













Nota do Editor: A seguir, está um artigo escrito e publicado no Relatório de Tendências de 2024 da DZone, Engenharia de Dados: Enriquecendo Pipelines de Dados, Expandindo IA e Acelerando Análises.
Este artigo explora estratégias essenciais para aproveitar o streaming de dados em tempo real para gerar insights acionáveis, enquanto protege os sistemas para o futuro através da automação de IA e bancos de dados vetoriais. Ele aborda as arquiteturas e ferramentas em evolução que permitem que as empresas mantenham agilidade e competitividade em um mundo驱动的 por dados.
Streaming de Dados em Tempo Real: A Evolução e Considerações Chave
O streaming de dados em tempo real evoluiu de processamento batch tradicional, onde os dados eram processados em intervalos que introduziam atrasos, para lidar continuamente com dados à medida que são gerados, permitindo respostas instantâneas a eventos críticos. Ao integrar IA, automação e bancos de dados vetoriais, as empresas podem aprimorar ainda mais suas capacidades, usando insights em tempo real para prever resultados, otimizar operações e gerenciar de forma eficiente grandes conjuntos de dados complexos.
Necessidade do Streaming em Tempo Real
É necessário agir sobre os dados assim que eles são gerados, especialmente em cenários como deteção de fraudes, análise de logs ou rastreamento do comportamento do cliente. O streaming em tempo real permite que as organizações capturem, processem e analisem dados instantaneamente, permitindo-lhes reagir rapidamente a eventos dinâmicos, otimizar a tomada de decisões e melhorar as experiências dos clientes em tempo real.
Fontes de dados em tempo real
Os dados em tempo real têm origem em vários sistemas e dispositivos que geram dados continuamente, muitas vezes em grandes quantidades e em formatos que podem ser difíceis de processar. As fontes de dados em tempo real incluem frequentemente:
- Dispositivos e sensores de IoT
- Registos de servidores
- Atividade de aplicações
- Apublicidade online
- Eventos de alteração de bases de dados
- Transmissão de cliques em sítios Web
- Plataformas de redes sociais sociais
- Bases de dados transaccionais
A gestão e análise eficazes destes fluxos de dados requerem uma infraestrutura robusta capaz de lidar com dados não estruturados e semi-estruturados.estruturados; Isto permite às empresas extrair informações valiosas e tomar decisões em tempo real.
Desafios críticos nos pipelines de dados modernos
Os pipelines de dados modernos enfrentam vários desafios, incluindo manter a qualidade dos dados, garantir transformações precisas e minimizar o tempo de inatividade do pipeline:
- A má qualidade dos dados pode levar a insights falhos.
- As transformações de dados são complexas e exigem scripts precisos.
- Frequentes interrupções干扰操作,使得容错系统变得至关重要.
Além disso, governança de dados é crucial para garantir coerência dos dados e confiabilidade em todo o processo. Escalabilidade é outro problema-chave, pois os pipelines devem lidar com volumes flutuantes de dados, e o monitoramento e alertas adequados são vitais para evitar falhas inesperadas e garantir uma operação suave.
Arquiteturas e cenários de aplicações de transmissão de dados em tempo real avançados
Esta seção demonstra a capacidade dos sistemas de dados modernos de processar e analisar dados em movimento, fornecendo às organizações as ferramentas para responder a eventos dinâmicos em milissegundos.
Passos para construir um pipeline de dados em tempo real
Para criar um pipeline de dados em tempo real eficaz, é essencial seguir uma série de passos estruturados que garantem um fluxo suave de dados, processamento e escalabilidade. A Tabela 1, compartilhada abaixo, descreve os principais passos envolvidos na construção de um pipeline de dados em tempo real robusto:
Tabela 1. Passos para construir um pipeline de dados em tempo real
| step | activities performed |
|---|---|
| 1. Ingestão de dados | Configurar um sistema para capturar fluxos de dados de várias fontes em tempo real |
| 2. Processamento de dados | Limpar, validar e transformar os dados para garantir que estejam prontos para análise |
| 3. Processamento de stream | Configurar consumidores para puxar, processar e analisar dados continuamente |
| 4. Armazenamento | Armazenar os dados processados em um formato adequado para uso downstream |
| 5. Monitoramento e escalabilidade | Implementar ferramentas para monitorar o desempenho do pipeline e garantir que ele possa escalar com o aumento da demanda de dados |
Ferramentas de Streaming Open Source de Destaque
Para construir pipelines de dados em tempo real robustos, várias ferramentas open source de destaque estão disponíveis para ingestão, armazenamento, processamento e análise de dados, cada uma desempenhando um papel crítico na gestão e processamento de fluxos de dados em larga escala.
Ferramentas open source para ingestão de dados:
- Apache NiFi, com sua versão mais recente 2.0.0-M3, oferece escalabilidade aprimorada e capacidades de processamento em tempo real.
- Apache Airflow é usado para orquestrar fluxos de trabalho complexos.
- Apache StreamSets fornece monitoramento e processamento contínuo do fluxo de dados.
- Airbyte simplifica a extração e carregamento de dados, tornando-se uma escolha forte para gerenciar diversas necessidades de ingestão de dados.
Ferramentas open source para armazenamento de dados:
- Apace Kafka é amplamente utilizado para construir pipelines em tempo real e aplicações de streaming devido à sua alta escalabilidade, tolerância a falhas e velocidade.
- Apace Pulsar, um sistema de mensagens distribuído, oferece forte escalabilidade e durabilidade, tornando-se ideal para lidar com mensagens em larga escala.
- NATS.io é um sistema de mensagens de alta performance, comumente usado em aplicações IoT e nativas da nuvem, projetado para arquiteturas de microservices e oferece comunicação leve e rápida para necessidades de dados em tempo real.
- Apace HBase, um banco de dados distribuído construído sobre HDFS, fornece forte consistência e alta throughput, tornando-se ideal para armazenar grandes quantidades de dados em tempo real em um ambiente NoSQL.
Ferramentas de código aberto para processamento de dados:
- Apace Spark se destaca com seu cluster de computação em memória, fornecendo processamento rápido para tanto aplicações em lote quanto streaming.
- Apace Flink é projetado para processamento distribuído de stream de alta performance e suporta jobs em lote.
- Apache Storm é conhecido por sua capacidade de processar mais de um milhão de registros por segundo, tornando-o extremamente rápido e escalável.
- Apache Apex oferece processamento unificado de fluxo e lote.
- Apache Beam fornece um modelo flexível que funciona com vários motores de execução, como Spark e Flink.
- Apache Samza, desenvolvido pelo LinkedIn, integra bem com Kafka e lida com processamento de fluxo com foco em escalabilidade e tolerância a falhas.
- Heron, desenvolvido pelo Twitter, é uma plataforma de análise em tempo real altamente compatível com Storm, mas oferece melhor desempenho e isolamento de recursos, tornando-se adequado para processamento de fluxo de alta velocidade em larga escala.
Ferramentas de código aberto para análise de dados:
- Apache Kafka permite o processamento de alta capacidade e baixa latência de fluxos de dados em tempo real.
- Apache Flink oferece processamento de fluxo poderoso, ideal para aplicativos que requerem computações distribuídas e com estado.
- Apache Spark Streaming integrado com o ecossistema mais amplo do Spark lida com dados em tempo real e em lote na mesma plataforma.
- Apache Druid e Pinot servem como bancos de dados analíticos em tempo real, oferecendo capacidades OLAP que permitem consultas a grandes conjuntos de dados em tempo real, tornando-os particularmente úteis para painéis e aplicações de inteligência de negócios.
Casos de Implementação
Implementações do mundo real de pipelines de dados em tempo real mostram as várias maneiras pelas quais essas arquiteturas impulsionam aplicativos críticos em várias indústrias, melhorando o desempenho, a tomada de decisões e a eficiência operacional.
Transmissão de Dados de Mercado Financeiro para Sistemas de Trading de Alta Frequência
No sistemas de trading de alta frequência, onde milissegundos podem fazer a diferença entre lucro e perda, Apache Kafka ou Apache Pulsar são usados para ingestão de dados de alta throughput. Apache Flink ou Apache Storm lidam com processamento de baixa latência para garantir que as decisões de negociação sejam tomadas instantaneamente. Esses pipelines devem suportar escalabilidade extrema e tolerância a falhas, pois qualquer tempo de inatividade do sistema ou atraso no processamento pode levar a oportunidades de negociação perdidas ou perdas financeiras.
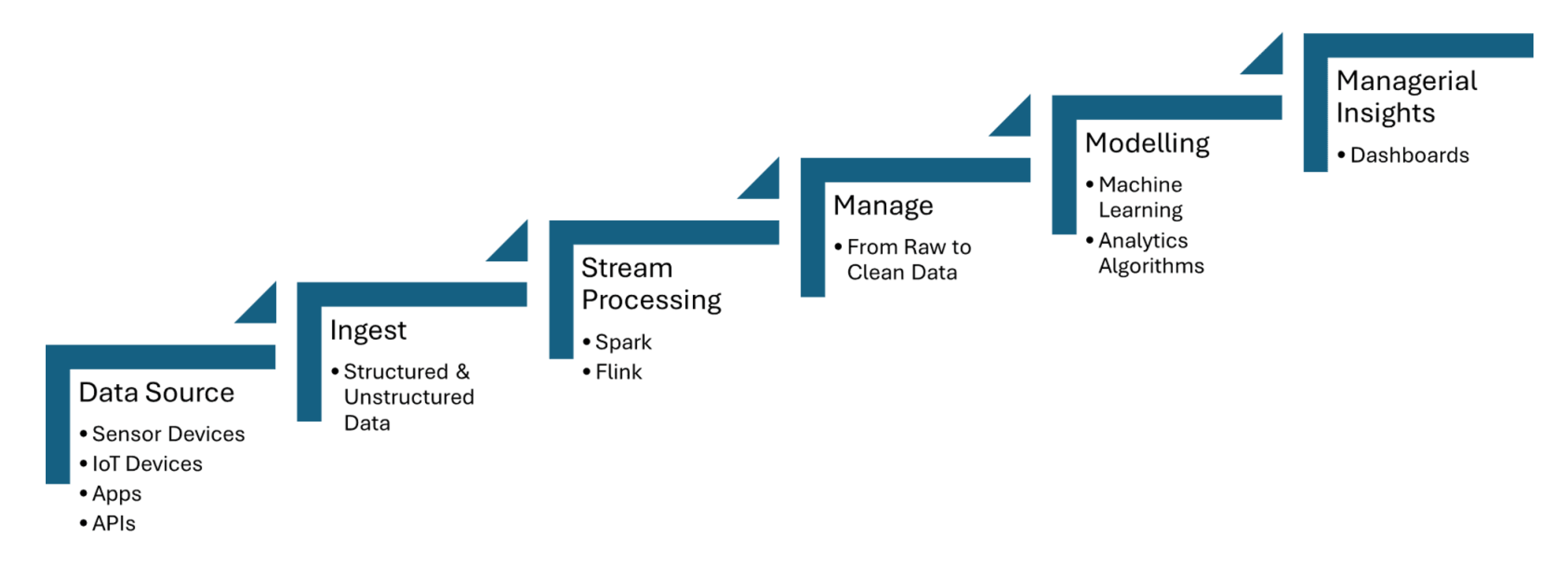
Processamento de Dados de Sensores IoT em Tempo Real
Pipelines de dados em tempo real ingestionam dados de sensores IoT, que capturam informações como temperatura, pressão ou movimento, e processam os dados com latência mínima. Apache Kafka é usado para lidar com a ingestão de dados de sensores, enquanto Apache Flink ou Apache Spark Streaming permitem a análise em tempo real e detecção de eventos. A Figura 1 compartilhada abaixo mostra os passos do processamento de fluxo para IoT de fontes de dados até o painel de controle:
Figura 1. Processamento de fluxo para IoT
Deteção de Fraude a Partir de Dados de Transações em Fluxo
Dados de transação são ingestionados em tempo real usando ferramentas como Apache Kafka, que lida com grandes volumes de dados em fluxo de várias fontes, como transações bancárias ou gateways de pagamento. Frameworks de processamento de fluxo como Apache Flink ou Apache Spark Streaming são usados para aplicar modelos de aprendizado de máquina ou sistemas baseados em regras que detectam anormalidades em padrões de transação, como comportamento de gastos incomum ou discrepâncias geográficas.
Como a Automatização de IA está Impulsionando PipeLines Inteligentes e Bancos de Dados Vetoriais
Fluxos de trabalho inteligentes utilizam processamento de dados em tempo real e bancos de dados vetoriais para melhorar a tomada de decisões, otimizar operações e aumentar a eficiência de grandes ambientes de dados.
Automatização de Pipeline de Dados
A automação de pipelines de dados permite o manejo eficiente de tarefas de ingestão, transformação e análise de grandes volumes de dados sem intervenção manual. O Apache Airflow garante que as tarefas sejam acionadas de forma automatizada no momento certo e na sequência correta. O Apache NiFi facilita a gestão automatizada do fluxo de dados, permitindo a ingestão, transformação e roteamento de dados em tempo real. O Apache Kafka garante que os dados sejam processados de forma contínua e eficiente.
Frameworks de Orquestração de Pipeline
Os frameworks de orquestração de pipeline são essenciais para automatizar e gerenciar fluxos de trabalho de dados de maneira estruturada e eficiente. O Apache Airflow oferece recursos como gerenciamento de dependências e monitoramento. Luigi se concentra em construir pipelines complexos de jobs em lote. Dagster e Prefect fornecem gerenciamento dinâmico de pipeline e handling avançado de erros.
Pipelines Adaptativos
Pipelines adaptativos são projetados para ajustar dinamicamente a-changing ambientes de dados, como flutuações no volume, estrutura ou fontes de dados. O Apache Airflow ou Prefect permitem uma resposta em tempo real automatizando dependências de tarefas e agendamento com base nas condições atuais do pipeline. Esses pipelines podem utilizar frameworks como Apache Kafka para streaming de dados escalável e Apache Spark para processamento de dados adaptativo, garantindo o uso eficiente de recursos.
Pipelines de Streaming
Uma pipeline de streaming para preencher um banco de dados vetorial para geração aumentada de recuperação em tempo real (RAG) pode ser construída entirely usando ferramentas como Apache Kafka e Apache Flink. Os dados de streaming processados são então convertidos em embeddings e armazenados em um banco de dados vetorial, permitindo uma busca semântica eficiente. Esta arquitetura em tempo real garante que modelos de linguagem grandes (LLMs) tenham acesso a informações atualizadas e contextualmente relevantes, melhorando a precisão e a confiabilidade de aplicações baseadas em RAG, como chatbots ou motores de recomendação.
Data Streaming como Data Fabric para IA Generativa
O streaming de dados em tempo real permite a ingestão, processamento e recuperação em tempo real de grandes quantidades de dados que os LLMs requerem para gerar respostas precisas e atualizadas. Enquanto Kafka ajuda no streaming, Flink processa esses streams em tempo real, garantindo que os dados sejam enriquecidos e contextualmente relevantes antes de serem alimentados em bancos de dados vetoriais.
A Estrada a Frente: Protegendo Pipelines de Dados para o Futuro
A integração de fluxos de dados em tempo real, automação de IA e bancos de dados vetoriais oferece potencial transformador para os negócios. Para a automação de IA, integrar fluxos de dados em tempo real com frameworks como TensorFlow ou PyTorch permite tomada de decisões em tempo real e atualizações contínuas de modelos. Para a recuperação de dados contextuais em tempo real, utilizar bancos de dados como Faiss ou Milvus ajuda em buscas semânticas rápidas, que são cruciais para aplicações como RAG.
Conclusão
Os principais pontos a serem levantados incluem o papel crucial de ferramentas como Apache Kafka e Apache Flink para streaming de dados escalável e de baixa latência, juntamente com TensorFlow ou PyTorch para automação de IA em tempo real, e FAISS ou Milvus para buscas semânticas rápidas em aplicações como RAG. Garantir a qualidade dos dados, automatizar fluxos de trabalho com ferramentas como Apache Airflow e implementar mecanismos robustos de monitoramento e tolerância a falhas ajudarão as empresas a permanecer ágeis em um mundo orientado por dados e a otimizar suas capacidades de tomada de decisões.
Recursos adicionais:
- Essenciais de Automatização de IA por Tuhin Chattopadhyay, DZone Refcard
- Esenciais do Apache Kafka por Sudip Sengupta, DZone Refcard
- Introdução aos Modelos de Linguagem de Grande Escala por Tuhin Chattopadhyay, DZone Refcard
- Introdução às Bases de Dados Vetoriais por Miguel Garcia, DZone Refcard
Este é um trecho do Relatório de Tendências de 2024 da DZone,
Engenharia de Dados: Enriquecendo Pipeelines de Dados, Expandindo IA e Acelerando Análises.
Source:
https://dzone.com/articles/the-data-pipeline-movement