













Данная статья представляет собой отрывок из моей книги TinyML Cookbook, Second Edition. Исходный код, используемый в статье, можно найти здесь.
Подготовка
Приложение, которое мы разработаем в этой статье, предназначено для непрерывной записи 1-секундного аудиофрагмента и выполнения вывода модели, как показано на следующем изображении:
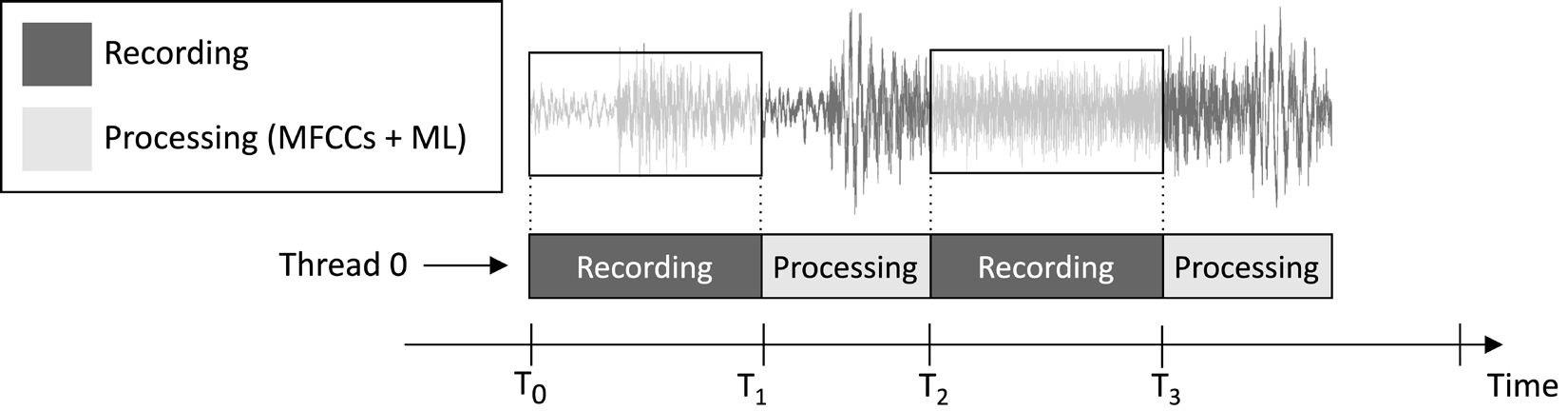
Рисунок 1: Последовательное выполнение задач записи и обработки
Из временной шкалы выполнения задач, показанной на предыдущем изображении, можно заметить, что извлечение признаков и вывод модели всегда происходит после записи аудио и не выполняется одновременно. Следовательно, очевидно, что мы не обрабатываем некоторые сегменты живого аудиопотока.
В отличие от приложения для обнаружения ключевых слов в реальном времени (KWS), которое должно захватывать и обрабатывать все части аудиопотока, чтобы никогда не пропустить произнесенное слово, здесь мы можем смягчить это требование, так как это не ухудшает эффективность приложения.
Как известно, входными данными для извлечения признаков MFCC является 1-секундный необработанный аудиосигнал в формате Q15. Однако образцы, полученные с микрофона, представлены как значения 16-битного целого числа. Поэтому как преобразовать 16-битные целые значения в Q15? Решение оказывается проще, чем можно было ожидать: преобразование аудио образцов не требуется.
Для понимания этого, рассмотрим формат фиксированной точки Q15. Этот формат может представлять значения с плавающей точкой в диапазоне [-1, 1]. Преобразование из чисел с плавающей точкой в Q15 включает умножение значений с плавающей точкой на 32,768 (2^15). Однако, поскольку представление с плавающей точкой возникло из деления 16-битного целого образца на 32,768 (2^15), это подразумевает, что 16-битные целые значения изначально находятся в формате Q15.
Как это сделать…
Возьмите макет с подключенным микрофоном к Raspberry Pi Pico. Отсоедините кабель данных от микроконтроллера и удалите кнопку и связанные с ней перемычки с макета, так как они не требуются для этого рецепта. Рисунок 2 показывает, что у вас должно быть на макете:
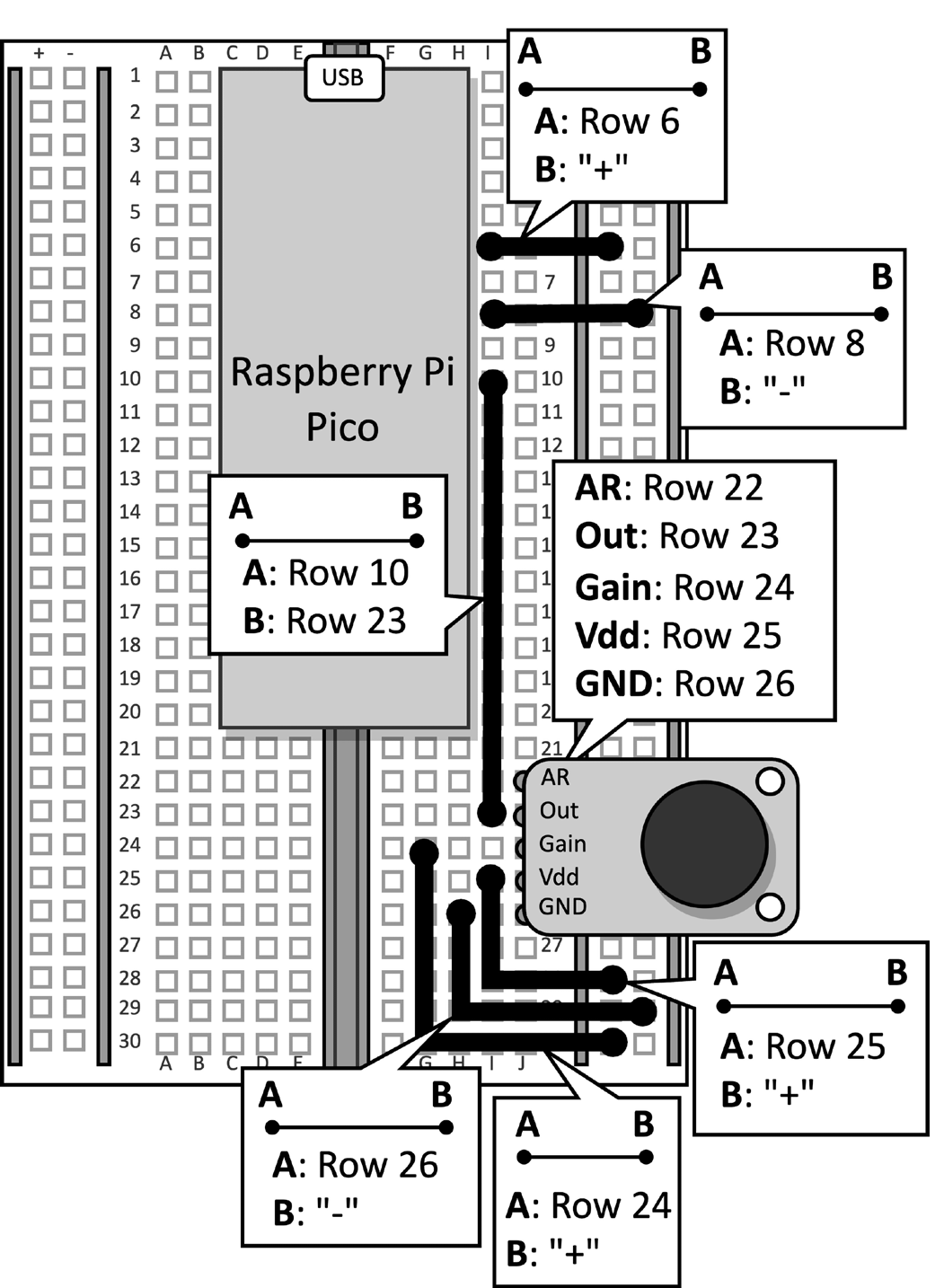
Рисунок 2: Электронная схема, построенная на макете
После удаления кнопки с макета, откройте Arduino IDE и создайте новый скетч.
Теперь следуйте этим шагам для разработки приложения распознавания музыкальных жанров на Raspberry Pi Pico:
Шаг 1
Скачайте библиотеку Arduino TensorFlow Lite с TinyML-Cookbook_2E GitHub репозитория.
После загрузки ZIP-файла импортируйте его в среду разработки Arduino IDE.
Шаг 2
Импортируйте все сгенерированные заголовочные файлы на языке C, необходимые для алгоритма извлечения признаков MFCCs в Arduino IDE, за исключением test_src.h и test_dst.h.
Шаг 3
Копируйте скетч, разработанный в Глава 6, Развертывание алгоритма извлечения признаков MFCCs на Raspberry Pi Pico для реализации алгоритма извлечения признаков MFCCs, исключая функции setup() и loop().
Удалите включение заголовочных файлов test_src.h и test_dst.h. Затем удалите выделение массива dst, так как MFCCs будут храниться непосредственно в входе модели.
Шаг 4
Копируйте скетч, разработанный в Глава 5, Распознавание музыкальных жанров с использованием TensorFlow и Raspberry Pi Pico – Часть 1, для записи аудио образцов с микрофона, исключая функции setup() и loop().
После импорта кода удалите любые ссылки на светодиод и кнопку, так как они больше не требуются. Затем измените определение AUDIO_LENGTH_SEC для записи аудио длительностью 1 секунду:
#define AUDIO_LENGTH_SEC 1Шаг 5
Импортируйте заголовочный файл, содержащий модель TensorFlow Lite (model.h), в проект Arduino.
После импорта файла включите заголовочный файл model.h в скетче:
#include "model.h"
Включить необходимые заголовочные файлы для tflite-micro:
#include
#include
#include
#include
#include
#include Шаг 6
Объявить глобальные переменные для модели и интерпретатора tflite-micro:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
Затем объявить объекты тензоров TensorFlow Lite (TfLiteTensor) для доступа к входным и выходным тензорам модели:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
Шаг 7
Объявить буфер (арена тензоров) для хранения промежуточных тензоров, используемых во время выполнения модели:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
Размер арены тензоров был определен эмпирическим тестированием, так как требуемая память для промежуточных тензоров варьируется в зависимости от реализации оператора LSTM в подвале. Наши эксперименты на Raspberry Pi Pico показали, что модель требует только 16 КБ ОЗУ для выполнения.
Шаг 8
В функции setup() инициализировать последовательный порт с частотой 115200 бод:
Serial.begin(115200);
while (!Serial);
Последовательный порт будет использоваться для передачи распознанного музыкального жанра через последовательное соединение.
Шаг 9
В функции setup() загрузить модель TensorFlow Lite, хранящуюся в заголовочном файле model.h:
tflu_model = tflite::GetModel(model_tflite);Тогда зарегистрируйте все операции DNN, поддерживаемые tflite-micro, и инициализируйте интерпретатор tflite-micro:
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;Шаг 10
В функции setup() выделите память, необходимую для модели, и получите указатели на входные и выходные тензоры:
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
Шаг 11
В функции setup() используйте SDK Raspberry Pi Pico для инициализации внешнего ADC:
adc_init();
adc_gpio_init(26);
adc_select_input(0);
Шаг 12
В функции loop() подготовьте вход модели. Для этого запишите аудиоклип продолжительностью 1 секунда:
// Сброс буфера аудио
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();После записи аудио выделите MFCC:
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
Как видно из предыдущего фрагмента кода, MFCC будут храниться непосредственно во входе модели.
Шаг 13
Запустите выполнение модели и верните результат классификации через последовательное соединение:
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);Теперь вставьте кабель микро-USB в Raspberry Pi Pico. После подключения скомпилируйте и загрузите скетч на микроконтроллер.
Затем откройте монитор последовательного порта в Arduino IDE и поместите свой смартфон рядом с микрофоном, чтобы воспроизвести песню в стиле диско, джаза или металла. Приложение должно теперь распознать жанр музыки песни и отобразить результат классификации в последовательном мониторе!
Заключение
В этой статье вы узнали, как развернуть обученную модель для классификации музыкальных жанров на Raspberry Pi Pico с использованием tflite-micro.
Source:
https://dzone.com/articles/recognizing-music-genres-with-the-raspberry-pi-pic