットフォームで処理します。
- Apache DruidとPinotは、リアルタイム分析データベースとして機能し、OLAP機能を提供して、大規模なデータセットをリアルタイムでクエリ可能にし、ダッシュボードやビジネスインテリジェンスアプリケーションに特に役立ちます。
実装のユースケース
リアルタイムデータパイプラインの現実世界の実装は、これらのアーキテクチャが異なる産業の重要なアプリケーションを強化し、パフォーマンス、意思決定、運用効率を向上させるさまざまな方法を示しています。
高频取引システムのための金融市場データストリーミング
ミリ秒が利益と損失の差を決める高频取引システムでは、Apache KafkaまたはApache Pulsarが高スループットデータインジェスションに使用されます。Apache FlinkまたはApache Stormは低遅延処理を担当し、取引決定を即座に行うことを確保します。これらのパイプラインは、システムダウンや処理遅延が取引機会の損失や金融損失につながるため、極限のスケーラビリティと耐障害性をサポートする必要があります。
IoTおよびリアルタイムセンサデータ処理
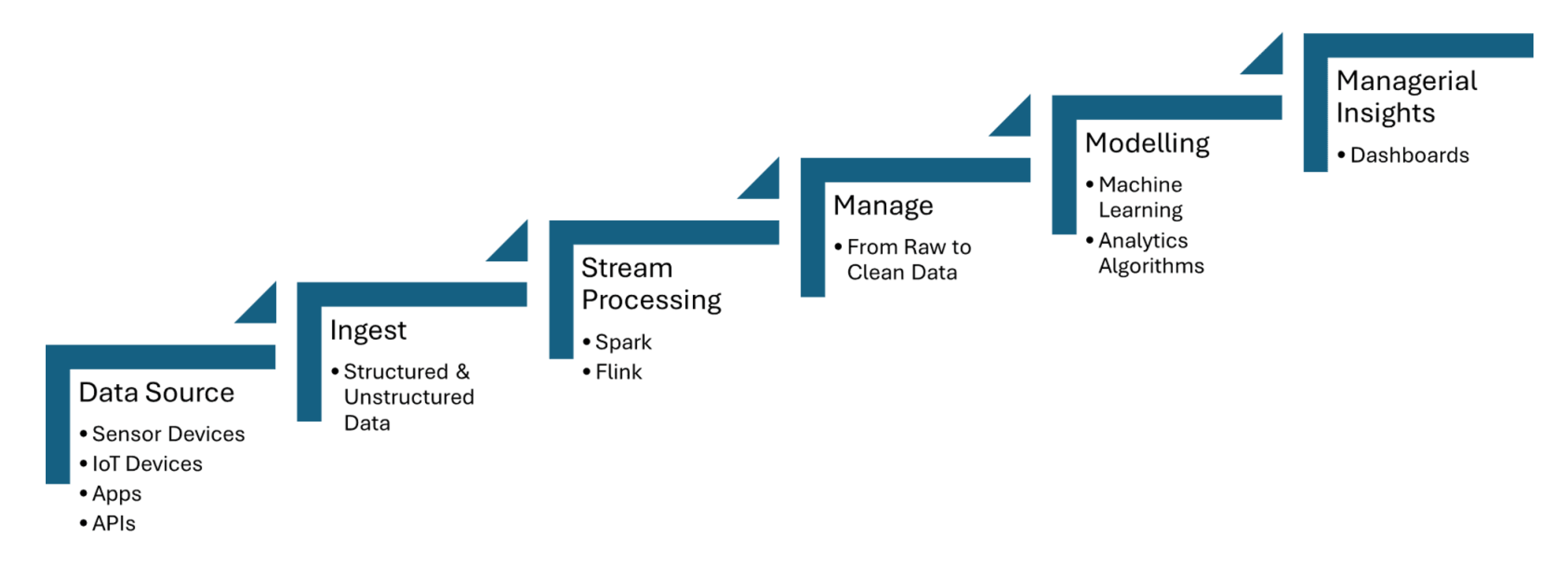
リアルタイムデータパイプラインは、温度、圧力、または動きなどの情報をキャプチャするIoTセンサーからのデータをインジェストし、最小のレイテンシでデータを処理します。Apache Kafkaはセンサーデータのインジェストを処理するために使用され、Apache FlinkまたはApache Spark Streamingはリアルタイム分析およびイベント検出を可能にします。以下に示される図1は、データソースからダッシュボードまでのIoTストリーム処理の手順を示しています:
図1. IoTのためのストリーム処理
トランザクションデータからの不正検知ストリーミング
トランザクションデータは、銀行取引や決済ゲートウェイなどの複数のソースからの大量のストリーミングデータを処理するApache Kafkaなどのツールを使用してリアルタイムでインジェストされます。ストリーム処理フレームワークであるApache FlinkまたはApache Spark Streamingは、異常な支出行動や地理的乖離など、トランザクションパターンにおけるアノマリーを検出するために機械学習モデルやルールベースシステムを適用します。
AI自動化がインテリジェントパイプラインとベクターダータベースを駆動させる方法
インテリジェントワークフローは、リアルタイムデータ処理とベクターダータベースを活用して、意思決定を強化し、運用を最適化し、大規模データ環境の効率を向上させます。
データパイプライン自動化
データパイプライン自動化は、手動介入なしで大規模なデータインゲスション、変換、分析タスクを効率的に処理することを可能にします。Apache Airflowは、タスクが適切な時間に自動的にトリガーされ、正しい順序で実行されることを确保します。Apache NiFiは、自動化されたデータフローの管理を容易にし、リアルタイムのデータインゲスション、変換、ルーティングを可能にします。Apache Kafkaは、データの連続的な処理を効率的に行います。
パイプラインオーケストレーションフレームワーク
パイプラインオーケストレーションフレームワークは、データワークフローの自動化と管理を構造化された効率的な方法で行うために不可欠です。Apache Airflowは依存関係管理や監視機能を提供します。Luigiは、バッチジョブの複雑なパイプラインを構築することに焦点を当てています。DagsterとPrefectは、動的なパイプライン管理と強化されたエラーハンドリングを提供します。
適応型パイプライン
適応型パイプラインは、データボリューム、構造、ソースの変動などの変化するデータ環境に動的に適応するように設計されています。Apache AirflowやPrefectは、現在のパイプライン条件に基づいてタスクの依存関係とスケジューリングを自動化することで、リアルタイムの応答性を提供します。これらのパイプラインは、スケーラブルなデータストリーミングにApache Kafkaを、適応型データ処理にApache Sparkを活用し、効率的なリソース利用を確保します。
ストリーミングパイプライン
ストリーミングパイプラインを用いて、リアルタイム検索強化生成(RAG)のためのベクタデータベースを構築することができ、これはApache KafkaやApache Flinkなどのツールを完全に使用して行うことができます。処理されたストリーミングデータはエンコ딜に変換され、ベクタデータベースに格納され、効率的なセマンティックサーチを可能にします。このリアルタイムアーキテクチャにより、大規模言語モデル(LLM)は最新で文的に適切な情報にアクセスできるようになり、チャットボットや推薦エンジンなどのRAGベースアプリケーションの精度と信頼性が向上します。
データストリーミングを生成型AIのためのデータファ브リックとして
リアルタイムデータストリーミングは、LLMが正確で最新の回答を生成するために必要とする大量のデータのリアルタイムインジェスト、処理、および検索を可能にします。Kafkaはストリーミングを助け、Flinkはこれらのストリームをリアルタイムで処理し、データが豊かになり文的に適切になる前にベクタデータベースにフィードされることを確実にします。
今後の道筋:データパイプラインの将来に備える
リアルタイムデータストリーミング、AIオートメーション、ベクターダータベースの統合は、企業に変革的な可能性をもたらします。AIオートメーションにおいては、リアルタイムデータストリームをTensorFlowやPyTorchなどのフレームワークと統合することで、リアルタイムでの意思決定とモデルの継続的な更新が可能になります。リアルタイムの文脈データの検索には、FaissやMilvusなどのデータベースを活用し、迅速な意味検索が重要なアプリケーションであるRAGに役立ちます。
結論
主要なポイントとしては、スケーラブルで低遅延のデータストリーミングにApache KafkaやApache Flinkが不可欠な役割を果たすこと、TensorFlowやPyTorchがリアルタイムAIオートメーションに使用されること、そしてRAGのようなアプリケーションにおける迅速な意味検索にFAISSやMilvusが使用されることが含まれます。データの品質を確保し、Apache Airflowなどのツールでワークフローの自動化を行い、強固な監視と故障toleranceメカニズムを導入することで、企業はデータ駆動型の世界で機敏に対応し、意思決定能力を最適化することができます。
追加リソース:
- AI Automation Essentials by Tuhin Chattopadhyay, DZone Refcard
- Apache Kafkaの基本 by Sudip Sengupta, DZone Refcard
- 大規模言語モデルの始め方 by Tuhin Chattopadhyay, DZone Refcard
- ベクターデータベースの始め方 by Miguel Garcia, DZone Refcard
これはDZoneの2024年トレンドレポートからの抜粋です,
データエンジニアリング: データパイプラインの強化、AIの拡張、アナリティクスの迅速化.
Source:
https://dzone.com/articles/the-data-pipeline-movement