













In der heutigen datengestützten Welt müssen sich Unternehmen auf die schnellen Änderungen in der Datenverwaltung, Analyse und Nutzung einstellen. Traditionelle zentralisierte Systeme und monolithische Architekturen, die historisch genügend waren, reichen nicht mehr aus, um den wachsenden Anforderungen von Organisationen gerecht zu werden, die schneller und in Echtzeit auf Dateninsights zugreifen müssen. Ein revolutionäres Framework in diesem Bereich ist die Ereignisgesteuerte Datenmaschen-Architektur, und wenn es mit AWS-Diensten kombiniert wird, bietet sie eine robuste Lösung für die Lösung komplexer Datenmanagementschwierigkeiten.
Die Daten-Dilemma
Viele Organisationen haben erhebliche Herausforderungen, wenn sie auf veraltete Datenarchitekturen angewiesen sind. Diese Herausforderungen beinhalten:
Zentralisierte, monolithische und domain-unabhängige Datensee
Ein zentralisierterDatensee ist ein einzelnes Speicherziel für alle Ihre Daten, was die Verwaltung und den Zugriff einfach macht, aber möglicherweise Leistungsprobleme verursacht, wenn er nicht angemessen skaliert wird. Ein monolithischer Datensee kombiniert alle Datenverarbeitungsprozesse in einem integrierten System, was die Einrichtung vereinfacht, aber schwer skalierbar und zu wartend sein kann. Ein domain-unabhängiger Datensee ist designed, um Daten aus jedem Branche oder Quelle zu speichern, was Flexibilität und breite Anwendbarkeit bietet, aber möglicherweise komplizierter zu verwalten und nicht speziell optimiert für bestimmte Anwendungen.
Fehlgeschlagene Drückepunkte traditioneller Architekturen
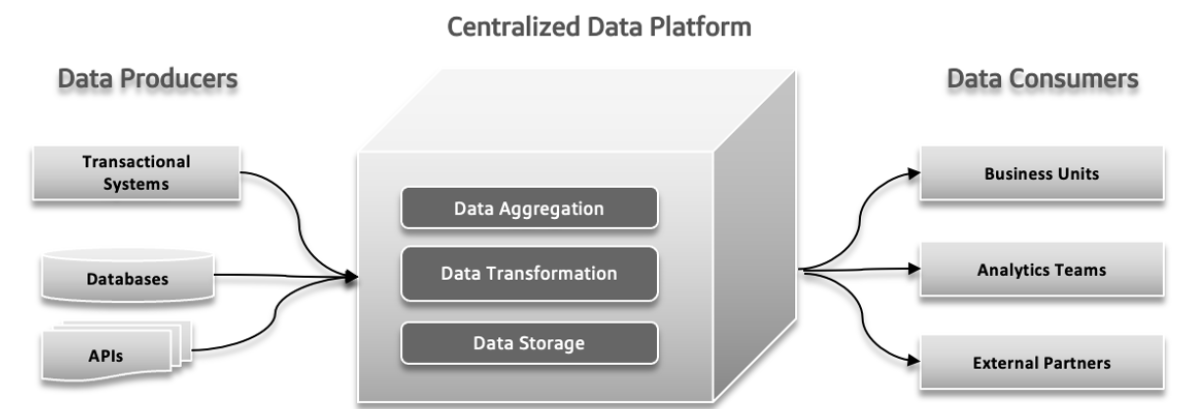
In traditionellen Daten systemen können mehrere Probleme auftreten. Datenproduzenten können große Datenmengen oder Daten mit Fehlern senden, die Probleme in der weiteren Verarbeitung verursachen. Mit zunehmender Datenkomplexität und der Beteiligung mehrerer verschiedener Quellen am System kann eine zentralisierte Datenplattform Schwierigkeiten haben, die wachsende Belastung zu bewältigen, was zu Abstürzen und langsamer Leistung führt. Der zunehmende Bedarf an schneller Experimentierung kann das System überfordern, was es schwer macht, schnell neue Ideen zu adaptieren und zu testen. Datenantwortzeiten können zu einem Problem werden, was zu Verzögerungen beim Zugriff und der Nutzung von Daten führt und die Entscheidungsfindung und die Gesamtfunktionalität beeinträchtigt.
Divergenz zwischen operativen und analytischen Datenlandschaften
In der Softwarearchitektur können Probleme wie getrennte Verantwortung, unklar verstandene Daten Nutzung, enge Anbindung von Datenpipelines und grundlegende Begrenzungen zu bedeutenden Problemen führen. Getrennte Verantwortung tritt auf, wenn verschiedene Teams isoliert arbeiten, was zu Koordinierungsproblemen und Ineffizienzen führt. Ein Mangel an klaren Informationen darüber, wie Daten verwendet oder geteilt werden sollten, kann zu doppelter Arbeit und inkonsistenten Ergebnissen führen. Verschmolzene Datenpipelines, bei denen Komponenten zu stark untereinander abhängig sind, erschweren es, das System anzupassen oder zu skalieren, was zu Verzögerungen führt. Schließlich können grundlegende Begrenzungen im System die Bereitstellung neuer Features und Updates verlangsamen, was die allgemeine Fortschritts behindert. Die Behandlung dieser Druckpunkte ist für einen effizienteren und reaktiveren Entwicklungsprozess wichtig.
Herausforderungen mit Big Data
Online Analytische Verarbeitung (OLAP) Systeme organisieren Daten auf eine Weise, die es Analysten erleichtert, unterschiedliche Aspekte der Daten zu erforschen. Um Abfragen zu beantworten, müssen diese Systeme operative Daten in ein Format verwandeln, das für die Analyse geeignet ist, und mit großen Datenmengen behandle. Traditionelle Datenlager verwenden ETL (Extrahieren, Transformieren, Laden) Prozesse, um dies zu verwalten. Big Data Technologien wie Apache Hadoop haben Datenlager verbessert, indem sie Skalierungsprobleme angegangen und Open Source sind, was es jedem Unternehmen ermöglicht, sie zu nutzen, solange sie die Infrastruktur verwalten können. Hadoop brachte eine neue Herangehensweise mit sich, indem er unstrukturierte oder halbstrukturierte Daten zuließ, anstatt einen strengen Schema vorab durchzusetzen. Diese Flexibilität, bei der Daten ohne vorherdefiniertes Schema geschrieben werden konnten und später während der Abfragen strukturiert wurden, machte es Dateningenieuren einfacher, Daten zu handhaben und zu integrieren. Die Adoption von Hadoop bedeutete oft die Formierung einer separaten Datateam: Dateningenieure handled Datenextraktion, Datenwissenschaftler verwalteten Reinigung und Umstrukturierung, und Datenanalysten führten Analysen durch. Diese Setup führte manchmal zu Problemen aufgrund der begrenzten Kommunikation zwischen dem Datateam und den Anwendungsentwicklern, oft, um die Produktionssysteme zu schützen.
Problem 1: Probleme mit den Datenmodell-Grenzen
Die verwendeten Daten für die Analyse sind eng mit ihrer ursprünglichen Struktur verbunden, was bei komplexen, oft aktualisierten Modellen problematisch sein kann. Änderungen an der Datenmodellierung betreffen alle Benutzer, die dadurch anfällig für diese Änderungen werden, insbesondere wenn das Modell viele Tabellen umfasst.
Problem 2: Schlechte Daten, die Kosten der Problemvermeidung
Schlechte Daten werden oft erst dann entdeckt, wenn sie zu Problemen in einem Schema führen, wie z.B. falsche Datentypen. Da die Validierung oft bis zum Ende des Prozesses verschoben wird, können schlechte Daten durch Pipelines verbreitet werden, was zu teuren Reparaturen und inkonsequenten Lösungen führt. Schlechte Daten können zu beträchtlichen Geschäftsverlusten führen, beispielsweise Rechnungsfehler, die Millionen kosten. Forschungen zeigen, dass schlechte Daten Geschäften jährlich Trilliarden an Kosten verursachen, was für Wissensarbeiter und Datenwissenschaftler substanzielle Zeit verschwendet.
Problem 3: Fehlende einheitliche Verantwortung
Anwendungsentwickler, die Experten im Quell-Datenmodell sind, teilen diese Information normalerweise nicht mit anderen Teams. Ihre Verantwortung beschränkt sich oft auf ihre Anwendung und Datenbank-Grenzen. Dateninformatiker, die Datenextraktion und -bewegung verwalten, arbeiten oft reaktiv und haben über die Datenquellen nur eingeschränkten Einfluss. Datenanalysten, die weit entfernt von den Entwicklern sind, haben Probleme mit den ihnen zugeordneten Daten, was zu Koordinierungsproblemen und der Notwendigkeit für separate Lösungen führt.
Problem 4: Benutzerdefinierte Datenverbindungen
In großen Organisationen können mehrere Teams dieselben Daten verwenden, aber für ihre Verwaltung eigene Prozesse erzeugen. Dies führt zu mehreren Kopien von Daten, die unabhängig voneinander verwaltet werden und erzeugen somit ein durcheinander. Es ist schwierig, ETL-Aufträge zu verfolgen und Datenqualität sicherzustellen, was zu Ungenauigkeiten durch Synchronisierungsprobleme und ungesicherte Datenquellen führt. Dieser zersplitterte Ansatz verschwendet Zeit, Geld und Chancen.
Datenmesh löst diese Probleme, indem Daten als Produkt behandelt werden, das über klare Schemas, Dokumentation und standardisierte Zugriffe verfügt, was das Risiko von schlechten Daten reduziert und die Datengenauigkeit und -effizienz verbessert.
Datenmesh: Ein moderner Ansatz
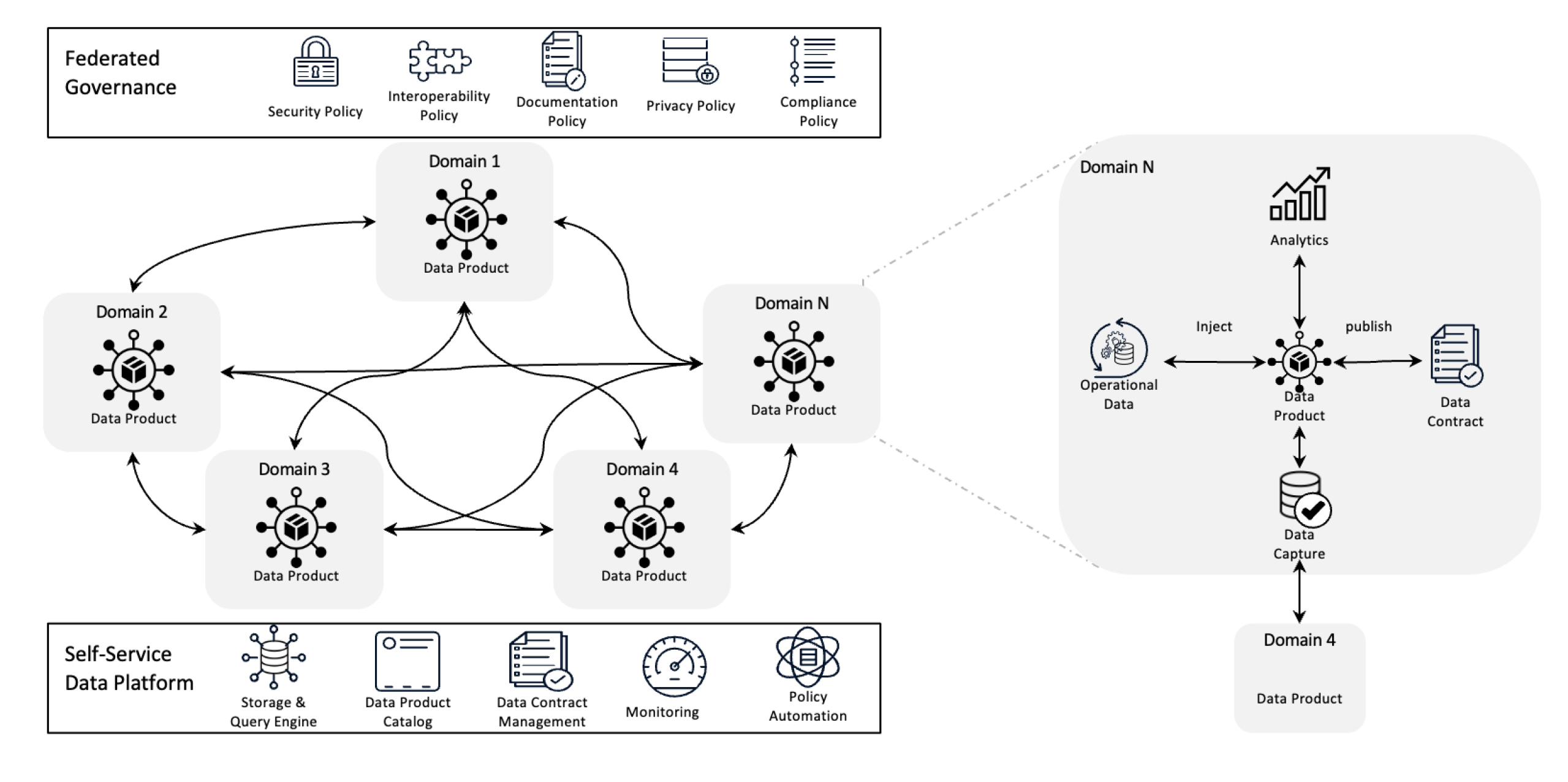
Datenmesh-Architektur
Der Datenmesh verändert die Datenverwaltung, indem er die Eigentumsverteilung dezentralisiert und Daten als Produkt behandelt, unterstützt durch selbstbedienende Infrastruktur. Dieser Wechsel ermöglicht den Teams, vollständige Kontrolle über ihre Daten zu erlangen, während die föderierte Governance Qualität, Compliance und Skalierbarkeit über die gesamte Organisation gewährleistet.
In einfacheren Worten handelt es sich um eine Architektur, die komplizierte Datenaufgaben löst durch die Verwendung dezentralisierter Eigentumsverteilung und verteilter Methoden. Es wird verwendet, um Daten aus verschiedenen Geschäftsbereichen zu integrieren, um umfassende Datenanalyse zu ermöglichen. Es basiert auch auf starken Datenanonymisierungs- und Governance-Politiken.
Ziele von Data Mesh
Datenmesh hilft verschiedenen Organisationen, wertvolle Einblicke in die Daten auf Skalen zu erhalten; kurzfristig, die Bearbeitung eines ständig wechselnden Datenlandschaften, die zunehmende Zahl von Datenquellen und Benutzern, die Vielzahl der notwendigen Datentransformationen und die Notwendigkeit, schnell auf Veränderungen zu adaptieren.
Data mesh löst alle oben genannten Probleme durch Dezentralisierung der Kontrolle, sodass Teams ihre eigenen Daten verwalten können, ohne dass sie in separaten Abteilungen isoliert sind. Dieser Ansatz verbessert die Skalierbarkeit durch die Verteilung der Datenverarbeitung und -speicherung, was das Verlangsammen eines einzigen zentralen Systems vermeidet. Es beschleunigt die Erkenntnisse, indem Teams direkt mit ih eigenen Daten arbeiten, die Verzögerungen vermeiden, die durch das Warten auf ein zentrales Team verursacht werden. Jeder Team übernimmt die Verantwortung für ihre eigenen Daten, was die Qualität und die Konsistenz verbessert. Durch die Verwendung leicht verständlicher Datenprodukte und Selbstbedienungstools gewährleistet data mesh, dass alle Teams schnell Zugriff auf und Verwaltung ihrer Daten haben, was zu schnelleren, effizienteren Operationen und besserer Übereinstimmung mit den Geschäftsbedürfnissen führt.
Wichtige Prinzipien von Data Mesh
- Dezentralisierte Daten Eigentum: Teams besitzen und verwalten ihre Datenprodukte, was sie dafür verantwortlich macht, für ihre Qualität und Verfügbarkeit.
- Daten als Produkt: Daten werden wie ein Produkt behandelt mit standardisiertem Zugriff, Versionsverwaltung und Schemadefinitionen, um Konsistenz und einfache Nutzung über Abteilungen hinweg zu gewährleisten.
- Föderierte Governance: Politiken werden festgelegt, um Datenintegrität, Sicherheit und Compliance aufrechtzuerhalten, während noch Dezentralisierung des Eigentums zugelassen wird.
- Selbstbediente Infrastruktur: Teams haben Zugang zu skalierbarer Infrastruktur, die die Verarbeitung, den Eingang und die Abfrage von Daten ohne Engpässe oder Abhängigkeit von einer zentralen Datenmannschaft unterstützt.
Wie helfen Ereignisse dem Data Mesh?
Ereignisse helfen einem Data Mesh, indem verschiedene Teile des Systems Daten in Echtzeit teilen und aktualisieren können. Wenn sich etwas ändert, erhalten andere Bereiche darüber informiert, sodass jeder auf dem neuesten Stand bleibt, ohne direkte Verbindungen zu benötigen. Dies macht das System flexibler und skalierbarer, da es großen Datenmengen und leichten adaptiertem auf Änderungen zuständig ist. Ereignisse erleichtern auch die Datenverwendung und -verwaltung und lassen jedes Team seine eigenen Daten selbstständig verwalten, ohne auf andere zu verlassen.
Schließlich lassen uns die Ereignisgesteuerte Data Mesh-Architektur anschauen.
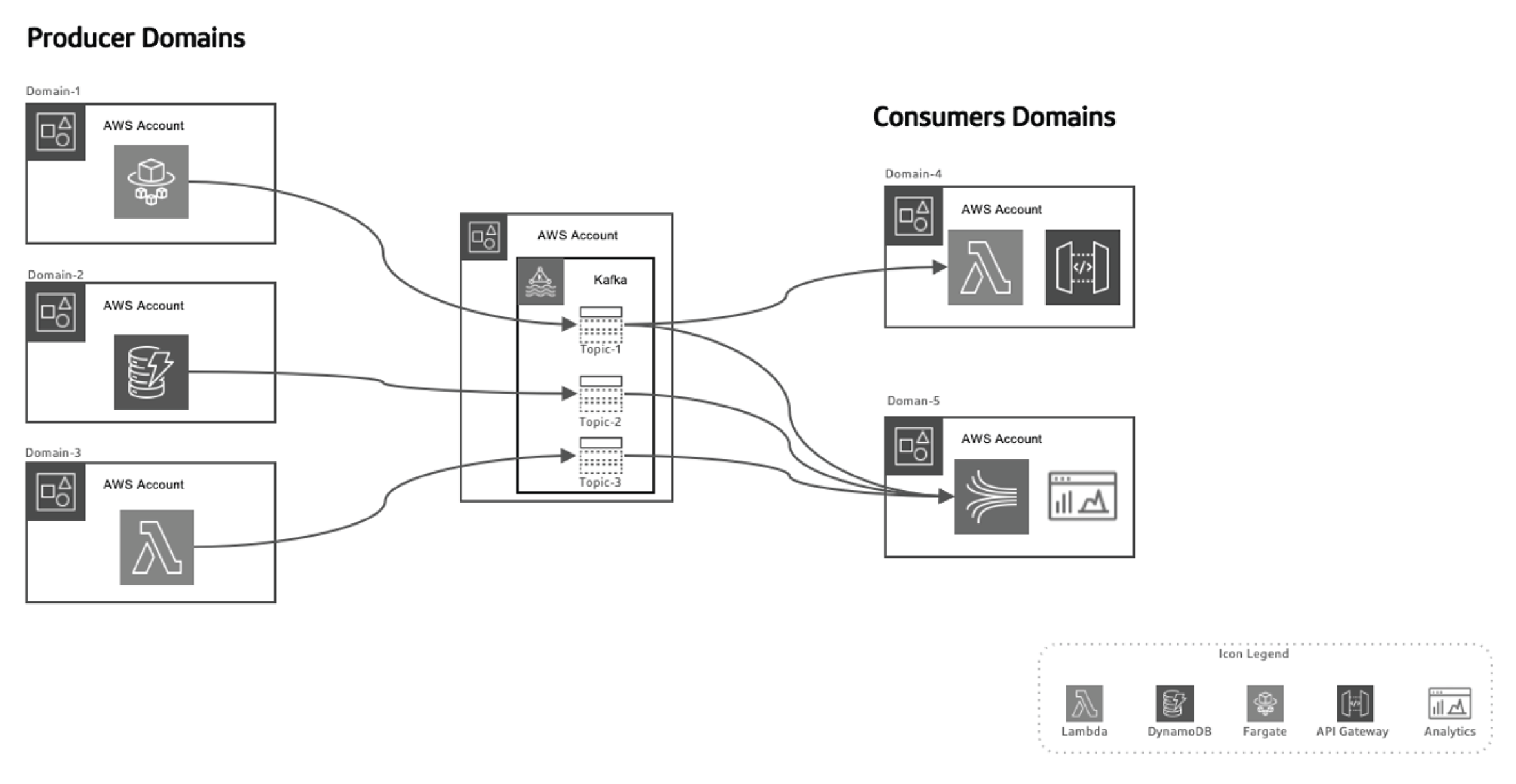
Dieser Ereignisgesteuerte Ansatz lässt die Datenproduzenten von den Datenverbrauchern trennen, was das System skalierbarer macht, da die Domänen mit der Zeit weiterentwickelt werden können, ohne größere Änderungen an der Architektur zu benötigen. Die Datenproduzenten sind verantwortlich für die Erzeugung von Ereignissen, die dann an ein Daten-in-Transit-System gesendet werden. Die Streaming-Plattform stellt sicher, dass diese Ereignisse zuverlässig übertragen werden. Wenn ein Produktions-Microservice oder ein Datenspeicher ein neues Ereignis veröffentlicht, wird es in eine bestimmte Thema gespeichert. Dies triggert auf der Verbraucherseite Listener, wie Lambda-Funktionen oder Kinesis, die das Ereignis verarbeiten und es wie notwendig verwenden.
Verwendung von AWS für die Ereignisgesteuerte Data Mesh-Architektur
AWS bietet eine Reihe von Dienstleistungen, die perfekt zu dem Ereignis-getriebenen Datenmesh-Modell passen, was Organisationen dazu befähigt, ihre Dateninfrastruktur skalieren, sicherzustellen, dass Daten in Echtzeit übermittelt werden und hohe Verwaltungs- und Sicherheitsstandards aufrecht erhalten.
So passt sich eine Reihe von AWS-Dienstleistungen in diese Architektur an:
AWS Kinesis für Echtzeit-Ereignisdatenstromverarbeitung
Bei einem Ereignis-getriebenen Datenmesh ist die Echtzeit-Datenstromverarbeitung ein entscheidender Bestandteil. AWS Kinesis bietet die Möglichkeit, skalierbare Echtzeit-Datenstromverarbeitung mit mehreren Konsumenten zu erbringen.
Kinesis verfügt über mehrere Komponenten:
- Kinesis Data Streams: Verarbeite Echtzeitereignisse gleichzeitig mit mehreren Konsumenten.
- Kinesis Data Firehose: Leite Ereignisdatenstrome direkt an S3, Redshift oder Elasticsearch weiter, um weitere Verarbeitung und Analyse durchzuführen.
- Kinesis Data Analytics: Verarbeite Daten in Echtzeit, um flüchtige Einsichten zu gewinnen und ermögliche sofortige Rückkopplungen in den Datenverarbeitungspipelines.
AWS Lambda für Ereignisverarbeitung
AWS Lambda stellt das Rückgrat des serverlosen Ereignisverarbeitungssystems in der Datenmesh-Architektur dar. Mit seiner Fähigkeit, automatisch skalierend und eingehende Datenströme ohne den Bedarf an Serververwaltung zu verarbeiten,
ist Lambda eine ideale Wahl für:
- Die Verarbeitung von Kinesis-Datenströmen in Echtzeit
- Das Aufrufen von API-Gatewayanfragen als Reaktion auf bestimmte Ereignisse
- Die Interaktion mit DynamoDB, S3 oder anderen AWS-Dienstleistungen zum Speichern, Verarbeiten oder Analysieren von Daten
AWS SNS und SQS für die Ereignisverteilung
AWS Einfaches Benachrichtigungsservice (SNS) agiert als primäres Ereignisübertragungssystem und sendet Echtzeitbenachrichtigungen über verteilte Systeme aus. AWS Einfache Warteschlangendienst (SQS) gewährleistet, dass Nachrichten zwischen unabhängigen Diensten zuverlässig zugestellt werden, auch bei teilweisen Systemfehlern. Diese Dienste ermöglichen es unabhängigen Mikroservices, unmittelbar aufeinander zu verzichten und das System bleibt skalierbar und fehlertolerant.
AWS DynamoDB für Echtzeitdatenverwaltung
In dezentralen Architekturen bietet DynamoDB eine skalierbare, niedriglatenzytige NoSQL-Datenbank an, die Ereignisdaten in Echtzeit speichern kann und somit ideal ist, um die Ergebnisse von Datenverarbeitungspipelines aufzuladen. Es unterstützt den Outbox-Muster, wo Ereignisse, die vom Anwendungsprogramm generiert werden, in DynamoDB gespeichert und anschließend vom Streaming-Dienst (z.B. Kinesis oder Kafka) verarbeitet werden.
in DynamoDB und von dem Streaming-Dienst (z.B. Kinesis oder Kafka) verarbeitet werden.
AWS Glue für verteilte Datenkataloge und ETL
AWS Glue bietet einen vollständig verwalteten Datenkatalog und ETL-Dienst, der für die verteilte Datenverwaltung in einem Datenmesh unerlässlich ist. Glue hilft dabei, Daten in verteilten Bereichen aufzulisten, vorzubereiten und zu transformieren, um die Entdeckbarkeit, die Verwaltung und die Integration innerhalb der Organisation sicherzustellen.
AWS Lake Formation und S3 für Datenlager.
Während die Datenmesh-Architektur weg von zentralisierten Datenseen geht, spielen S3 und AWS Lake Formation eine entscheidende Rolle bei der Speicherung, Sicherung und Katalogisierung von Daten, die zwischen verschiedenen Bereichen fließen, um langfristige Speicherung, Governance und Compliance sicherzustellen.
Ereignisgetriebene Datenmesh in Aktion mit AWS und Python
Ereignisproduzent: AWS Kinesis + Python
In diesem Beispiel verwenden wir AWS Kinesis, um Ereignisse zu streamen, wenn ein neuer Kunde erstellt wird:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
Ereignisverarbeitung: AWS Lambda + Python
Diese Lambda-Funktion verarbeitet Kinesis-Ereignisse in Echtzeit.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
Fazit
Durch die Nutzung von AWS-Diensten wie Kinesis, Lambda, DynamoDB und Glue, können Organisationen das vollständige Potential des Ereignisgetriebenen Datenmesh-Architekturs nutzen. Diese Architektur bietet Agilität, Skalierbarkeit und Echtzeitsignale, die sicherstellen, dass Organisationen im heutigen schnell verändernden Datenlandscape wettbewerbsfähig bleiben. Die Einführung einer Ereignisgetriebenen Datenmesh-Architektur ist nicht nur eine technische Verbesserung, sondern eine strategische Notwendigkeit für Unternehmen, die im Zeitalter der Big Data und verteilten Systeme erfolgreich sein wollen.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws