













Cet article est un extrait de mon livre TinyML Cookbook, Deuxième Édition. Vous pouvez trouver le code utilisé dans l’article ici.
Préparation
L’application que nous concevrons dans cet article vise à enregistrer en continu un clip audio d’une seconde et à exécuter l’inférence du modèle, comme illustré dans l’image suivante:
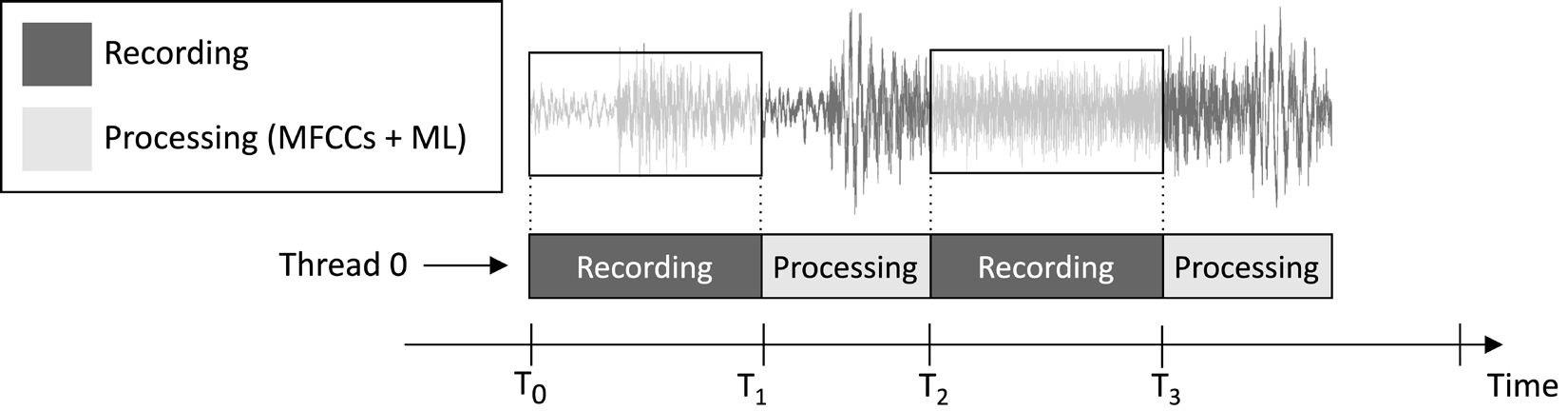
Figure 1 : Enregistrement et tâches de traitement s’exécutant séquentiellement
À partir de l’échéancier d’exécution des tâches indiqué dans l’image précédente, vous pouvez constater que l’extraction de caractéristiques et l’inférence du modèle sont toujours effectuées après l’enregistrement audio et non en parallèle. Par conséquent, il est évident que nous ne traitons pas certaines parties du flux audio en direct.
Contrairement à une application de détection de mots-clés en temps réel (KWS), qui doit capturer et traiter toutes les parties du flux audio pour ne jamais manquer aucune parole prononcée, ici, nous pouvons relâcher cette exigence car elle ne compromet pas l’efficacité de l’application.
Comme nous le savons, l’entrée de l’extraction de caractéristiques MFCC est le son brut d’une seconde en format Q15. Cependant, les échantillons acquis avec le microphone sont représentés sous forme de valeurs entières de 16 bits. Par conséquent, comment convertissons-nous les valeurs entières de 16 bits en Q15? La solution est plus simple que vous ne le pensez : il n’est pas nécessaire de convertir les échantillons audio.
Pour comprendre pourquoi, considérez le format Q15 à virgule fixe. Ce format peut représenter des valeurs à virgule flottante dans la plage [-1, 1]. La conversion de la virgule flottante au format Q15 implique la multiplication des valeurs à virgule flottante par 32 768 (2^15). Cependant, puisque la représentation à virgule flottante provient de la division de l’échantillon entier 16 bits par 32 768 (2^15), cela implique que les valeurs entières 16 bits sont intrinsèquement au format Q15.
Comment le faire…
Prenez la planche à découper avec le microphone attaché au Raspberry Pi Pico. Déconnectez le câble de données du microcontrôleur et retirez le bouton poussoir et ses cavaliers connectés de la planche à découper, car ils ne sont pas nécessaires pour cette recette. Figure 2 montre ce que vous devriez avoir sur la planche à découper:
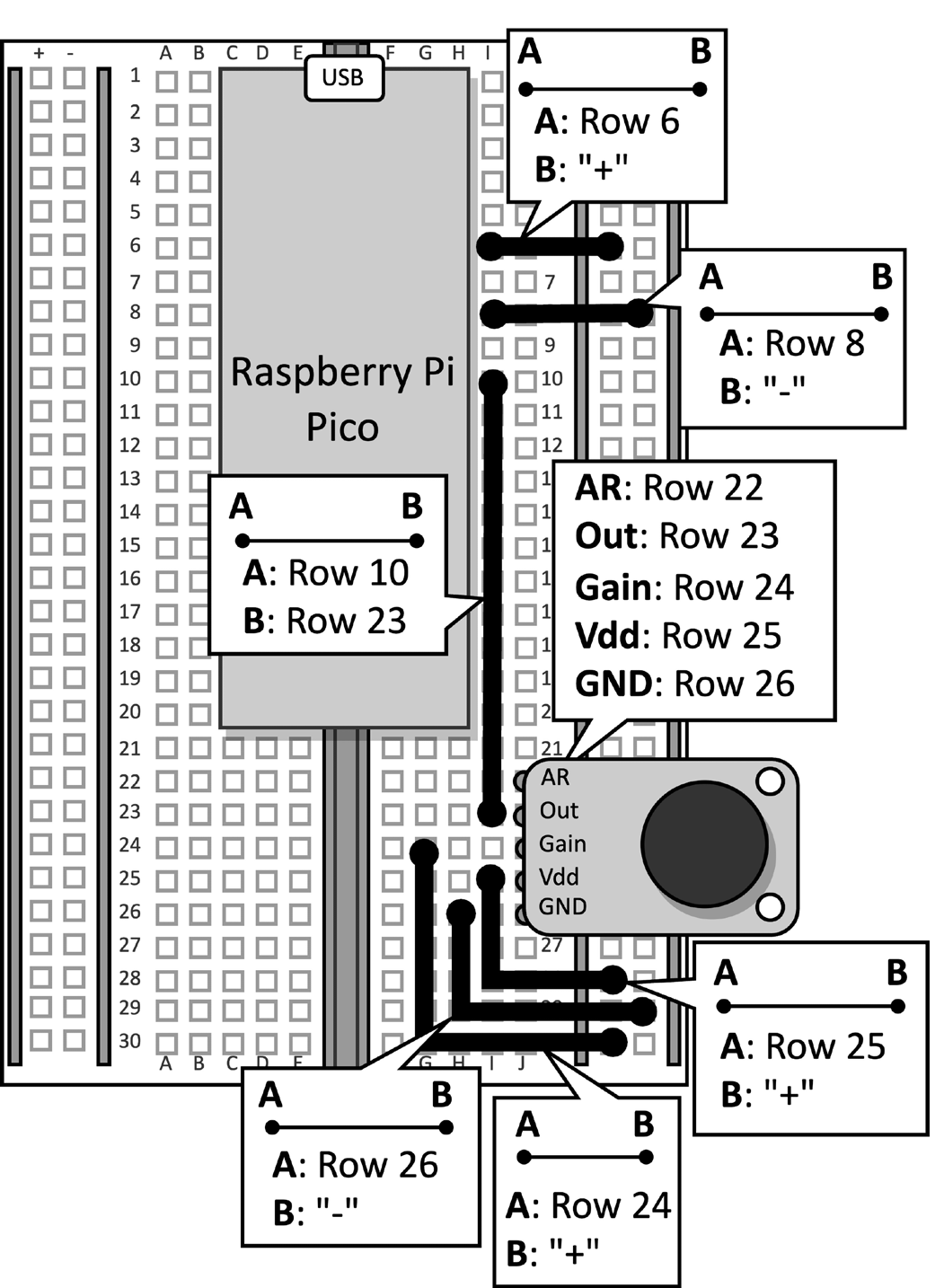
Figure 2 : Le circuit électronique construit sur la planche à découper
Après avoir retiré le bouton poussoir de la planche à découper, ouvrez l’IDE Arduino et créez un nouveau croquis.
Maintenant, suivez les étapes suivantes pour développer l’application de reconnaissance de genre musical sur le Raspberry Pi Pico:
Étape 1
Téléchargez la bibliothèque Arduino TensorFlow Lite à partir du TinyML-Cookbook_2E dépôt GitHub repository.
Après avoir téléchargé le fichier ZIP, importez-le dans l’IDE Arduino.
Étape 2
Importez tous les fichiers d’en-tête C générés nécessaires pour l’algorithme d’extraction de caractéristiques MFCC dans l’IDE Arduino, à l’exclusion de test_src.h et test_dst.h.
Étape 3
Copiez le croquis développé dans Chapitre 6, Déploiement de l’algorithme d’extraction de caractéristiques MFCC sur le Raspberry Pi Pico pour mettre en œuvre l’extraction de caractéristiques MFCC, à l’exclusion des fonctions setup() et loop().
Supprimez l’inclusion des fichiers d’en-tête test_src.h et test_dst.h. Ensuite, supprimez l’allocation du tableau dst, car les MFCC seront stockés directement dans l’entrée du modèle.
Étape 4
Copiez le croquis développé dans Chapitre 5, Reconnaissance des genres musicaux avec TensorFlow et le Raspberry Pi Pico – Partie 1, pour enregistrer des échantillons audio avec le microphone, à l’exclusion des fonctions setup() et loop().
Une fois que vous avez importé le code, supprimez toute référence à la LED et au bouton-poussoir, car ils ne sont plus nécessaires. Ensuite, modifiez la définition de AUDIO_LENGTH_SEC pour enregistrer un audio d’une durée d’une seconde :
#define AUDIO_LENGTH_SEC 1Étape 5
Importez le fichier d’en-tête contenant le modèle TensorFlow Lite (model.h) dans le projet Arduino.
Une fois le fichier importé, incluez le fichier d’en-tête model.h dans le croquis :
#include "model.h"
Inclure les fichiers d’en-tête nécessaires pour tflite-micro:
#include
#include
#include
#include
#include
#include Étape 6
Déclarer des variables globales pour le modèle et l’interpréteur tflite-micro:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
Ensuite, déclarer les objets de tenseur TensorFlow Lite (TfLiteTensor) pour accéder aux tenseurs d’entrée et de sortie du modèle:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
Étape 7
Déclarer un tampon (aire de tenseur) pour stocker les tenseurs intermédiaires utilisés pendant l’exécution du modèle:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
La taille de l’aire de tenseur a été déterminée par des tests empiriques, car la mémoire nécessaire pour les tenseurs intermédiaires varie, en fonction de la manière dont l’opérateur LSTM est implémenté en dessous. Nos expériences sur le Raspberry Pi Pico ont montré que le modèle n’a besoin que de 16 Ko de RAM pour l’inférence.
Étape 8
Dans la fonction setup(), initialiser le périphérique série avec un débit de 115200:
Serial.begin(115200);
while (!Serial);
Le périphérique série sera utilisé pour transmettre le genre de musique reconnu via la communication série.
Étape 9
Dans la fonction setup(), charger le modèle TensorFlow Lite stocké dans le fichier d’en-tête model.h:
tflu_model = tflite::GetModel(model_tflite);Ensuite, inscrivez toutes les opérations DNN prises en charge par tflite-micro et initialisez l’interpréteur tflite-micro :
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;Étape 10
Dans la fonction setup(), allouez la mémoire nécessaire pour le modèle et obtenez le pointeur mémoire des tenseurs d’entrée et de sortie :
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
Étape 11
Dans la fonction setup(), utilisez le SDK Raspberry Pi Pico pour initialiser le périphérique ADC :
adc_init();
adc_gpio_init(26);
adc_select_input(0);
Étape 12
Dans la fonction loop(), préparez l’entrée du modèle. Pour ce faire, enregistrez un clip audio pendant 1 seconde :
// Réinitialisez le tampon audio
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();Après l’enregistrement audio, extrayez les MFCC :
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
Comme vous pouvez le voir dans le code précédent, les MFCC seront stockés directement dans l’entrée du modèle.
Étape 13
Exécutez l’inférence du modèle et renvoyez le résultat de classification via la communication série :
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);Maintenant, branchez le câble micro-USB dans le Raspberry Pi Pico. Une fois connecté, compilez et téléversez le croquis sur le microcontrôleur.
Ensuite, ouvrez le moniteur série dans l’IDE Arduino et placez votre smartphone près du microphone pour jouer un morceau de disco, de jazz ou de metal. L’application devrait maintenant reconnaître le genre musical de la chanson et afficher le résultat de classification dans le moniteur série !
Conclusion
Dans cet article, vous avez appris à déployer un modèle entraîné pour la classification des genres musicaux sur le Raspberry Pi Pico en utilisant tflite-micro.
Source:
https://dzone.com/articles/recognizing-music-genres-with-the-raspberry-pi-pic