













Если вам надоело, что ваши сценарии Bash выполняются вечность, этот учебник для вас. Часто вы можете запускать сценарии Bash параллельно, что может значительно ускорить результат. Как? Используя утилиту GNU Parallel, также называемую просто Parallel, с некоторыми удобными примерами GNU Parallel!
Parallel выполняет сценарии Bash параллельно с помощью концепции, называемой многопоточностью. Эта утилита позволяет запускать различные задания на каждом ЦП вместо только одного, сокращая время выполнения сценария.
В этом учебнике вы узнаете о многопоточности сценариев Bash с большим количеством примеров GNU Parallel!
Предварительные требования
Этот учебник будет полон практических демонстраций. Если вы собираетесь следовать за мной, убедитесь, что у вас есть следующее:
- A Linux computer. Any distribution will work. The tutorial uses Ubuntu 20.04 running on Windows Subsystem for Linux (WSL).
- Войдите в систему от имени пользователя с привилегиями sudo.
Установка GNU Parallel
Для начала ускорения сценариев Bash с многопоточностью сначала необходимо установить Parallel. Итак, давайте начнем с загрузки и установки.
1. Откройте терминал Bash.
2. Выполните wget для загрузки пакета Parallel. Приведенная ниже команда загружает последнюю версию (parallel-latest) в текущий рабочий каталог.
Если вы предпочитаете использовать более старую версию GNU Parallel, вы можете найти все пакеты на официальном сайте загрузок.
3. Теперь выполните команду tar ниже, чтобы разархивировать только что загруженный пакет.
В данной команде используется флаг x для извлечения архива, j для указания, что архив имеет расширение .bz2, и f для указания файла в качестве входных данных для команды tar. sudo tar -xjf parallel-latest.tar.bz2
Теперь у вас должна быть папка с именем parallel- с указанием месяца, дня и года последнего выпуска.
4. Перейдите в папку архива пакета с помощью команды cd. В этом руководстве папка архива пакета называется parallel-20210422, как показано ниже.
5. Затем соберите и установите двоичный файл GNU Parallel, выполнив следующие команды:
Теперь проверьте, что Parallel установлен правильно, проверив установленную версию.
При первом запуске Parallel вы также можете увидеть несколько пугающих строк, содержащих текст вроде
perl: warning:. Эти предупреждения указывают, что Parallel не может определить вашу текущую локаль и языковые настройки. Но пока не беспокойтесь о них. Позже вы узнаете, как исправить эти предупреждения.
Настройка GNU Parallel
Теперь, когда установлен Parallel, вы можете использовать его сразу! Но прежде всего важно настроить несколько небольших параметров перед началом.
В то время как вы находитесь в вашем терминале Bash, согласитесь на разрешение для академических исследований GNU Parallel, указав параметр citation, за которым следует will cite.
Если вы не хотите поддерживать GNU или его разработчиков, согласие на цитирование не требуется для использования GNU Parallel.
Измените локальные настройки, установив следующие переменные окружения, выполнив указанные ниже строки кода. Установка локали и переменных среды языка, подобным образом, не является обязательным требованием. Но GNU Parallel проверяет их при каждом запуске.
Если переменные среды не существуют, Parallel будет жаловаться на них при каждом запуске, как вы видели в предыдущем разделе.
Этот учебник предполагает, что вы говорите на английском языке. Другие языки также поддерживаются.
Запуск Ad-Hoc Shell Commands
Давайте начнем использовать GNU Parallel! Сначала вы изучите базовый синтаксис. Как только вы будете уверены в синтаксисе, перейдем к нескольким удобным примерам использования GNU Parallel.
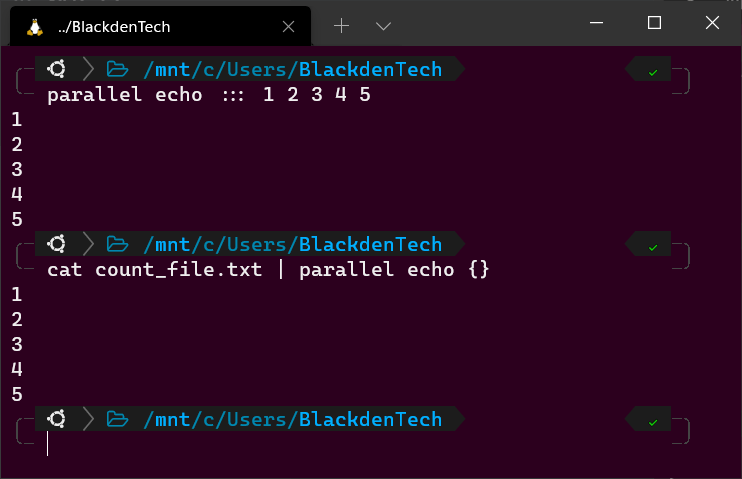
Для начала давайте рассмотрим супер-простой пример, в котором просто выводятся числа от 1 до 5.
1. В вашем терминале Bash выполните следующие команды. Увлекательно, верно? В Bash используется команда echo для отправки чисел от 1 до 5 в терминал. Если бы вы поместили каждую из этих команд в скрипт, Bash выполнил бы их последовательно, ожидая завершения предыдущей.
В этом примере вы выполняете пять команд, которые почти не занимают времени. Но представьте, что если бы эти команды были настоящими скриптами Bash, которые выполняли полезные действия, но требовали вечность для выполнения?
Теперь выполните каждую из этих команд одновременно с помощью Parallel, как показано ниже. В этом примере Parallel запускает команду echo и, обозначенную символом :::, передает этой команде аргументы 1, 2, 3, 4, 5. Три двоеточия сообщают Parallel, что вы предоставляете ввод через командную строку, а не через конвейер (подробнее позже).
В приведенном ниже примере вы передали одну команду Parallel без параметров. Здесь, как и во всех примерах использования Parallel, Parallel запускает новый процесс для каждой команды, используя разные ядра ЦП.
Все команды Parallel следуют синтаксису
parallel [Опции] <Команда для многопоточного выполнения>.
3. Чтобы продемонстрировать параллельный прием ввода из конвейера Bash, создайте файл с именем count_file.txt как показано ниже. Каждое число представляет собой аргумент, который вы передадите команде echo.
4. Теперь запустите команду cat, чтобы прочитать этот файл и передать вывод в Parallel, как показано ниже. В этом примере {} представляет каждый аргумент (1-5), который будет передан в Parallel.
Сравнение Bash и GNU Parallel
Сейчас использование Parallel может показаться сложным способом выполнения команд Bash. Но реальное преимущество для вас – это экономия времени. Помните, что Bash будет выполняться только на одном ядере CPU, в то время как GNU Parallel будет работать сразу на нескольких.
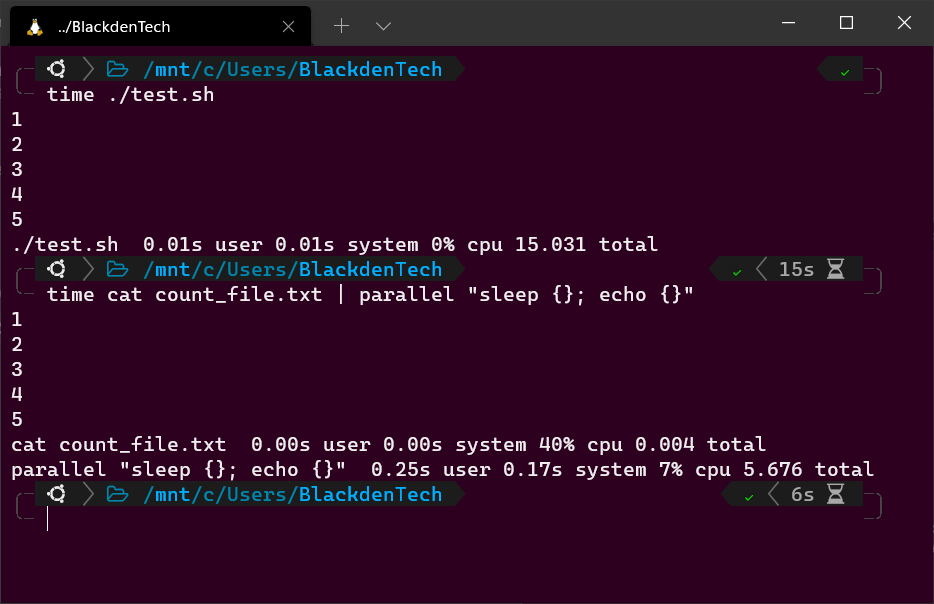
1. Чтобы продемонстрировать разницу между последовательными командами Bash и Parallel, создайте сценарий Bash с именем test.sh с следующим кодом. Создайте этот сценарий в том же каталоге, где вы ранее создали count_file.txt.
Сценарий Bash ниже читает файл count_file.txt, засыпает на 1, 2, 3, 4 и 5 секунд, выводит длину сна в терминал и завершается.
2. Теперь запустите сценарий, используя команду time, чтобы измерить, сколько времени займет выполнение сценария. Это займет 15 секунд.
3. Теперь используйте команду time снова, чтобы выполнить ту же задачу, но на этот раз используйте Parallel.
Нижеприведенная команда выполняет ту же задачу, но на этот раз, вместо ожидания завершения первого цикла перед началом следующего, она будет запускать один на каждом ядерном процессоре и начнет столько, сколько может одновременно.
Знайте Пробный Запуск!
Пришло время перейти к некоторым более реальным примерам использования GNU Parallel. Но прежде, чем вы это сделаете, вы должны знать о флаге --dryrun. Этот флаг пригодится, когда вы хотите увидеть, что произойдет без фактического выполнения Parallel.
Флаг --dryrun может быть финальной проверкой перед запуском команды, которая ведет себя не так, как вы ожидали. К сожалению, если вы введете команду, которая может повредить вашу систему, единственное, что поможет вам GNU Parallel, это сделать это еще быстрее!
Пример GNU Parallel №1: Загрузка файлов из Интернета
Для этой задачи вы будете загружать список файлов с различных URL-адресов в Интернете. Например, эти URL-адреса могут представлять веб-страницы, которые вы хотите сохранить, изображения или даже список файлов с FTP-сервера.
Для этого примера вы собираетесь загрузить список архивных пакетов (и файлы SIG) с FTP-сервера GNU Parallel.
1. Создайте файл с именем download_items.txt, возьмите несколько ссылок для загрузки с официального сайта загрузок и добавьте их в файл, разделяя новой строкой.
Вы можете сэкономить время, используя библиотеку Beautiful Soup Python для парсинга всех ссылок с страницы загрузки.
2. Прочтите все URL-адреса из файла download_items.txt и передайте их в Parallel, который вызовет wget и передаст каждый URL-адрес.
Не забудьте, что
{}в команде parallel является заполнителем для входной строки!
3. Возможно, вам нужно контролировать количество потоков, которые одновременно использует GNU Parallel. Если это так, добавьте параметр --jobs или -j к команде. Параметр --jobs ограничивает количество потоков, которые могут запускаться параллельно, до указанного вами числа.
Например, чтобы ограничить Parallel на загрузку пяти URL-адресов одновременно, команда будет выглядеть следующим образом:
Параметр
--jobsв указанной команде может быть настроен для загрузки любого количества файлов, при условии, что компьютер, на котором вы выполняете его, имеет достаточно много процессоров для их обработки.
4. Чтобы продемонстрировать эффект параметра --jobs, теперь измените количество заданий и запустите команду time, чтобы измерить, сколько времени занимает каждый запуск.
Пример GNU Parallel №2: Разархивация архивных пакетов
Теперь, когда у вас есть все эти файлы архивов, скачанные из предыдущего примера, вам нужно их разархивировать.
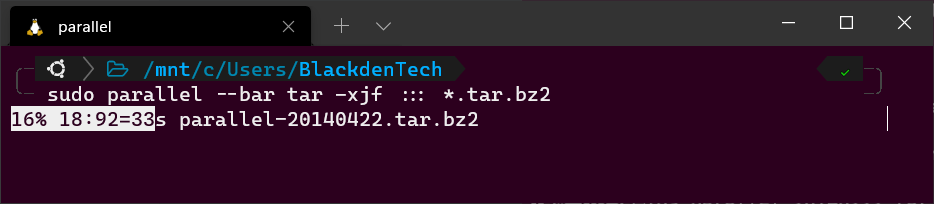
Находясь в том же каталоге, что и архивные пакеты, запустите следующую команду Parallel. Обратите внимание на использование символа подстановки (*). Поскольку этот каталог содержит как архивные пакеты, так и файлы SIG, вы должны указать Parallel, чтобы он обрабатывал только файлы .tar.bz2.
Бонус! Если вы используете GNU parallel интерактивно (не в сценарии), добавьте флаг --bar, чтобы Parallel показал вам индикатор выполнения задачи в виде полосы прогресса.
--bar flagПример GNU Parallel №3: Удаление файлов
Если вы следовали примерам один и два, у вас должно быть много папок в вашем рабочем каталоге, занимающих место. Давайте теперь удалите все эти файлы параллельно!
Для удаления всех папок, которые начинаются с parallel- с помощью Parallel, перечислите все папки с помощью ls -d и направьте каждый путь к папке в Parallel, вызывая rm -rf для каждой папки, как показано ниже.
Не забудьте флаг
--dryrun!
Заключение
Теперь вы можете автоматизировать задачи с помощью Bash и сэкономить много времени. Что вы выберете делать с этим временем, зависит от вас. Будь то ранний уход с работы или чтение другой поста блога ATA, это время возвращается в ваш день.
Теперь подумайте о всех долго работающих сценариях в вашей среде. Какие из них вы можете ускорить с помощью Parallel?
Source:
https://adamtheautomator.com/how-to-speed-up-bash-scripts-with-multithreading-and-gnu-parallel/