













Nel mondo oggi guidato da dati, le aziende devono adattarsi rapidamente alle nuove modalità di gestione, analisi e utilizzo dei dati. I sistemi centralizzati tradizionali e le architetture monolitiche, pur essendo state sufficienti storicamente, non sono più adeguate ai crescenti bisogni delle organizzazioni che richiedono accessi veloci e real-time alle insights dei dati. Una rivoluzione in questo settore è l’architettura event-driven del data mesh, e quando combinata con i servizi di AWS, diventa una soluzione robusta per affrontare i complessi挑战 del manageamento dei dati.
Il Dilemma dei Dati
Molte organizzazioni affrontano sfide significative quando si affidano a architetture dati obsolete. Questi challenge includono:
Lake Dei Dati Centralizzato, Monolitico e Agnostic Domain
Un lake dei dati centralizzatoè un unico punto di storage per tutti i vostri dati, rendendone la gestione e l’accesso facili ma potenzialmente causando problemi di performance se non scalato correttamente. Un lake dei dati monolitico combina tutti i processi di gestione dati in un sistema integrato, che semplifica la configurazione ma può essere difficile da scalare e mantenere. Un lake dei dati agnostic domain è progettato per memorizzare dati da qualsiasi settore o fonte, offrendo flessibilità e applicabilità ampia ma può essere complesso da gestire e meno ottimizzato per specifici usi.
Punti di pressione di fallimento nell’architettura tradizionale
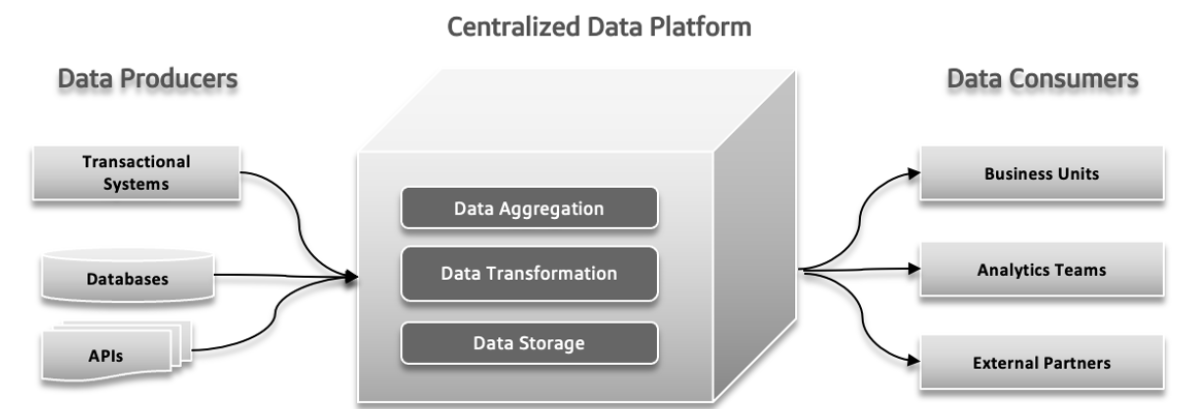
In sistemi dati tradizionali, possono verificarsi diversi problemi. I produttori di dati possono inviare grandi quantità di dati o dati con errori, creando problemi a valle. Con l’aumentare la complessità dei dati e l’ingresso di fonti sempre più diverse nel sistema, la piattaforma dati centralizzata può lottare ad affrontare il carico in crescita, portando a crash e prestazioni lente. L’aumentata domanda di sperimentazione rapida può sopraffare il sistema, rendendo difficile adattarsi e testare nuove idee in modo rapido. Le risposte ai dati possono diventare un problema, causando rallentamenti nell’accesso e utilizzo dei dati, che influiscono sulla decisione e sull’efficienza complessiva.
Divergenza tra il panorama operativo e quello analitico dei dati
Nell’architettura software, problemi come la proprietà isolata, l’uso dei dati non chiaro, i data pipeline altamente dipendenti tra di loro e le limitazioni innate possono causare problemi significativi. La proprietà isolata si verifica quando team diversi lavorano in isolamento, portando a problemi di coordinamento e inefficienze. La mancanza di una chiara comprensione di come i dati dovrebbero essere utilizzati o condivisi può portare a duplicazioni di sforzi e risultati inconsistenti. I data pipeline unitari, in cui i componenti sono troppo dipendenti l’uno dall’altro, rendono difficile adattarsi o scalare il sistema, causando rallentamenti. Infine, le limitazioni innate del sistema possono rallentare l’implementazione di nuove funzionalità e aggiornamenti, ostacolando il progresso complessivo. Risolvere questi punti di pressione è cruciale per un processo di sviluppo più efficiente e reattivo.
Sfide del Big Data
I sistemi di Processamento Analitico Online (OLAP) organizzano i dati in modo da facilitare agli analisti l’esplorazione di diversi aspetti dei dati. Per rispondere alle query, questi sistemi devono trasformare i dati operativi in un formato adatto all’analisi e gestire grandi volumi di dati. I tradizionali data warehouse utilizzano i processi ETL (Estrai, Trasforma, Carica) per gestire questo. Le tecnologie big data, come Apache Hadoop, hanno migliorato i data warehouse risolvendo i problemi di scalabilità e essendo open source, permettendo a qualsiasi azienda di usarli purché sia in grado di gestire l’infrastruttura. Hadoop ha introdotto un nuovo approcio permettendo dati non strutturati o semi-strutturati invece di imporre un schema stretto all’avvio. questa flessibilità, in cui i dati potevano essere scritti senza schema predefinito e strutturati in seguito durante le query, ha reso più semplice per gli ingegneri del data handling e integrazione dati. Adottare Hadoop spesso significava formare un team separato per i dati: gli ingegneri del data si occupavano dell’estrazione dati, i data scientist gestivano la pulizia e la ristrutturazione, e gli analisti dell’analisi facevano l’analisi. Questo setup ha spesso portato a problemi a causa della limitata comunicazione tra il team dati e i sviluppatori dell’applicazione, spesso per prevenire l’impatto sui sistemi di produzione.
Problema 1: Issue con i limiti del modello dati
I dati utilizzati per l’analisi sono strettamente legati alla loro struttura originale, il che può essere problematico con modelli complessi e aggiornati frequentemente. Modifiche al modello dati influiscono su tutti gli utenti, li rendendo vulnerabili a questi cambiamenti, specialmente quando il modello coinvolge molte tabelle.
Problema 2: Dati errati, i costi dell’ignorare il problema
I dati errati spesso passano inosservati fino a quando non causano problemi in uno schema, portando a problemi come i tipi di dati sbagliati. Dato che la validazione spesso è posticipata fino alla fine del processo, i dati errati possono diffondersi attraverso i pipeline, portando a correzioni costose e soluzioni incoerenti. I dati errati possono portare a significative perdite aziendali, come gli errori di fatturazione che costano milioni. ricerche indicano che i dati errati costano agli aziendi trilioni all’anno, squandendo notevolmente il tempo dei lavoratori del sapere e degli scienziati dati.
Problema 3: Mancanza di un’unica proprietà
I programmatori delle applicazioni, esperti nella modellazione dati sorgente, di solito non comunicano queste informazioni agli altri team. Le loro responsabilità spesso finiscono ai limiti delle applicazioni e dei database. Gli ingegneri dati, che gestiscono l’estrazione e il movimento dati, lavorano spesso in maniera reattiva e hanno un controllo limitato sugli schemi dati. Gli analisti dati, separati dai programmatori, affrontano i problemi con i dati che ricevono, portando a problemi di coordinamento e alla necessità di soluzioni separate.
Problema 4: Connessioni dati personalizzate
In grandi organizzazioni, diversi team potrebbero utilizzare lo stesso set di dati ma creare i propri processi per la gestione di quei dati. Questo può portare a molteplici copie dei dati, ciascuna gestita indipendentemente, creando un’enorme confusione. Diventa difficile seguire i job ETL e assicurarsi della qualità dei dati, portando a inaccurazioni dovute a fattori come problemi di sincronizzazione e fonti meno secure di dati. Questo approcio disperso squilibra il tempo, i costi e le opportunità.
Data Mesh risolve questi problemi trattando i dati come un prodotto con schemi chiari, documentazione e accesso standardizzato, riducendo il rischio di dati errati e migliorando l’accuratezza e l’efficienza dei dati.
Data Mesh: Un Approcio Moderno
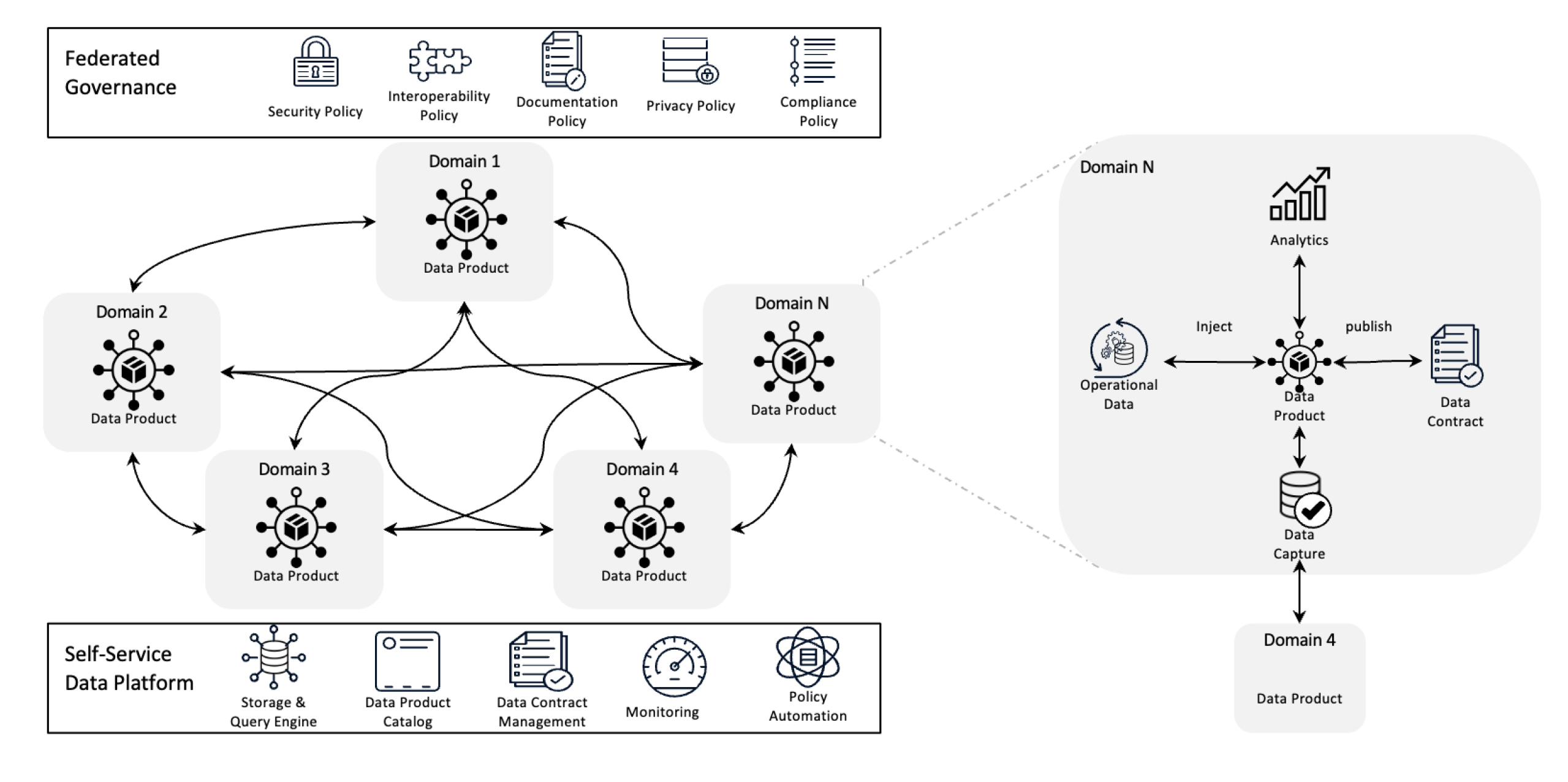
Architettura di Data Mesh
Il Data Mesh redefinisce la gestione dati decentralizzando la proprietà e trattando i dati come un prodotto, supportato da infrastrutture di self-service. Questo cambio consente alle squadre di assumere il pieno controllo dei loro dati mentre una governanza federata garantisce qualità, conformità e scalabilità a livello organizzativo.
In termini semplici, rappresenta un framework architetturale progettato per risolvere i complessi challenge dati utilizzando una proprietà decentralizzata e metodi distribuiti. Viene utilizzato per integrare dati da diversi settori aziendali per analisi dati comprehensive. E ‘anche costruito sulla base di solide politiche di condivisione e governance dati.
Obiettivi di Data Mesh
La data mesh aiuta varie organizzazioni a ottenere insights preziosi sui dati a scala; in breve, si tratta di gestire un scenario dati in continuo cambiamento, il numero crescente di fonti dati e utenti, la varietà di trasformazioni dati necessarie, e la necessità di adattarsi rapidamente ai cambiamenti.
La data mesh risolve tutti i problemi menzionati prima decentralizzando il controllo, cosicché i team possono gestire i propri dati senza che siano isolati in dipartimenti separati. Questo approcio migliora la scalabilità distribuendo la processing e il storage dati, evitando rallentamenti in un singolo sistema centrale.加速洞察通过允许团队直接与自己的数据工作,减少等待中央团队引起的延迟。每个团队对自己的数据负责,提高了质量和一致性。通过使用容易理解的数据产品和自助工具,数据网格确保所有团队可以快速访问和管理他们的数据,从而加快了操作,更有效地与业务需求保持一致。
Principi chiave di Data Mesh
- Proprietà decentralizzata dei dati: I team sono responsabili della loro prodotto dati, gestendoli e garantendo la loro qualità e disponibilità.
- Dati come prodotto: I dati sono trattati come prodotti con accesso standardizzato, versionamento e definizioni di schema, garantendo coerenza e facilità d’uso tra i dipartimenti.
- Governo federato: Le politiche sono stabilite per mantenere l’integrità dei dati, la sicurezza e la conformità, permettendo ancora il possesso decentralizzato.
- Infrastruttura self-service: Le squadre hanno accesso ad una infrastruttura scalabile che supporta l’ingestione, il processamento e la ricerca dei dati senza bottleneck o dipendenza da un team dati centralizzato.
Come i事件 aiutano la Data Mesh?
I事件 aiutano la Data Mesh permettendo a diversi componenti del sistema di condividere e aggiornare i dati in tempo reale. Quando qualcosa cambia in una determinata area, un evento notifica altre aree, cosicché tutti rimangono aggiornati senza aver bisogno di connessioni dirette. Ciò rende il sistema più flessibile e scalabile poiché può gestire grandi quantità di dati e adattarsi ai cambiamenti con facilità. I事件 anche facilitano il tracciamento dell’uso e della gestione dei dati, consentendo a ogni team di gestire i propri dati senza dipendere dagli altri.
Infine, consideriamo l’architettura della Data Mesh basata su eventi.
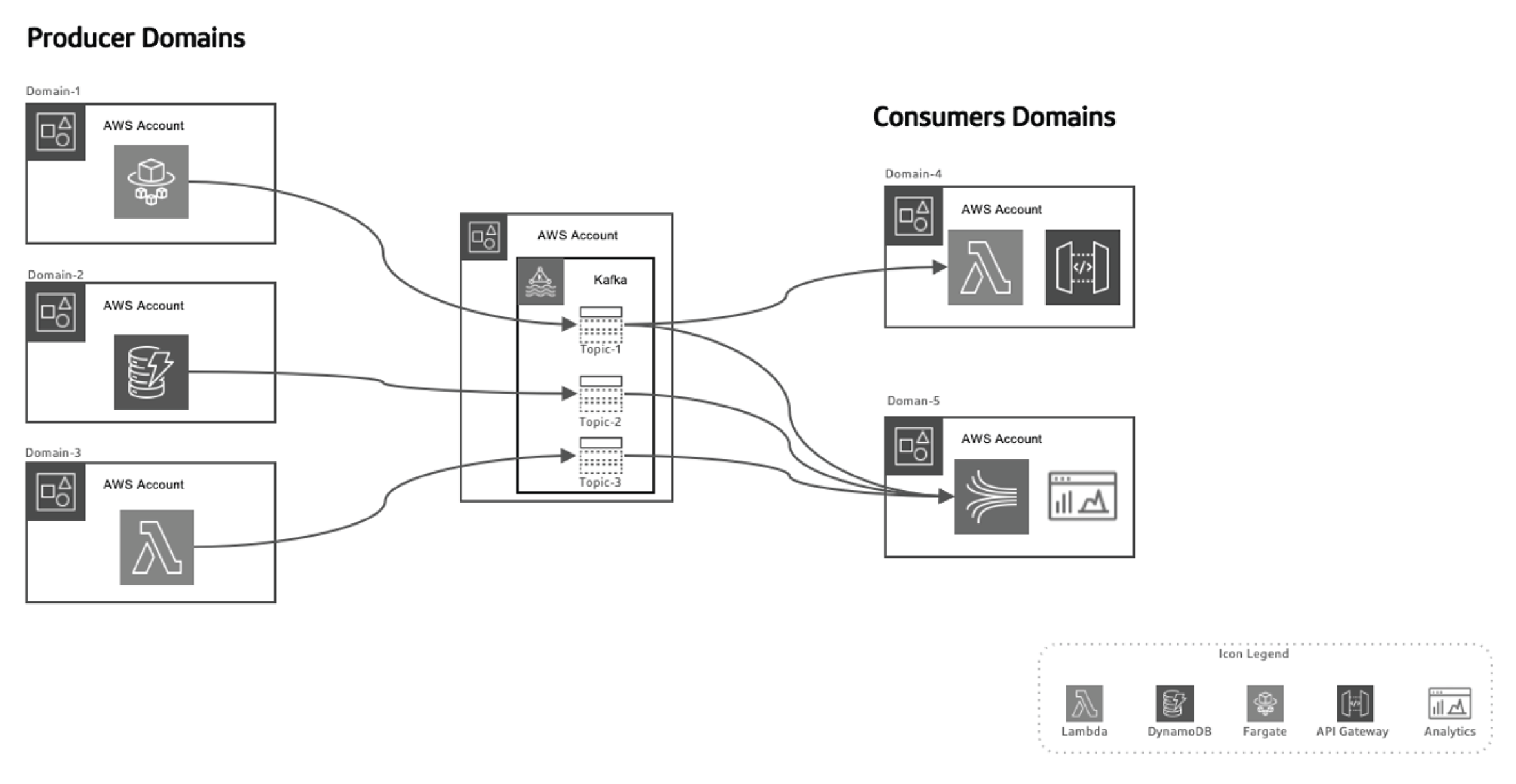
Questo approcio basato su eventi consente di separare i produttori di dati dai consumatori, rendendo il sistema più scalabile mentre i domini evolvono nel tempo senza necessità di modifiche significative all’architettura. I produttori sono responsabili della generazione degli eventi, che vengono quindi inviati a un sistema dati in transito. La piattaforma streaming garantisce la consegna affidabile di questi eventi. Quando un microservizio o un datastore produttore pubblica un nuovo evento, viene memorizzato in un topic specifico. Questo triggerizza ascoltatori sul lato consumer, come funzioni Lambda o Kinesis, per processare l’evento e usarlo come necessario.
Utilizzare AWS per l’architettura Data Mesh basata su eventi
AWS offre una suite di servizi che integrano perfettamente il modello di data mesh guidato dagli eventi, permettendo alle organizzazioni di scalare la loro infrastruttura dati, di assicurare la consegna dati in tempo reale e di mantenere alti livelli di governance e sicurezza.
Ecco come i vari servizi AWS si inseriscono in questa architettura:
AWS Kinesis per il Streaming Evento in tempo reale
In un data mesh guidato dagli eventi, il streaming evento in tempo reale è un elemento cruciale. AWS Kinesis offre la capacità di raccogliere, processare e analizzare dati streaming in tempo reale a scala.
Kinesis offre diversi componenti:
- Stream di dati Kinesis: Ingredisce eventi in tempo reale e li processa in parallelo con molti consumer.
- Data Firehose di Kinesis: Consegna direttamente stream di eventi a S3, Redshift o Elasticsearch per ulteriore processamento e analisi.
- Analisi dati Kinesis: Processa i dati in tempo reale per estrarre insights sul momento, permettendo loop di feedback immediati nei pipeline di processamento dati.
AWS Lambda per il Processamento degli Eventi
AWS Lambda costituisce la base del processamento degli eventi serverless nell’architettura del data mesh. Con la sua capacità di scalare automaticamente e processare stream di dati in entrata senza la necessità di gestire server,
Lambda è una scelta ideale per:
- Processare stream Kinesis in tempo reale
- Invocare richieste API Gateway in risposta a specifici eventi
- Interagire con DynamoDB, S3 o altri servizi AWS per memorizzare, processare o analizzare dati
AWS SNS e SQS per la Distribuzione degli Eventi
AWSServizio di Notifica Semplice(SNS) agisce come sistema primario di diffusione di eventi, inviando notifiche in tempo reale attraverso sistemi distribuiti.AWS Servizio di Coda Semplice (SQS) garantisce che i messaggi tra i servizi decentralizzati siano consegnati in maniera affidabile, anche in presenza di guasti parziali del sistema. Questi servizi consentono agli microservizi decouplati di interagire senza dipendenze dirette, garantendo che il sistema rimanga scalabile e tollerante ai guasti.
AWS DynamoDB per la gestione dati in tempo reale
Nelle architetture decentralizzate, DynamoDB fornisce una database NoSQL scalabile e a bassa latenza in grado di memorizzare i dati di evento in tempo reale, rendendola ideale per la memorizzazione dei risultati dei pipeline di processamento dati. Supporta il pattern Outbox, in cui gli eventi generati dall’applicazione sono memorizzati
in DynamoDB e consumati dal servizio di streaming (ad esempio Kinesis o Kafka).
AWS Glue per il catalogo federato dei dati e l’ETL
AWS Glue offre un servizio di catalogo dati e ETL completamente gestito, essenziale per il governo dati federati nel data mesh. Glue aiuta a catalogare, preparare e trasformare i dati in domini distribuiti, garantendo la scoperta, il governo e l’integrazione attraverso l’organizzazione.
AWS Lake Formation e S3 per i data lake.
Mentre l’architettura della data mesh si allontana dalla centralizzazione dei data lake, S3 e AWS Lake Formation svolgono un ruolo cruciale nel memorizzare, proteggere e catalogare i dati in transito tra diversi domini, garantendo la conservazione a lungo termine, la governance e il rispetto delle norme.
Event-Driven Data Mesh in Azione con AWS e Python
Event Producer: AWS Kinesis + Python
In questo esempio, usiamo AWS Kinesis per la streaming di eventi quando viene creato un nuovo cliente:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
Event Processing: AWS Lambda + Python
Questa funzione Lambda consuma gli eventi di Kinesis e li processa in tempo reale.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
Conclusione
Tramite l’utilizzo di AWS servizi come Kinesis, Lambda, DynamoDB e Glue, le organizzazioni possono realizzare appieno il potenziale dell’architettura event-driven della data mesh. Questa architettura fornisce agilità, scalabilità e insight in tempo reale, garantendo alle organizzazioni di rimanere competitive nel panorama dati in rapida evoluzione di oggi. Adottare un’architettura event-driven della data mesh non è solo un miglioramento tecnico, ma un imperativo strategico per le aziende che vogliono prosperare nell’era dei grandi dati e dei sistemi distribuiti.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws