













En el mundo actual, basado en datos, las empresas deben adaptarse a los rápidos cambios en cómo se gestionan, analizan y utilizan los datos. Los sistemas centralizados tradicionales y las arquitecturas monolíticas, aunque históricamente suficientes, ya no son adecuados para satisfacer las demandas crecientes de organizaciones que necesitan un acceso rápido y en tiempo real a las insights de los datos. Un framework revolucionario en este espacio es la arquitectura de data mesh evento-driven, y cuando se combina con los servicios de AWS, se convierte en una solución robusta para abordar los desafíos complejos de gestión de datos.
El Dilema de los Datos
Muchas organizaciones enfrentan desafíos significativos al recurrir a arquitecturas de datos obsoletas. Estos desafíos incluyen:
Lago de Datos Centralizado, Monolítico y Agnóstico de dominio
Un lago de datos centralizado es un solo lugar de almacenamiento para todos sus datos, lo que facilita la gestión y el acceso pero puede causar problemas de rendimiento si no se escaló correctamente. Un lago de datos monolítico combina todos los procesos de manejo de datos en un solo sistema integrado, lo que simplifica la configuración pero puede ser difícil de escalar y mantener. Un lago de datos agnóstico de dominio está diseñado para almacenar datos de cualquier industria o fuente, ofreciendo flexibilidad y aplicabilidad amplia, pero puede ser complicado de gestionar y menos optimizado para usos específicos.
Puntos de falla en la presión de la arquitectura tradicional
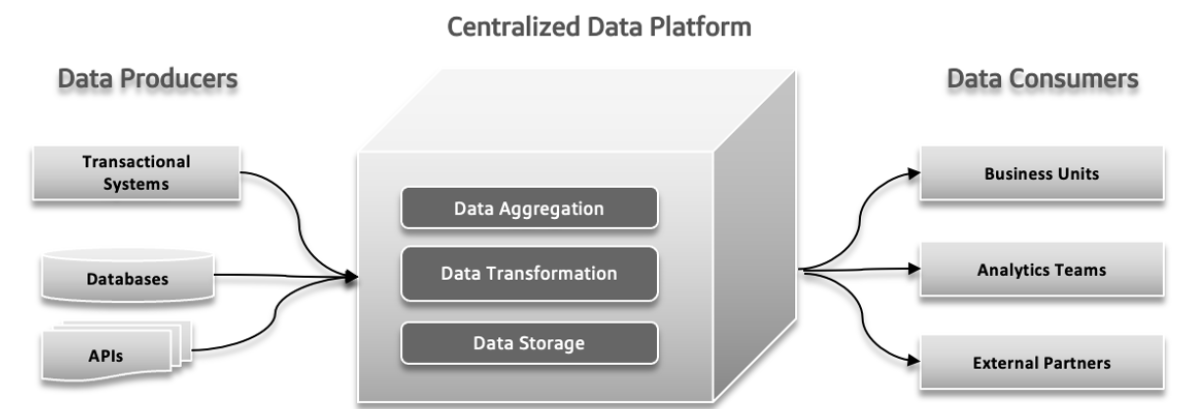
En los sistemas de datos tradicionales, pueden ocurrir varios problemas. Los productores de datos pueden enviar grandes volúmenes de datos o datos con errores, creando problemas en las etapas posteriores. Con el aumento de la complejidad de los datos y la contribución de más fuentes diversas al sistema, la plataforma de datos centralizada puede luchar para manejar la carga creciente, lo que puede llevar a fallos y un rendimiento lento. La demanda incrementada de experimentación rápida puede sobrecargar el sistema, haciendo difícil adaptarse y probar nuevas ideas rápidamente. Los tiempos de respuesta de los datos pueden convertirse en un reto, causando retrasos en el acceso y uso de los datos, lo que afecta la toma de decisiones y la eficiencia general.
Divergencia entre los paisajes de datos operacionales y analíticos
En la arquitectura de software, problemas como la propiedad en silos, la utilización de datos poco clara, los pipeline de datos fuertemente acoplados y las limitaciones inherentes pueden causar problemas significativos. La propiedad en silos ocurre cuando diferentes equipos trabajan en aislamiento, llevando a problemas de coordinación e ineficiencias. La falta de entendimiento claro de cómo se debe utilizar o compartir los datos puede resultar en esfuerzos duplicados y resultados inconsistentes. Los pipeline de datos acoplados, donde los componentes dependen demasiado unos de otros, dificultan la adaptación o escalada del sistema, llevando a retrasos. Finalmente, las limitaciones inherentes del sistema pueden desacelerar la entrega de nuevas características y actualizaciones, impidiendo el progreso general. Abordar estos puntos de presión es crucial para un proceso de desarrollo más eficiente y responsive.
Retos con los Big Data
Los sistemas de Procesamiento Analítico en Línea (OLAP) organizan los datos de manera que sea fácil para los analistas explorar diferentes aspectos de los mismos. Para responder a consultas, estos sistemas deben transformar los datos operacionales en un formato adecuado para el análisis y manejar grandes volúmenes de datos. Los data warehouses tradicionales utilizan procesos de ETL (Extracción, Transformación, Carga) para gestionar esto. Las tecnologías de big data, como Apache Hadoop, mejoraron los data warehouses resolviendo problemas de escala y siendo de código abierto, lo que permitió que cualquier empresa los utilizara si podía manejar la infraestructura. Hadoop presentó una nueva aproximación al permitir datos no estructurados o semi-estructurados, en lugar de imponer un esquema estricto de antemano. Esta flexibilidad, donde los datos podían ser escritos sin un esquema predefinido y estructurados más tarde durante las consultas, hizo más fácil para los ingenieros de datos manejar e integrar datos. La adopción de Hadoop a menudo significó formar un equipo de datos separado: los ingenieros de datos manejaban la extracción de datos, los científicos de datos administraban la limpieza y la reestructuración, y los analistas de datos realizaban análisis. Este arreglo a veces llevó a problemas debido a la limitada comunicación entre el equipo de datos y los desarrolladores de aplicaciones, a menudo para evitar impactar los sistemas de producción.
Problema 1: Incidencias con los Límites del Modelo de Datos
Los datos utilizados para análisis están estrechamente relacionados con su estructura original, lo que puede ser problemático con modelos complejos y actualizados frecuentemente. Los cambios en el modelo de datos afectan a todos los usuarios, haciéndolos vulnerables a estos cambios, especialmente cuando el modelo implica muchas tablas.
Problema 2: Datos Malos, Los Costos de Ignorar el Problema
Los datos malos a menudo pasan desapercibidos hasta que causan problemas en un esquema, provocando problemas como tipos de datos incorrectos. Dado que la validación a menudo se retrasa hasta el final del proceso, los datos malos pueden propagarse a través de las tuberías, resultando en reparaciones caras y soluciones inconsistentes. Los datos malos pueden llevar a pérdidas significativas para las empresas, como errores de facturación que cuestan millones. La investigación indica que los datos malos cuestan a las empresas billones anualmente, desperdiciando considerable tiempo para trabajadores de conocimiento y científicos de datos.
Problema 3: Falta de Propietario Único
Los desarrolladores de aplicaciones, que son expertos en el modelo de datos de origen, normalmente no comunican esta información a otras equipos. Sus responsabilidades a menudo terminan en sus límites de aplicación y base de datos. Los ingenieros de datos, que manejan la extracción y el movimiento de datos, a menudo trabajan de forma reactiva y tienen un control limitado sobre las fuentes de datos. Los analistas de datos, alejados de los desarrolladores, enfrentan dificultades con los datos que reciben, provocando problemas de coordinación y la necesidad de soluciones separadas.
Problema 4: Conexiones de Datos Personalizadas
En organizaciones grandes, varios equipos pueden utilizar los mismos datos pero crear sus propios procesos para gestionarlos. Esto resulta en varias copias de los datos, cada una gestionada de manera independiente, creando un desordenado lío. Resulta difícil rastrear los trabajos ETL y asegurar la calidad de los datos, lo que conduce a imprecisiones debido a factores como problemas de sincronización y fuentes de datos menos seguras. Este enfoque disperso desperdicia tiempo, dinero y oportunidades.
Data mesh aborda estos problemas tratando los datos como un producto con esquemas claros, documentación y acceso estandarizado, reduciendo el riesgo de datos malos y mejorando la precisión y la eficiencia de los datos.
Data Mesh: Un Enfoque Moderno
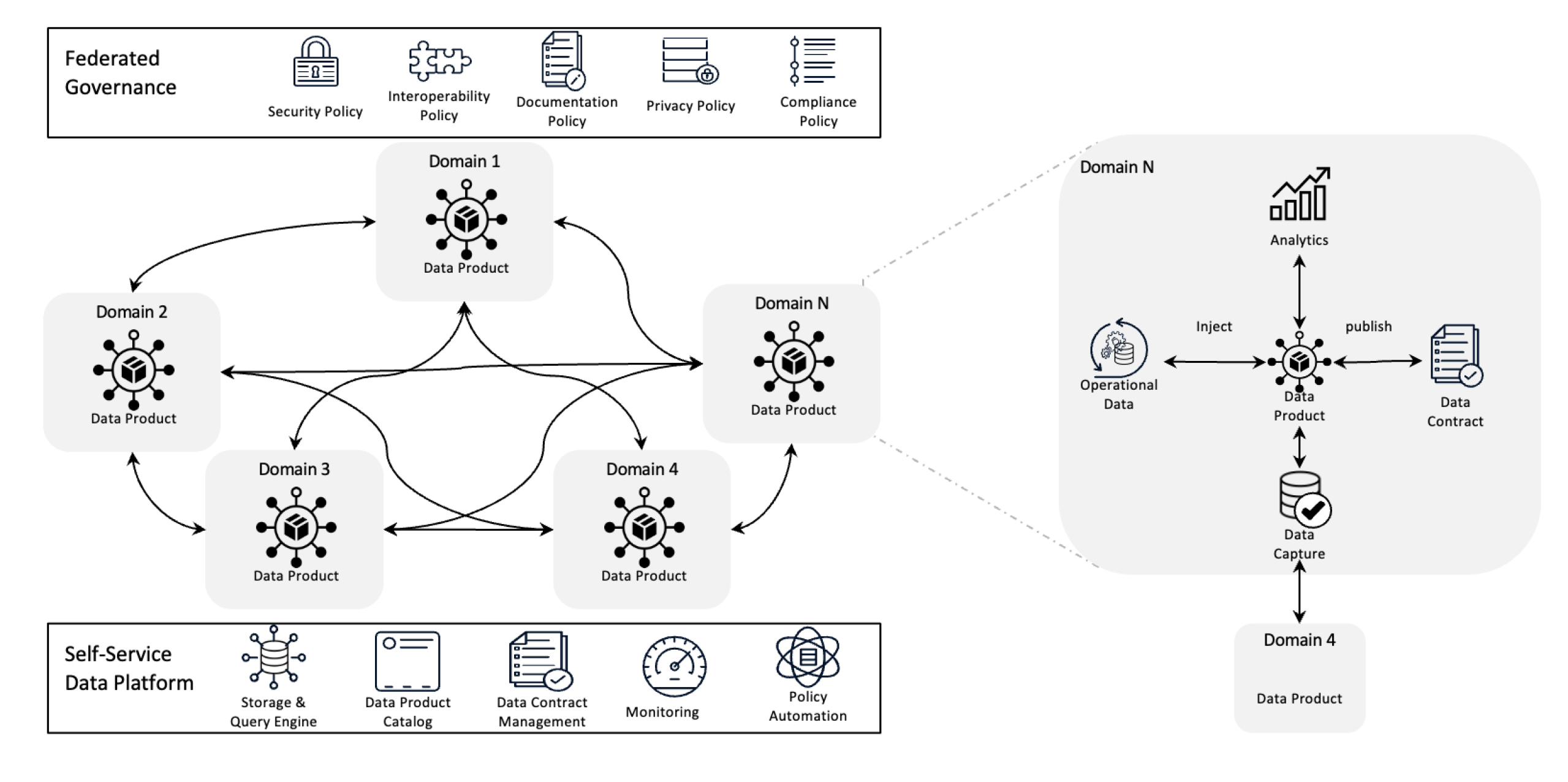
Arquitectura de Data Mesh
Data mesh redefine la gestión de datos mediante la descentralización de la propiedad y el tratamiento de los datos como un producto, apoyado por una infraestructura de auto-servicio. Este cambio empodera a los equipos para tomar el control completo de sus datos mientras que la gobernanza federada garantiza calidad, cumplimiento y escalabilidad a través de la organización.
En términos más simples, es un marco arquitectónico diseñado para resolver los desafíos de datos complejos mediante la utilización de propiedad descentralizada y métodos distribuidos. Se utiliza para integrar datos de diferentes dominios de negocios para análisis de datos comprensivos. También se basa en políticas fuertes de intercambio y gobernanza de datos.
Objetivos de Data Mesh
La data mesh ayuda a varias organizaciones obtener insights valiosos en escala en los datos; en resumen, manejar un escenario de datos en constante cambio, el aumento del número de fuentes de datos y usuarios, la variedad de transformaciones de datos necesarias y la necesidad de adaptarse rápidamente a los cambios.
La data mesh resuelve todos los problemas mencionados anteriormente mediante la descentralización del control, de manera que los equipos puedan gestionar sus propios datos sin que estén aislados en departamentos separados. Este enfoque mejora la escalabilidad distribuyendo la procesación y almacenamiento de datos, lo que ayuda a evitar los lentes en un solo sistema central. Acelera las insights permitiendo que los equipos trabajen directamente con sus propios datos, reduciendo los retrasos causados por esperar a un equipo central. Cada equipo se hace responsable de sus propios datos, lo que impulsa la calidad y la uniformidad. Mediante el uso de productos de datos fáciles de entender y herramientas de autoservicio, la data mesh garantiza que todos los equipos puedan acceder y gestionar rápidamente sus datos, llevando a operaciones más rápidas y eficientes y una mejor alineación con las necesidades del negocio.
Principios clave de Data Mesh
- Propiedad descentralizada de datos: Los equipos son propietarios y manejadores de sus productos de datos, lo que les hace responsables de su calidad y disponibilidad.
- Datos como un producto: Los datos se tratan como un producto con acceso estandarizado, versionado y definiciones de esquema, garantizando consistencia y facilidad de uso entre departamentos.
- Gobernabilidad federada: Se establecen políticas para mantener la integridad de los datos, la seguridad y la conformidad, permitiendo aún la propiedad descentralizada.
- Infraestructura de autoservicio: Los equipos tienen acceso a una infraestructura escalable que apoya la ingestión, procesamiento y consulta de datos sin problemas de colas o dependencia de un equipo centralizado de datos.
¿Cómo ayudan los eventos a la matriz de datos?
Los eventos ayudan a la matriz de datos permitiendo a diferentes partes del sistema compartir y actualizar datos en tiempo real. Cuando algo cambia en una zona, un evento notifica a otras áreas sobre esto, de modo que todos se mantienen actualizados sin necesidad de conexiones directas. Esto hace que el sistema sea más flexible y escalable porque puede manejar muchos datos y adaptarse a cambios fácilmente. Los eventos también hacen más fácil rastrear cómo se utilizan y gestionan los datos y permiten que cada equipo maneje sus propios datos sin depender de los demás.
Finalmente, veamos la arquitectura de matriz de datos basada en eventos.
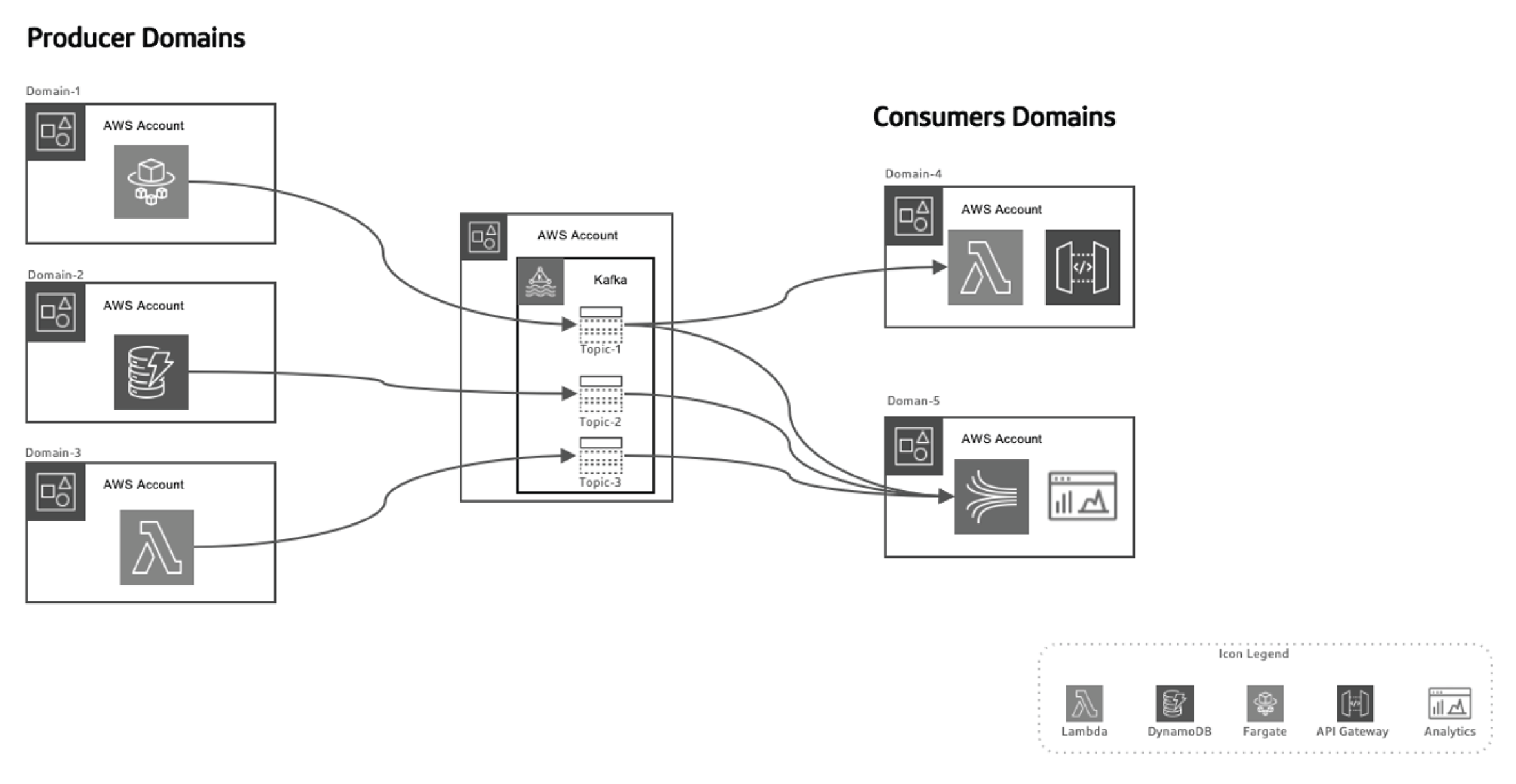
Este enfoque basado en eventos permite separar a los productores de datos de los consumidores, haciendo que el sistema sea más escalable a medida que los dominios evolucionan con el tiempo sin necesidad de cambios mayores en la arquitectura. Los productores son responsables de generar eventos, que luego se envían a un sistema de datos en tránsito. La plataforma de streaming garantiza que estos eventos se entreguen de manera confiable. Cuando un microservicio de productor o almacén de datos publica un nuevo evento, se almacena en un tema específico. Esto dispara los listeners del lado de los consumidores, como funciones Lambda o Kinesis, para procesar el evento y utilizarlo según sea necesario.
Aprovechando AWS para la arquitectura de matriz de datos basada en eventos
AWS ofrece una suite de servicios que complementan perfectamente el modelo de red de datos basado en eventos, permitiendo a las organizaciones escalar su infraestructura de datos, garantizar la entrega de datos en tiempo real, y mantener altos niveles de gobernanza y seguridad.
Así es cómo varios servicios de AWS se ajustan a esta arquitectura:
AWS Kinesis para Streaming de Eventos en Tiempo Real
En un modelo de red de datos basado en eventos, el streaming de eventos en tiempo real es un elemento crucial. AWS Kinesis proporciona la capacidad para recolectar, procesar y analizar datos de streaming en tiempo real a escala.
Kinesis ofrece varios componentes:
- Streams de Datos Kinesis: Ingiere eventos en tiempo real y procesuelos de manera concurrente con varios consumidores.
- Data Firehose de Kinesis: Entrega flujos de eventos directamente a S3, Redshift o Elasticsearch para un procesamiento y análisis adicionales.
- Análisis de Datos Kinesis: Procesa datos en tiempo real para obtener insights en vivo, permitiendo bucles de retroalimentación inmediatos en los pipelines de procesamiento de datos.
AWS Lambda para Procesamiento de Eventos
AWS Lambda es la base del procesamiento de eventos sin servidores en la arquitectura de red de datos. Con su capacidad para escalar automáticamente y procesar flujos de datos entrantes sin la necesidad de administración de servidores,
Lambda es una opción ideal para:
- Procesar flujos de Kinesis en tiempo real
- Invocar solicitudes de API Gateway en respuesta a eventos específicos
- Interactuar con DynamoDB, S3 o otros servicios de AWS para almacenar, procesar o analizar datos
AWS SNS y SQS para Distribución de Eventos
Servicio de Notificación Simple de AWSSNS) actúa como sistema primario de difusión de eventos, enviando notificaciones en tiempo real a través de sistemas distribuidos. AWS Servicio Simple de Cola (SQS) garantiza que los mensajes entre servicios desacoplabanse se entreguen de manera confiable, incluso en caso de fallas parciales del sistema. Estos servicios permiten que microservicios desacoplabanse interactúen sin dependencias directas, garantizando que el sistema permanezca escalable y tolerante a fallas.
AWS DynamoDB para la Gestión de Datos en Tiempo Real
En arquitecturas descentralizadas, DynamoDB proporciona una base de datos NoSQL escalable y de bajo latencia que puede almacenar datos de eventos en tiempo real, lo que lo hace ideal para almacenar los resultados de los pipelines de procesamiento de datos. Además, admite el patrón Outbox, donde los eventos generados por la aplicación se almacenan
en DynamoDB y consumidos por el servicio de flujo de datos (por ejemplo, Kinesis o Kafka).
AWS Glue para el Catálogo de Datos Federado y ETL
AWS Glue ofrece un servicio de catálogo de datos y ETL totalmente administrado, imprescindible para el gobierno de datos federados en la malla de datos. Glue ayuda a catalogar, preparar y transformar datos en dominios distribuidos, garantizando la descubierta, gobierno y integración a través de la organización.
AWS Lake Formation y S3 para Data Lakes
Mientras la arquitectura de data mesh se aleja de los lagos de datos centralizados, S3 y AWS Lake Formation juegan un papel crucial en el almacenamiento, seguridad y catalogación de datos que fluyen entre varios dominios, garantizando almacenamiento a largo plazo, gobernanza y cumplimiento de normas.
Arquitectura de Data Mesh Driven por Eventos en Acción con AWS y Python
Productor de Eventos: AWS Kinesis + Python
En este ejemplo, utilizamos AWS Kinesis para transmitir eventos cuando se crea un nuevo cliente:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
Procesamiento de Eventos: AWS Lambda + Python
Esta función Lambda consume eventos de Kinesis y los procesa en tiempo real.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
Conclusión
Al aprovechar los servicios de AWS como Kinesis, Lambda, DynamoDB y Glue, las organizaciones pueden comprender plenamente el potencial de la arquitectura de data mesh driven por eventos. Esta arquitectura ofrece agilidad, escalabilidad e insights en tiempo real, garantizando que las organizaciones permanezcan competitivas en el escenario de los datos en rápido evolución. Adoptar una arquitectura de data mesh driven por eventos no solo representa una mejora técnica sino un imperativo estratégico para las empresas que desean prosperar en la era de los grandes datos y de los sistemas distribuidos.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws