













Dieser Artikel ist ein Auszug aus meinem Buch TinyML Cookbook, Second Edition. Sie können den in dem Artikel verwendeten Code hier.
Vorbereitung
Das in diesem Artikel entworfene Anwendungsbeispiel soll fortlaufend einen 1-sekündigen Audioclip aufzeichnen und Modellinferenzen durchführen, wie in folgendem Bild dargestellt:
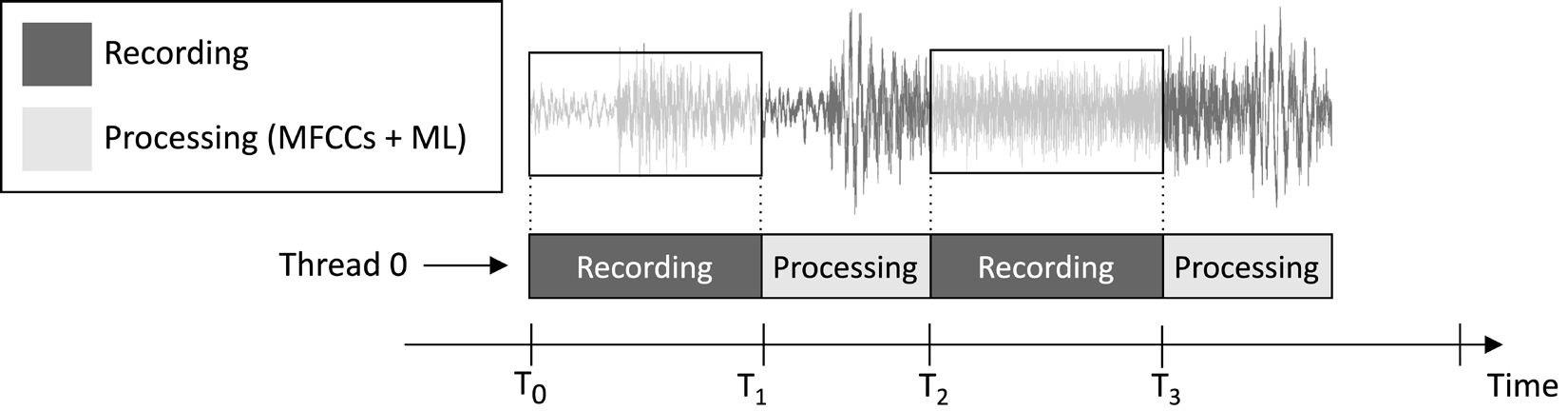
Abbildung 1: Aufzeichnungs- und Verarbeitungsaufgaben sequentiell ausgeführt
Aus der im vorherigen Bild gezeigten Aufgabenausführungszeitachse können Sie erkennen, dass die Merkmalsextraktion und Modellinferenz immer nach der Audioaufnahme und nicht gleichzeitig erfolgen. Daher ist offensichtlich, dass wir einige Abschnitte des Live-Audios im Stream nicht verarbeiten.
Im Gegensatz zu einer Echtzeit-Schlüsselwort-Erkennungs-Anwendung (KWS), die alle Teile des Audios im Stream erfassen und verarbeiten sollte, um niemals ein gesprochenes Wort zu verpassen, können wir hier diese Anforderung lockern, da sie die Effektivität der Anwendung nicht beeinträchtigt.
Wie wir wissen, ist die Eingabe der MFCC-Merkmalsextraktion der 1-sekündige Roh-Audio in Q15-Format. Die mit dem Mikrofon erfassten Samples werden jedoch als 16-Bit-Integer-Werte dargestellt. Daher wie konvertieren wir die 16-Bit-Integer-Werte in Q15? Die Lösung ist einfacher, als Sie vielleicht denken: Die Konvertierung der Audiosamples ist nicht notwendig.
Um das zu verstehen, betrachten wir das Q15 Festkommaformat. Dieses Format kann Gleitkommawerte im Bereich von [-1, 1] darstellen. Die Konvertierung von Gleitkomma zu Q15 erfolgt durch Multiplikation der Gleitkommawerte mit 32.768 (2^15). Da die Gleitkommadarstellung jedoch aus der Division des 16-Bit-Ganzzahl-Samples durch 32.768 (2^15) entsteht, bedeutet dies, dass die 16-Bit-Ganzzahlwerte von Natur aus im Q15-Format vorliegen.
