













Este artigo é um trecho do meu livro TinyML Cookbook, Segunda Edição. Você pode encontrar o código utilizado no artigo aqui.
Preparação
O aplicativo que desenharemos neste artigo tem como objetivo gravar continuamente um clipe de áudio de 1 segundo e executar a inferência do modelo, como ilustrado na imagem a seguir:
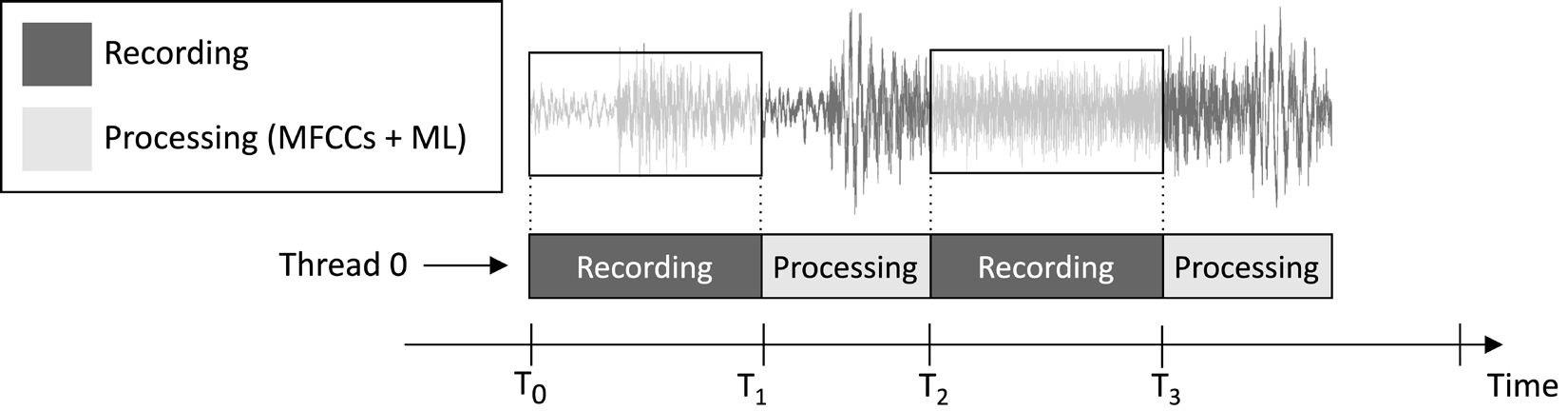
Figura 1: Tarefas de gravação e processamento executadas sequencialmente
A partir do cronograma de execução de tarefas mostrado na imagem anterior, você pode observar que a extração de características e a inferência do modelo são sempre realizadas após a gravação de áudio e não de forma concorrente. Portanto, é evidente que não processamos algumas partes do fluxo de áudio ao vivo.
Ao contrário de um aplicativo de detecção de palavras-chave em tempo real (KWS), que deve capturar e processar todos os pedaços do fluxo de áudio para nunca perder nenhuma palavra falada, aqui, podemos relaxar esse requisito porque isso não prejudica a eficácia do aplicativo.
Como sabemos, a entrada da extração de características MFCCs é o áudio bruto de 1 segundo no formato Q15. No entanto, as amostras adquiridas com o microfone são representadas como valores inteiros de 16 bits. Portanto, como convertemos os valores inteiros de 16 bits para Q15? A solução é mais simples do que você pode pensar: não é necessário converter as amostras de áudio.
Para entender por que, considere o formato de ponto fixo Q15. Esse formato pode representar valores de ponto flutuante dentro do intervalo [-1, 1]. A conversão de ponto flutuante para Q15 envolve multiplicar os valores de ponto flutuante por 32.768 (2^15). No entanto, como a representação de ponto flutuante origina-se da divisão do exemplo de inteiro de 16 bits por 32.768 (2^15), isso implica que os valores de inteiros de 16 bits são inerentemente no formato Q15.
Como Fazer…
Pegue a placa de teste com o microfone conectado ao Raspberry Pi Pico. Desconecte o cabo de dados do microcontrolador e remova o botão de pressão e seus jumpers conectados da placa de teste, pois não são necessários para esta receita. Figura 2 mostra o que você deve ter na placa de teste:
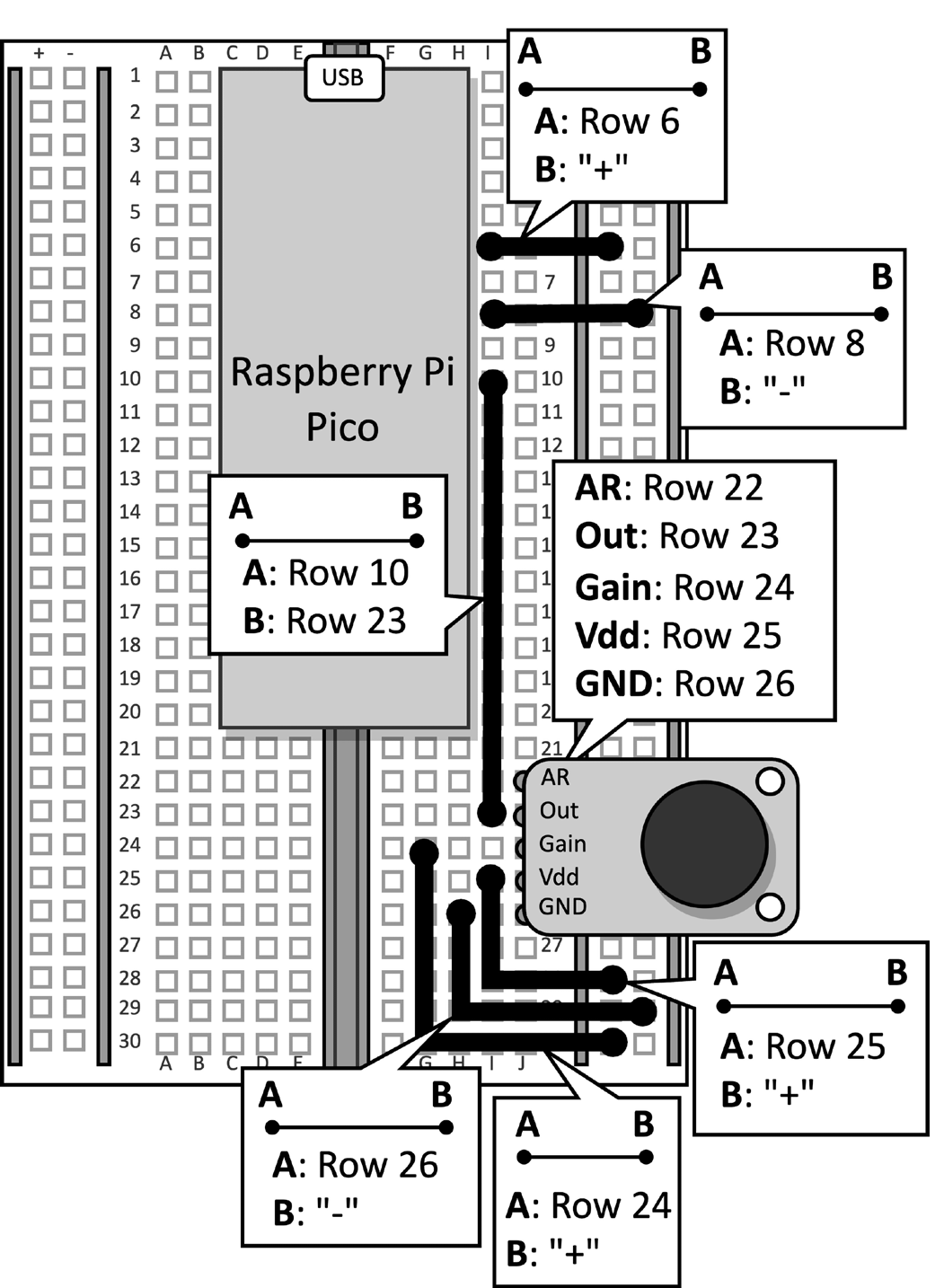
Figura 2: O circuito eletrônico construído na placa de teste
Após remover o botão de pressão da placa de teste, abra o Arduino IDE e crie um novo esboço.
Agora, siga os seguintes passos para desenvolver o aplicativo de reconhecimento de gênero musical no Raspberry Pi Pico:
Passo 1
Baixe a biblioteca Arduino TensorFlow Lite do TinyML-Cookbook_2E repositório do GitHub repositório.
Após baixar o arquivo ZIP, importe-o no Arduino IDE.
Passo 2
Importe todos os arquivos de cabeçalho C gerados necessários para o algoritmo de extração de características MFCCs no Arduino IDE, excluindo test_src.h e test_dst.h.
Passo 3
Copie o esboço desenvolvido em Capítulo 6, Implantação do algoritmo de extração de características MFCCs no Raspberry Pi Pico para implementar a extração de características MFCCs, excluindo as funções setup() e loop().
Remova a inclusão dos arquivos de cabeçalho test_src.h e test_dst.h. Em seguida, remova a alocação do array dst, pois os MFCCs serão armazenados diretamente na entrada do modelo.
Passo 4
Copie o esboço desenvolvido em Capítulo 5, Reconhecendo Gêneros Musicais com TensorFlow e o Raspberry Pi Pico – Parte 1, para gravar amostras de áudio com o microfone, excluindo as funções setup() e loop().
Após importar o código, remova qualquer referência à LED e ao botão de pressão, pois eles não são mais necessários. Em seguida, altere a definição de AUDIO_LENGTH_SEC para gravar áudio que dure 1 segundo:
#define AUDIO_LENGTH_SEC 1Passo 5
Importe o arquivo de cabeçalho contendo o modelo TensorFlow Lite (model.h) no projeto Arduino.
Após a importação do arquivo, inclua o arquivo de cabeçalho model.h no esboço:
#include "model.h"
Inclua os arquivos de cabeçalho necessários para tflite-micro:
#include
#include
#include
#include
#include
#include Passo 6
Declare variáveis globais para o modelo e o interpretador tflite-micro:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
Em seguida, declare os objetos de tensor TensorFlow Lite (TfLiteTensor) para acessar os tensores de entrada e saída do modelo:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
Passo 7
Declare um buffer (arena de tensor) para armazenar os tensores intermediários usados durante a execução do modelo:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
O tamanho da arena de tensor foi determinado por testes empíricos, já que a memória necessária para os tensores intermediários varia, dependendo de como o operador LSTM é implementado por baixo. Nossos experimentos no Raspberry Pi Pico descobriram que o modelo requer apenas 16 KB de RAM para inferência.
Passo 8
No método setup(), inicialize o periférico serial com uma taxa de 115200 bauds:
Serial.begin(115200);
while (!Serial);
O periférico serial será utilizado para transmitir o gênero musical reconhecido através da comunicação serial.
Passo 9
No método setup(), carregue o modelo TensorFlow Lite armazenado no arquivo de cabeçalho model.h:
tflu_model = tflite::GetModel(model_tflite);Então, registre todas as operações do DNN suportadas pelo tflite-micro e inicialize o interpretador tflite-micro:
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;
Passo 10
Na função setup(), aloque a memória necessária para o modelo e obtenha o ponteiro de memória dos tensores de entrada e saída:
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
Passo 11
Na função setup(), use o SDK do Raspberry Pi Pico para inicializar o periférico ADC:
adc_init();
adc_gpio_init(26);
adc_select_input(0);
Passo 12
Na função loop(), prepare a entrada do modelo. Para fazer isso, grave um clipe de áudio por 1 segundo:
// Redefinir buffer de áudio
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();Após gravar o áudio, extraia os MFCCs:
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
Como você pode ver no trecho de código anterior, os MFCCs serão armazenados diretamente na entrada do modelo.
Passo 13
Execute a inferência do modelo e retorne o resultado da classificação pela comunicação serial:
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);Agora, conecte o cabo de dados micro-USB no Raspberry Pi Pico. Uma vez conectado, compile e envie o esboço no microcontrolador.
Em seguida, abra o monitor serial no Arduino IDE e coloque seu smartphone perto do microfone para tocar uma música de discoteca, jazz ou metal. A aplicação deve agora reconhecer o gênero musical da música e exibir o resultado da classificação no monitor serial!
Conclusão
Neste artigo, você aprendeu como implantar um modelo treinado para classificação de gêneros musicais no Raspberry Pi Pico usando tflite-micro.
Source:
https://dzone.com/articles/recognizing-music-genres-with-the-raspberry-pi-pic