













오늘날 데이터 기반의 세계에서, 사업에서는 데이터를 관리, 분석, 이용하는 방법이 빨라지고 변화하는 것에 적응해야 한다. 이전의 중앙ized 시스템과 단일 아키텍처, 과거에는 충분했지만, 더 빨라고 실시간으로 데이터 洞見을 ACCESS 할 수 있는 기 organizatio의 成长的 Demands를 만족시키기에 충분하지 않게 되었다. 이 영역에서 혁명적인 프레임워크로 event-driven data mesh architecture가 있으며, AWS 서비스와 결합되면, 複雑한 데이터 관리 도전을 해결하는 강력한 솔루션이 되는 것이다.
The Data Dilemma
Numerous organizations face significant challenges when relying on outdated data architectures. These challenges include:
Centralized, Monolithic, and Domain Agnostic Data Lake
A centralized data lake is a single storage location for all your data, making it easy to manage and access but potentially causing performance issues if not scaled properly. A monolithic data lake combines all data handling processes into one integrated system, which simplifies setup but can be hard to scale and maintain. A domain-agnostic data lake is designed to store data from any industry or source, offering flexibility and broad applicability but may be complex to manage and less optimized for specific uses.
Traditional Architecture Failure Pressure Points
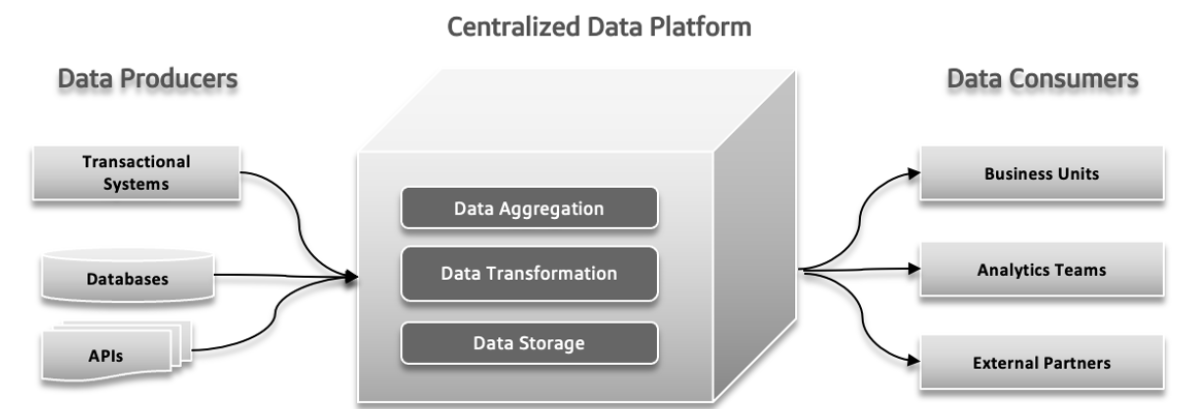
전통적인 데이터 시스템에서는 다양한 문제가 발생할 수 있습니다. 데이터 생성자는 large volumes of data나 에러가 있는 데이터를 보내는 것을 시작하여, downstream에 대한 문제를 일으킵니다. 데이터의 복잡도가 증가하고 더 많은 diverse sources가 시스템에 기여하면, 중앙ized data platform이 增长的 load를 처리하기 어려워 崩壊과 느린 パフォーマン스를 일으킵니다. 빨라게 실험하는 수요가 증가하면, 시스템을 잃어버릴 수 있으며 신观点을 빨라게 적용하고 테스트하는 것이 어려울 수 있습니다. 데이터 응답 시간이 어려움을 일으킵니다. 이를 해결하기 위해서는 결정 과정에서 지연되는 것을 방지하고 데이터를 사용하는 것이 중요합니다.
Operational and Analytical Data Landscapes 之间的分歧
소프트웨어 아키텍처에서, 独自 소유, 데이터 사용이 명확하지 않음, tight coupled data pipelines 및 inherent limitations이 重大な 문제를 일으킵니다. 独自 소유가 발생하면, 다른 团队合作을 시작하여 조치 문제를 일으킵니다. 데이터가 어떻게 사용되거나 공유되어야 하는지 명확하지 않음으로 이를 해결하기 위한 중요성을 가지고 있습니다. 결합된 data pipelines, 어느 요소가 다른 요소에 너무 依存적이라고 해야 합니다. 시스템을 적응하거나 확장하는 것이 어려울 것입니다. 결국, 시스템의 固有한 제한은 새로운 기능과 更新을 제공하는 것을 느리게 하는 것입니다. 이러한 압력 지점을 해결하는 것은 더 이상적인 개발 과정을 만들기 위해 중요합니다.
대량의 데이터에 대한 도전
오픈 소스 기반으로 대량의 데이터를 관리하고 있는 전통적인 데이터 웨어하우스는 ETL(抽出, 変換, 読み込み) 프로세스를 사용하여 이러한 관리를 行います. 대량의 데이터를 处理할 수 있는 대량의 데이터 기술, 예를 들어 Apache Hadoop는 스케일링 문제를 해결하고 오픈 소스이므로 어떠한 기업이나 infraSTRUCTURE를 관리할 수 있다면 이를 사용할 수 있습니다. Hadoop은 predefined schema를 강제하지 않고 unstructured 또는 半構造化된 데이터를 허용하는 새로운 접근法을 introduced하였습니다. 이러한 유연성은 미리 정의 된 schema가 없이 data가 기록되었을 때, 쿼리 실행 시간에 구조화되는 것을 허용합니다. 이러한 유연성은 데이터 엔지니어들이 데이터를 처리하고 인tegrate하는 것을 더 쉽게 만들었습니다. Hadoop을 적용하면 separate data team을 形作成하는 것이 자주 나타나며, data engineers가 data extraction을 처리하고, data scientists가 cleaning과 restructuring을 관리하고, data analysts가 분석을 실시합니다. 이러한 조직 구조는 데이터 团队과 응용 開発자들 사이의 Communication이 제한되어 있으며, 생산 시스템을 영향 주지 않게 하는 것에 주요한 문제가 발생할 수 있습니다.
문제 1: 데이터 모델 경계에 대한 문제
analyze에 사용되는 데이터는 원래의 구조와 멀리 연결되어 있으며, 복잡하고 자주 更新되는 모델에서 문제가 발생할 수 있습니다. 데이터 모델의 변경은 모든 사용자에게 영향을 미칠 수 있으며, 특히 모델이 많은 테이블을 涉及하는 경우에 더욱 敏銳합니다.
Problem 2: Bad Data, The Costs of Ignoring the Problem
Bad data는 구조에 문제를 일으키기 전까지 주로 발견되지 않습니다. 이를 결정하는 과정 끝에 대기하는 것 같은 유효성 검사를 거쳐 나중에 안전하게 처리할 수 있지만, bad data는 Channel을 통해 확산되어 비용이 많이 들고 일관성이 없는 솔루션을 이룰 수 있습니다. Bad data는 billings 오류가 예이 난 수 만큼의 비즈니스 손실을 일으킬 수 있습니다. 조사는 비즈니스에게 årly trillions의 비용을 낚아가며, knowledge workers과 data scientists에게 substantial time를 浪費시키는 것을 보여줍니다.
Problem 3: Lack of Single Ownership
Application developers는 원본 data model에 대한 expert가 되며, 이러한 정보를 다른 팀에게 보고하는 것이 없습니다. 그들의 責任는 대로 적은 응용 프로그램과 데이터베이스 경계에서 끝나며, 이를 관리합니다. Data engineers는 데이터 추출과 이동을 관리하는데 대原因적으로 활동하며 데이터 소스에 대한 제한적인 제어를 가지고 있습니다. Data analysts, 개발자에 멀리 떨어져 있으며, 받은 데이터에 대해 도전을 만들어 조화 문제를 겪게 되며, 분리된 솔루션을 필요로 합니다.
Problem 4: Custom Data Connections
large 조직에서, 여러 团队이 같은 데이터를 사용하면서 그들 자신의 관리 과정을 생성할 수 있습니다. 이로 인해 데이터가 여러 نسخ을 생성하고, 모두 독립적으로 관리되는 것으로 섞여 어리석은 상황이 발생합니다. ETL 과정을 추적하고 데이터 quality를 확보하는 것이 어려워지고, 동기화 문제와 보안성이 떨어지는 데이터 источник 등의 요인에 의해 정확성이 없는 것입니다. 이러한 분산된 접근은 시간, 자원, 기회를 浪費시키는 것입니다.
데이터 메시(Data Mesh)는 이러한 문제를 해결하기 위해 明确的 schema, 문서화, 표준화된 ACCESS를 갖춘 데이터를 제품으로 여기고 나쁜 데이터 ри스크를 줄이고 데이터의 정확성과 효율성을 향상시키ます.
데이터 网格: 현대적 접근法
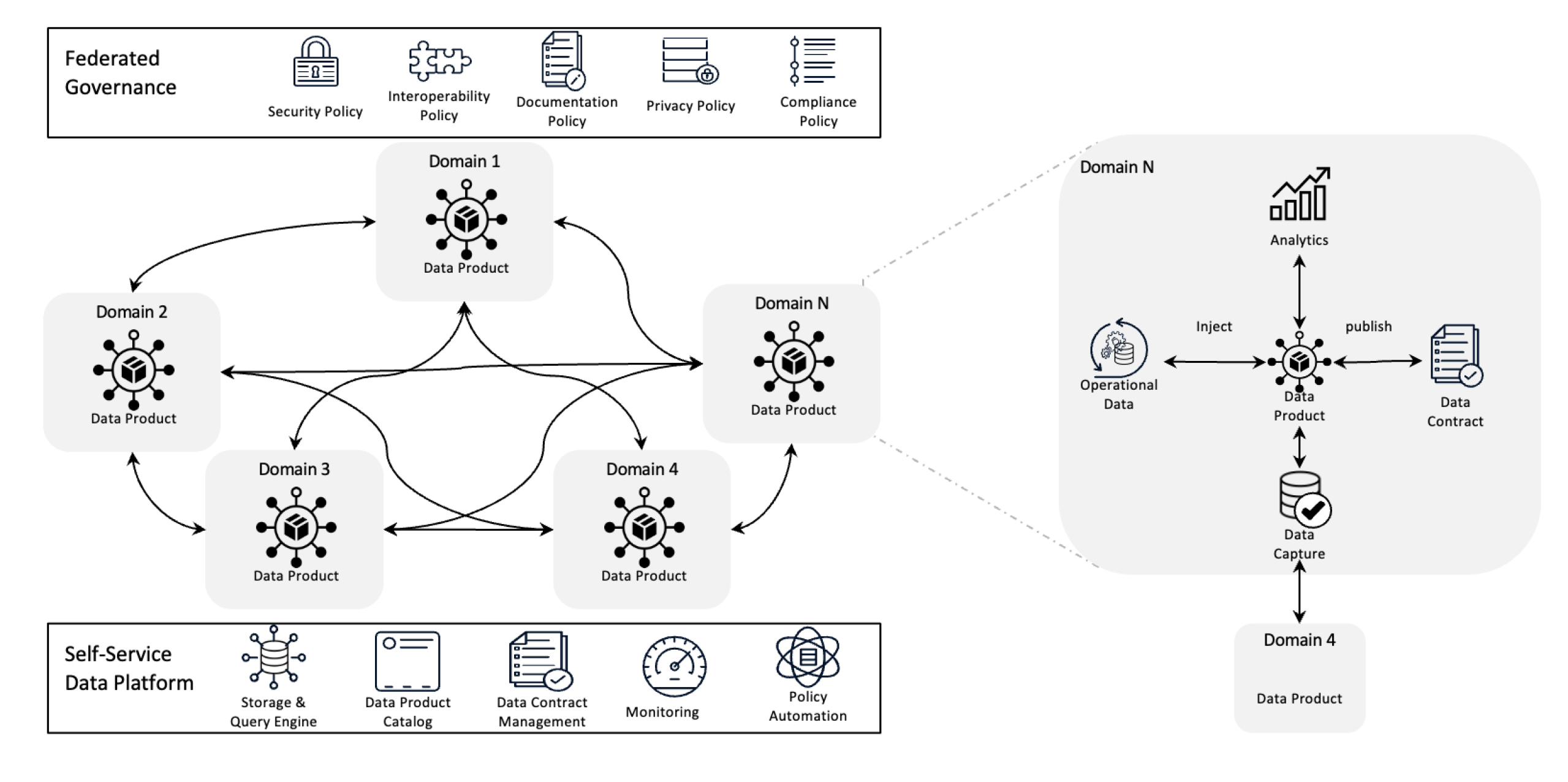
데이터 网格 아키텍처
데이터 网格은 데이터 관리를 去中心化 소유를 통해 데이터를 제품으로 重新정의하고 자自理 인프라를 지원하는 것으로 데이터를 관리합니다. 이러한 전환은 团队이 자신의 데이터를 完全한 제어를 할 수 있게 해줍니다. федератив govrnance는 quality, compliance, 그리고 조직 내에서 확장성을 보장하는 것을 지원합니다.
간단하게 말하자면, 복잡한 데이터 도전을 해결하기 위해 去中心化 소유와 분산화 방법을 사용하는 아키텍처적 fameework입니다. 다양한 사업 영역에서 데이터를 통합하여 comprehensive data analytics를 실행할 수 있습니다. 강한 데이터 sharing과 govrnance 정책을 기반으로 built-on되었습니다.
Data Mesh의 목표를 이해하는 것은 다음과 같습니다.
数据分析网格(Data Mesh)帮助各种组织在规模上获得宝贵的数据洞察;简而言之,它处理不断变化的数据景观、日益增长的数据源和用户数量、所需的数据转换多样性以及快速适应变化的需求。
数据分析网格通过去中心化控制解决了上述所有问题,因此团队可以在不孤立于不同部门的情况下管理自己的数据。这种方法通过分布式数据处理和存储提高了可扩展性,有助于避免单一中央系统的减速。它通过允许团队直接与其自己的数据工作来加速洞察,减少了等待中央团队引起的中断。每个团队都对自己的数据负责,这提高了质量和一致性。通过使用易于理解的数据产品和自助工具,数据分析网格确保所有团队都能快速访问和管理他们的数据,从而加快了更高效运营的速度,并更好地符合业务需求。
数据网格的四大原则
- 去中心化数据所有权:团队拥有和管理他们的数据产品,因此他们对它们的质量和可用性负责。
- 数据即产品:数据被视为具有标准化访问、版本控制和模式定义的产品,确保跨部门的一致性和易用性。
- 联邦治理:建立政策以维护数据完整性、安全和合规性,同时仍允许去中心化所有权。
- 자동 서비스 인프라STRUCTURE: 팀은 스케일 아웃 가능한 인프라스트럫쳐를 사용하여 데이터를 수집, 처리, 및 문제하는 것에 대해 적절한 대처를 제공받으며, 중앙 데이터 팀에 의존하지 않습니다.
이벤트가 데이터 메시를 어떻게 도울까요?
이벤트는 데이터 메시를 도울 수 있습니다. 시스템의 다른 부분들이 실시간으로 데이터를 공유하고 갱신할 수 있도록 도와줍니다. 하나의 영역에서 변화가 생기면, 이벤트가 그 변화에 대한 알림을 다른 영역에게 보냅니다. 따라서 직접적인 연결 없이도 모두가 최신 정보를 얻을 수 있습니다. 이러한 시스템은 더 유연하고 스케일 ability를 가지게 되었습니다. 많은 데이터를 처리하고 대변에 대응할 수 있습니다. 이벤트는 데이터가 어떻게 사용되고 관리되는지 추적하는 것을 더욱 容易하게 만듭니다. 모든 团队이 자신의 데이터를 다른 团队에 의존하지 않고 처리할 수 있습니다.
결국, 이벤트-기반 데이터 메시 구성에 대해 보겠습니다.
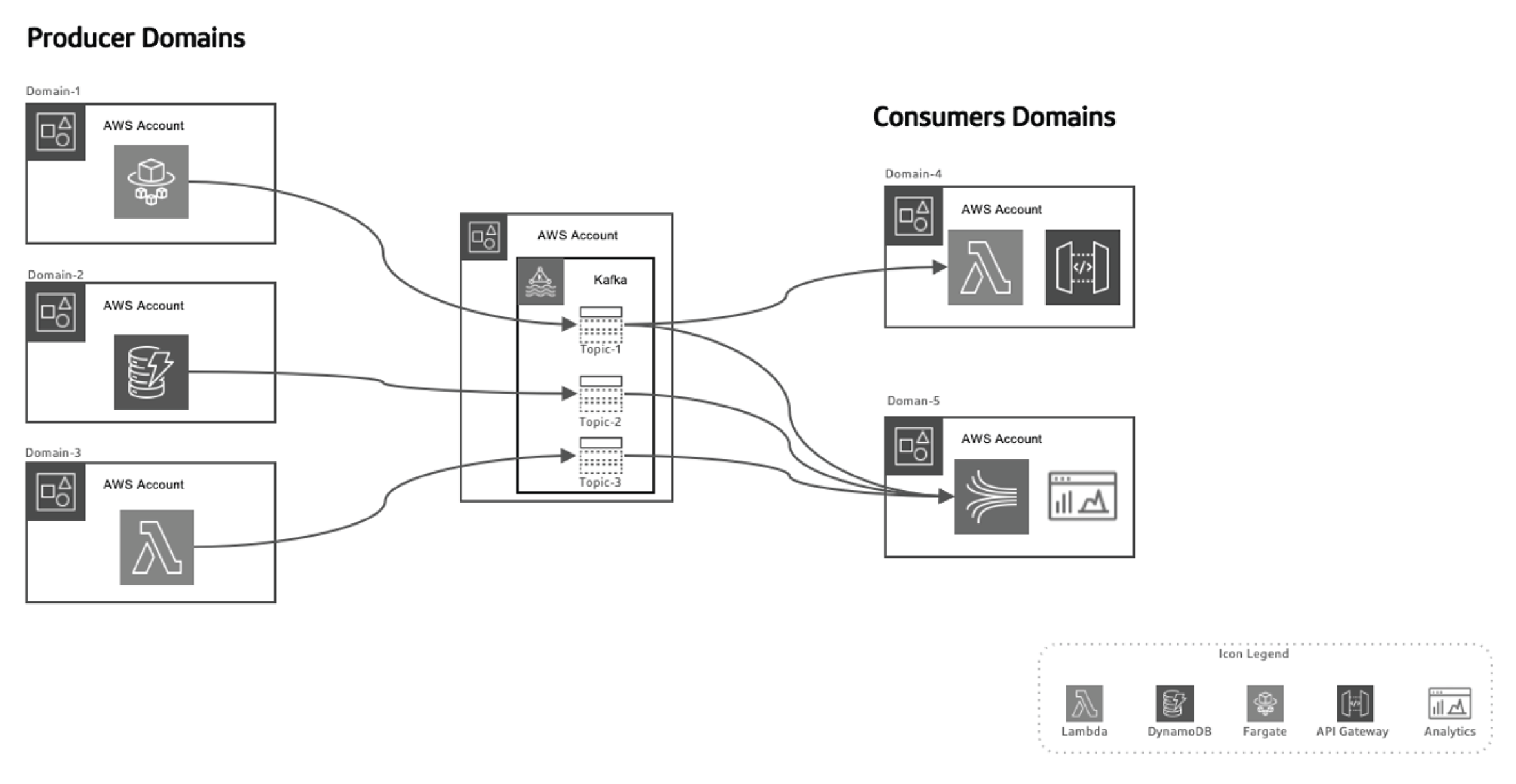
이벤트-기반 접근은 데이터 생성자와 소비자를 분리하여 시스템을 스케일 ability를 향상시키고 시간이 지나면 구조를 大幅하게 변경하지 않고 도메인을 발전시킵니다. 생성자는 이벤트를 생성하는 것에 대 responsibility를 가지며, 이러한 이벤트를 데이터 이전 시스템에 보냅니다. 스reaming 플랫폼은 이러한 이벤트가 안정적으로 전달되도록 보장합니다. 생성자 미리 서비스나 데이터 스토어가 새로운 이벤트를 발행할 때, 특정 주제에 저장됩니다. 이러한 이벤트가 소비자 측에 있는 감시자, 예를 들어 Lambda 함수나 Kinesis를 triggle하여 이벤트를 처리하고 필요하다면 사용합니다.
이벤트-기반 데이터 메시 구성에서 AWS를 사용하는 것을 이용하는 것
AWS는 이벤트 드riven 데이터 网格(data mesh) 모델을 완벽하게 补完하는 서비스 수 JeIrA]를 제공합니다. 기관은 이러한 서비스를 사용하여 데이터 인프라스트럭트를 스케일링, 실시간 데이터 배달을 보장하고 관리와 보안의 고수준을 유지할 수 있습니다.
이러한 구성에서 various AWS services를 어떻게 해석하는지에 대해 기술합니다.
AWS Kinesis for Real-Time Event Streaming
이벤트 드riven 데이터 网格(data mesh) 모델에서, 실시간 스트reaMing은 중요한 요소입니다. AWS Kinesis는 대규모로 실시간 스트reaMing 데이터를 수집, 처리, 분석할 수 있는 기능을 제공합니다.
Kinesis은 다음과 같은 구성 요소를 제공합니다.
- Kinesis Data Streams: 실시간 이벤트를 수집하고 다양한 수용者와 동시에 처리합니다.
- Kinesis Data Firehose: 이벤트 스트reaMing을 S3, Redshift, 或者 Elastic search에 직접 이동하여 추가적인 처리 或者 분석을 수행합니다.
- Kinesis Data Analytics: 실시간에 데이터를 처리하여 现场의 인사이트를 얻는 기능을 제공합니다. 이를 통해 데이터 처리 파이프라인에서 现场的 피드백 루프를 실시간으로 사용할 수 있습니다.
AWS Lambda for Event Processing
AWS Lambda는 이벤트 드riven 데이터 网格(data mesh) 구성에서 서버 less 이벤트 처리의 주요 요소입니다. 자동으로 스케일링하고 이벤트 수신 스트림을 관리하지 않고 처리할 수 있는 기능을 갖추고 있습니다.
Lambda는 다음과 같은 용도로 적용할 수 있습니다.
- Kinesis 스트림을 실시간으로 처리하는 것
- 특정 이벤트에 따라 API 网关 요청을 실행하는 것
- DynamoDB, S3, 或者 다른 AWS 서비스와 이를 통해 데이터를 저장, 처리, 或者 분석하는 것
AWS SNS and SQS for Event Distribution
AWS간편 알림 서비스 (SNS)는 분산 시스템 간에 실시간 알림을 보내는 주요 이벤트 브로드캐스팅 시스템입니다. AWS 간편 대기열 서비스 (SQS)는 분리된 서비스 간의 메시지를 신뢰성 있게 전달하여 부분적인 시스템 장애가 발생해도 안정적으로 작동합니다. 이러한 서비스들은 직접적인 의존성 없이 분리된 마이크로서비스들이 상호작용할 수 있도록 하여 시스템의 확장성과 내결함성을 유지합니다.
실시간 데이터 관리를 위한 AWS DynamoDB
분산 아키텍처에서 DynamoDB는 실시간으로 이벤트 데이터를 저장할 수 있는 확장 가능하고 지연 시간이 낮은 NoSQL 데이터베이스로, 데이터 처리 파이프라인의 결과를 저장하기에 이상적입니다. 애플리케이션에서 생성된 이벤트를 DynamoDB에 저장하고 스트리밍 서비스(Kinesis 또는 Kafka 등)에서 소비하는 Outbox 패턴을 지원합니다.
페더레이티드 데이터 카탈로그 및 ETL을 위한 AWS Glue
AWS Glue는 데이터 메시의 페더레이티드 데이터 거버넌스에 필수적인 완전 관리형 데이터 카탈로그 및 ETL 서비스를 제공합니다. Glue는 분산 도메인에서 데이터를 카탈로그화, 준비화 및 변환하여 조직 전체에서의 발견성, 거버넌스 및 통합을 보장합니다.
데이터 레이크를 위한 AWS Lake Formation 및 S3
数据网格(Data Mesh) 아키텍처가 集中型 데이터 저울(Data Lake)을 离れ는 동시에, S3과 AWS Lake Formation은 다양한 도메인 사이에 흐潺한 데이터를 저장하고, 보호하고, катало그ramming을 실시하는 중요한 역할을 합니다.
AWS와 Python을 사용한 이벤트 기반 데이터 网格(Event-Driven Data Mesh)의 실제 적용
이벤트 생성자: AWS Kinesis + Python
이 예제에서는, 새로 생성된 고객이 있을 때 이벤트를 스트림ming 하기 위해 AWS Kinesis을 사용합니다.
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
이벤트 처리: AWS Lambda + Python
이 Lambda 함수는 Kinesis 이벤트를 소비하고 실시간으로 이를 처리합니다.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
결론
Kinesis, Lambda, DynamoDB, Glue 등 AWS 서비스를 활용하면 이벤트 기반 데이터 网格(Event-Driven Data Mesh) 아키텍처의 가능성을 完全히 실현할 수 있습니다. 이 아키텍тура는 유연성, 스케일ability, 실시간 인사이트를 제공하여 organizations가 현재 빠르게 변화하는 데이터 landscape에서 竞争力을 유지하는 데 도움을 줍니다. 이벤트 기반 데이터 网格(Event-Driven Data Mesh) 아키텍처를 채택하는 것은 仅仅 기술적인 개선이 아닌, 대剂量 데이터 時代과 분산 시스템 시대에서 사업에서 성공하기 위한 전략적인 명령이죠.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws