













Wenn Ihre Bash-Skripte ewig zum Ausführen benötigen und Sie es satt haben, ist dieses Tutorial genau das Richtige für Sie. Oft können Sie Bash-Skripte parallel ausführen, was das Ergebnis dramatisch beschleunigen kann. Wie? Mit dem Dienstprogramm GNU Parallel, auch einfach Parallel genannt, und einigen nützlichen Beispielen von GNU Parallel!
Parallel führt Bash-Skripte parallel über ein Konzept namens Multithreading aus. Dieses Dienstprogramm ermöglicht es Ihnen, verschiedene Aufgaben pro CPU auszuführen, anstatt nur einer, was die Ausführungszeit eines Skripts verkürzt.
In diesem Tutorial lernen Sie, wie Sie Bash-Skripte mit Multithreading anhand von vielen großartigen Beispielen von GNU Parallel erstellen!
Voraussetzungen
Dieses Tutorial wird voller praktischer Demonstrationen sein. Wenn Sie mitmachen möchten, stellen Sie sicher, dass Sie Folgendes haben:
- A Linux computer. Any distribution will work. The tutorial uses Ubuntu 20.04 running on Windows Subsystem for Linux (WSL).
- Mit einem Benutzer mit sudo-Berechtigungen angemeldet.
Installation von GNU Parallel
Um Bash-Skripte mit Multithreading zu beschleunigen, müssen Sie zunächst Parallel installieren. Also lassen Sie uns beginnen, indem wir es herunterladen und installieren.
1. Öffnen Sie ein Bash-Terminal.
2. Führen Sie wget aus, um das Parallel-Paket herunterzuladen. Der folgende Befehl lädt die neueste Version (parallel-latest) in das aktuelle Arbeitsverzeichnis herunter.
Wenn Sie lieber eine ältere Version von GNU Parallel verwenden möchten, finden Sie alle Pakete auf der offiziellen Download-Seite.
3. Führen Sie nun den untenstehenden tar-Befehl aus, um das gerade heruntergeladene Paket zu entpacken.
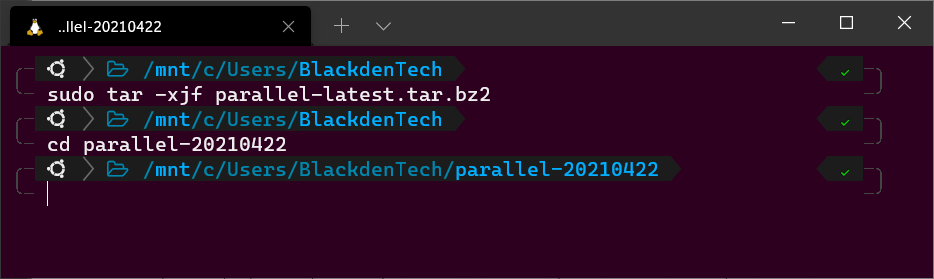
Im folgenden Befehl wird die x-Flagge verwendet, um das Archiv zu extrahieren, j, um anzugeben, dass es sich um ein Archiv mit der Erweiterung .bz2 handelt, und f, um eine Datei als Eingabe für den Tar-Befehl anzunehmen. sudo tar -xjf parallel-latest.tar.bz2
Sie sollten jetzt ein Verzeichnis mit dem Namen parallel- mit dem Monat, dem Tag und dem Jahr der neuesten Veröffentlichung haben.
4. Navigieren Sie in den Paketarchivordner mit cd. In diesem Tutorial wird der Paketarchivordner wie unten gezeigt parallel-20210422 genannt.
5. Installieren Sie als nächstes das GNU Parallel-Binary, indem Sie die folgenden Befehle ausführen:
Überprüfen Sie nun, ob Parallel korrekt installiert wurde, indem Sie die installierte Version überprüfen.
