













Si vous en avez marre que vos scripts Bash prennent une éternité à s’exécuter, ce tutoriel est fait pour vous. Souvent, vous pouvez exécuter des scripts Bash en parallèle, ce qui peut considérablement accélérer le résultat. Comment ? En utilisant l’utilitaire GNU Parallel, également appelé Parallel, avec quelques exemples pratiques de GNU Parallel !
Parallel exécute des scripts Bash en parallèle via un concept appelé multithreading. Cet utilitaire vous permet d’exécuter différents travaux par CPU au lieu d’un seul, réduisant ainsi le temps d’exécution d’un script.
Dans ce tutoriel, vous allez apprendre à utiliser le multithreading dans les scripts Bash avec une tonne d’excellents exemples de GNU Parallel !
Prérequis
Ce tutoriel sera rempli de démonstrations pratiques. Si vous avez l’intention de suivre, assurez-vous d’avoir les éléments suivants :
- A Linux computer. Any distribution will work. The tutorial uses Ubuntu 20.04 running on Windows Subsystem for Linux (WSL).
- Connecté en tant qu’utilisateur avec des privilèges sudo.
Installation de GNU Parallel
Pour commencer à accélérer les scripts Bash avec le multithreading, vous devez d’abord installer Parallel. Alors, commençons par le télécharger et l’installer.
1. Ouvrez un terminal Bash.
2. Exécutez wget pour télécharger le package Parallel. La commande ci-dessous télécharge la dernière version (parallel-latest) dans le répertoire de travail actuel.
Si vous préférez utiliser une version plus ancienne de GNU Parallel, vous pouvez trouver tous les paquets sur le site de téléchargement officiel.
3. Maintenant, exécutez la commande tar ci-dessous pour désarchiver le paquet que vous venez de télécharger.
Voici, la commande utilise le drapeau x pour extraire l’archive, j pour spécifier qu’elle cible une archive avec une extension .bz2, et f pour accepter un fichier en tant qu’entrée pour la commande tar. sudo tar -xjf parallel-latest.tar.bz2
Vous devriez maintenant avoir un répertoire nommé parallel- avec le mois, le jour et l’année de la dernière version.
4. Naviguez dans le dossier d’archive du paquet avec cd. Dans ce tutoriel, le dossier d’archive du paquet s’appelle parallel-20210422, comme indiqué ci-dessous.
5. Ensuite, construisez et installez le binaire GNU Parallel en exécutant les commandes suivantes :
Maintenant, vérifiez que Parallel est installé correctement en vérifiant la version installée.
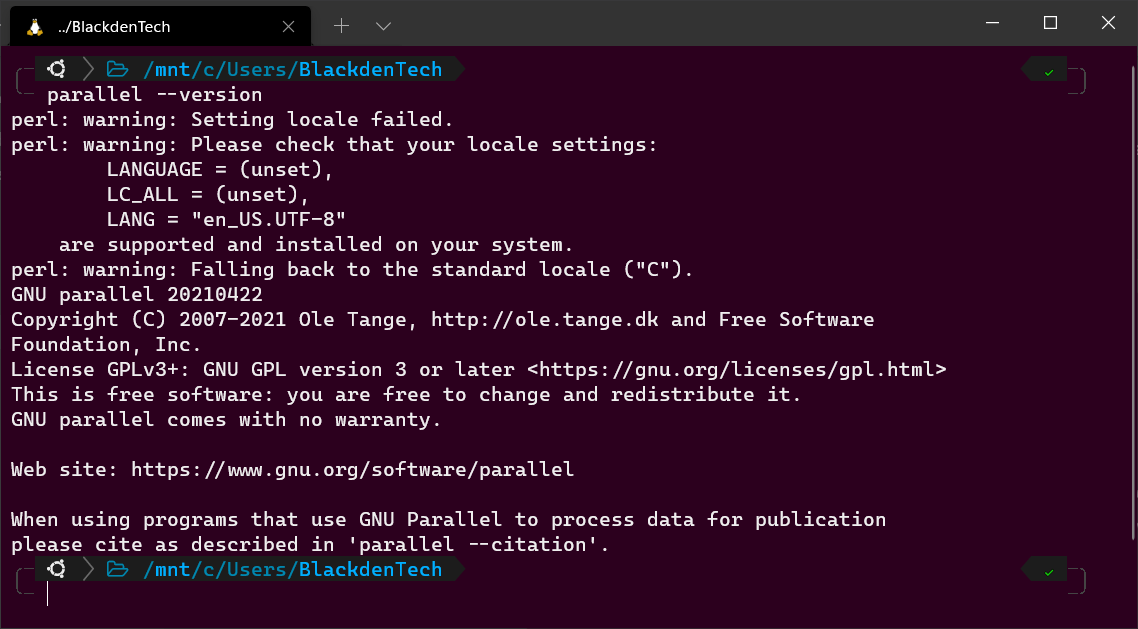
Lorsque vous exécutez Parallel pour la première fois, vous pouvez également voir quelques lignes effrayantes qui affichent du texte comme
perl: avertissement:. Ces messages d’avertissement indiquent que Parallel ne peut pas détecter vos paramètres de langue et de localisation actuels. Mais ne vous inquiétez pas de ces avertissements pour le moment. Vous apprendrez comment résoudre ces avertissements plus tard.
Configuration de GNU Parallel
Maintenant que Parallel est installé, vous pouvez l’utiliser immédiatement ! Mais d’abord, il est important de configurer quelques paramètres mineurs avant de commencer.
Toujours dans votre terminal Bash, acceptez l’autorisation de recherche académique GNU Parallel permission de recherche académique en spécifiant le paramètre de citation suivi de will cite.
Si vous ne souhaitez pas soutenir GNU ou ses mainteneurs, accepter de citer n’est pas obligatoire pour utiliser GNU Parallel.
Changez la langue en définissant les variables d’environnement suivantes en exécutant les lignes de code ci-dessous. Définir les variables d’environnement de langue de cette manière n’est pas une obligation, mais GNU Parallel les vérifie à chaque exécution.
Si les variables d’environnement n’existent pas, Parallel se plaindra d’elles à chaque exécution, comme vous l’avez vu dans la section précédente.
Ce tutoriel suppose que vous êtes un locuteur anglais. D’autres langues sont également prises en charge.
Exécution de commandes Shell ad hoc
Commençons maintenant à utiliser GNU Parallel! Pour commencer, vous apprendrez la syntaxe de base. Une fois à l’aise avec la syntaxe, vous passerez à quelques exemples pratiques de GNU Parallel plus tard.
Pour commencer, examinons un exemple très simple consistant à afficher les nombres de 1 à 5.
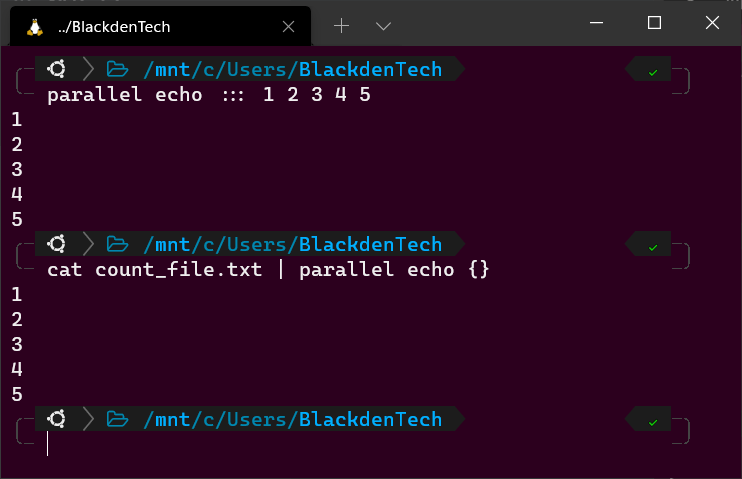
1. Dans votre terminal Bash, exécutez les commandes suivantes. Passionnant, n’est-ce pas? Bash utilise la commande echo pour envoyer les nombres de 1 à 5 au terminal. Si vous mettiez chacune de ces commandes dans un script, Bash les exécuterait séquentiellement, en attendant que la précédente se termine.
Dans cet exemple, vous exécutez cinq commandes qui ne prennent pratiquement pas de temps. Mais imaginez si ces commandes étaient des scripts Bash qui faisaient réellement quelque chose d’utile mais qui prenaient une éternité à s’exécuter?
Maintenant, exécutez chacune de ces commandes en même temps avec Parallel comme ci-dessous. Dans cet exemple, Parallel exécute la commande echo et, indiquée par le :::, transmet cette commande les arguments 1, 2, 3, 4, 5. Les trois deux-points indiquent à Parallel que vous fournissez une entrée via la ligne de commande plutôt que par le pipeline (plus tard).
Dans l’exemple ci-dessous, vous avez passé une seule commande à Parallel sans options. Ici, comme tous les exemples de Parallel, Parallel a démarré un nouveau processus pour chaque commande en utilisant un cœur de CPU différent.
Toutes les commandes Parallel suivent la syntaxe
parallel [Options] <Commande à exécuter en parallèle>.
3. Pour démontrer la réception parallèle d’entrées provenant du pipeline Bash, créez un fichier appelé count_file.txt comme ci-dessous. Chaque nombre représente l’argument que vous passerez à la commande echo.
4. Maintenant, exécutez la commande cat pour lire ce fichier et transmettez la sortie à Parallel, comme indiqué ci-dessous. Dans cet exemple, le {} représente chaque argument (1-5) qui sera transmis à Parallel.
Comparaison entre Bash et GNU Parallel
À ce stade, l’utilisation de Parallel peut sembler être simplement une manière compliquée d’exécuter des commandes Bash. Mais l’avantage réel pour vous est le gain de temps. N’oubliez pas, Bash s’exécutera sur un seul cœur de CPU tandis que GNU Parallel s’exécutera sur plusieurs à la fois.
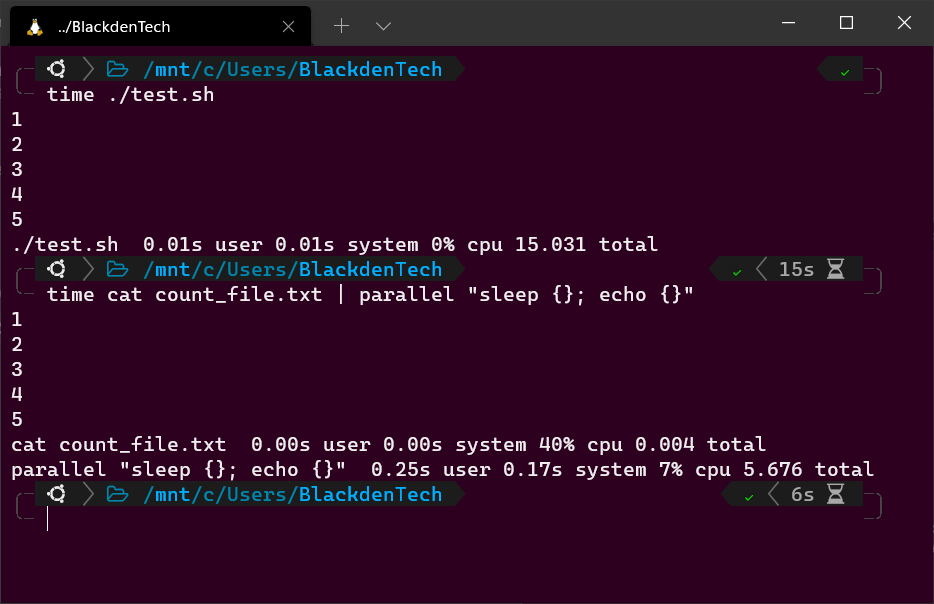
1. Pour démontrer la différence entre les commandes Bash séquentielles et Parallel, créez un script Bash appelé test.sh avec le code suivant. Créez ce script dans le même répertoire où vous avez créé le fichier count_file.txt précédemment.
Le script Bash ci-dessous lit le fichier count_file.txt, dort pendant 1, 2, 3, 4 et 5 secondes, affiche la durée du sommeil sur le terminal et se termine.
2. Maintenant, exécutez le script en utilisant la time commande pour mesurer combien de temps le script prend pour s’exécuter. Cela prendra 15 secondes.
3. Maintenant, utilisez à nouveau la commande time pour effectuer la même tâche mais cette fois utilisez Parallel pour le faire.
La commande ci-dessous effectue la même tâche mais cette fois, au lieu d’attendre que la première boucle se termine avant de commencer la suivante, elle exécutera une sur chaque cœur de processeur, et démarrera autant qu’elle le peut en même temps.
Connaître le Test à Sec!
Il est maintenant temps d’aborder quelques exemples d’utilisation réelle de GNU Parallel. Mais, avant de le faire, vous devez d’abord connaître le drapeau --dryrun. Ce drapeau est utile lorsque vous souhaitez voir ce qui va se passer sans que Parallel le fasse réellement.
Le drapeau --dryrun peut être le dernier contrôle de santé avant d’exécuter une commande qui ne se comporte pas comme prévu. Malheureusement, si vous entrez une commande qui pourrait nuire à votre système, la seule chose que GNU Parallel vous aidera à faire est de lui nuire plus rapidement!
Exemple de GNU Parallel n°1 : Téléchargement de fichiers depuis le Web
Pour cette tâche, vous téléchargerez une liste de fichiers à partir de diverses URL sur le Web. Par exemple, ces URL pourraient représenter des pages Web que vous souhaitez enregistrer, des images, ou même une liste de fichiers à partir d’un serveur FTP.
Pour cet exemple, vous allez télécharger une liste de paquets d’archive (et les fichiers SIG) à partir du serveur FTP de GNU Parallel.
1. Créez un fichier appelé download_items.txt, récupérez quelques liens de téléchargement à partir de le site de téléchargement officiel et ajoutez-les au fichier séparés par une nouvelle ligne.
Vous pourriez gagner du temps en utilisant la bibliothèque Beautiful Soup de Python pour extraire tous les liens de la page de téléchargement.
2. Lisez toutes les URL du fichier download_items.txt et transmettez-les à Parallel, qui invoquera wget et transmettra chaque URL.
N’oubliez pas que
{}dans une commande parallèle est un espace réservé pour la chaîne d’entrée!
3. Peut-être que vous devez contrôler le nombre de threads que GNU Parallel utilise à la fois. Si c’est le cas, ajoutez le paramètre --jobs ou -j à la commande. Le paramètre --jobs limite le nombre de threads pouvant s’exécuter simultanément au nombre que vous spécifiez.
Par exemple, pour limiter Parallel au téléchargement de cinq URL à la fois, la commande ressemblerait à ceci:
Le paramètre
--jobsdans la commande ci-dessus peut être ajusté pour télécharger n’importe quel nombre de fichiers, tant que l’ordinateur sur lequel vous exécutez a autant de CPU pour les traiter.
4. Pour démontrer l’effet du paramètre --jobs, ajustez maintenant le nombre de travaux et exécutez la commande time pour mesurer la durée de chaque exécution.
Exemple de GNU Parallel #2: Décompression de packages d’archive
Maintenant que vous avez téléchargé tous ces fichiers d’archive à partir de l’exemple précédent, vous devez maintenant les décompresser.
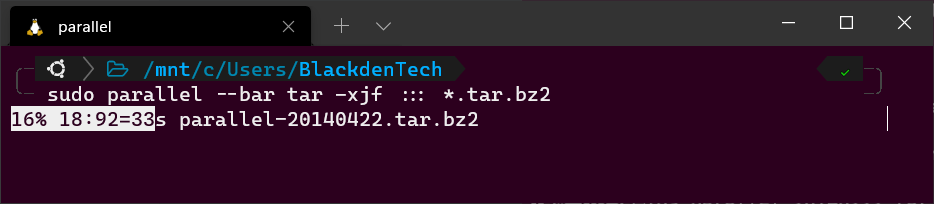
Tout en étant dans le même répertoire que les packages d’archive, exécutez la commande Parallel suivante. Remarquez l’utilisation du joker (*). Puisque ce répertoire contient à la fois des packages d’archive et les fichiers SIG, vous devez indiquer à Parallel de ne traiter que les fichiers .tar.bz2.
Bonus! Si vous utilisez GNU parallel de manière interactive (pas dans un script), ajoutez le drapeau --bar pour que Parallel vous montre une barre de progression pendant que la tâche s’exécute.
--bar flagExemple de GNU Parallel #3: Suppression de fichiers
Si vous avez suivi les exemples un et deux, vous devriez maintenant avoir de nombreux dossiers dans votre répertoire de travail occupant de l’espace. Alors, supprimons tous ces fichiers en parallèle!
Pour supprimer tous les dossiers qui commencent par parallel- en utilisant Parallel, répertoriez tous les dossiers avec ls -d et envoyez chaque chemin de dossier à Parallel en invoquant rm -rf sur chaque dossier, comme illustré ci-dessous.
N’oubliez pas le drapeau
--dryrun!
Conclusion
Maintenant, vous pouvez automatiser des tâches avec Bash et vous économiser beaucoup de temps. Ce que vous choisissez de faire de ce temps vous revient. Que gagner du temps signifie partir un peu plus tôt du travail ou lire un autre article de blog ATA, c’est du temps retrouvé dans votre journée.
Maintenant, pensez à tous les scripts qui s’exécutent longtemps dans votre environnement. Lesquels pouvez-vous accélérer avec Parallel ?
Source:
https://adamtheautomator.com/how-to-speed-up-bash-scripts-with-multithreading-and-gnu-parallel/