













Introdução
Métodos de interpretabilidade de modelos têm ganhado cada vez mais importância ao longo dos anos, como consequência direta do aumento na complexidade dos modelos e a falta de transparência associada. A compreensão do modelo é um tópico de estudo quente e um foco para aplicações práticas que empregam aprendizagem automática em diversos setores.
Captum fornece a acadêmicos e desenvolvedores técnicas de ponta, como o Gradiente Integrado, que tornam fácil identificar os elementos que contribuem para a saída do modelo. Captum torna mais fácil para os pesquisadores de ML usar modelos PyTorch para construir métodos de interpretabilidade.
Ao tornar mais fácil identificar muitos elementos que contribuem para a saída do modelo, o Captum pode ajudar os desenvolvedores de modelos a criar melhores modelos e corrigir modelos que fornecem resultados não esperados.
Descrições de Algoritmos
O Captum é uma biblioteca que permite a implementação de vários métodos de interpretabilidade. É possível classificar os algoritmos de atribuição de Captum em três categorias amplas:
- atribuição primária: Determina a contribuição de cada feature de entrada para a saída do modelo.
- Autorias de Camadas: Cada neurônio em uma camada particular é avaliado quanto à sua contribuição para a saída do modelo.
- Autorias de Neurônios: A ativação de um neurônio oculto é determinada avaliando a contribuição de cada característica de entrada.
A seguir, há uma breve visão geral dos vários métodos que são atualmente implementados no Captum para atribuição primária, de camada e de neurônio. Também é incluída uma descrição do túnel de ruído, que pode ser usado para suavizar os resultados de qualquer método de atribuição.
O Captum fornece métricas para estimar a confiabilidade das explicações do modelo, além de seus algoritmos de atribuição. Atualmente, eles fornecem métricas de infidelidade e sensibilidade que auxiliam a avaliar a precisão das explicações.
Técnicas de Atribuição Primária
Gradientes Integrados
Vamos dizer que temos uma representação formal de uma rede profunda, F : Rn → [0, 1].
Vamos dizer que x ∈ Rn é o input atual e x′ ∈ Rn é o input de base.
A linha de base em redes de imagem pode ser a imagem preta, enquanto que pode ser o vetor de embeddings zero em modelos de texto.
Da linha de base x′ para o input x, computamos as gradientes em todos os pontos ao longo do caminho reto (em Rn). Ao acumular essas gradientes, é possível gerar gradientes integrados. Gradientes integrados são definidos como o integral de gradientes ao longo de uma caminho direto da linha de base x′ para o input x.
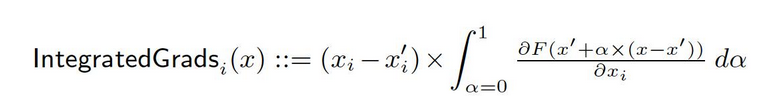
As duas suposições básicas, sensibilidade e invariança de implementação, formam a base deste método. Consulte o artigo original para saber mais sobre esses axiomas.
Gradiente SHAP
Valores de Shapley em teoria de jogos cooperativos são usados para calcular os valores de Gradient SHAP, que são calculados usando uma abordagem de gradiente. Gradient SHAP adiciona ruído gaussiano a cada amostra de entrada várias vezes, depois escolhe um ponto aleatório no caminho entre o baseline e a entrada para determinar o gradiente das saídas. Como resultado, os valores finais de SHAP representam a média esperada dos gradientes. * (entradas – baseline). Os valores de SHAP são aproximados com a premissa de que as features de entrada são independentes e que o modelo explicativo é linear entre as entradas e os baseline fornecidos.
DeepLIFT
É possível usar DeepLIFT (uma técnica de propagação reversa) para atribuir mudanças de entrada baseadas nas diferenças entre entradas e suas referências correspondentes (ou base). O DeepLIFT tenta explicar a disparidade entre a saída da referência usando a disparidade entre as entradas da referência. O DeepLIFT emprega a ideia de multiplicadores para “culpar” neurônios individuais pela diferença nas saídas. Para um dado neurônio de entrada x com diferença da referência ∆x, e um neurônio alvo t com diferença da referência ∆t que queremos computar a contribuição para, definimos o multiplicador m∆x∆t como:
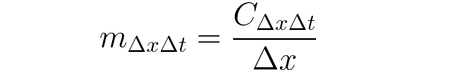
DeepLIFT SHAP
DeepLIFT SHAP é uma extensão do DeepLIFT baseada nos valores de Shapley estabelecidos na teoria de jogos cooperativos. O DeepLIFT SHAP calcula a atribuição de DeepLIFT para cada par de entrada-base e divide a média das atribuições resultantes por exemplo de entrada usando uma distribuição de bases. As regras não-linearidade do DeepLIFT ajudam a linearizar as funções não-lineares da rede, e a aproximação dos valores de SHAP também se aplica à rede linearizada. As características de entrada são presumidas independentes neste método.
Saliência
Ao calcular a atribuição de entrada via saliência, o processo é simples e resulta na gradiente da saída em relação à entrada. Uma expansão de primeiro grau de rede de Taylor é usada na entrada, e as gradientes são os coeficientes de cada característica na representação linear do modelo. O valor absoluto destes coeficientes pode ser usado para indicar a relevância de uma característica. Você pode encontrar informações adicionais sobre o método de saliência no artigo original.
Entrada X Gradiente
Gradiente de Entrada X é uma extensão do método de saliência, que considera os gradientes da saída em relação à entrada e multiplica-os pelos valores de features de entrada. Uma intuição para este método considera um modelo linear; os gradientes são basicamente os coeficientes de cada entrada, e a multiplicação da entrada por um coeficiente corresponde à contribuição total da feature para a saída do modelo linear.
Backpropagation Guiada e Deconvolução
A computação de gradientes é realizada através de backpropagation guiada e deconvolução, embora a backpropagation de funções ReLU seja substituída para que apenas gradientes não negativos sejam propagados de volta. Enquanto a função ReLU é aplicada aos gradientes de entrada na backpropagation guiada, ela é aplicada diretamente aos gradientes de saída na deconvolução. É prática comum utilizar esses métodos em conjunto com redes convolucionais, mas eles também podem ser usados em outras arquiteturas de rede neural.
Guided GradCAM
A atribuição de backpropagation guiada calcula o produto elemento a elemento das atribuições de guided GradCAM (guided GradCAM) com as atribuições (camada) GradCAM upsampled. A computação de atribuições é feita para uma camada dada e upsampled para caber na dimensão de entrada. As redes neurais convolucionais são o foco desta técnica. No entanto, qualquer camada que possa ser espacialmente alinhada com a entrada pode ser fornecida. Normalmente, a última camada convolucional é fornecida.
Feature Ablation
Para computar atribuições, uma técnica conhecida como “feature ablation” usa um método baseado em perturbação que substitui um “padrão de referência” ou “valor de referência” conhecido (como 0) por cada feature de entrada antes de computar a diferença no saída. Agrupar e ablatar features de entrada é uma alternativa melhor do que fazê-lo individualmente, e muitas aplicações diferentes podem beneficiar disto. Agrupando e ablatando segmentos de uma imagem, podemos determinar a importância relativa do segmento.
Permutação de Funções
Permutação de funções é um método baseado em perturbação no qual cada função é permutada aleatoriamente dentro de um lote, e a mudança na saída (ou perda) é calculada como resultado desta modificação. As funções também podem ser agrupadas juntas, em vez de individualmente, da mesma forma que a ablação de funções. Note que, em contraste com os outros algoritmos disponíveis em Captum, este algoritmo é o único que pode fornecer atribuições apropriadas quando fornecido com um lote de vários exemplos de entrada. Outros algoritmos precisam de apenas um exemplo de entrada.
