













ملاحظة المحرر: ما يلي هو مقال كتب من أجل ونشر في تقرير الاتجاهات لـ DZone لعام 2024،هندسة البيانات: تحسين أنابيب البيانات، توسيع الذكاء الاصطناعي، وتسريع التحليلات.
يستعرض هذا المقال الاستراتيجيات الأساسية للاستفادة من تدفق البيانات الفعلي لتحفيز الأفكار الفعالة بينما يضمن النظام حماية مستقبلية من خلال 自动化和 قواعد البيانات المتجهة. يتناول المقال تطور البنية التحتية والأدوات التي تمكّن الأعمال من البقاء مرنة ومتنافسة في عالم يعتمد على البيانات.
تدفق البيانات الفعلي: التطور والاست considerations الرئيسية
تطور تدفق البيانات الفعلي من معالجة الكتل التقليدية، حيث كانت البيانات تُمعالج بفواصل زمنية تسبب تأخيرات، إلى معالجة البيانات بشكل مستمر آنياً عند إنشائها، مما يمكن من الاستجابة الفورية للأحداث الحرجة. من خلال دمج الذكاء الاصطناعي، وال自动化和 قواعد البيانات المتجهة، يمكن للشركات تعزيز قدراتها، باستخدام الأفكار الفعلية لتوقّع النتائج، وتحسين العمليات، وإدارة مجموعة كبيرة ومعقدة من البيانات بكفاءة.
ضرورة تدفق البيانات الفعلي
الحاجة إلى العمل على البيانات فور إنشائها، خاصة في سيناريوهات مثل كشف الغش، تحليل السجلات، أو تتبع سلوك العملاء. يتيح Streamlining الفوري للبيانات للمنظمات التقاط، معالجة، وتحليل البيانات على الفور، مما يمكنها من الاستجابة بسرعة لحدث ديناميكي، تحسين اتخاذ القرارات، وتعزيز تجارب العملاء في الوقت الفعلي.
مصادر البيانات الفورية
تنشأ بيانات الفورية من أنظمة وأجهزة متنوعة التي تنتج بيانات بشكل مستمر، غالبًا بكميات كبيرة وأشكال قد تكون صعبة المعالجة. تشمل مصادر البيانات الفورية عادة:
- أجهزة IoT وال传感器ات
- سجلات السيرفر
- نشاط التطبيقات
- الإعلانات عبر الإنترنت
- أحداث تغيير قاعدة البيانات
- تدفقات النقر على الموقع
- منصات وسائل التواصل الاجتماعي
- قواعد البيانات التجارية
يتطلب إدارة وتحليل هذه التدفقات البيانية بنية تحتية قوية قادرة على التعامل مع البيانات غير المنظمة والمنظمة بشكل جزئي؛ مما يتيح للشركات استخراج رؤى قيمة واتخاذ قرارات فورية.
التحديات الأساسية في أنابيب البيانات الحديثة
تواجه أنابيب البيانات الحديثة عدة تحديات، بما في ذلك الحفاظ على جودة البيانات، ضمان تحويلات البيانات الدقيقة، وتقليل وقت توقف الأنابيب:
- جودة البيانات السيئة يمكن أن تؤدي إلى استنتاجات معيبة.
- تحويلات البيانات معقدة وتتطلب كتابة سكريبتات دقيقة.
- الإنقطاع المتكرر يerrupts العمليات، مما يجعل الأنظمة القابلة للتحمل أساسية.
بالإضافة إلى ذلك،إدارة البيانات أمر حاسم لضمان استمرارية البيانات والموثوقية عبر العمليات. القدرة على التوسع هي أيضًاissue أساسي حيث يجب على القنوات التعامل مع تقلبات أحجام البيانات، و proper المراقبة والإخطار ضروريان لتجنب الفشل غير المتوقع وضمان السير السلس للعمليات.
架构和应用场景的先进实时数据流
هذا القسم يوضح قدرات أنظمة البيانات الحديثة في معالجة وتحليل البيانات المتحركة، مما يمنح المنظمات الأدوات للرد على الأحداث الديناميكية في جزء من الألف من الثانية.
خطوات بناء قناة بيانات فعلية
لإنشاء قناة بيانات فعلية فعالة، من الضروري اتباع سلسلة من الخطوات المنظمة التي تضمن تدفق البيانات السلس، والمعالجة، والقدرة على التوسع. الجدول 1، المشار إليه أدناه، يوضح الخطوات الرئيسية المتعلقة ببناء قناة بيانات فعلية قوية:
الجدول 1. خطوات بناء قناة بيانات فعلية
| step | activities performed |
|---|---|
| 1. استقبال البيانات | إعداد نظام لالتقاط تيارات البيانات من مصادر مختلفة في الوقت الحقيقي |
| 2. معالجة البيانات | تنظيف البيانات وتصحيحها وتحويلها لضمان استعدادها للتحليل |
| 3. معالجة التدفق | تهيئة المستهلكين لسحب البيانات ومعالجتها وتحليلها باستمرار |
| 4. التخزين | تخزين البيانات المعالجة في صيغة مناسبة للاستخدام اللاحق |
| 5. مراقبة وتوسيع | تنفيذ أدوات لمراقبة أداء Pipeline وضمان قدرته على التوسع مع زيادة طلبات البيانات |
أدوات تدفق البيانات المفتوحة المصدر الرائدة
لبناء أنظمة بيانات حقيقية زمنية قوية، هناك العديد من الأدوات المفتوحة المصدر الرائدة المتاحة لاستقبال البيانات، وتخزينها، ومعالجتها، وتحليلها، تلعب كل منها دورًا حاسمًا في إدارة ومعالجة تدفقات البيانات الكبيرة.
أدوات مفتوحة المصدر لاستقبال البيانات:
- Apache NiFi، مع أحدث إصدار2.0.0-M3، يقدم تحسينات في التوسع ومعالجة البيانات الفعلية.
- Apache Airflow يستخدم لتنسيق_flows_ معقدة.
- Apache StreamSets يقدم مراقبة ومعالجة تدفق البيانات المستمر.
- Airbyte يبسط استخراج وتحميل البيانات، مما يجعله خيارًا قويًا لإدارة احتياجات استقبال البيانات المختلفة.
أدوات مفتوحة المصدر لتخزين البيانات:
- أبache Kafka يستخدم على نطاق واسع لبناء أنابيب فورية وتطبيقات البث due to its high scalability, fault tolerance, and speed.
- أبache Pulsar، نظام مراسلة موزع، يقدم مرونة قوية ومتانة، مما يجعله مثاليًا لمعالجة الرسائل على نطاق واسع.
- NATS.io هو نظام مراسلة عالي الأداء، يُستخدم عادةً في تطبيقات IoT والأنظمة الأصلية السحابية، صمم لعمليات الميكروservices ويقدم تواصل خفيف وسريع لتلبية احتياجات البيانات الفورية.
- أبache HBase، قاعدة بيانات موزعة مبنية على HDFS، توفر توافقًا قويًا و Throughput عالي، مما يجعلها مثالية لتخزين كميات كبيرة من البيانات الفورية في بيئة NoSQL.
أدوات مفتوحة المصدر لمعالجة البيانات:
- أبache Spark بارز بقدرته على الحوسبة داخل الذاكرة، مما يوفر معالجة سريعة لكل من التطبيقات متسلسلة وتلك الفورية.
- أبache Flink مصمم لمعالجة تيارات التوزيع عالي الأداء ويدعم الوظائف متسلسلة.
- Apache Storm معروف بقدرته على معالجة أكثر من مليون سجل في الثانية، مما يجعله سريعًا وقابلًا للتحجيم بشكل كبير.
- Apache Apex يقدم معالجة موحدة لل溪流 وال批次.
- Apache Beam يوفر نموذجًا مرنًا يعمل مع عدة محركات تنفيذ مثل Spark و Flink.
