













Se sei stanco che i tuoi script Bash impieghino tanto tempo per eseguire, questo tutorial fa al caso tuo. Spesso, puoi eseguire script Bash in parallelo, il che può velocizzare notevolmente il risultato. Come? Utilizzando l’utilità GNU Parallel, anche chiamata semplicemente Parallel, con alcuni utili esempi di GNU Parallel!
Parallel esegue script Bash in parallelo tramite un concetto chiamato multi-threading. Questa utilità ti permette di eseguire diversi lavori per CPU anziché solo uno, riducendo il tempo di esecuzione di uno script.
In questo tutorial, imparerai a eseguire script Bash multi-threading con un sacco di ottimi esempi di GNU Parallel!
Prerequisiti
Questo tutorial sarà pieno di dimostrazioni pratiche. Se intendi seguirci, assicurati di avere quanto segue:
- A Linux computer. Any distribution will work. The tutorial uses Ubuntu 20.04 running on Windows Subsystem for Linux (WSL).
- Accesso con un utente con privilegi sudo.
Installazione di GNU Parallel
Per iniziare a velocizzare gli script Bash con il multithreading, devi prima installare Parallel. Quindi cominciamo scaricando e installandolo.
1. Apri un terminale Bash.
2. Esegui wget per scaricare il pacchetto Parallel. Il comando seguente scarica l’ultima versione (parallel-latest) nella directory di lavoro corrente.
Se preferisci utilizzare una versione più vecchia di GNU Parallel, puoi trovare tutti i pacchetti sul sito ufficiale di download.
3. Ora, esegui il comando tar di seguito per decomprimere il pacchetto che hai appena scaricato.
Di seguito, il comando utilizza il flag x per estrarre l’archivio, j per specificare che si tratta di un archivio con estensione .bz2, e f per accettare un file come input per il comando tar. sudo tar -xjf parallel-latest.tar.bz2
Dovresti ora avere una directory chiamata parallel- con il mese, il giorno e l’anno dell’ultima versione rilasciata.
4. Passa alla cartella dell’archivio del pacchetto con cd. In questo tutorial, la cartella dell’archivio del pacchetto si chiama parallel-20210422, come mostrato di seguito.
5. Successivamente, compila e installa il binario di GNU Parallel eseguendo i seguenti comandi:
Ora, verifica che Parallel sia stato installato correttamente controllando la versione installata.
Quando esegui Parallel per la prima volta, potresti anche vedere un paio di righe spaventose che mostrano testo come
perl: warning:. Questi messaggi di avvertimento indicano che Parallel non riesce a rilevare le tue impostazioni correnti di localizzazione e lingua. Ma non preoccuparti di questi avvisi per ora. Imparerai come risolvere questi avvisi più avanti.
Configurazione di GNU Parallel
Ora che Parallel è installato, puoi usarlo immediatamente! Ma prima, è importante configurare alcune impostazioni minori prima di iniziare.
Mentre sei ancora nel tuo terminale Bash, accetta il permesso di ricerca accademica di GNU Parallel dicendo a Parallel che lo citerai in qualsiasi ricerca accademica specificando il parametro citation seguito da will cite.
Se non vuoi supportare GNU o i suoi manutentori, accettare di citare non è richiesto per usare GNU Parallel.
Cambia la localizzazione impostando le seguenti variabili d’ambiente eseguendo le righe di codice qui sotto. Impostare variabili d’ambiente per locale e lingua in questo modo non è un requisito. Ma GNU Parallel le controlla ogni volta che viene eseguito.
Se le variabili d’ambiente non esistono, Parallel si lamenterà di esse ogni volta come hai visto nella sezione precedente.
Questo tutorial presume che tu sia un parlante inglese. Anche altre lingue sono supportate.
Esecuzione di comandi shell ad-hoc
Cominciamo ora ad usare GNU Parallel! Per iniziare, imparerai la sintassi di base. Una volta a tuo agio con la sintassi, passerai a alcuni utili esempi di GNU Parallel più avanti.
Per iniziare, copriamo un esempio super semplice di semplicemente stampare i numeri da 1 a 5.
1. Nel tuo terminale Bash, esegui i seguenti comandi. Emozionante, vero? Bash utilizza il comando echo per inviare i numeri da 1 a 5 al terminale. Se avessi messo ciascuno di questi comandi in uno script, Bash li eseguirebbe uno dopo l’altro, aspettando che il precedente finisca.
In questo esempio, stai eseguendo cinque comandi che non richiedono quasi tempo. Ma, immagina se quei comandi fossero script Bash che fanno qualcosa di utile ma impiegano una vita per eseguirsi?
Ora, esegui ciascuno di questi comandi contemporaneamente con Parallel come segue. In questo esempio, Parallel esegue il comando echo e, designato dai :::, passa a quel comando gli argomenti, 1, 2, 3, 4, 5. I tre due punti dicono a Parallel che stai fornendo l’input tramite la riga di comando anziché tramite il pipeline (più avanti).
Nell’esempio seguente, hai passato un singolo comando a Parallel senza opzioni. Qui, come in tutti gli esempi di Parallel, Parallel ha avviato un nuovo processo per ogni comando utilizzando un diverso core della CPU.
Tutti i comandi di Parallel seguono la sintassi
parallel [Opzioni] <Comando da multithreading>.
3. Per dimostrare la ricezione parallela dell’input dalla pipeline di Bash, crea un file chiamato count_file.txt come segue. Ogni numero rappresenta l’argomento che passerai al comando echo.
4. Ora, esegui il comando cat per leggere quel file e passa l’output a Parallel, come mostrato di seguito. In questo esempio, il {} rappresenta ogni argomento (1-5) che verrà passato a Parallel.
Confronto tra Bash e GNU Parallel
Al momento, l’utilizzo di Parallel potrebbe sembrare solo un modo complicato per eseguire comandi Bash. Ma il vero vantaggio per te è il risparmio di tempo. Ricorda, Bash funzionerà su un solo core della CPU, mentre GNU Parallel funzionerà su diversi contemporaneamente.
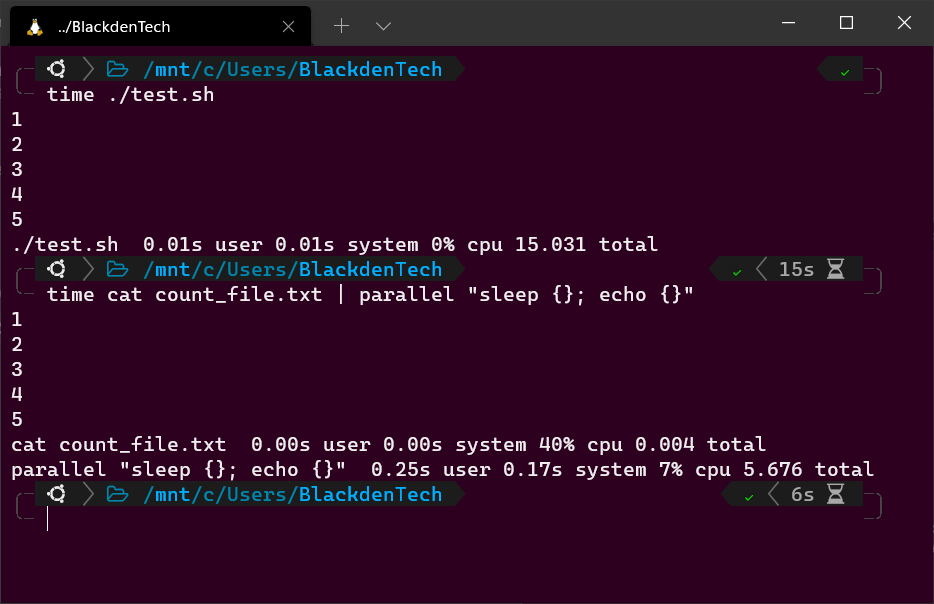
1. Per dimostrare la differenza tra i comandi Bash sequenziali e Parallel, crea uno script Bash chiamato test.sh con il seguente codice. Crea questo script nella stessa directory in cui hai creato il count_file.txt in precedenza.
Lo script Bash di seguito legge il file count_file.txt, attende per 1, 2, 3, 4 e 5 secondi, stampa la durata dell’attesa al terminale e si termina.
2. Ora, esegui lo script utilizzando il comando time per misurare quanto tempo impiega lo script per completarsi. Ci vorranno 15 secondi.
3. Ora, utilizza di nuovo il comando time per eseguire la stessa attività, ma questa volta utilizza Parallel per farlo.
Il comando sottostante esegue la stessa attività, ma questa volta, anziché attendere che il primo ciclo completi prima di avviare il successivo, eseguirà uno su ogni core della CPU e avvierà tanti cicli contemporaneamente quanti ne può.
Conosci l’Esecuzione di Prova!
È ora il momento di passare ad alcuni esempi di esecuzione pratica di GNU Parallel. Ma, prima di farlo, dovresti sapere del flag --dryrun. Questo flag è utile quando vuoi vedere cosa succederà senza che Parallel lo faccia effettivamente.
Il flag --dryrun può essere l’ultimo controllo di sanità prima di eseguire un comando che non si comporta come pensavi. Purtroppo, se inserisci un comando che potrebbe danneggiare il tuo sistema, l’unica cosa che GNU Parallel ti aiuterà a fare è danneggiarlo più rapidamente!
Esempio di GNU Parallel #1: Scaricare File dal Web
Per questa attività, scaricherai un elenco di file da vari URL sul web. Ad esempio, questi URL potrebbero rappresentare pagine web che desideri salvare, immagini o persino un elenco di file da un server FTP.
Per questo esempio, stai per scaricare un elenco di pacchetti di archivi (e i file SIG) dal server FTP di GNU parallel.
1. Crea un file chiamato download_items.txt, prendi alcuni link di download dal sito di download ufficiale e aggiungili al file separati da una nuova riga.
Potresti risparmiare del tempo utilizzando la libreria Beautiful Soup di Python per estrarre tutti i link dalla pagina di download.
2. Leggi tutti gli URL dal file download_items.txt e passali a Parallel, che invocherà wget e passerà ogni URL.
Non dimenticare che
{}in un comando parallelo è un segnaposto per la stringa di input!
3. Forse è necessario controllare il numero di thread che GNU Parallel utilizza contemporaneamente. In tal caso, aggiungi il parametro --jobs o -j al comando. Il parametro --jobs limita il numero di thread che possono essere eseguiti contemporaneamente al numero specificato.
Per esempio, per limitare Parallel a scaricare cinque URL alla volta, il comando sarebbe simile a questo:
Il parametro
--jobsnel comando precedente può essere regolato per scaricare qualsiasi numero di file, purché il computer su cui stai eseguendo abbia tante CPU per elaborarli.
4. Per dimostrare l’effetto del parametro --jobs, ora regola il conteggio dei lavori ed esegui il comando time per misurare quanto tempo impiega ogni esecuzione.
Esempio di GNU Parallel #2: Decompressione di pacchetti di archivi
Ora che hai scaricato tutti questi file di archivio dall’esempio precedente, devi ora decomprimerli.
Mentre ti trovi nella stessa directory dei pacchetti di archivio, esegui il seguente comando Parallel. Nota l’uso del carattere jolly (*). Poiché questa directory contiene sia pacchetti di archivio e i file SIG, devi dire a Parallel di processare solo i file .tar.bz2.
Bonus! Se stai usando GNU parallel in modo interattivo (non in uno script), aggiungi il flag --bar per farti mostrare da Parallel una barra di avanzamento mentre il compito è in esecuzione.
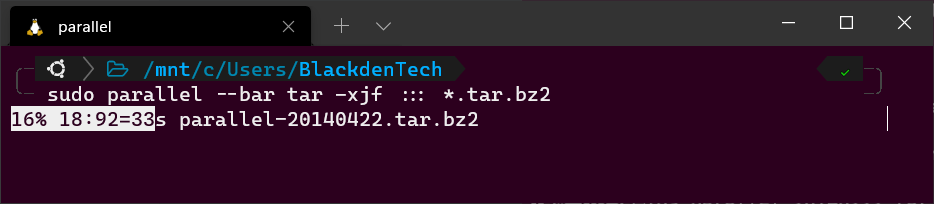
--bar flagEsempio di GNU Parallel #3: Rimozione di file
Se hai seguito gli esempi uno e due, ora dovresti avere molte cartelle nella tua directory di lavoro che occupano spazio. Quindi rimuoviamo tutti quei file in parallelo!
Per rimuovere tutte le cartelle che iniziano con parallel- utilizzando Parallel, elenca tutte le cartelle con ls -d e indirizza ciascun percorso delle cartelle a Parallel, invocando rm -rf su ciascuna cartella, come mostrato di seguito.
Ricorda il flag
--dryrun!
Conclusione
Ora puoi automatizzare compiti con Bash e risparmiare molto tempo. Quello che decidi di fare con quel tempo dipende da te. Che risparmiare tempo significhi lasciare il lavoro un po’ prima o leggere un altro post sul blog ATA, è tempo guadagnato nella tua giornata.
Ora pensa a tutti gli script che esegui nel tuo ambiente. Quali di questi puoi velocizzare con Parallel?
Source:
https://adamtheautomator.com/how-to-speed-up-bash-scripts-with-multithreading-and-gnu-parallel/