Ocultação
Ocultação é uma abordagem baseada em perturbação para calcular atribuições, substituindo cada região retangular contínua com um baseline/referência dado e calculando a diferença na saída. Para funções localizadas em várias áreas (hypérrertangulos), as diferenças de saída correspondentes são calculadas para computar a atribuição para essa função. A ocultação é mais útil em casos como imagens, onde os pixels em uma região retangular contínua são provavelmente altamente correlacionados.
Amostragem do Valor de Shapley
A técnica de atribuição Valor de Shapley é baseada na teoria de jogos cooperativos. Esta técnica considera cada permutação dos atributos de entrada e os adiciona um por um a um baseline específico. A diferença na saída após a adição de cada atributo corresponde à sua contribuição, e essas diferenças são somadas em todas as permutações para determiná-la.
Lime
Um dos métodos de interpretabilidade mais amplamente usados é o Lime, que treina um modelo substituto interpretável amostrando pontos de dados em volta de um exemplo de entrada e usando avaliações de modelo nestes pontos para treinar um modelo “substituto” mais simples, como um modelo linear.
KernelSHAP
Kernel SHAP é uma técnica para calcular os Valores de Shapley que usa o framework LIME. Os Valores de Shapley podem ser obtidos de forma mais eficiente no framework LIME, definindo a função de perda, ponderando o kernel e regularizando adequadamente as expressões.
Técnicas de Atribuição de Camadas
Condução de Camadas
A Condução de Camadas é uma metodologia que constrói uma imagem mais abrangente da importância de uma neurônica, combinando a ativação da neurona com as derivadas parciais tanto da neurona em relação à entrada quanto da saída em relação à neurona. Através da neurona oculta, a condução constrói sobre o fluxo de atribuição de Integrated Gradients (IG). A condução total de uma neurona oculta y é definida da seguinte forma no artigo original:
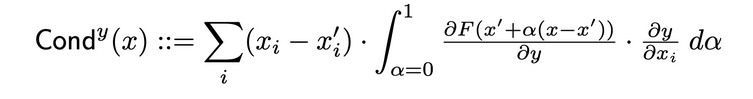
Influência Interna
Usando o Influência Interna, é possível estimar a integral das gradientes ao longo do caminho de uma entrada de base para a entrada fornecida. Esta técnica é semelhante a aplicar gradientes integrados, que envolve integrar a gradientes em relação à camada (em vez da entrada).
Gradiente de Camada X Ativação
Gradiente de Camada X Ativação é a versão da rede do método de Input X Gradiente para camadas ocultas em uma rede…
Ele multiplica a ativação do elemento da camada por elemento com as gradientes do alvo de saída em relação à camada especificada.
GradCAM
GradCAM é uma técnica de atribuição de camadas de rede convolucional que geralmente é aplicada à última camada convolucional. O GradCAM calcula as gradientes do alvo de saída em relação à camada especificada, calcula a média de cada canal de saída (dimensão de saída 2) e multiplica a média de gradientes de cada canal pela ativação da camada. Uma função ReLU é aplicada à saída para garantir que apenas atribuições não-negativas são retornadas da soma dos resultados em todos os canais.
Técnicas de Atribuição de Neurônios
Condutância de Neurônios
Condutância combina ativação de neurônio com as derivadas parciais tanto do neurônio em relação à entrada quanto do resultado em relação ao neurônio, fornecendo uma visão mais abrangente da relevância do neurônio. Para determinar a condutância de um neurônio específico, se examina o fluxo de atribuição de IG de cada entrada que passa por esse neurônio. A seguir está a definição formal de condutância do neurônio y dada a atribuição de entrada i do artigo original:
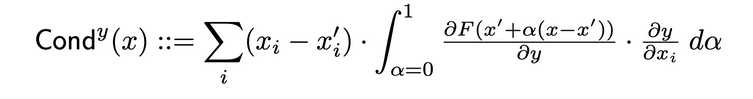
De acordo com essa definição, deve-se notar que a soma da condutância de um neurônio (para todas as características de entrada) é sempre igual à condutância da camada na qual esse neurônio específico está localizado.