- Apache Samza، الذي طورته LinkedIn، يتكامل بشكل جيد مع Kafka ويعالج معالجة溪流 مع التركيز على التوسع والقدرة على الت_recovery من الأخطاء.
- Heron، الذي طورته Twitter، هو منصة تحليل فورية في الوقت الحقيقي متوافقة بشكل كبير مع Storm ولكنها توفر أداءً أفضل وفصلًا للموارد، مما يجعلها مثالية لمعالجة溪流 عالية السرعة على نطاق واسع.
أدوات مفتوحة المصدر لتحليل البيانات:
- Apache Kafka يسمح بمعالجة بيانات溪流 في الوقت الحقيقي بسرعة عالية و latency منخفضة.
- Apache Flink يقدم معالجة溪流 قوية، مثالية للتطبيقات التي تتطلب حسابات موزعة وذات حالة.
- Apache Spark Streaming متكامل مع النظام الأوسع لـ Spark، يتعامل مع البيانات الفعلية والبيانات بال批量 ضمن نفس المنصة.
- Apache Druid و Pinot يعملان كقواعد بيانات تحليلية فعلية، تقدم capabilities OLAP التي تسمح بالاستعلام عن مجموعات بيانات كبيرة في الوقت الفعلي، مما يجعلها مفيدة بشكل خاص في لوحات المعلومات وتطبيقات Inteligence الأعمال.
حالات الاستخدامImplementation
التطبيقات الحقيقية لقنوات البيانات الفعلية تظهر الطرق المختلفة التي تدعمها هذه البنى التحتية لتشغيل تطبيقات حاسمة عبر مختلف الصناعات، مما يزيد من الأداء، اتخاذ القرارات، و الكفاءة التشغيلية.
بث بيانات السوق المالي للنظم التجارية عالية التردد
في أنظمة التداول عالية التردد، حيث يمكن أن تجعل الأجزاء من الثانية الفارق بين الربح والخسارة، يتم استخدام Apache Kafka أو Apache Pulsar لاستقبال بيانات عالية السعة. Apache Flink أو Apache Storm يتعاملان مع معالجة منخفضة التأخير لضمان اتخاذ قرارات التداول على الفور. يجب أن تدعم هذه القنوات التوسع الشديد والقدرة على الت忍受 الفشل، حيث أن أي انقطاع في النظام أو تأخير في المعالجة يمكن أن يؤدي إلى تفويت فرص التداول أو خسائر مالية.
معالجة بيانات IoT وال sensors الفعلية
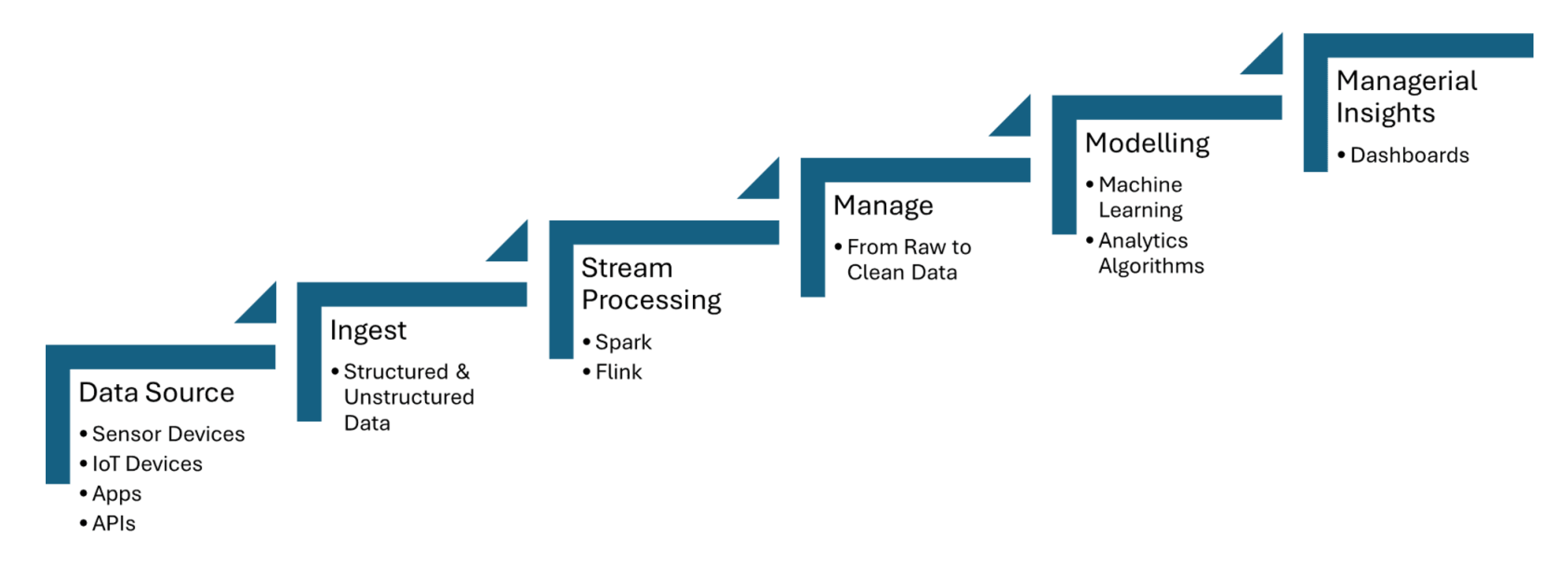
pipelines بيانات فورية تستهلك بيانات من حساسات إنترنت الأشياء، التي تلتقط معلومات مثل درجة الحرارة، الضغط، أو الحركة، ثم تقوم بمعالجة البيانات بحد أدنى من التأخير. يتم استخدام Apache Kafka لمعالجة استقبال بيانات الحساسات، بينما يتم استخدام Apache Flink أو Apache Spark Streaming لتحليل البيانات الفوري والكشف عن الأحداث. الشكل 1 المشارك أدناه يوضح خطوات معالجة التدفقات للإنترنت من الأشياء من مصادر البيانات إلى لوحات المعلومات:
الشكل 1. معالجة التدفقات للإنترنت من الأشياء
الكشف عن الغش من بيانات المعاملات المتدفقة
تتم استقبال بيانات المعاملات في الوقت الحقيقي باستخدام أدوات مثل Apache Kafka، التي تتعامل مع كميات كبيرة من بيانات التدفق من مصادر متعددة، مثل معاملات البنوك أو بوابات الدفع. تستخدم إطاريات معالجة التدفقات مثل Apache Flink أو Apache Spark Streaming تطبيق نماذج التعلم الآلي أو نظم القواعد التي تكشف عن الأنماط الشاذة في أنماط المعاملات، مثل السلوكيات غير المعتادة للإنفاق أو الاختلافات الجغرافية.
كيفية قيادة الت自动化 الذكاء الاصطناعي لمجاري البيانات والقواعد متعددة الأبعاد
تستفيد العملية الذكية من معالجة البيانات الفورية والقواعد متعددة الأبعاد لتحسين اتخاذ القرارات، وتحسين العمليات، وتعزيز كفاءة بيئات البيانات الكبيرة.
自动化 سير العمل البياني
تتيح 自动化数据管道 处理大规模数据摄入、转换和分析任务,而无需人工干预. Apache Airflow يضمن بدء المهام بشكل آلي في الوقت المناسب والترتيب الصحيح. Apache NiFi يسهل إدارة تدفق البيانات الآلي، مما يتيح استقبال البيانات في الوقت الحقيقي، وتحويلها وتوجيهها. Apache Kafka يضمن معالجة البيانات بشكل مستمر وفعال.
إطارات توزيع الأنابيب
تعتبر إطارات توزيع الأنابيب أساسية لتحويل وتسيير تدفقات البيانات بشكل منظم وفعال. يقدم Apache Airflow ميزات مثل إدارة التبعيات والمراقبة. Luigi يركز على بناء أنابيب معقدة من مهام الدفع. Dagster و Prefect يقدمان إدارة أنابيب ديناميكية ومعالجة الأخطاء المحسنة.
الأنابيب التكيفية
تم تصميم الأنابيب التكيفية لتتكيف بشكل ديناميكي مع البيئات البيانية المتغيرة، مثل تقلبات حجم البيانات أو الهيكل أو المصادر. يتيح Apache Airflow أو Prefect الاستجابة في الوقت الحقيقي عن طريق أتمتة التبعيات والجدولة بناءً على ظروف الأنابيب الحالية. يمكن لهذه الأنابيب استخدام إطارات مثل Apache Kafka لStreaming البيانات القابلة للتمديد و Apache Spark لمعالجة البيانات التكيفية، مما يضمن استخدام موارد فعالة.
الأنابيب المتدفقة
يمكن بناء أنبوب تدفق البث لملىء قاعدة بيانات متجهية لاسترجاع augmenté en temps réel (RAG) باستخدام بالكامل أدوات مثل Apache Kafka و Apache Flink. يتم تحويل البيانات المتدفقة المحسوبة إلى تمثيلات متجهية وتخزينها في قاعدة بيانات متجهية، مما يتيح البحث الس semantic Search. توفر هذه Architecture temps réel الوصول إلى نماذج لغوية كبيرة (نماذج لغوية كبيرة) معلومات محدثة ذات صلة سياقياً، مما ي改善了 دقة الاعتماد على التطبيقات المستندة إلى RAG مثل Chatbots أو محركات التوصية.
تدفق البيانات كنسيج بيانات لذكاء اصطناعي التوليد
تدفق البيانات في الوقت الحقيقي يتيح استقبال ومعالجة واسترجاع كميات هائلة من البيانات التي تحتاجها نماذج اللغوية الكبيرة لإنشاء ردود دقيقة وحالية. بينما يساعد Kafka في تدفق البيانات، تقوم Flink بمعالجة هذه التدفقات في الوقت الحقيقي، مما يضمن أن البيانات م Enrique et pertinent avant d’être injectée dans les bases de données vectorielles.
الطريق المستقبلي: تأمين خطوط أنابيب البيانات للمستقبل
دمج تدفق البيانات الفوري، وتحسين الذكاء الاصطناعي، وقواعد البيانات المتجهة يقدم إمكانيات تحولية للأعمال. بالنسبة لتحسين الذكاء الاصطناعي، دمج تدفقات البيانات الفورية مع الإطارات مثل TensorFlow أو PyTorch يتيح اتخاذ قرارات فورية وتحديث نماذج مستمر. للوصول الفوري إلى بيانات سياقية، الاستفادة من قواعد البيانات مثل Faiss أو Milvus تساعد في إجراء عمليات بحث سريعة语义ية، والتي تعد cruciale للاستخدامات مثل RAG.
الخاتمة
النقاط الرئيسية تشمل الدور الحاسم لأدوات مثل Apache Kafka وApache Flink في تدفق البيانات القابل للقياس والمنخفض في التأخير، إلى جانب TensorFlow أو PyTorch لتحسين الذكاء الاصطناعي الفوري، وFAISS أو Milvus للبحث السريع语义ي في تطبيقات مثل RAG. ضمان جودة البيانات، وتحسين سير العمل باستخدام أدوات مثل Apache Airflow، وتنفيذ أنظمة مراقبة ومتانة قوية سيساعد الأعمال على البقاء مرنة في عالم يعتمد على البيانات وتحسين قدراتها في اتخاذ القرارات.
موارد إضافية:
- Essentials of AI Automation بواسطة Tuhin Chattopadhyay، Refcard DZone
- أساسيات Apache Kafka لسوديب سينغوبتا، داون زون ريفكارد
- البداية مع نماذج اللغة الكبيرة لتوهين تشاتوبادياي، داون زون ريفكارد
- البداية مع قواعد البيانات المتجهة لميجيل غارسيا، داون زون ريفكارد
هذا摘录 من تقرير DZone للعام 2024،
هندسة البيانات: تحسين أنابيب البيانات، توسيع الذكاء الاصطناعي، وتسريع التحليلات.
Source:
https://dzone.com/articles/the-data-pipeline-movement