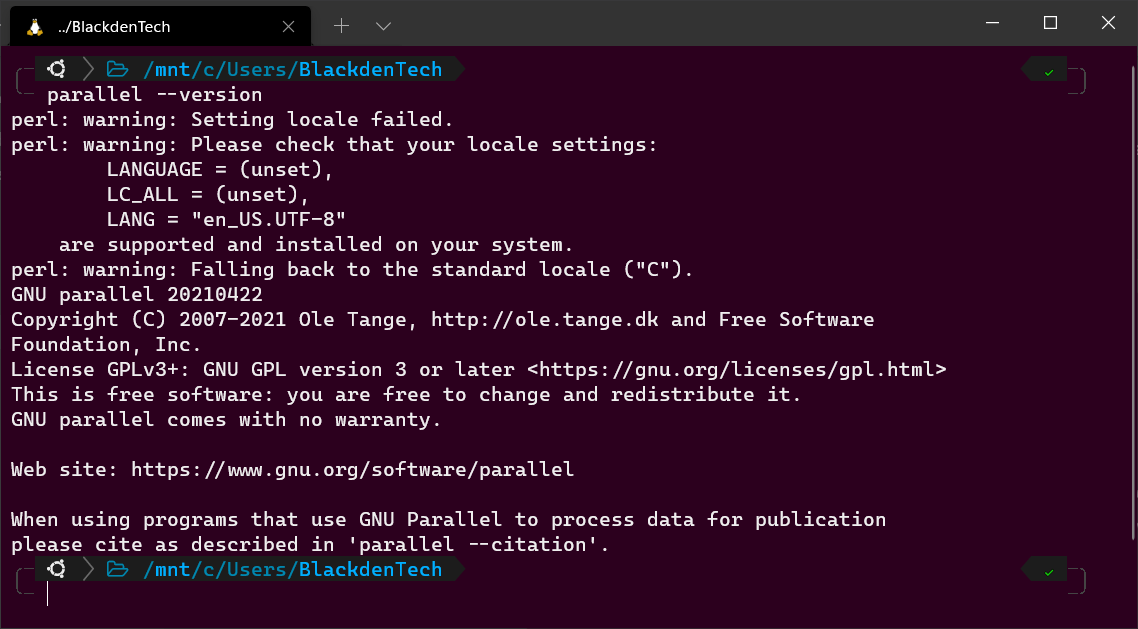
Wenn Sie Parallel zum ersten Mal ausführen, sehen Sie möglicherweise auch ein paar beängstigende Zeilen, die Text wie
perl: warning:anzeigen. Diese Warnmeldungen zeigen an, dass Parallel Ihre aktuellen Gebiets- und Spracheinstellungen nicht erkennen kann. Aber machen Sie sich vorerst keine Sorgen um diese Warnungen. Sie werden später lernen, wie Sie diese Warnungen beheben können.
Konfigurieren von GNU Parallel
Jetzt, da Parallel installiert ist, können Sie es sofort verwenden! Bevor Sie jedoch loslegen, ist es wichtig, einige kleinere Einstellungen zu konfigurieren.
Während Sie sich noch in Ihrem Bash-Terminal befinden, stimmen Sie der GNU Parallel-Akademische Forschungsvereinbarung zu, indem Sie den Parameter citation gefolgt von will cite angeben und damit Parallel mitteilen, dass Sie es in jeder akademischen Forschung zitieren werden.
Wenn Sie GNU oder seine Maintainer nicht unterstützen möchten, ist es nicht erforderlich, Parallel zu zitieren, um es zu verwenden.
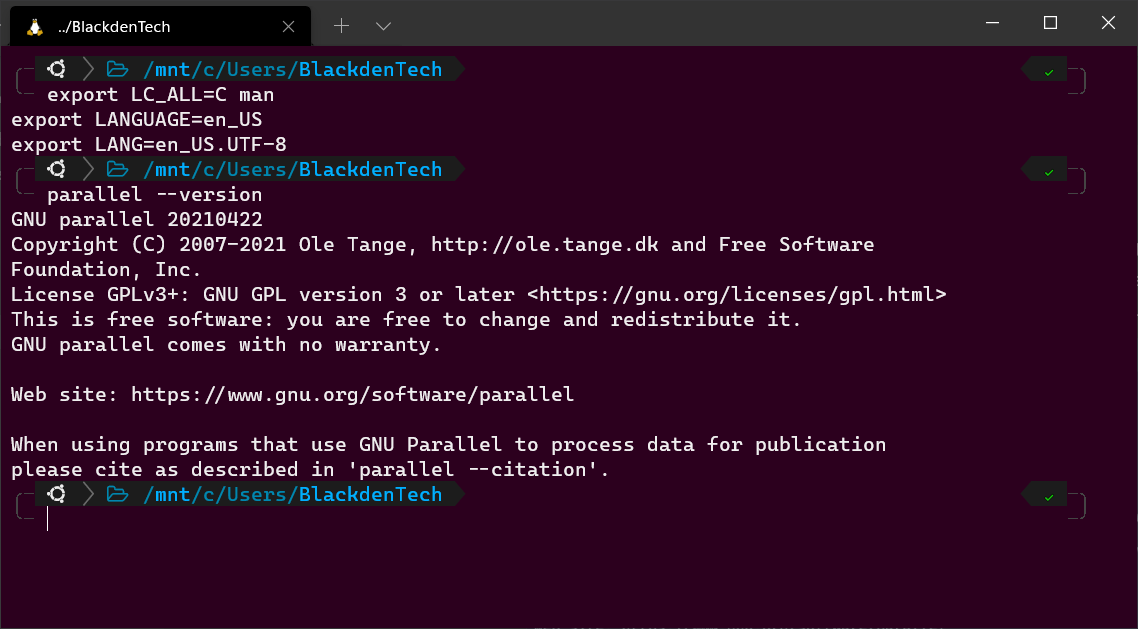
Ändern Sie die Spracheinstellung, indem Sie die folgenden Umgebungsvariablen durch Ausführen der untenstehenden Codezeilen setzen. Das Festlegen von Umgebungsvariablen für Sprache und Locale ist keine Voraussetzung. Aber GNU Parallel überprüft sie jedes Mal, wenn es ausgeführt wird.
Wenn die Umgebungsvariablen nicht vorhanden sind, beschwert sich Parallel jedes Mal darüber, wie Sie im vorherigen Abschnitt gesehen haben.
In diesem Tutorial wird davon ausgegangen, dass Sie Englisch sprechen. Es werden auch andere Sprachen unterstützt.
Ausführen von Ad-Hoc-Shell-Befehlen
Lassen Sie uns jetzt mit GNU Parallel beginnen! Zuerst lernen Sie die grundlegende Syntax. Sobald Sie mit der Syntax vertraut sind, werden Sie später einige praktische Beispiele mit GNU Parallel kennenlernen.
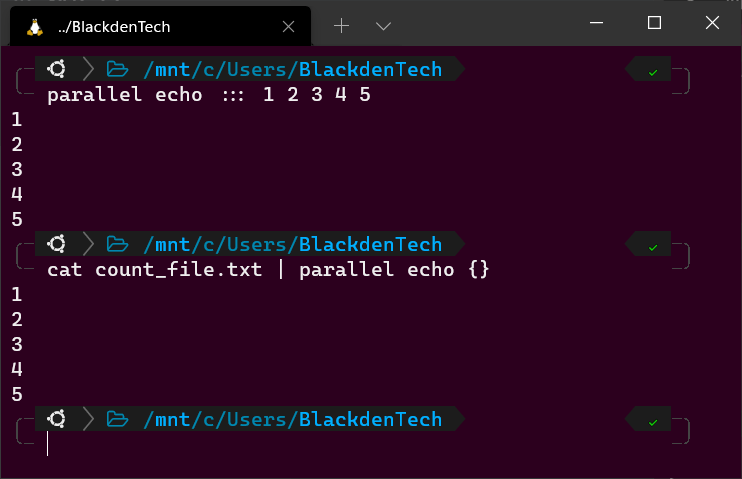
Beginnen wir mit einem super-einfachen Beispiel, bei dem nur die Zahlen 1-5 ausgegeben werden.
1. Führen Sie die folgenden Befehle in Ihrem Bash-Terminal aus. Spannend, oder? Bash verwendet den Echo-Befehl, um die Zahlen 1-5 an das Terminal zu senden. Wenn Sie jeden dieser Befehle in einem Skript platzieren würden, würde Bash jeden Befehl sequenziell ausführen und auf das Ende des vorherigen Befehls warten.
In diesem Beispiel führen Sie fünf Befehle aus, die kaum Zeit benötigen. Aber stellen Sie sich vor, diese Befehle wären Bash-Skripte, die tatsächlich etwas Nützliches tun, aber eine Ewigkeit zum Ausführen brauchen würden?
Führen Sie nun jeden dieser Befehle gleichzeitig mit Parallel aus, wie unten gezeigt. In diesem Beispiel führt Parallel den Echo-Befehl mit den Argumenten 1, 2, 3, 4, 5 aus, die durch die drei Doppelpunkte gekennzeichnet sind. Die drei Doppelpunkte geben Parallel an, dass Sie die Eingabe über die Befehlszeile und nicht über die Pipeline bereitstellen (mehr dazu später).
In dem untenstehenden Beispiel haben Sie einen einzelnen Befehl ohne Optionen an Parallel übergeben. Hier hat Parallel, wie in allen Parallel-Beispielen, für jeden Befehl einen neuen Prozess gestartet, der einen anderen CPU-Kern verwendet.
Alle Parallel-Befehle folgen der Syntax
Parallel [Optionen] <Befehl zum Mehrfach-Threaden>.
3. Um zu demonstrieren, wie Parallel Eingaben aus der Bash-Pipeline empfängt, erstellen Sie eine Datei namens count_file.txt wie unten dargestellt. Jede Zahl stellt das Argument dar, das Sie an den echo-Befehl übergeben werden.
4. Führen Sie nun den Befehl cat aus, um diese Datei zu lesen, und leiten Sie die Ausgabe an Parallel weiter, wie unten gezeigt. In diesem Beispiel stellt {} jedes Argument (1-5) dar, das an Parallel übergeben wird.
Vergleich von Bash und GNU Parallel
Derzeit mag die Verwendung von Parallel einfach wie eine komplizierte Möglichkeit erscheinen, Bash-Befehle auszuführen. Aber der wirkliche Vorteil für Sie liegt in der Zeitersparnis. Denken Sie daran, dass Bash nur auf einem CPU-Kern läuft, während GNU Parallel gleichzeitig auf mehreren Kernen läuft.
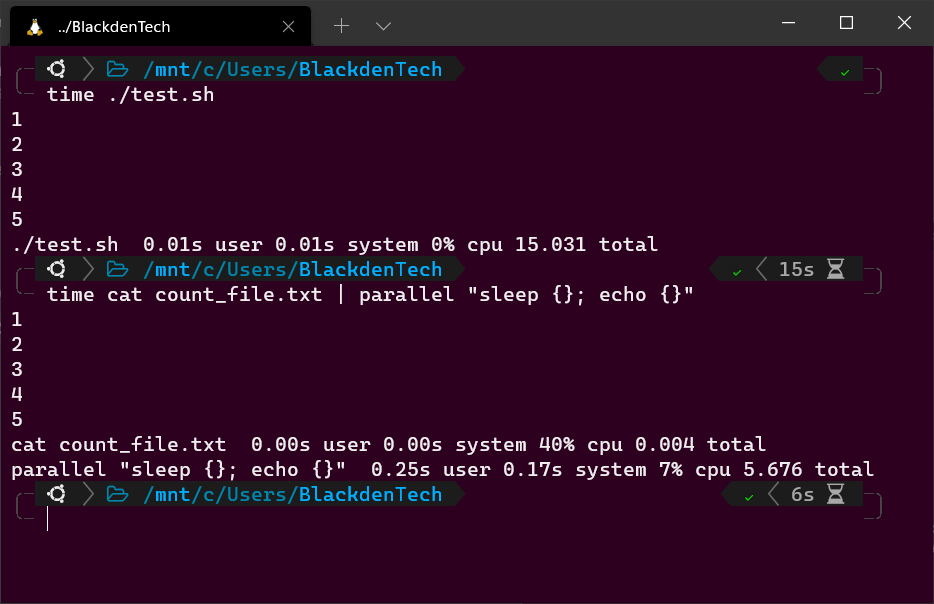
1. Um den Unterschied zwischen sequenziellen Bash-Befehlen und Parallel zu demonstrieren, erstellen Sie ein Bash-Skript namens test.sh mit folgendem Code. Erstellen Sie dieses Skript im selben Verzeichnis, in dem Sie zuvor die Datei count_file.txt erstellt haben.
Das untenstehende Bash-Skript liest die Datei count_file.txt, wartet jeweils 1, 2, 3, 4 und 5 Sekunden, gibt die Länge der Wartezeit auf dem Terminal aus und beendet sich.
2. Führen Sie nun das Skript mit dem time-Befehl aus, um zu messen, wie lange das Skript zum Abschluss benötigt. Es dauert 15 Sekunden.
3. Verwenden Sie nun den time-Befehl erneut, um dieselbe Aufgabe auszuführen, verwenden Sie diesmal jedoch Parallel dazu.
Der folgende Befehl führt dieselbe Aufgabe aus, jedoch anstatt darauf zu warten, dass die erste Schleife abgeschlossen ist, bevor die nächste gestartet wird, wird jede auf einem eigenen CPU-Kern ausgeführt und so viele wie möglich gleichzeitig gestartet.
Kennen Sie den Dry Run!
Es ist jetzt an der Zeit, einige praxisnahe Beispiele für GNU Parallel zu betrachten. Bevor Sie dies tun, sollten Sie jedoch zunächst über das Flag --dryrun Bescheid wissen. Dieses Flag ist nützlich, wenn Sie sehen möchten, was passieren wird, ohne dass Parallel es tatsächlich ausführt.
Die --dryrun Flagge kann als letzte Überprüfung vor der Ausführung eines Befehls dienen, der sich nicht so verhält, wie Sie es erwartet haben. Leider kann Ihnen GNU Parallel nur dabei helfen, Ihr System schneller zu schädigen, wenn Sie einen Befehl eingeben, der Ihrem System schaden würde!
GNU Parallel Beispiel #1: Dateien aus dem Web herunterladen
Für diese Aufgabe werden Sie eine Liste von Dateien von verschiedenen URLs im Web herunterladen. Diese URLs könnten zum Beispiel Webseiten sein, die Sie speichern möchten, Bilder oder sogar eine Liste von Dateien von einem FTP-Server.
In diesem Beispiel werden Sie eine Liste von Archivpaketen (und den SIG-Dateien) von GNU Parallels FTP-Server herunterladen.
1. Erstellen Sie eine Datei namens download_items.txt, suchen Sie sich einige Download-Links von der offiziellen Download-Seite und fügen Sie sie mit einem Zeilenumbruch getrennt in die Datei ein.
Sie könnten Zeit sparen, indem Sie die Python-Bibliothek Beautiful Soup verwenden, um alle Links von der Download-Seite zu extrahieren.
2. Lesen Sie alle URLs aus der Datei download_items.txt und übergeben Sie sie an Parallel, der wget aufrufen und jede URL übergeben wird.
Vergessen Sie nicht, dass
{}in einem Parallel-Befehl ein Platzhalter für den Eingabestring ist!
3. Möglicherweise müssen Sie die Anzahl der Threads steuern, die GNU Parallel gleichzeitig verwendet. Wenn ja, fügen Sie dem Befehl den Parameter --jobs oder -j hinzu. Der Parameter --jobs begrenzt die Anzahl der gleichzeitig auszuführenden Threads auf die von Ihnen angegebene Anzahl.
Zum Beispiel, um Parallel darauf zu beschränken, fünf URLs gleichzeitig herunterzuladen, würde der Befehl so aussehen:
Der
--jobs-Parameter in obigem Befehl kann angepasst werden, um eine beliebige Anzahl von Dateien herunterzuladen, vorausgesetzt, der Computer, auf dem Sie arbeiten, verfügt über genügend CPUs, um sie zu verarbeiten.
4. Um die Auswirkungen des --jobs-Parameters zu demonstrieren, passen Sie jetzt die Anzahl der Jobs an und führen Sie den Befehl time aus, um zu messen, wie lange jeder Lauf dauert.
GNU Parallel Beispiel #2: Entpacken von Archivpaketen
Nun, da Sie alle diese Archivdateien aus dem vorherigen Beispiel heruntergeladen haben, müssen Sie diese jetzt entpacken.
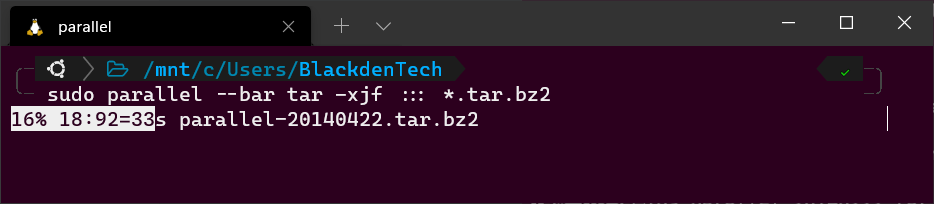
Während Sie sich im gleichen Verzeichnis wie die Archivpakete befinden, führen Sie den folgenden Parallel-Befehl aus. Beachten Sie die Verwendung des Platzhalters (*). Da dieses Verzeichnis sowohl Archivpakete als auch die SIG-Dateien enthält, müssen Sie Parallel mitteilen, dass nur .tar.bz2-Dateien verarbeitet werden sollen.
Bonus! Wenn Sie GNU Parallel interaktiv verwenden (nicht in einem Skript), fügen Sie die Option --bar hinzu, um Parallel während der Ausführung eine Fortschrittsanzeige anzeigen zu lassen.
--bar flagGNU Parallel Beispiel #3: Löschen von Dateien
Wenn Sie den Beispielen eins und zwei gefolgt sind, sollten Sie jetzt viele Ordner in Ihrem Arbeitsverzeichnis haben, die Platz beanspruchen. Lassen Sie uns also alle diese Dateien parallel entfernen!
Um alle Ordner zu entfernen, die mit parallel- beginnen, verwenden Sie Parallel, um alle Ordner mit ls -d aufzulisten und leiten Sie dann jeden Ordnerpfad an Parallel weiter. Rufen Sie rm -rf für jeden Ordner auf, wie unten gezeigt.
Vergessen Sie die
--dryrun-Flagge nicht!
Fazit
Jetzt können Sie Aufgaben mit Bash automatisieren und viel Zeit sparen. Was Sie mit dieser Zeit machen, liegt bei Ihnen. Ob Zeit sparen bedeutet, etwas früher Feierabend zu machen oder einen weiteren ATA-Blogbeitrag zu lesen, bleibt Ihnen überlassen.
Denken Sie jetzt an all die lang laufenden Skripte in Ihrer Umgebung. Welche davon können Sie mit Parallel beschleunigen?
Source:
https://adamtheautomator.com/how-to-speed-up-bash-scripts-with-multithreading-and-gnu-parallel/