Gradiente de Neurônio
A abordagem gradiente de neurônio é o equivalente à abordagem de saliência para um neurônio único na rede. Ela simplesmente calcula o gradiente do saída de neurônio em relação à entrada do modelo. Este método, como a Saliência, pode ser considerado como fazendo uma expandimento de Taylor de primeira ordem da saída do neurônio no ponto de entrada dado, com os gradientes correspondendo aos coeficientes de cada característica na representação linear do modelo.
Gradientes Integrados de Neurônio
É possível estimar a integral dos gradientes de entrada em relação a um determinado neurônio ao longo da caminho de um input de base para o input de interesse usando uma técnica chamada de “Gradientes Integrados de Neurônio.” Gradientes integrados são equivalentes a este método, assumindo que a saída é apenas a de neurônio identificado. Você pode encontrar informações adicionais sobre a abordagem de gradientes integrados no artigo original aqui.
GradienteSHAP de Neurônio
O Neuron GradientSHAP é o equivalente do GradientSHAP para um neurônio específico. O Neuron GradientSHAP adiciona ruído Gaussiano a cada amostra de entrada várias vezes, escolhe um ponto aleatório ao longo do caminho entre o baseline e a entrada e calcula o gradiente do neurônio alvo em relação a cada ponto escolhido aleatoriamente.
Os valores SHAP resultantes são semelhantes aos valores de gradiente predito *. (entradas – baselines).
Neuron DeepLIFT SHAP
O Neuron DeepLIFT SHAP é o equivalente do DeepLIFT para um neurônio específico. Usando a distribuição de baseline, o algoritmo DeepLIFT SHAP calcula a atribuição de Neuron DeepLIFT para cada par entrada-baseline e divide os resultados de atribuição por exemplo de entrada.
Túnel de Ruído
Túnel de Ruído é uma técnica de atribuição que pode ser usada em conjunto com outros métodos. O túnel de ruído calcula atribuição várias vezes, adicionando ruído Gaussiano à entrada cada vez, e então junta as atribuições resultantes dependendo do tipo escolhido. Os seguintes tipos de túnel de ruído são suportados:
- Smoothgrad: Retorna a média das atribuições amostradas. A suavização da técnica de atribuição especificada usando um kernel gaussiano é uma aproximação deste processo.
- Smoothgrad Quadrado: Retorna a média das atribuições amostradas quadradas.
- Vargrad: Retorna a variância das atribuições de amostra.
Métricas
Infidelidade
Infidelidade mede a média quadrada dos erros entre as explicações de modelos nas magnitude de perturbações de entrada e as mudanças da função preditora nestas perturbações de entrada. A infidelidade é definida da seguinte forma:
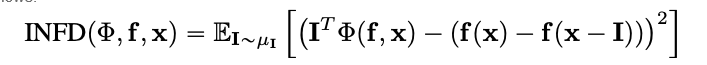
A partir das técnicas de atribuição bem conhecidas, como o gradiente integrado, isso é um conceito mais eficiente computacionalmente e estendido de Sensitivy-n. O último analisa as correlações entre a soma das atribuições e as diferenças da função preditora em seu ponto de entrada e num ponto de referência padrão.
Sensibilidade
Sensibilidade, que é definida como o grau de mudança da explicação causada por pequenas perturbações nas entradas usando a aproximação baseada em amostragem de Monte Carlo, é medida da seguinte forma:

Por padrão, nós amostramos the um subespaço de uma esfera de L-Infinity com um raio padrão para aproximar a sensibilidade. Os usuários podem alterar o raio da esfera e a função de amostragem.
Interpretação de Modelos para Modelo ResNet Pré-treinado
Este tutorial mostra como usar métodos de interpretabilidade de modelos the um modelo ResNet pré-treinado com uma imagem escolhida, e visualiza as atribuições para cada pixel sobrepostas na imagem. Neste tutorial, usaremos os algoritmos de interpretação Integrated Gradients, GradientShape, Attribution com GradCAM de Camada e Occlusion.
Antes de começar, você deve ter um ambiente Python que inclua:
- Versão do Python 3.6 ou superior
- Versão do PyTorch 1.2 ou superior (a versão mais recente é recomendada)
- Versão do TorchVision 0
- .6 ou superior (a versão mais recente é recomendada)
- Captum (a versão mais recente é recomendada)
Dependendo de se você está usando o ambiente virtual Anaconda ou pip, as seguintes instruções ajudarão você a configurar o Captum:
Com conda:
conda install pytorch torchvision captum -c pytorch
Com pip:
pip install torch torchvision captum
Vamos importar as bibliotecas.
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
Carrega o modelo ResNet treinado e o coloca no modo de avaliação
model = models.resnet18(pretrained=True)
model = model.eval()
O ResNet está treinado no conjunto de dados ImageNet. Baixa e le a lista de classes/etiquetas do conjunto de dados ImageNet em memória.
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
Agora que terminamos o modelo, podemos baixar a imagem para análise.

A pasta de imagens deve conter o arquivo cat.jpg. Como podemos ver abaixo, Image.open() abre e identifica o arquivo de imagem fornecido e np.asarray() o converte em um array.
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
No código abaixo, definiremos transformadores e funções de normalização para a imagem. Para treinar o nosso modelo ResNet, usamos o conjunto de dados ImageNet, o que exige que as imagens sejam de um tamanho particular, com os dados de canal normalizados a um intervalo de valores especificado. transforms.Compose() compõe várias transformações juntas e transforms.Normalize() normaliza uma imagem de tensor com média e desvio padrão.
# expectativa de modelo é uma imagem de 224x224 cores três
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# normalização ImageNet
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
#unsqueeze retorna um novo tensor com uma dimensão de tamanho um inserido na posição especificada.
input = input.unsqueeze(0)
Agora, vamos prever a classe da imagem de entrada. A questão que pode ser colocada é: “O que o nosso modelo acha que essa imagem representa?”
#chamar o nosso modelo
output = model(input)
## aplicar função softmax()
output = F.softmax(output, dim=1)
#torch.topk retorna os k elementos maiores do tensor de entrada dado along a dimensão dada. K aqui é 1
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
#converter em um dicionário de pares chave-valor do rótulo de previsão, convertê-lo em uma string para obter o rótulo predito
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
saída:
Predicted: tabby ( 0.5530276298522949 )
Agora, o facto de o ResNet acharmos que a imagem de um gato representa um gato real está confirmado. Mas o que dá ao modelo a impressão de que isto é uma imagem de um gato? Para obter a solução para essa questão, vamos consultar o Captum.
Atribuição de Funcionalidades com Gradientes Integrados
Uma das várias técnicas de atribuição de funcionalidades em Captum é o Gradientes Integrados. Os Gradientes Integrados atribuem uma pontuação de relevância a cada features de entrada estimando o integral dos gradientes do output do modelo em relação a entradas.
Para o nosso caso, nós iremos pegar um componente particular do vetor de saída – o que indica a confiança do modelo em sua categoria selecionada – e usar os gradientes integrados para descobrir quais aspectos da imagem de entrada contribuíram para essa saída. Isso nos permitirá determinar quais partes da imagem foram as mais importantes na produção deste resultado.
Após obtermos o mapa de importância de Gradientes Integrados, nós usaremos as ferramentas de visualização capturadas por Captum para fornecer uma representação clara e compreensível do mapa de importância.
Os Gradientes Integrados calcularão a integral dos gradientes do output do modelo para a classe predita pred_label_idx com relação aos pixeis da imagem de entrada ao longo do caminho da imagem preta até nossa imagem de entrada.
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
#Criar objeto Gradientes Integrados e obter atributos
integrated_gradients = IntegratedGradients(model)
#Solicitar ao algoritmo que atribua nosso alvo de saída
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
Saída:
Predicted: tabby ( 0.5530276298522949 )
Vamos ver a imagem e as atribuições que vêm com ela, sobrepondo as últimas na imagem. O método visualize_image_attr() que Captum oferece fornece uma série de possibilidades para personalizar a apresentação dos dados de atribuição às suas preferências. Aqui, passamos uma cor mapa personalizado Matplotlib (veja LinearSegmentedColormap()).
Visualização de resultados com mapa de cores personalizado
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
# Use o método auxiliar visualize_image_attr para visualização para mostrar a # imagem original para comparação
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
Output:
Você deveria conseguir notar na imagem que mostramos acima que a área em volta do gato na imagem é onde o algoritmo Integrated Gradients dá-nos o sinal mais forte.
Vamos calcular atribuições usando o Integrated Gradients e então suavizá-las em várias imagens que foram produzidas por um túnel de ruído.
O último modifica a entrada adicionando ruído gaussiano com uma desvio padrão de um, 10 vezes (nt_samples=10). A abordagem smoothgrad_sq é usada pelo túnel de ruído para tornar as atribuições consistentes em todos os smoothgrad_sq valores de atribuição média de atribuições quadradas em nt_samples amostras. visualize_image_attr_multiple() visualiza as atribuições para uma imagem dada normalizando os valores de atribuição de um sinal específico (positivo, negativo, valor absoluto ou todos) e então exibindo-os em uma figura matplotlib usando o modo selecionado.
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
Output:

Posso ver nas imagens acima que o modelo se concentra na cabeça do gato.
Vamos finalizar usando GradientShap. GradientShap é uma abordagem de gradiente que pode ser usada para calcular valores SHAP e também é uma ferramenta excelente para obter insights sobre o comportamento global. É um modelo de explicação linear que explica as previsões do modelo usando uma distribuição de amostras de referência. Determina as gradientes esperadas para uma entrada escolhida aleatoriamente entre a entrada e um baseline.
O baseline é escolhido aleatoriamente a partir da distribuição de baselines fornecida.
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
# Definição da distribuição de baseline de imagens
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
Saída:

Atribuição de Camada com GradCAM
Você pode relacionar a atividade das camadas ocultas dentro do seu modelo a características de sua entrada com a ajuda da Atribuição de Camadas.
Nós aplicaremos um algoritmo de atribuição de camadas para investigar a atividade de uma das camadas convolucionais incluídas em nosso modelo.
O GradCAM é responsável por calcular as gradientes da saída alvo em relação à camada especificada. Estes gradientes são então calculados para cada canal de saída (dimensão 2 da saída), e as ativações da camada são multiplicadas pelo gradiente médio para cada canal.
Os resultados são somados para todos os canais. Como a atividade das camadas convolucionais frequentemente se mapeia espacialmente para a entrada, as atribuições GradCAM são frequentemente upsampled e usadas para mascarar a entrada. Note que o GradCAM é explicitamente desenvolvido para redes neurais convolucionais (convnets). A atribuição de camadas é configurada da mesma forma que a atribuição de entrada, com a exceção de que, além do modelo, você deve fornecer uma camada oculta dentro do modelo que você deseja analisar. Similar a aquilo que foi discutido anteriormente, quando chamamos attribute(), indicamos a classe de interesse do alvo.
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
Para fazer uma comparação mais precisa entre a imagem de entrada e esses dados de atribuição, nós vamos upsampling com ajuda da função interpolate(), localizada na classe base LayerAttribution.
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
Output:
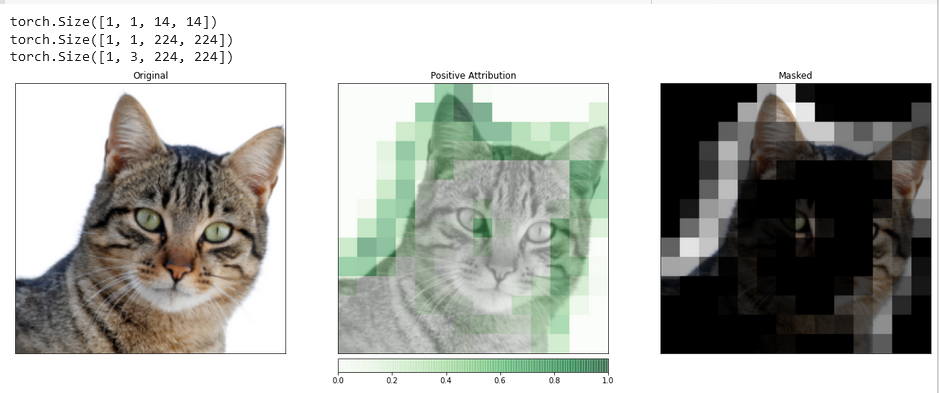
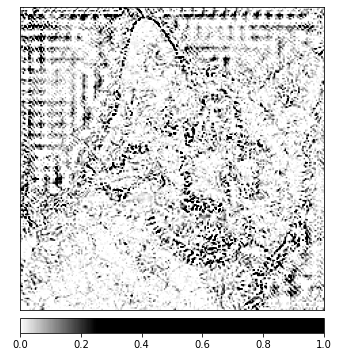
Visualizações como esta têm o potencial para fornecer a você insights únicos sobre como suas camadas ocultas respondem à entrada fornecida.
Atribuição de Funcionalidades com Oclusão
Métodos baseados em gradientes ajudam a entender o modelo em termos de computar diretamente as mudanças no saída com relação à entrada.
A técnica conhecida como atribuição baseada em perturbação tem um método mais direto para esse problema, fazendo modificações na entrada para quantificar o impacto dessas mudanças na saída. Uma estratégia tão chamativa é chamada de oclusão.
Ela envolve substituir peças da imagem de entrada e analisar como essa mudança afeta o sinal produzido na saída.
A seguir, nós configuraremos a atribuição de oclusão. Tal como a configuração de uma rede neural convolucional, você pode escolher o tamanho da região alvo e a distância de passo, que determina a separação entre as medições individuais.
Nós usaremos a função visualize_image_attr_multiple() para ver os resultados da nossa atribuição de oclusão. Esta função mostrará mapas de calor de ambos os atributos positivos e negativos por região e mascarará a imagem original com as regiões de atribuição positiva.
A máscara fornece uma olhada muito iluminativa nas regiões da nossa foto de gato que o modelo identificou como as mais “gatunas”.
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
Saída:
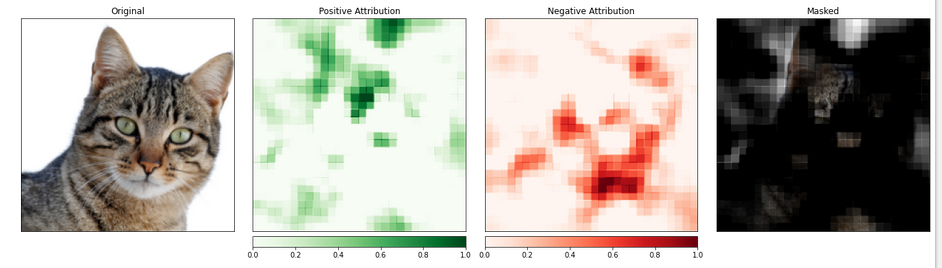
A parte da imagem que contém o gato parece ser dada um nível de importância maior.
Conclusão
Captum é uma biblioteca de interpretabilidade de modelos para PyTorch que é versátil e simples. Ela oferece técnicas de ponta para entender como as neurônios e camadas específicas impactam as previsões.
Existem três tipos principais de técnicas de atribuição: Técnicas de Atribuição Primária, Técnicas de Atribuição de Camada e Técnicas de Atribuição de Neurônio.
Referências
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf