













만약 Bash 스크립트가 오래 걸려서 지치셨다면, 이 튜토리얼이 도움이 될 것입니다. 종종, Bash 스크립트를 병렬로 실행하여 결과를 대폭 빠르게 할 수 있습니다. 어떻게 할까요? GNU Parallel 유틸리티, 또는 간단히 Parallel을 사용하면 됩니다. 이 튜토리얼에서는 몇 가지 유용한 GNU Parallel 예제와 함께 Bash 스크립트를 병렬로 실행하는 방법을 배울 것입니다!
Parallel은 멀티 스레딩이라는 개념을 통해 Bash 스크립트를 병렬로 실행합니다. 이 유틸리티를 사용하면 한 번에 여러 작업을 CPU 당 실행할 수 있으므로 스크립트 실행 시간을 단축할 수 있습니다.
이 튜토리얼에서는 다양한 좋은 GNU Parallel 예제와 함께 멀티 스레딩 Bash 스크립트를 배울 것입니다!
사전 준비물
이 튜토리얼은 실습 중심으로 진행될 예정입니다. 따라하기를 원한다면 다음 사항을 확인하세요:
- A Linux computer. Any distribution will work. The tutorial uses Ubuntu 20.04 running on Windows Subsystem for Linux (WSL).
- sudo 권한을 가진 사용자로 로그인되어 있는 것.
GNU Parallel 설치
멀티 스레딩을 사용하여 Bash 스크립트를 빠르게 실행하기 위해 먼저 Parallel을 설치해야 합니다. 그러므로 Parallel을 다운로드하고 설치하기 시작해 보겠습니다.
1. Bash 터미널을 엽니다.
2. 다음 명령어로 Parallel 패키지를 다운로드합니다. 아래 명령어는 최신 버전(parallel-latest)을 현재 작업 디렉토리에 다운로드합니다.
GNU Parallel의 이전 버전을 사용하려면 공식 다운로드 사이트에서 모든 패키지를 찾을 수 있습니다.
3. 이제 방금 다운로드한 패키지를 압축 해제하기 위해 아래의 tar 명령을 실행하세요.
아래의 명령에서 x 플래그는 아카이브를 추출하는 데 사용되고, j는 .bz2 확장자를 가진 아카이브를 대상으로 한다는 것을 지정하며, f는 tar 명령에 파일을 입력으로 사용한다는 것을 의미합니다. sudo tar -xjf parallel-latest.tar.bz2
이제 최신 릴리스의 월, 일 및 년도로 된 parallel-라는 디렉토리가 있어야 합니다.
4. cd 명령을 사용하여 패키지 아카이브 폴더로 이동하세요. 이 튜토리얼에서 패키지 아카이브 폴더는 parallel-20210422로 불리며, 아래와 같이 표시됩니다.
5. 다음으로, 다음 명령을 실행하여 GNU Parallel 이진 파일을 빌드하고 설치하세요.
이제 설치된 Parallel의 버전을 확인하여 올바르게 설치되었는지 확인하세요.
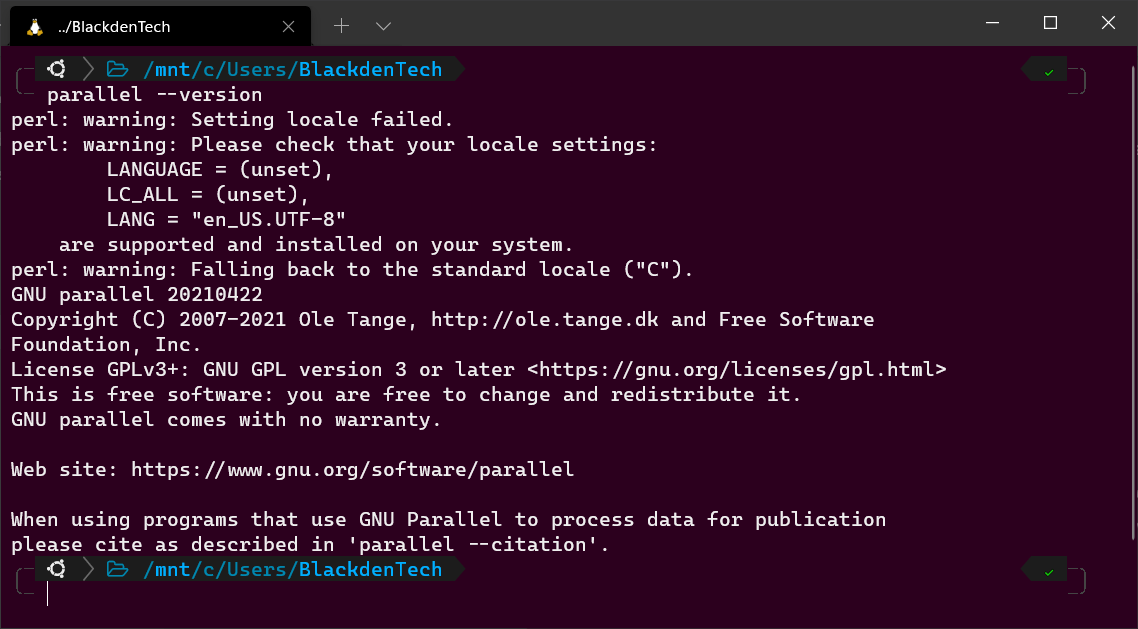
Parallel을 처음 실행할 때는
perl: warning:과 같은 텍스트가 포함된 몇 가지 경고 메시지가 표시될 수도 있습니다. 이러한 경고 메시지는 Parallel이 현재 로캘 및 언어 설정을 감지할 수 없음을 나타냅니다. 하지만 지금은 이러한 경고 메시지에 대해 걱정하지 마세요. 나중에 이러한 경고를 수정하는 방법을 배우게 될 것입니다.
GNU Parallel 구성하기
이제 Parallel이 설치되었으므로 즉시 사용할 수 있습니다! 그러나 시작하기 전에 몇 가지 작은 설정을 구성하는 것이 중요합니다.
여전히 Bash 터미널에서, GNU Parallel 학술 연구 허가에 동의하여 어떤 학술 연구에서도 인용할 것을 Parallel에 알려주기 위해 citation 매개 변수 다음에 will cite를 지정하세요.
GNU나 유지 보수자를 지원하지 않으려면, 인용 동의는 GNU Parallel을 사용하는 데 필요하지 않습니다.
아래 코드 라인을 실행하여 다음 환경 변수를 설정함으로써 로캘을 변경하세요. 이렇게 로캘 및 언어 환경 변수를 설정하는 것은 필수 사항은 아닙니다. 그러나 GNU Parallel은 실행할 때마다 이를 확인합니다.
환경 변수가 존재하지 않으면, Parallel은 이전 섹션에서 보았듯이 계속해서 이에 대해 불평할 것입니다.
본 자습서는 영어 사용자를 가정합니다. 다른 언어도 지원됩니다.
임시 셸 명령 실행하기
이제 GNU Parallel을 사용하여 시작해 보겠습니다! 먼저 기본 구문을 배우게 될 것입니다. 구문에 익숙해지면 나중에 유용한 GNU Parallel 예제로 넘어갈 것입니다.
먼저, 단순히 숫자 1부터 5까지 출력하는 매우 간단한 예제를 살펴보겠습니다.
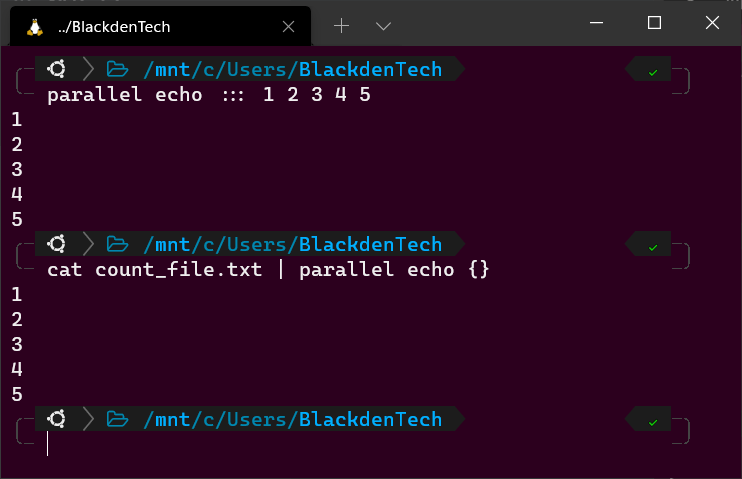
1. Bash 터미널에서 다음 명령을 실행하세요. 흥미로운 거죠? Bash는 echo 명령어를 사용하여 숫자 1부터 5까지 터미널로 보냅니다. 이 명령들을 각각 스크립트에 넣었다면, Bash는 각각의 명령을 순차적으로 실행하며 이전 명령이 끝날 때까지 기다릴 것입니다.
이 예제에서는 거의 시간이 걸리지 않는 다섯 개의 명령을 실행하고 있습니다. 하지만 이 명령들이 유용한 작업을 수행하면서 실행 시간이 길어진다고 상상해 보세요.
이제 아래와 같이 Parallel을 사용하여 각각의 명령을 동시에 실행해 보세요. 이 예제에서 Parallel은 echo 명령을 실행하고 :::로 지정하여 해당 명령에 인수 1, 2, 3, 4, 5를 전달합니다. 세 개의 콜론은 Parallel에게 명령 줄을 통해 입력을 제공한다는 것을 알려줍니다(나중에 더 자세히 설명합니다).
아래 예제에서는 옵션이 없는 단일 명령을 Parallel에게 전달했습니다. 여기서도 다른 모든 Parallel 예제와 마찬가지로 각각의 명령에 대해 새로운 프로세스를 시작하여 다른 CPU 코어를 사용합니다.
모든 Parallel 명령은
parallel [옵션] <멀티스레드할 명령>구문을 따릅니다.
3. 병렬로 Bash 파이프라인에서 입력을 받는 예제로, 아래와 같이 count_file.txt라는 파일을 생성하십시오. 각 숫자는 echo 명령어에 전달할 인수를 나타냅니다.
4. 이제 아래와 같이 cat 명령어를 실행하여 해당 파일을 읽고 출력을 Parallel에 전달하십시오. 이 예제에서 {}는 Parallel에 전달될 각 인수 (1-5)를 나타냅니다.
Bash와 GNU Parallel 비교
지금은 Parallel을 사용하는 것이 Bash 명령어를 실행하는 복잡한 방법으로만 보일 수 있습니다. 그러나 실제로 Parallel을 사용하는 가장 큰 장점은 시간을 절약할 수 있다는 것입니다. 기억하세요, Bash는 하나의 CPU 코어에서만 실행되지만 GNU Parallel은 여러 개의 코어에서 동시에 실행됩니다.
1. 순차적인 Bash 명령어와 Parallel의 차이를 보여주기 위해, 다음 코드를 포함한 Bash 스크립트인 test.sh를 생성하십시오. 이 스크립트는 이전에 count_file.txt를 생성한 디렉토리에 생성하십시오.
아래 Bash 스크립트는 count_file.txt 파일을 읽고, 1, 2, 3, 4, 5 초 동안 대기한 후, 대기 시간을 터미널에 출력하고 종료합니다.
2. 이제 time 명령어를 사용하여 스크립트가 완료되는 데 걸리는 시간을 측정하여 스크립트를 실행하세요. 15초가 소요됩니다.
3. 이제 time 명령어를 사용하여 동일한 작업을 수행하지만 이번에는 Parallel을 사용하세요.
아래 명령은 동일한 작업을 수행하지만 첫 번째 루프가 완료될 때까지 기다리지 않고 각 CPU 코어에서 하나씩 실행하며 가능한 한 동시에 시작합니다.
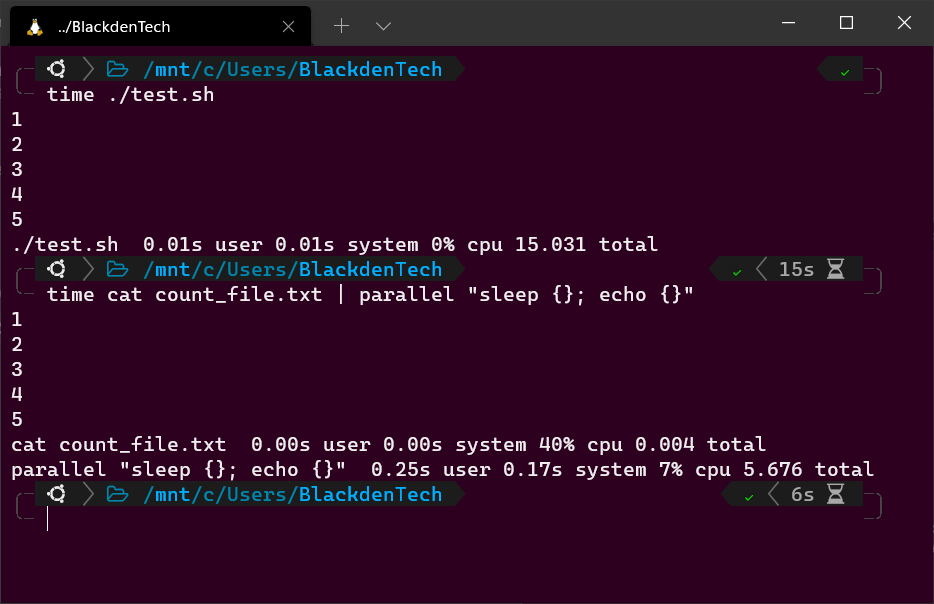
실행 시험을 알아두세요!
이제 몇 가지 더 실제 예제를 살펴보겠습니다. 그러나 실제로 실행하지 않고 무엇이 발생할지 보려면 먼저 --dryrun 플래그에 대해 알아야 합니다. 이 플래그는 Parallel이 실제로 작업을 수행하지 않고 무엇이 발생할지 볼 때 유용합니다.
--dryrun 플래그는 원하는 대로 동작하지 않는 명령을 실행하기 전에 최종적인 안전성 확인을 할 수 있습니다. 불행히도 시스템에 해를 입힐 수 있는 명령을 입력하면 GNU Parallel은 단순히 더 빠르게 시스템에 해를 입히도록 도와줄 뿐입니다!
GNU Parallel 예제 #1: 웹에서 파일 다운로드
이 작업에서는 웹의 여러 URL에서 파일 목록을 다운로드합니다. 예를 들어, 이러한 URL은 저장하려는 웹 페이지, 이미지 또는 심지어 FTP 서버의 파일 목록일 수 있습니다.
이 예제에서는 GNU parallel의 FTP 서버에서 아카이브 패키지 목록(및 SIG 파일)을 다운로드합니다.
1. download_items.txt라는 파일을 만들고 공식 다운로드 사이트에서 몇 가지 다운로드 링크를 가져와 새 줄로 구분하여 파일에 추가합니다.
Python의 Beautiful Soup 라이브러리를 사용하여 다운로드 페이지에서 모든 링크를 스크래핑하여 시간을 절약할 수 있습니다.
2. download_items.txt 파일에서 모든 URL을 읽고 Parallel에 전달하여 wget을 호출하고 각 URL을 전달합니다.
병렬 명령어에서
{}는 입력 문자열의 자리 표시자임을 잊지 마세요!
3. 아마도 GNU Parallel이 동시에 사용하는 스레드 수를 제어해야 할 수도 있습니다. 그렇다면 명령에 --jobs 또는 -j 매개변수를 추가하십시오. --jobs 매개변수는 동시에 실행되는 스레드 수를 지정한 수로 제한합니다.
예를 들어, Parallel을 한 번에 다섯 개의 URL을 다운로드하는 것으로 제한하려면 다음과 같이 명령을 작성하면 됩니다:
위 명령의
--jobs매개변수는 컴퓨터에 있는 CPU의 수에 따라 파일을 다운로드하는 데 필요한 모든 파일 수로 조정할 수 있습니다.
4. --jobs 매개변수의 효과를 보여주기 위해 작업 수를 조정하고 각 실행에 대해 실행 시간을 측정하는 time 명령을 실행하십시오.
GNU Parallel 예제 #2: 아카이브 패키지 압축 풀기
이전 예제에서 다운로드한 모든 아카이브 파일을 이제 압축 해제해야 합니다.
아카이브 패키지와 동일한 디렉토리에서 다음 Parallel 명령을 실행하십시오. 와일드카드(*)의 사용에 주목하십시오. 이 디렉토리에는 아카이브 패키지와 SIG 파일이 모두 있으므로 Parallel에게 .tar.bz2 파일만 처리하도록 지시해야 합니다.
보너스! GNU parallel을 대화식으로 사용하는 경우(스크립트가 아닌 경우), 작업이 실행되는 동안 Parallel이 진행률 표시 막대를 보여주도록 --bar 플래그를 추가하십시오.
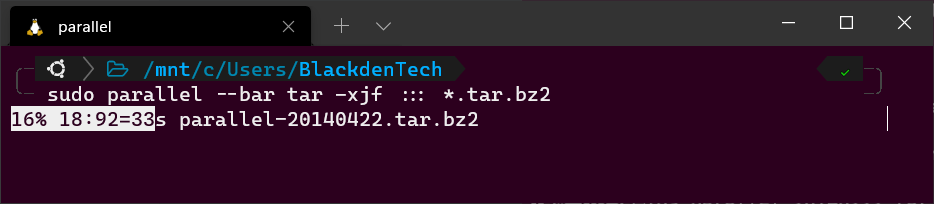
--bar flagGNU Parallel 예제 #3: 파일 삭제
1번과 2번 예제를 따라왔다면 작업 디렉토리에 많은 폴더가 있어 공간을 차지하고 있을 것입니다. 그러니 이제 모든 파일을 병렬로 제거해 보겠습니다!
Parallel를 사용하여 parallel-로 시작하는 모든 폴더를 제거하려면 ls -d로 모든 폴더를 나열하고 각 폴더 경로를 Parallel에 파이프로 전달하여 아래와 같이 각 폴더에 rm -rf를 실행하십시오.
--dryrun플래그를 기억하세요!
결론
이제 Bash로 작업을 자동화하고 많은 시간을 절약할 수 있습니다. 그 시간을 어떻게 활용할지는 여러분에게 달려 있습니다. 시간을 절약한다는 것은 일찍 퇴근하거나 다른 ATA 블로그 포스트를 읽는 것과 같은 여러분의 시간을 되찾는 것입니다.
이제 환경에서 오래 실행되는 스크립트를 생각해보십시오. 어떤 스크립트를 Parallel로 속도를 향상시킬 수 있을까요?
Source:
https://adamtheautomator.com/how-to-speed-up-bash-scripts-with-multithreading-and-gnu-parallel/