













Algoritmos de otimização desempenham um papel crucial em aprendizagem profunda: eles ajustam os pesos do modelo para minimizar as funções de perda durante o treinamento. Tal algoritmo é o Otimizador Adam.
O Adam tornou-se extremamente popular em aprendizagem profunda devido à sua capacidade de combinar as vantagens de momento e taxas de aprendizagem adaptativas. Isso o tornou altamente eficiente para o treinamento de redes neurais profundas. Além disso, ele exige o mínimo de ajuste de parâmetros de hipermercado, tornando-o amplamente acessível e eficaz em várias tarefas.
Em 2017, Ilya Loshchilov e Frank Hutter apresentaram uma versão mais avançada do popular algoritmo Adam em seu artigo “Decoupled Weight Decay Regularization.” Eles o chamaram de AdamW, que se destaca por desacoplar a decaimento de peso do processo de atualização de gradientes. Esta separação é uma melhoria crucial em relação ao Adam e ajuda com uma melhor generalização do modelo.
O AdamW tornou-se cada vez mais importante em aplicações modernas de aprendizagem profunda, particularmente no manuseio de modelos em escala large. Sua capacidade superior de regular atualizações de peso contribuiu para sua adoção em tarefas que exigem alto desempenho e estabilidade.
Neste tutorial, vamos abordar as principais diferenças entre o Adam e o AdamW, e os diferentes casos de uso, e vamos implementar um guia passo a passo para a implementação do AdamW emPyTorch.
Adam vs AdamW
Adam e AdamW são ambos optimizadores adaptativos amplamente usados em aprendizagem profunda. A grande diferença entre eles é a forma como eles tratam regularização de pesos, o que impacta sua eficácia em diferentes cenários.
Enquanto o Adam combina momento e taxas de aprendizagem adaptativas para oferecer otimização eficiente, ele incorpora regularização L2 de uma maneira que pode impedir o desempenho. O AdamW resolve isso desacoplando a decréscimo de pesos da atualização da taxa de aprendizagem, oferecendo uma abordagem mais eficaz para modelos grandes e melhorando a generalização. A decréscimo de pesos, uma forma de regularização L2, penaliza pesos grandes no modelo. O Adam incorpora a decréscimo de pesos no processo de atualização de gradiente, enquanto o AdamW a aplica separadamente após a atualização de gradiente
Aqui estão algumas outras maneiras de diferenças entre eles:
Principais diferenças entre Adam e AdamW
Embora ambos os otimizadores sejam projetados para gerenciar o momento e ajustar as taxas de aprendizagem dinamicamente, eles diferem fundamentalmente no seu tratamento da decaimento de peso.
No Adam, o decaimento de peso é aplicado de forma indireta como parte da atualização de gradiente, o que pode modificar acidentalmente as dinâmicas de aprendizagem e interferir no processo de otimização. No entanto, o AdamW separa o decaimento de peso da etapa de gradiente, garantindo que a regularização impacte diretamente os parâmetros sem alterar o mecanismo adaptativo de aprendizagem.
Este design leva a uma regularização mais precisa, ajudando os modelos a generalizar melhor, particularmente em tarefas que envolvem grandes e complexos conjuntos de dados. Como resultado, os dois otimizadores frequentemente têm casos de uso muito diferentes.
Casos de uso para Adam
O Adam tem melhores desempenhos em tarefas onde a regularização é menos crítica ou quando a eficiência computacional é priorizada sobre a generalização. Exemplos incluem:
- Redes Neurais Menores. Para tarefas como a classificação básica de imagens usando pequenas CNNs (Redes Neurais Convolucionais) em conjuntos de dados como o MNIST ou CIFAR-10, onde a complexidade do modelo é baixa, o Adam pode otimizar eficientemente sem precisar de regularização extensa.
- Problemas de regressão simples. Em tarefas de regressão simples com conjuntos de características limitados, como prever preços de casas usando um modelo de regressão linear, o Adam pode convergir rapidamente sem precisar de técnicas de regularização avançadas.
- Prototipagem inicial. Durante as fases iniciais do desenvolvimento do modelo, onde é necessária uma rápida experimentação, o Adam permite iterar rapidamente sobre arquiteturas simples, permitindo que pesquisadores identifiquem problemas sem o overhead de ajustar parâmetros de regularização.
- Dados menos ruidosos. Quando trabalhando com conjuntos de dados limpos com pouco ruído, como dados de texto bem curados para análise de sentimento, o Adam pode aprender padrões efetivamente sem o risco de overfitting que poderia exigir regularização mais pesada.
- Ciclos de treinamento curtos. Em situações com limitações de tempo, como o deploy rápido de modelos para aplicações em tempo real, a otimização eficiente do Adam pode ajudar a entregar resultados satisfatórios rapidamente, mesmo que eles não sejam totalmente otimizados para generalização.
Casos de uso do AdamW
O AdamW se destaca em cenários onde o sobreajuste é um problema e o tamanho do modelo é substancial. Por exemplo:
- Transformadores em escala large-scale. Nas tarefas de processamento de linguagem natural, como a finetuning de modelos como o GPT the grandes corpora de texto, a habilidade do AdamW de gerenciar a atenuação de pesos efetivamente previne o sobreajuste, garantindo melhor generalização.
- Modelos complexos de visão computacional. Para tarefas que envolvem redes neurais convolucionais profundas (CNNs) treinadas em grandes conjuntos de dados como ImageNet, o AdamW ajuda a manter a estabilidade e o desempenho do modelo desacoplando a atenuação de pesos, o que é crucial para alcançar alta precisão.
- Aprendizagem multitarefa. Em cenários onde um modelo é treinado simultaneamente em várias tarefas, o AdamW oferece flexibilidade para lidar com dados diversos e prevenir overfitting em qualquer tarefa única.
- Modelos geradores. Para treinar redes adversárias generativas (GANs), onde manter um equilíbrio entre o gerador e o discriminador é crítico, a melhor regularização do AdamW pode ajudar a estabilizar o treinamento e melhorar a qualidade dos resultados gerados.
- Aprendizado por reforço. Nas aplicações de aprendizado por reforço onde os modelos têm que adaptar-se a ambientes complexos e aprender políticas robustas, o AdamW auxilia a mitigar o overfitting the estados ou ações específicos, melhorando a performance geral do modelo em situações variadas.
Vantagens do AdamW sobre o Adam
Mas por que alguém gostaria de usar o AdamW ao invés do Adam? Simples. O AdamW oferece vários benefícios chave que melhoram seu desempenho, particularmente em cenários de modelagem complexa.
Ele aborda algumas das limitações encontradas no otimizador Adam, tornando-o mais eficaz em optimizações e contribuindo para melhorias no treinamento de modelos e na robustez.
Aqui estão algumas das vantagens destacadas:
- Decuplação do decaimento de peso.Ao separar o decaimento de peso das atualizações de gradiente, o AdamW permite um controle mais preciso sobre a regularização, levando a melhor generalização do modelo.
- Generalização aprimorada. O AdamW reduce o risco de overfitting, especialmente em modelos em larga escala, tornando-o adequado para tarefas que envolvem conjuntos de dados extensos e arquiteturas complexas.
- Estabilidade durante o treinamento. O design do AdamW ajuda a manter a estabilidade ao longo do processo de treinamento, o que é essencial para modelos que requerem cuidadoso ajuste de seus hiperparâmetros.
- Escalabilidade.O AdamW é particularmente eficaz para dimensionar modelos, pois consegue manter a complexidade aumentada de redes profundas sem sacrificar desempenho, permitindo-o ser aplicado em arquiteturas de ponta.
Como o AdamW Funciona
A principal força do AdamW está em sua abordagem à decaimento de peso, que está desacoplando do ajuste adaptativo de gradientes típico do Adam. Essajustificação garante que a regularização seja aplicada diretamente aos pesos do modelo, melhorando a generalização sem afetar negativamente as dinâmicas da taxa de aprendizagem.
O otimizador constrói sobre a natureza adaptativa de Adam, mantendo os benefícios da momento e das ajustes de taxa de aprendizagem por parâmetro. A aplicação de decomposição independente resolve uma das principais deficiências de Adam: sua tendência de afetar as atualizações de gradientes durante a regularização. Essa separação permite que AdamW mantenha uma aprendizagem estável, mesmo em modelos complexos e em larga escala, enquanto mantém sob controle o overfitting.
Nas seções seguintes, exploraremos a teoria por trás da decomposição de peso e da regularização e a matemática que sustenta o processo de otimização de AdamW.
Teoria por Trás da Decomposição de Peso e da Regularização L2
A regularização L2 é uma técnica usada para evitar o overfitting. Ela alcança esse objetivo adicionando uma penalidade à função de perda, desencorajando valores de peso grandes. Esta técnica ajuda a criar modelos simples que generalizam melhor para novos dados.
Em optimizadores tradicionais, como o Adam, a decaimento de peso é aplicado como parte da atualização de gradiente, o que acidentalmente afeta as taxas de aprendizagem e pode levar a desempenhos subótimos.
O AdamW melhora isso ao desacoplar o decaimento de peso da computação de gradiente. Em outras palavras, em vez de aplicar o decaimento de peso durante a atualização de gradiente, o AdamW o trata como um passo separado, aplicando-o diretamente aos pesos após a atualização de gradiente. Isso evita que o decaimento de peso interfira no processo de otimização, levando a treinamentos mais estáveis e melhor generalização.
Fundação Matemática do AdamW
O AdamW modifica o optimizador Adam tradicional alterando a forma como o decaimento de peso é aplicado. As equações centrais para o AdamW podem ser representadas da seguinte forma:
- Momento e taxa de aprendizagem adaptativa:Similarmente a Adam, o AdamW usa momento e taxas de aprendizagem adaptativas para calcular atualizações de parâmetros com base nas médias移动as de gradientes e gradientes quadrados.
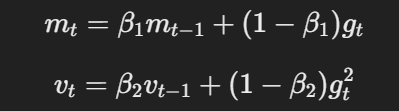
A equação para momentum e taxa de aprendizagem adaptativa
- Estimativas corretas de bias:As primeiras e segundas estimativas de momento são corrigidas para o bias usando o seguinte:
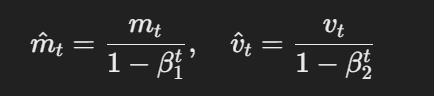
A fórmula para estimativas corretas de bias
- Atualização de parâmetro com decaimento de peso desacoplando:No AdamW, o decaimento de peso é aplicado diretamente aos parâmetros após a atualização da gradiente. A regra de atualização é:
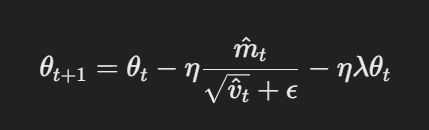
Atualização de parâmetro com decaimento de peso desacoplando
Aqui, η é a taxa de aprendizagem, λ é o fator de decaimento de peso, e θt representa os parâmetros. Este termo de decaimento de peso desacoplado λθt garante que a regularização é aplicada independentemente da atualização da gradiente, que é a diferença chave em relação ao Adam.
Implementação do AdamW em PyTorch
Implementar AdamW em PyTorch é fácil; este tópico fornece um guia completo para configurá-lo. Siga com estas etapas para aprender a finetune modelos com eficiência com o Otimizador Adam.
Um guia passo a passo para AdamW em PyTorch
Nota: este tutorial pressupõe que você já instalou o PyTorch. Consulte aDocumentação para qualquer orientação.
Passo 1: Importar as bibliotecas necessárias
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
Passo 2: Definir o modelo
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
Passo 3: Configurar os hiperparâmetros
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # número de épocas
Passo 4: Inicializar o otimizador AdamW e configurar a função de perda
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
Voilà!
Agora, você está pronto para começar a treinar o seu modelo de CNN, e é isso que faremos na próxima seção.
Exemplo Prático: Ajustando um Modelo Usando AdamW
A cima, nós definimos o modelo, definimos os hiperparâmetros, inicializamos o otimizador (AdamW), e configuramos a função de perda.
Para treinar o modelo, precisaremos de importar alguns módulos adicionais;
from torch.utils.data import DataLoader # fornece um iterável do conjunto de dados import torchvision import torchvision.transforms as transforms
A seguir, defina o conjunto de dados e os dataloaders. Para este exemplo, nós usaremos o conjunto de dados CIFAR-10:
# Define transformações para o conjunto de treinamento transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # Carregar conjunto de dados CIFAR-10 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # Criar carregadores de dados train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
Como já definimos o nosso modelo, a próxima etapa é implementar o laço de treinamento para otimizar o modelo usando AdamW.
Eis como isso se parece:
for epoch in range(num_epochs): model.train() # Definir o modelo para o modo de treinamento running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # Limpar gradientes outputs = model(inputs) # Passo de frente loss = criterion(outputs, labels) # Calcular perda loss.backward() # Passo de trás optimizer.step() # Atualizar pesos running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
A última etapa é validar o desempenho do modelo no conjunto de dados de validação que criamos anteriormente.
Aqui está o código:
model.eval() # Defina o modelo em modo de avaliação correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # Passo de frente _, predicted = torch.max(outputs.data, 1) # Obtenha a classe predita total += labels.size(0) # Atualize amostras totais correct += (predicted == labels).sum().item() # Atualize predições corretas accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
E pronto, é assim que você implementa AdamW em PyTorch.
Você agora sabe como implementar AdamW em PyTorch.
Casos de Uso Comuns para AdamW
Ok, nós estabeleceram que AdamW ganhou popularidade devido à sua melhor gestão de decaimento de peso do que o seu antecessor, Adam.
Mas, qual são alguns casos de uso comuns para este otimizador?
Vamos entrar nisto na seção…
Modelos de Aprendizagem Profunda em Scala
O AdamW é particularmente benéfico na treinamento de modelos grandes, como o BERT, GPT e outras arquiteturas de transformadores. Esses modelos normalmente têm milhões ou até biliões de parâmetros, o que muitas vezes significa que exigem algoritmos de otimização eficientes que lidam com atualizações de peso complexas e desafios de generalização.
Tarefas de Visão Computacional e Processamento de Linguagem Natural
O AdamW tornou-se o otimizador de escolha em tarefas de visão computacional envolvendo CNNs e tarefas de processamento de linguagem natural envolvendo transformadores. Sua capacidade de prevenir sobreajuste torna-o ideal para tarefas envolvendo grandes conjuntos de dados e arquiteturas complexas. A desacoplação de decaimento de peso significa que o AdamW evita os problemas encontrados por Adam emsobreregularizar modelos.
Ajuste de Hiperparâmetros no AdamW
Ajuste de hiperparâmetros é o processo de selecionar as melhores configurações para parâmetros que governam o treinamento de um modelo de aprendizagem automática, mas que não são aprendidas a partir dos dados em questão. Esses parâmetros influenciam diretamente como o modelo otimiza e converge.
O ajuste adequado desses hiperparâmetros no AdamW é fundamental para alcançar treinamento eficiente, evitar overfitting e garantir que o modelo generaliza bem para dados não vistos.
Nesta seção, exploraremos como finetuning os chave hiperparâmetros de AdamW para o desempenho ótimo.
Práticas recomendadas para escolha de taxas de aprendizagem e decaimento de peso
A taxa de aprendizagem é um hiperparâmetro que controla quanto ajustar os pesos do modelo em relação à gradiente de perda durante cada passo de treinamento. Uma taxa de aprendizagem alta acelera o treinamento, mas pode causar o modelo a ultrapassar os pesos ótimos, enquanto uma taxa baixa permite ajustes mais finos mas pode tornar o treinamento lento ou atolado em mínimos locais.
Decréscimo de peso, por outro lado, é uma técnica de regularização usada para evitar sobreajuste penalizando pesos grandes no modelo. Nomeadamente, o decréscimo de peso adiciona uma pequena penalidade proporcional ao tamanho dos pesos do modelo durante o treinamento, ajudando a reduzir a complexidade do modelo e melhorar a generalização para novos dados.
Para escolher taxas de aprendizagem e valores de decréscimo de peso ótimos para AdamW:
- Comece com uma taxa de aprendizagem moderada – Para o AdamW, uma taxa de aprendizagem em torno de 1e-3 é frequentemente um bom ponto de partida. Você pode ajustá-la com base na convergência do modelo, abaixando-a se o modelo ter dificuldade em convergir ou aumentando-a se o treinamento for muito lento.
- Experimente com decaimento de peso. Comece com um valor em torno de 1e-2 a 1e-4, dependendo do tamanho do modelo e do conjunto de dados. Um decaimento de peso ligeiramente maior pode ajudar a prevenir o overfitting para modelos maiores e complexos, enquanto modelos pequenos podem precisar de menos regularização.
- Use programação de taxa de aprendizagem. Implemente programações de taxa de aprendizagem (como decaimento de passo ou anelhamento cosseno) para reduzir dinamicamente a taxa de aprendizagem conforme a treinagem avança, ajudando o modelo a finetune seus parâmetros conforme se aproxima da convergência.
- Monitore desempenho. Monitore constantemente o desempenho do modelo no conjunto de validação. Se você observar overfitting, considere aumentar o decaimento de peso, ou se o perda de treinamento estiver estagnando, reduza a taxa de aprendizagem para melhor otimização.
Pensamentos finais
AdamW tornou-se um dos melhores otimizadores em aprendizado profundo, especialmente para modelos em escalas grandes. Isto é devido à sua capacidade de desacoplar a decaimento de peso de atualizações de gradiente. Nomeadamente, o design do AdamW melhora a regularização e ajuda os modelos a generalizar melhor, particularmente quando se trata de arquiteturas complexas e conjuntos de dados extensos.
Como demonstrado neste tutorial, a implementação do AdamW em PyTorch é fácil – só é necessário algumas mudanças de Adam. No entanto, a ajuste de hiperparâmetros permanece um passo crucial para maximizar a eficácia do AdamW. Encontrar o equilíbrio certo entre a taxa de aprendizagem e o decaimento de peso é essencial para garantir que o otimizador funcione eficientemente sem sobreajustar ou subajustar o modelo.
Agora você sabe o suficiente para implementar AdamW em seus próprios modelos. Para continuar seu aprendizado, consulte algumas dessas fontes:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch