













Anmerkung der Redaktion: Der folgende Artikel wurde für den DZone Trend Report 2024 geschrieben und veröffentlicht, Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
Dieser Artikel untersucht die wesentlichen Strategien zur Nutzung von Echtzeit-Datenströmen, um verwertbare Erkenntnisse zu gewinnen und gleichzeitig Systeme durch KI-Automatisierung und Vektor-Datenbanken zukunftssicher zu machen. Er befasst sich mit den sich entwickelnden Architekturen und Tools, die es Unternehmen ermöglichen, in einer datengesteuerten Welt agil und wettbewerbsfähig zu bleiben.
Real-Time Data Streaming: The Evolution and Key Considerations
Real-Time Data Streaming hat sich von der traditionellen Batch-Verarbeitung, bei der Daten in Intervallen verarbeitet wurden, die zu Verzögerungen führten, zu einer kontinuierlichen Verarbeitung von Daten in dem Moment entwickelt, in dem sie generiert werden, und ermöglicht sofortige Reaktionen auf kritische Ereignisse. Durch die Integration von KI, Automatisierung und Vektordatenbanken können Unternehmen ihre Fähigkeiten weiter ausbauen, indem sie Echtzeiterkenntnisse nutzen, um Ergebnisse vorherzusagen, Abläufe zu optimieren und große, komplexe Datensätze effizient zu verwalten.
Notwendigkeit von Echtzeit-Streaming
Es gibt die Notwendigkeit, Daten so schnell wie möglich zu verarbeiten, insbesondere in Szenarien wie Betrugsbekämpfung, Protokollanalyse oder das Tracking von Kundenverhalten. Echtzeit-Streaming ermöglicht es Organisationen, Daten sofort zu erfassen, zu verarbeiten und zu analysieren, allowing ihnen, schnell auf dynamische Ereignisse zu reagieren, Entscheidungen zu optimieren und Kundenerfahrungen in Echtzeit zu verbessern.
Quellen von Echtzeit-Daten
Echtzeitdaten stammen aus verschiedenen Systemen und Geräten, die kontinuierlich Daten erzeugen, oft in großen Mengen und in Formaten, die schwer zu verarbeiten sind. Quellen von Echtzeitdaten umfassen oft:
- IoT-Geräte und Sensoren
- Server-Protokolle
- App-Aktivität
- Online-Werbung
- Veränderungsereignisse in Datenbanken
- Website-Klickströme
- Soziale Medien-Plattformen
- Transaktions-Datenbanken
Die effektive Verwaltung und Analyse dieser Datenströme erfordert eine robuste Infrastruktur, die in der Lage ist, unstrukturierte und teilstrukturierte Daten zu handhaben; dies ermöglicht es Unternehmen, wertvolle Einblicke zu gewinnen und Echtzeit-Entscheidungen zu treffen.
Kritische Herausforderungen in modernen Daten-Pipelines
Modernen Daten-Pipelines stehen mehrere Herausforderungen gegenüber, einschließlich der Aufrechterhaltung der Datenqualität, der Sicherstellung genauer Transformationen und der Minimierung von Ausfallzeiten der Pipeline:
- Schlechte Datenqualität kann zu fehlerhaften Einblicken führen.
- Daten-Transformationen sind komplex und erfordern präzises Skripting.
- Häufige Ausfälle stören den Betrieb, weshalb fehlertolerante Systeme unerlässlich sind.
Darüber hinaus ist Datenverwaltung entscheidend, um Datenkonsistenz und Zuverlässigkeit über Prozesse hinweg zu gewährleisten. Skalierbarkeit ist ein weiteres Schlüsselproblem, da Pipes wechselnde Datenmengen bewältigen müssen, und eine ordnungsgemäße Überwachung sowie Alarmierung sind für die Vermeidung unerwarteter Ausfälle und die Sicherstellung eines reibungslosen Betriebs von entscheidender Bedeutung.
Fortgeschrittene Echtzeit-Daten-Streaming-Architekturen und Anwendungsszenarien
Dieser Abschnitt demonstrates die Fähigkeiten moderner Daten-systeme zur Verarbeitung und Analyse von Daten in Bewegung, und bietet Organisationen die Werkzeuge, um auf dynamische Ereignisse in Millisekunden zu reagieren.
Schritte zur Erstellung einer Echtzeit-Daten-Pipeline
Zur Erstellung einer effektiven Echtzeit-Daten-Pipeline ist es unerlässlich, einer Reihe strukturierte Schritte zu befolgen, die einen reibungslosen Datenfluss, die Verarbeitung und die Skalierbarkeit sicherstellen. Tabelle 1, die unten geteilt wird, skizziert die wichtigsten Schritte bei der Erstellung einer robusten Echtzeit-Daten-Pipeline:
Tabelle 1. Schritte zur Erstellung einer Echtzeit-Daten-Pipeline
| step | activities performed |
|---|---|
| 1. Daten-ingest | Ein System einrichten, um Datenströme aus verschiedenen Quellen in Echtzeit zu erfassen |
| 2. Datenverarbeitung | Daten bereinigen, validieren und transformieren, um sicherzustellen, dass sie für die Analyse bereit sind |
| 3. Stream-Verarbeitung | Consumers konfigurieren, um Daten kontinuierlich abzurufen, zu verarbeiten und zu analysieren |
| 4. Speicherung | Verarbeitete Daten in einem geeigneten Format für die nachgelagerte Nutzung speichern |
| 5. Überwachung und Skalierung | Implementieren Sie Tools zur Überwachung der Pipeline-Leistung und stellen Sie sicher, dass diese mit steigenden Datenanforderungen skaliert werden kann |
Leading Open-Source Streaming Tools
Um robuste Echtzeit-Datenpipelines zu erstellen, stehen mehrere führende Open-Source-Tools für die Datenintegration, Speicherung, Verarbeitung und Analyse zur Verfügung, die jeweils eine entscheidende Rolle bei der effizienten Verwaltung und Verarbeitung großer Datenströme spielen.
Open-Source-Tools für die Datenintegration:
- Apache NiFi, mit seiner neuesten 2.0.0-M3 Version, bietet erweiterte Skalierbarkeit und Echtzeit-Verarbeitungsfähigkeiten.
- Apache Airflow wird zur Orchestrierung komplexer Workflows verwendet.
- Apache StreamSets bietet kontinuierliche Datenflussüberwachung und -verarbeitung.
- Airbyte vereinfacht die Datenextraktion und -ladung und ist eine starke Wahl für die Verwaltung unterschiedlicher Datenintegrationsanforderungen.
Open-Source-Tools für die DatenSpeicherung:
- Apache Kafka wird weitgehend zur Erstellung von Echtzeit-Pipelines und Streaming-Anwendungen aufgrund seiner hohen Skalierbarkeit, Fehlertoleranz und Geschwindigkeit eingesetzt.
- Apache Pulsar, ein verteiltes Nachrichtenübertragungssystem, bietet starke Skalierbarkeit und Haltbarkeit und ist ideal für die Verarbeitung von groß angelegten Nachrichten.
- NATS.io ist ein leistungsstarkes Nachrichtenübertragungssystem, das häufig in IoT- und Cloud-Native-Anwendungen verwendet wird und für Microservices-Architekturen konzipiert ist. Es bietet leichte, schnelle Kommunikation für Echtzeit-Datenbedürfnisse.
- Apache HBase, eine verteilte Datenbank, die auf HDFS aufbaut, bietet starke Konsistenz und hohen Durchsatz und ist ideal zum Speichern großer Mengen Echtzeitdaten in einer NoSQL-Umgebung.
Open-Source-Werkzeuge für die Datenverarbeitung:
- Apache Spark zeichnet sich durch seine In-Memory-Cluster-Rechnung aus und bietet schnelle Verarbeitung sowohl für Batch- als auch für Streaming-Anwendungen.
- Apache Flink ist für die hochleistungsfähige verteilte Stream-Verarbeitung konzipiert und unterstützt Batch-Jobs.
- Apache Storm ist bekannt für seine Fähigkeit, mehr als eine Million Einträge pro Sekunde zu verarbeiten, was es extrem schnell und skalierbar macht.
- Apache Apex bietet eine vereinheitlichte Stream- und Batch-Verarbeitung.
- Apache Beam bietet ein flexibles Modell, das mit mehreren Ausführungs-Engines wie Spark und Flink funktioniert.
- Apache Samza, entwickelt von LinkedIn, integriert sich gut mit Kafka und verarbeitet Stream-Daten mit Fokus auf Skalierbarkeit und Fehlertoleranz.
- Heron, entwickelt von Twitter, ist eine Echtzeit-Analyse-Plattform, die hochgradig kompatibel mit Storm ist, aber bessere Leistung und Ressourcen-Isolation bietet, was es für die hochgeschwindigkeits-Stream-Verarbeitung in großem Maßstab geeignet macht.
Open-Source-Werkzeuge für Datenanalyse:
- Apache Kafka ermöglicht die hochdurchsatzige, niedriglatenzige Verarbeitung von Echtzeit-Datenströmen.
- Apache Flink bietet leistungsstarke Stream-Verarbeitung, ideal für Anwendungen, die verteilte, zustandsbehaftete Berechnungen erfordern.
- Apache Spark Streaming integriert in das breitere Spark-Ökosystem, verarbeitet Echtzeit- und Batch-Daten innerhalb derselben Plattform.
- Apache Druid und Pinot dienen als Echtzeit-Analyse-Datenbanken, die OLAP-Fähigkeiten bieten, die das Abfragen von großen Datensätzen in Echtzeit ermöglichen und besonders nützlich für Dashboards und Business-Intelligence-Anwendungen sind.
Implementierungsfallbeispiele
Realwelt-Implementierungen von Echtzeit-Datenpipelines zeigen die vielfältigen Möglichkeiten, in denen diese Architekturen kritische Anwendungen in verschiedenen Branchen unterstützen, die Leistung, Entscheidungsfindung und betriebliche Effizienz verbessern.
Finanzmarktdaten-Streaming für High-Frequency-Trading-Systeme
In High-Frequency-Trading-Systemen, wo Millisekunden den Unterschied zwischen Gewinn und Verlust ausmachen können, werden Apache Kafka oder Apache Pulsar für die hochdurchsatzfähige Datenbeschaffung verwendet. Apache Flink oder Apache Storm übernehmen die low-latency-Verarbeitung, um sicherzustellen, dass Handelsentscheidungen sofort getroffen werden. Diese Pipelines müssen extreme Skalierbarkeit und Fehlertoleranz unterstützen, da jede Systemunterbrechung oder Verzögerung in der Verarbeitung zu verpassten Handelschancen oder finanziellen Verlusten führen kann.
IoT und Echtzeit-Sensordatenverarbeitung
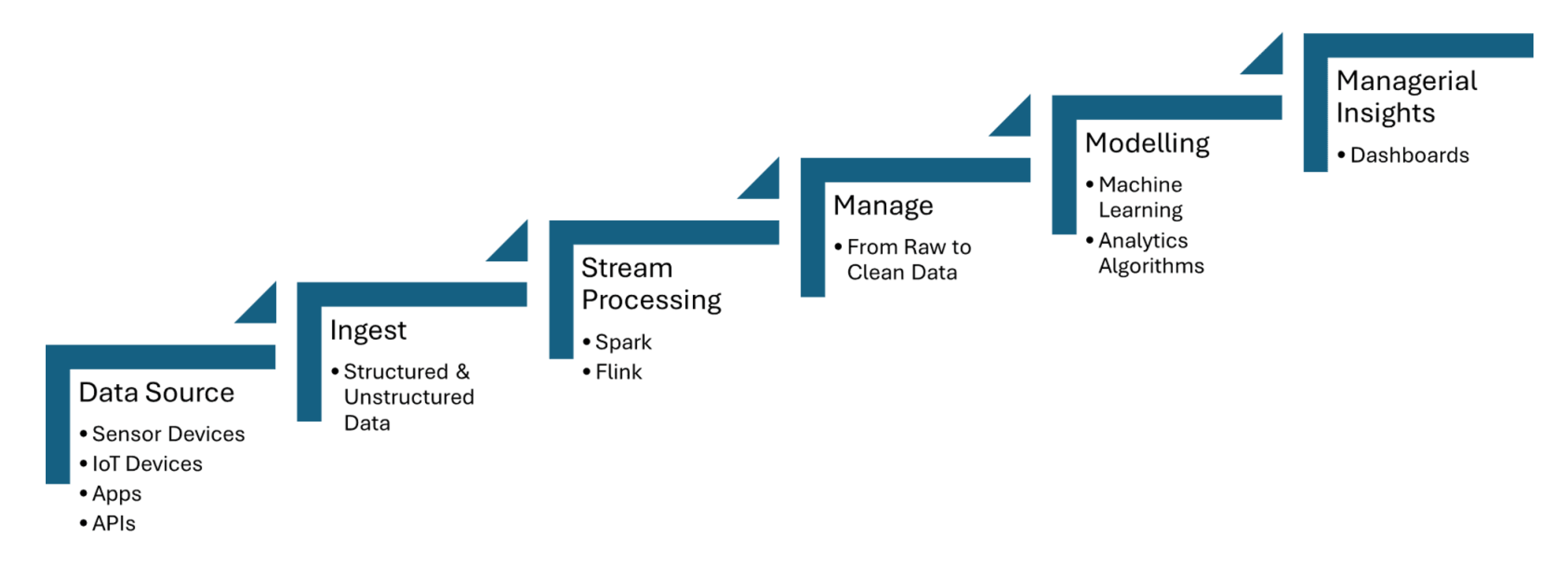
Echtzeit-Datenpipelines ingests Daten von IoT-Sensoren, die Informationen wie Temperatur, Druck oder Bewegung erfassen, und verarbeiten die Daten mit minimaler Latenz. Apache Kafka wird verwendet, um die Erfassung von Sensor-Daten zu verwalten, während Apache Flink oder Apache Spark Streaming Echtzeit-Analysen und Ereignisdetektion ermöglichen. Abbildung 1, die unten geteilt wird, zeigt die Schritte der Datenstromverarbeitung für IoT von den Datenquellen bis hin zur Dashboardsicht:
Abbildung 1. Datenstromverarbeitung für IoT
Fraud Detection From Transaction Data Streaming
Transaktionsdaten werden in Echtzeit mit Tools wie Apache Kafka erfasst, das große Mengen an Datenströmen von mehreren Quellen wie Banktransaktionen oder Zahlungsgateways verarbeitet. Stream-Verarbeitungs-Frameworks wie Apache Flink oder Apache Spark Streaming werden verwendet, um Maschinen-Lern-Modelle oder regelbasierte Systeme anzuwenden, die Anomalien in Transaktionsmustern erkennen, wie ungewöhnliches Ausgabeverhalten oder geografische Unregelmäßigkeiten.
Wie AI-Automatisierung intelligente Pipelines und Vektor-Datenbanken antreibt
Intelligente Workflows nutzen Echtzeit-Datenverarbeitung und Vektor-Datenbanken, um Entscheidungsfindung zu verbessern, Operationen zu optimieren und die Effizienz von großen Datenumgebungen zu steigern.
Datenpipelines-Automatisierung
Die Automatisierung von Datenpipelines ermöglicht die effiziente Bewältigung von Aufgaben zur Groß-scale-Dateningest, -transformation und -analyse ohne manuelle Intervention. Apache Airflow stellt sicher, dass Aufgaben automatisiert zur richtigen Zeit und in der richtigen Sequenz ausgelöst werden. Apache NiFi ermöglicht die automatische Datenflussverwaltung und ermöglicht die Echtzeit-Dateningest, -transformation und -routing. Apache Kafka stellt sicher, dass Daten kontinuierlich und effizient verarbeitet werden.
Pipeline-Orchestrierungsrahmen
Pipeline-Orchestrierungsrahmen sind für die Automatisierung und Verwaltung von Datenworkflows auf strukturierte und effiziente Weise unerlässlich. Apache Airflow bietet Funktionen wie Abhängigkeitsmanagement und Überwachung. Luigi konzentriert sich darauf, komplexe Pipelines von Batch-Jobs zu erstellen. Dagster und Prefect bieten dynamische Pipeline-Management und erweiterte Fehlerbehandlung.
Adaptive Pipelines
Adaptive Pipelines sind darauf ausgelegt, sich dynamisch an wechselnde Datenumgebungen anzupassen, wie z.B. Schwankungen in Datenmenge, Struktur oder Quellen. Apache Airflow oder Prefect ermöglichen eine Echtzeit-Reaktionsfähigkeit durch die Automatisierung von Abhängigkeiten und Planung basierend auf den aktuellen Pipeline-Bedingungen. Diese Pipelines können Frameworks wie Apache Kafka für skalierbare Datenströme und Apache Spark für adaptives Datenprocessing nutzen, um eine effiziente Ressourcennutzung zu gewährleisten.
Streaming Pipelines
Eine Streaming-Pipeline zur Befüllung einer Vektor-Datenbank für Echtzeit-Abfrage-angereicherte Generierung (RAG) kann vollständig mit Tools wie Apache Kafka und Apache Flink erstellt werden. Die verarbeiteten Streaming-Daten werden in Embeddings umgewandelt und in einer Vektor-Datenbank gespeichert, was eine effiziente semantische Suche ermöglicht. Diese Echtzeit-Architektur stellt sicher, dass große Sprachmodelle (LLMs) Zugang zu aktuellen, kontextuell relevanten Informationen haben, was die Genauigkeit und Zuverlässigkeit von RAG-basierten Anwendungen wie Chatbots oder Empfehlungs-Engines verbessert.
Data Streaming als Data Fabric für Generative AI
Echtzeit-Daten-Streaming ermöglicht die Echtzeit-Eingabe, Verarbeitung und Abruf von umfangreichen Daten, die LLMs zur Generierung genauer und aktueller Antworten benötigen. Während Kafka beim Streaming hilft, verarbeitet Flink diese Streams in Echtzeit, ensuring dass die Daten bereichert und kontextuell relevant sind, bevor sie in Vektor-Datenbanken eingespeist werden.
Der Weg nach vorne: Zukunftssicherung von Datenpipelines
Die Integration von Echtzeit-Datenströmen, KI-Automatisierung und Vektor-Datenbanken bietet transformative Potenziale für Unternehmen. Für die KI-Automatisierung ermöglicht die Integration von Echtzeit-Datenströmen mit Frameworks wie TensorFlow oder PyTorch Echtzeit-Entscheidungen und kontinuierliche Modellaktualisierungen. Für die Echtzeit-Retrieval von kontextuellen Daten nutzen Datenbanken wie Faiss oder Milvus schnelle semantische Suchen, die für Anwendungen wie RAG entscheidend sind.
Schlussfolgerung
Die wichtigsten Erkenntnisse umfassen die entscheidende Rolle von Tools wie Apache Kafka und Apache Flink für skalierbare, niedriglatenz-Datenströme sowie TensorFlow oder PyTorch für Echtzeit-KI-Automatisierung und FAISS oder Milvus für schnelle semantische Suchen in Anwendungen wie RAG. Die Sicherstellung der Datenqualität, die Automatisierung von Workflows mit Tools wie Apache Airflow und die Implementierung robuster Überwachungs- und Fehlertoleranzmechanismen helfen Unternehmen, in einer datengesteuerten Welt agil zu bleiben und ihre Entscheidungsfähigkeiten zu optimieren.
Zusätzliche Ressourcen:
- KI-Automatisierungsgrundlagen von Tuhin Chattopadhyay, DZone Refcard
- Apache Kafka Essentials von Sudip Sengupta, DZone Refcard
- Erste Schritte mit Large Language Models von Tuhin Chattopadhyay, DZone Refcard
- Erste Schritte mit Vektor-Datenbanken von Miguel Garcia, DZone Refcard
Dies ist ein Auszug aus dem DZone-Trendbericht 2024,
Data Engineering: Datenpipelines bereichern, KI erweitern und Analysen beschleunigen.
Source:
https://dzone.com/articles/the-data-pipeline-movement