So geht’s…
Nimm die Steckplatine mit dem angeschlossenen Mikrofon an derRaspberry Pi Pico. Trenne das Datenkabel vom Mikrocontroller und entferne den Druckknopf und die damit verbundenen Jumper von der Steckplatine, da sie für dieses Rezept nicht benötigt werden. Abbildung 2 zeigt, was auf der Steckplatine vorhanden sein sollte:
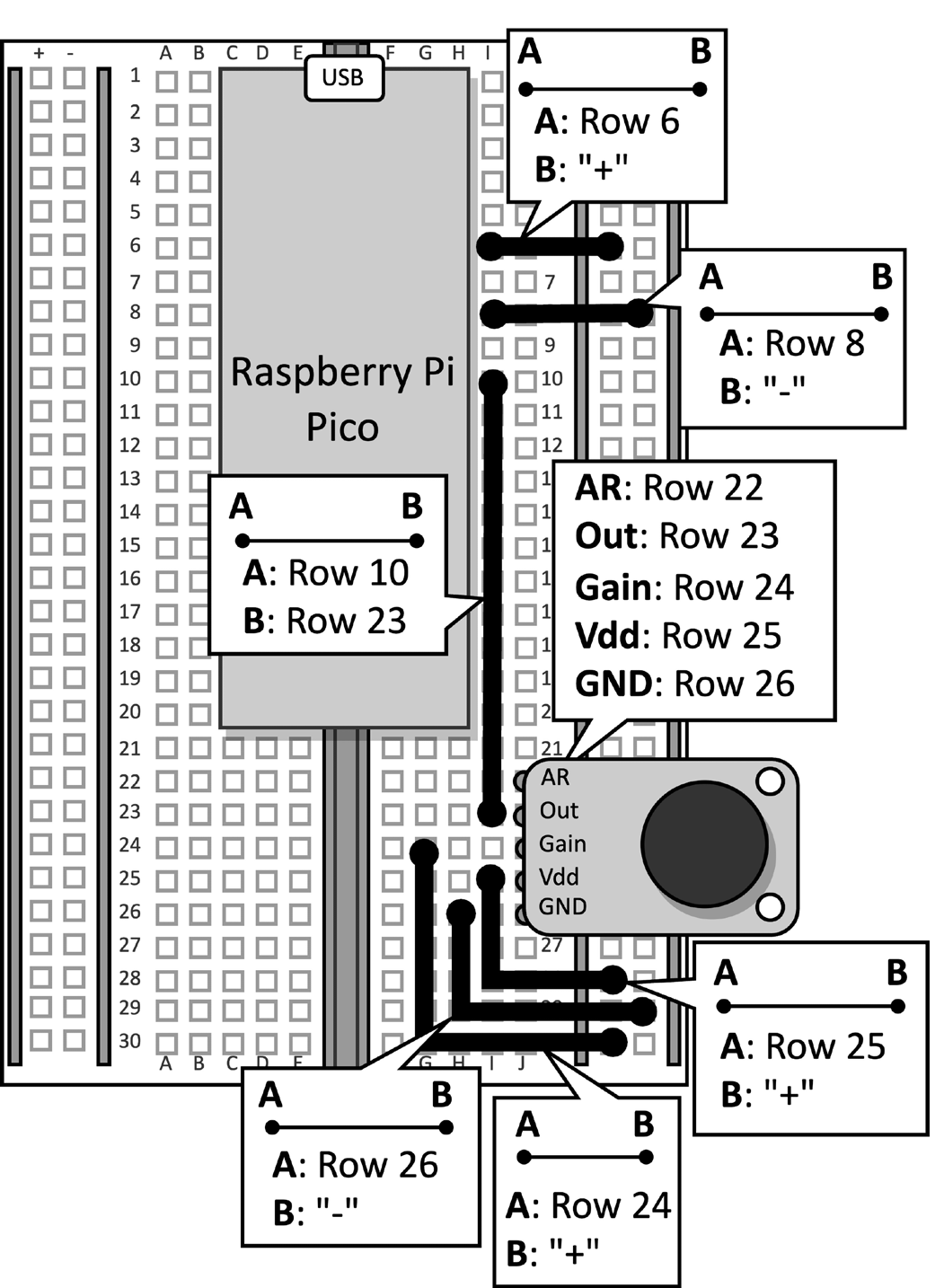
Abbildung 2: Der auf der Steckplatine aufgebaute elektronische Schaltkreis
Nachdem der Druckknopf von der Steckplatine entfernt wurde, öffne die Arduino IDE und erstelle eine neue Skizze.
Führe nun die folgenden Schritte aus, um die Musikstilerkennungsanwendung auf dem Raspberry Pi Pico zu entwickeln:
Schritt 1
Lade die ArduinoTensorFlow Lite-Bibliothek aus demTinyML-Cookbook_2E GitHubRepositoryherunter.
Nachdem Sie die ZIP-Datei heruntergeladen haben, importieren Sie sie in die Arduino IDE.
Schritt 2
Importieren Sie alle erzeugten C-Header-Dateien, die für den MFCCs-Merkmalsextraktionsalgorithmus benötigt werden, in der Arduino IDE, mit Ausnahme von test_src.h und test_dst.h.
Schritt 3
Kopieren Sie den in Kapitel 6, Bereitstellen des MFCCs-Merkmalsextraktionsalgorithmus auf dem Raspberry Pi Pico entwickelten Sketch für die Implementierung der MFCCs-Merkmalsextraktion, mit Ausnahme der setup() und loop() Funktionen.
Entfernen Sie die Einbindung der Header-Dateien test_src.h und test_dst.h. Entfernen Sie anschließend die Zuweisung des dst-Arrays, da die MFCCs direkt in der Eingabe des Modells gespeichert werden.
Schritt 4
Kopieren Sie den in Kapitel 5, Erkennen von Musikgenres mit TensorFlow und dem Raspberry Pi Pico – Teil 1 entwickelten Sketch, um Audiosamples mit dem Mikrofon aufzunehmen, mit Ausnahme der setup() und loop() Funktionen.
Sobald Sie den Code importiert haben, entfernen Sie alle Verweise auf die LED und den Druckknopf, da sie nicht mehr benötigt werden. Ändern Sie dann die Definition von AUDIO_LENGTH_SEC zur Aufnahme von Audio mit einer Dauer von 1 Sekunde:
#define AUDIO_LENGTH_SEC 1Schritt 5
Importieren Sie die Header-Datei, die das TensorFlow Lite Modell (model.h) enthält, in das Arduino-Projekt.
Nachdem die Datei importiert wurde, binden Sie die model.h Header-Datei in den Sketch ein:
#include "model.h"
Schließen Sie die notwendigen Header-Dateien für tflite-micro ein:
#include
#include
#include
#include
#include
#include Schritt 6
Deklarieren Sie globale Variablen für das tflite-micro-Modell und den Interpreter:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
Dann deklarieren Sie die TensorFlow Lite Tensor-Objekte (TfLiteTensor) zur Zugriff auf die Eingabe- und Ausgabetensoren des Modells:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
Schritt 7
Deklarieren Sie einen Puffer (Tensor Arena) zum Speichern der während der Modellausführung verwendeten Zwischentensoren:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
Die Größe des Tensor Arenas wurde durch empirische Tests bestimmt, da der Speicherbedarf für die Zwischentensoren je nach Implementierung des LSTM-Operators unter der Haube variiert. Unsere Experimente auf dem Raspberry Pi Pico ergaben, dass das Modell für die Inferenz nur 16 KB RAM benötigt.
Schritt 8
In der setup()-Funktion initialisieren Sie den seriellen Peripheriegerät mit einer 115200 Baudrate:
Serial.begin(115200);
while (!Serial);
Das serielle Peripheriegerät wird verwendet, um das erkannte Musikgenre über die serielle Kommunikation zu übertragen.
Schritt 9
In der setup()-Funktion laden Sie das in der model.h-Headerdatei gespeicherte TensorFlow Lite-Modell:
tflu_model = tflite::GetModel(model_tflite);Dann registrieren Sie alle DNN-Operationen, die von tflite-micro unterstützt werden, und initialisieren Sie den tflite-micro-Interpreter:
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;Schritt 10
In der setup()-Funktion reservieren Sie den Speicher, der für das Modell benötigt wird, und erhalten den Speicherzeiger für die Eingabe- und Ausgabetensoren:
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
Schritt 11
In der setup()-Funktion initialisieren Sie mithilfe des Raspberry Pi Pico SDK das ADC-Peripheriegerät:
adc_init();
adc_gpio_init(26);
adc_select_input(0);
Schritt 12
In der loop()-Funktion bereiten Sie die Eingabe des Modells vor. Dazu nehmen Sie einen 1-sekündigen Audioschnipsel auf:
// Audio-Puffer zurücksetzen
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();Nach dem Aufnehmen des Audios extrahieren Sie die MFCCs:
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
Wie aus dem vorhergehenden Codeausschnitt ersichtlich ist, werden die MFCCs direkt in der Eingabe des Modells gespeichert.
Schritt 13
Führen Sie die Modellinferenz aus und geben Sie das Klassifizierungsergebnis über die serielle Kommunikation zurück:
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);Schließen Sie nun das Micro-USB-Datenkabel an den Raspberry Pi Pico an. Sobald Sie es verbunden haben, kompilieren und laden Sie die Skizze auf dem Mikrocontroller hoch.
Danach öffnen Sie das serielle Monitor-Tool in der Arduino IDE und halten Sie Ihr Smartphone in der Nähe des Mikrofons, um ein Disco-, Jazz- oder Metal-Lied abzuspielen. Die Anwendung sollte nun den Musikstil des Liedes erkennen und das Klassifizierungsergebnis im seriellen Monitor anzeigen!
Schlussfolgerung
In diesem Artikel hast du gelernt, wie man ein trainiertes Modell zur Musikgenreklassifizierung auf dem Raspberry Pi Pico unter Verwendung von tflite-micro bereitstellt.
Source:
https://dzone.com/articles/recognizing-music-genres-with-the-raspberry-pi-pic