













В настоящем данных-ориентированном мире бизнесы должны адаптироваться к быстрым изменениям в том, как происходит управление, анализ и использование данных. Традиционные централизованные системы и монолитные архитектуры, хотя и были достаточными с historical point of view, более недостаточны для удовлетворения растущих требований организаций, которые нужны быстрый доступ в реальном времени к взглядам на данные. Революционная рамка в этом пространстве – это архитектура событий-ориентированного данных-сет, и lorsque она сочетается с услугами AWS, она становится крепкой решением для решения сложных задач управления данными.
Данные-дилема
Многие организации сталкиваются с значительными проблемами, когда они используют устаревшие архитектуры данных. Эти проблемы включают:
Централизованная, Монолитная иDomain Agnostic Data Lake
A централизованная Data Lake – это единственное хранение всех ваших данных, что simplify management and access but may cause performance issues if not scaled properly. A монолитная data lake объединяет все процессы обработки данных в одной интегрированной системе, что simplifies setup but can be hard to scale and maintain. A domain-agnostic data lake is designed to store data from any industry or source, offering flexibility and broad applicability but may be complex to manage and less optimized for specific uses.
Pressure Points Failures Traditional Architecture
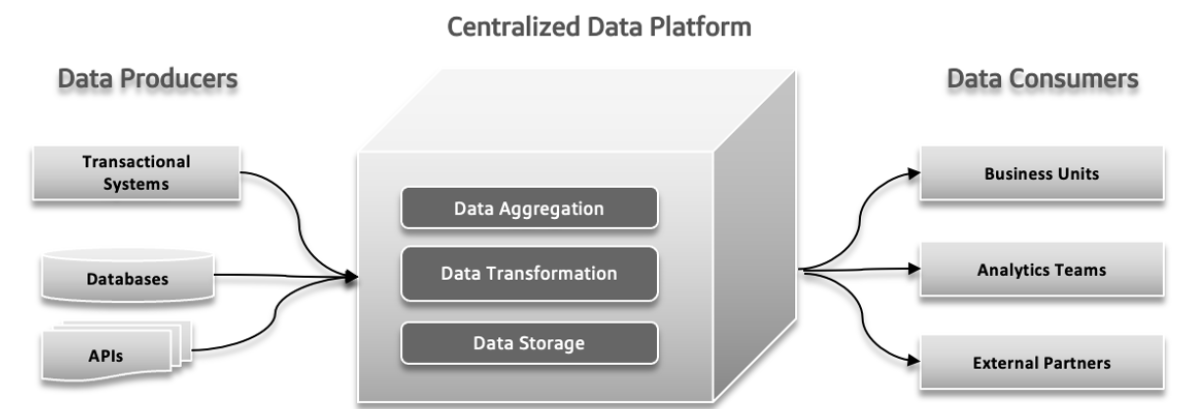
В традиционных системах данных могут возникнуть несколько проблем. Производители данных могут отправить большое количество данных или данные с ошибками, что может привести к проблемам вниз по цепочке. Как увеличивается сложность данных и вклады различных источников в систему, централизованная платформа данных может испытывать трудности с обработкой увеличивающегося нагрузки, что может привести к сбоям и снижению производительности. Увеличивающийся спрос на быстрое экспериментирование может опрокидывать систему, что затрудняет быстрое адаптирование и тестирование новых идей. Время реакции данных может стать проблемой, вызывая задержки при доступе к и использовании данных, что сказывается на принятии решений и общей эффективности.
Различие между оперативной и аналитической средой данных
В структуре программного обеспечения проблемы, такие как изолированная принадлежность, неясное использование данных, тесно связанные каналы данных и внутренние ограничения, могут вызывать значительные проблемы. Изолированная принадлежность происходит, когда различные команды работают в изоляции, что приводит к проблемам координации и неэффективности. Отсутствие ясного понимания того, как данные должны быть использованы или обменены, может привести к дублированию усилий и несогласованности результатов. Связанные каналы данных, где компоненты слишком зависят друг от друга, затрудняют адаптацию или масштабирование системы, что вызывает задержки. Наконец, внутренние ограничения системы могут замедлять развертывание новых функций и обновлений, препятствуя общему прогрессу. Разрешение этих напряженных точек crucial для более эффективного и реактивного процесса разработки.
Проблемы с большими данными
Онлайн аналитическое процессирование (OLAP) системы организуют данные так, что это упрощает для аналитиков исследование различных аспектов данных. Чтобы ответить на запросы, эти системы должны трансформировать операционные данные в формат, подходящий для анализа, и обрабатывать большие объемы данных. Традиционные дедлайн-системы используют процессы ETL (Extract, Transform, Load) для управления этим. Биг-данные технологии, такие как Apache Hadoop, улучшили дедлайн-системы, решая вопросы масштабирования и являясь открытым исходным кодом, что позволяло любой компании использовать его, при условии управления инфраструктурой. Hadoop ввел новый подход, позволяя неструктурированным или полуструктурированным данным, а не навязывая строгую схему сразу. Эта гибкость, когда данные могли быть записаны без предварительно определенной схемы и структурироваться позже при выполнении запросов, сделала его легче для инженеров данных обрабатывать и интегрировать данные. Внедрение Hadoop часто означало создание отдельной команды данных: инженеры данных обслуживали экстракцию данных, ученые-данные управляли очисткой и реструктурированием, а аналитики выполняли аналитику. Этот набор иногда приводил к проблемам из-за ограниченного общения между командой данных и разработчиками приложений, часто для предотвращения влияния на производственные системы.
Проблема 1: проблемы с границами данной модели.
Данные, используемые для анализа, тесно связаны с исходной структурой, что может стать проблемным в случае сложных, часто обновляемых моделей. Изменения в модели данных влияют на всех пользователей, делая их уязвимыми для этих изменений, особенно когда модель включает множество таблиц.
Проблема 2: плохие данные, расходы от игнорирования проблемы
Плохие данные обычно незамечены, пока они не вызывают проблем в схеме, приводя к таким проблемам, как неверные типы данных. Since validation is often delayed until the end of the process, bad data can spread through pipelines, resulting in expensive fixes and inconsistent solutions. Bad data can lead to significant business losses, such as billing errors costing millions. Research indicates that bad data costs businesses trillions annually, wasting substantial time for knowledge workers and data scientists.
Проблема 3: отсутствие единого владения
Разработчики приложений, являющиеся экспертами в исходной модели данных, обычно не передают эту информацию другим командам. Их обязанности обычно ограничены пределами их приложений и баз данных. Data engineers, who manage data extraction and movement, often work reactively and have limited control over data sources. Data analysts, far removed from developers, face challenges with the data they receive, leading to coordination issues and the need for separate solutions.
Проблема 4: настраиваемые соединения с данными
В крупных организациях различные команды могут использовать одные и те же данные, но создавать свои собственные процессы для управления ими. Это приводит к созданию множества копий данных, каждая из которых управляется независимо, исходя из-за чего возникает переплетение. Трудно контролировать задачи ETL и обеспечивать качество данных, что приводит к неточностям вследствие таких факторов, как проблемы с синхронизацией и менее безопасные источники данных. Этот рассеянный подход тратит время, деньги и пропускает возможности.
Данные в решениях Data Mesh решают эти проблемы, требуя тщательно оформленных схем, документации и стандартизированного доступа, что помогает снизить риски неверных данных и улучшает точность и эффективность данных.
Данные в решениях Data Mesh: Современный подход
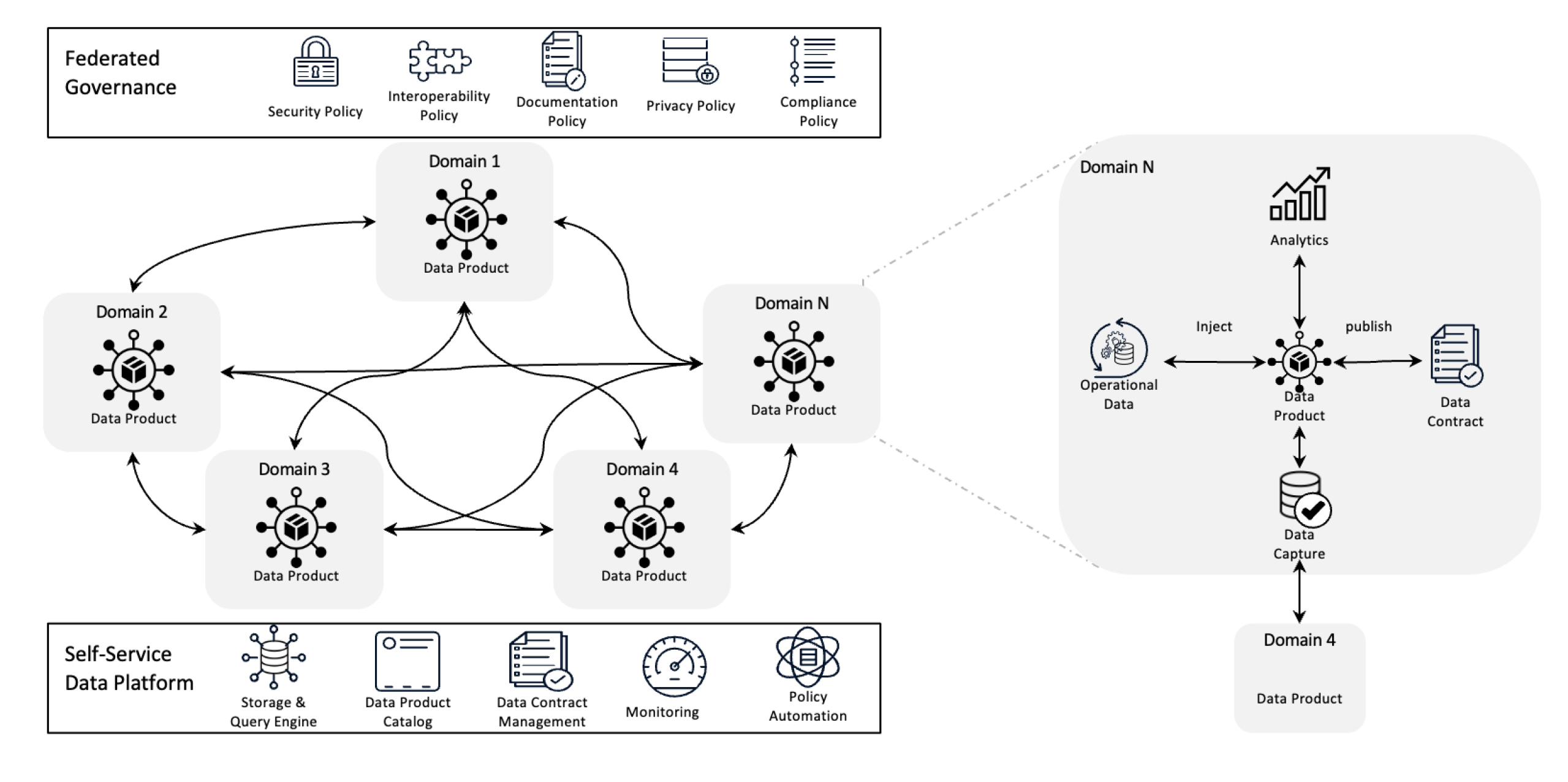
Архитектура Data Mesh
Архитектура Data Mesh пересматривает управление данными, децентрализуя владение и требуя, чтобы данные рассматривались как продукт, который поддерживается самосервисной инфраструктурой. Этот сдвиг дает командам полный контроль над их данными, а федеративное управление обеспечивает качество, соблюдение норм и масштабность по всей организации.
В более простой форме это архитектурная рама, которая разрабатывается для решения сложных проблем с данными, используя децентрализованное владение и распределенные методы. Она используется для интеграции данных из различных коммерческих областей для всестороннего анализа данных. Она также основана на крепких политиках разделения данных и управления ими.
Цели Data Mesh:
Data mesh помогает различным организациям получать ценные заключения от данных масштабируемо; коротко говоря, это обеспечение различных данных, изменяющегося ландшафта данных, увеличивающегося количества источников данных и пользователей, различных требующихся трансформаций данных и необходимости быстро адаптироваться к изменениям.
Data mesh решает все вышеупомянутые проблемы, децентрализуя контроль, так что команды могут управлять собственными данными, не разделяя их с отдельными отраслями. Этот подход улучшает масштабность, распределяя обработку и хранение данных, что помогает избегать замедлений в одной центральной системе. Он ускоряет получение заключений, позволяя командам работать непосредственно со своими собственными данными, уменьшая задержки, вызванные ожиданием центральной команды. Каждая команда берет на себя ответственность за свои собственные данные, что повышает качество и последовательность. Используя удобные для понимания данные продукты и самосервисные инструменты, data mesh обеспечивает, чтобы все команды могли быстро получить и управлять собственными данными, что ведет к более быстрой, эффективной работе и лучшему соответствию бизнес-needs.
Основные принципы Data Mesh
- Децентрализованное владение данными: Команды владеют и управляют своими данными продуктами, делая их ответственными за их качество и доступность.
- Данные как продукт: Данные третируются как продукт с стандартизированным доступом, версионированием и определениями схем, обеспечивая последовательность и удобство использования по всему департаменту.
- Федеративное управление: Политики устанавливаются для поддержания целостности данных, безопасности и соблюдения合规, позволяя децентрализованному владению.
- Само обслуживаемая инфраструктура:团队合作者可以访问可扩展的基础设施,该基础设施支持数据的摄取、处理和查询,而不会出现瓶颈或依赖集中的数据团队。
Как мероприятия помогают Data Mesh?
Мероприятия помогают data mesh, позволяя различным частям системы share и обновлять данные в реальном времени. Когда что-то меняется в одной области, мероприятие уведомляет другие области о этом, так что коллектив остается на свежем заказе без необходимости наличия прямых связей. Это делает систему более гибкой и масштабируемой, поскольку она может обрабатывать большие объемы данных и легко адаптироваться к изменениям. Мероприятия также simplify tracking использования и управления данными и позволяют каждой команде работать со своими данными без зависимости от других.
Конечно, посмотрим на архитектуру data mesh с использованием мероприятий.
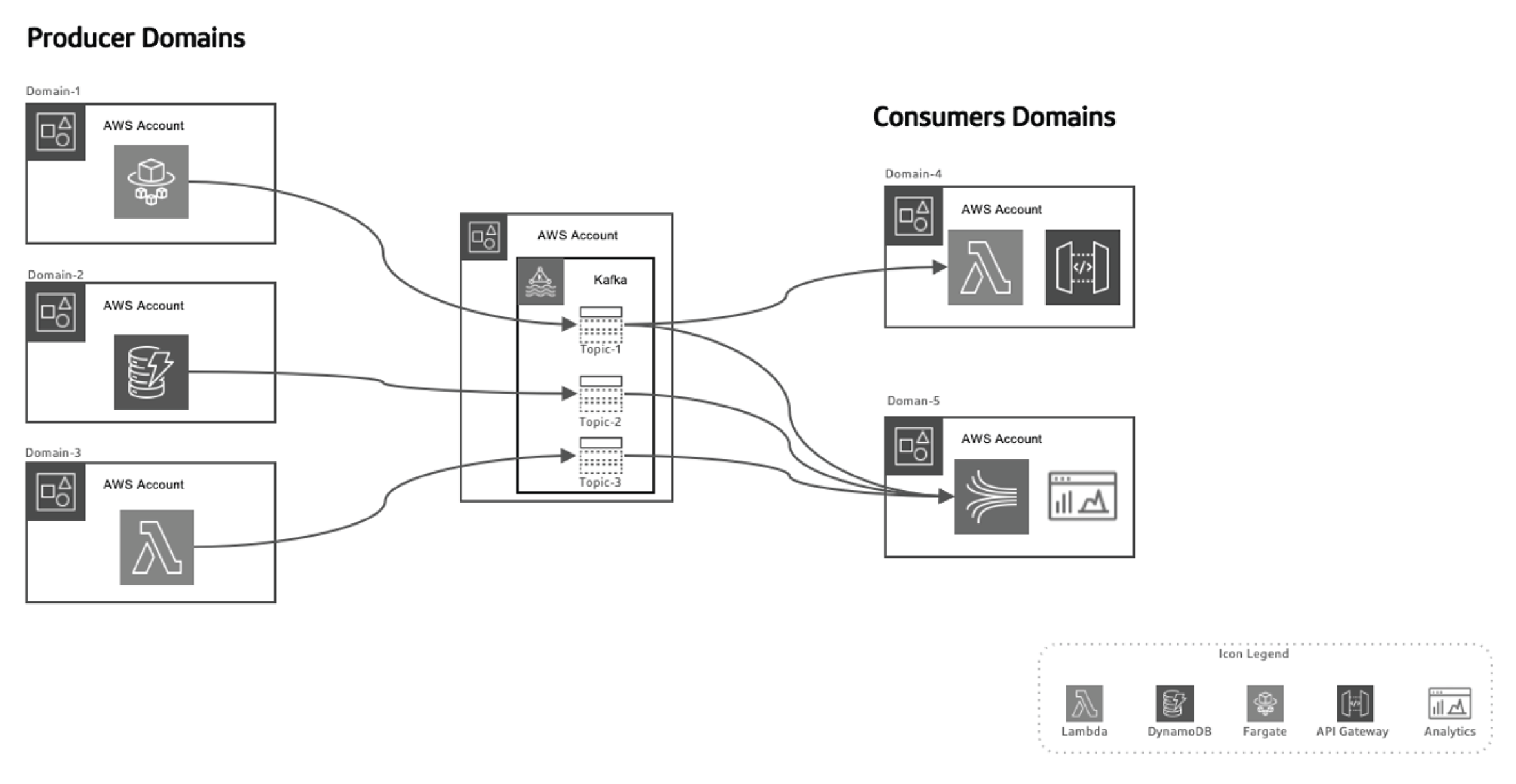
Этот приемлемый подход к использованию мероприятий разделяет производителей данных от потребителей, делая систему более масштабируемой, поскольку домены развиваются по времени, не требуя крупных изменений в архитектуре. Producers ответственны за генерацию мероприятий, которые затем посылаются в систему данных в перемещении. Streaming-платформа обеспечивает надежное доставление этих событий. When a producer microservice or datastore publishes a new event, it gets stored in a specific topic. This triggers listeners on the consumer side, like Lambda functions or Kinesis, to process the event and use it as needed.
Использование AWS для архитектуры data mesh с использованием мероприятий
AWS предлагает набор служб, которые идеально дополняют модель трафика данных, driven by events, позволяя организациям масштабировать их инфраструктуру данных, обеспечивать реальное время для доставки данных и поддерживать высокий уровень управления и безопасности.
Вот как различные службы AWS соответствуют этому архитектурному столу:
AWS Kinesis для реального времени потока событий
В модели данных, driven by events, реальный поток событий является ключевым элементом. AWS Kinesis обеспечивает возможность накопления, обработки и анализа реального времени потока данных масштаба.
Kinesis предлагает несколько компонентов:
- Kinesis Data Streams: вводителем реального времени событий и обрабатывает их в paralel с несколькими потребителями.
- Kinesis Data Firehose: доставляет потоки событий непосредственно в S3, Redshift или Elastic search для дальнейшего обработки и анализа.
- Kinesis Data Analytics: обрабатывает данные в реальном времени для извлечения洞见 на ходу, позволяя немедленные циклы обратной связи в каналах обработки данных.
AWS Lambda для обработки событий
AWS Lambda является основой безсерверной обработки событий в архитектуре данных, driven by events. Благодаря своей способности автоматически масштабироваться и обрабатывать поступающий поток данных без необходимости управления серверами,
Lambda является идеальным выбором для:
- Обработки Kinesis потоков в реальном времени
- Вызывает запросы API Gateway в ответ на специфические события
- Interaktsii с DynamoDB, S3 или другими службами AWS для сохранения, обработки или анализа данных
AWS SNS и SQS для распределения событий
AWS Простой Сервис уведомлений (SNS) выполняет основную роль системы распространения событий, отправляя реально-тайм уведомления в распределенных системах. AWS Простой Сервис очереди (SQS) обеспечивает надежное доставление сообщений между независимыми сервисами даже в случае частичных сбоев в системе. Эти сервисы позволяют независимым микросервисам взаимодействовать без прямых зависимостей, обеспечивая, чтобы система оставалась масштабируемой и отказостойкой.
AWS DynamoDB для управления реально-тайм данными
В децентрализованных архитектурах DynamoDB обеспечивает масштабируемую, низколатency NoSQL-базу данных, которая может хранить данные событий в реальном времени, что делает ее идеальной для хранения результатов каналов обработки данных. Он поддерживает модель Outbox, где события, генерируемые приложением, сохраняются
в DynamoDB и потребляются стриминговым сервисом (например, Kinesis или Kafka).
AWS Glue для федеративного каталога данных и ETL
AWS Glue предлагает полностью управляемую службу каталога данных и ETL, необходимую для федеративного управления данными в data mesh. Glue помогает каталогизировать, подготавливать и трансформировать данные в распределенных областях, обеспечивая обнаруживаемость, управление и интеграцию по всей организации.
AWS Lake Formation и S3 для Data Lakes
Archитектура данных mesh уходит от централизованных data lakes, при этом S3 и AWS Lake Formation играют ключевую роль в хранении, безопасности и каталогизации данных, которые перетекают между различными доменами, обеспечивая долгосрочное хранение, управление и соответствие регламенту.
В действии Event-Driven Data Mesh с AWS и Python
Производитель событий: AWS Kinesis + Python
В этом примере мы используем AWS Kinesis для передачи потока событий при создании нового клиента:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
Процесс обработки событий: AWS Lambda + Python
Эта функция Lambda потребляет события Kinesis и обрабатывает их в реальном времени.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
Заключение
При использовании AWS-сервисов, таких как Kinesis, Lambda, DynamoDB и Glue, организации могут полностью реализовать потенциал архитектуры event-driven data mesh. Эта архитектура обеспечивает гибкость, масштабность и реально-временные заключения, ensuring that organizations remain competitive in today’s rapidly evolving data landscape. Адаптация архитектуры event-driven data mesh не просто техническое улучшение, это стратегическое требование для компаний, которые хотят процветать в эпохе big data и распределенных систем.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws