













Enfrentando o desafio de manter um banco de dados PostgreSQL resiliente na paisagem sempre mutável das demandas digitais? Se o termo “Patroni” ressoa com suas aspirações tecnológicas, você está à beira de desbloquear uma solução que eleva o PostgreSQL a uma fortaleza de alta disponibilidade.
Certamente, um desafio o espera, mas não tema – você está embarcando em uma jornada transformadora para construir um cluster PostgreSQL inabalável. Imagine um futuro onde interrupções de banco de dados são meros contratempos, e sua configuração PostgreSQL se mantém como o epítome da confiabilidade.
Prepare-se para fortalecer seu ambiente PostgreSQL em um bastião inabalável!
Pré-requisitos
Antes de você iniciar a implementação de alta disponibilidade para PostgreSQL, garanta que você tenha o seguinte em lugar:
- Cinco (ou mais) servidores Linux – Este tutorial usa servidores Debian 12, cada um com um usuário não-root com privilégios de sudo/administrador como segue:
| Hostname | IP Address | Used as |
|---|---|---|
| postgres01 | 192.168.5.20 | PostgreSQL Server |
| postgres02 | 192.168.5.21 | PostgreSQL Server |
| postgres03 | 192.168.5.22 | PostgreSQL Server |
| etcd | 192.168.5.15 | Cluster Data Store |
| haproxy | 192.168.5.16 | Load Balancer |
- A client machine (Linux, Windows, or MacOS) with a PostgreSQL client installed.
Instalando o Servidor PostgreSQL e Patroni
Com todos os pré-requisitos atendidos, imagine este momento como a fundação para um ambiente de banco de dados robusto e à prova de falhas. O objetivo é criar uma implantação PostgreSQL de alta disponibilidade via PostgreSQL 15. Mas primeiro, você deve instalar os pacotes necessários (Servidor PostgreSQL e Patroni) em todos os seus servidores PostgreSQL.
Patroni é um aplicativo baseado em Python para criar implantações de PostgreSQL de alta disponibilidade em seus data centers, desde hardware físico até Kubernetes. Patroni está disponível no repositório oficial do PostgreSQL e suporta servidores PostgreSQL 9.5-16.
Para instalar o Servidor PostgreSQL e o Patroni, siga as instruções abaixo:
? NOTA: Execute as seguintes operações nos servidores PostgreSQL. Neste caso,
postgres01,postgres02epostgres03.
1. Abra um terminal e execute o comando curl abaixo, que não terá saída, mas adiciona a chave GPG para o repositório do PostgreSQL ao arquivo /usr/share/keyrings/pgdg.gpg.
? Este tutorial usa uma conta root para execução de comandos para garantir compatibilidade de demonstração. No entanto, lembre-se de que é altamente recomendável usar uma conta não-root com privilégios sudo. Com uma conta não-root, você deve prefixar seus comandos com
sudopara maior segurança e boas práticas.
2. Em seguida, execute o seguinte comando, que não fornece saída, mas adiciona o repositório do PostgreSQL à lista de fontes de pacotes no arquivo /etc/apt/sources.list.d/pgdg.list.
3. Após adicionado, execute o comando abaixo apt update para atualizar seu índice de pacotes e obter informações mais recentes sobre os pacotes.
4. Uma vez atualizado, execute o seguinte comando para instalar os pacotes a seguir:
postgresql-15– O sistema de gerenciamento de banco de dados PostgreSQL versão 15.patroni– Uma solução de código aberto para alta disponibilidade no PostgreSQL, um modelo para clusters HA do PostgreSQL usando Python e etcd.python3-etcd– Uma biblioteca cliente Python para interagir com o etcd, um armazenamento de chave-valor distribuído. Esta biblioteca permite que aplicações Python se comuniquem e gerenciem clusters etcd.python3-psycopg2– Um adaptador PostgreSQL para Python 3, conectando aplicações Python e bancos de dados PostgreSQL.
Insira Y para prosseguir com a instalação quando solicitado.
5. Com os pacotes instalados, execute cada comando abaixo, que não exibe saída no terminal, mas realiza o seguinte:
- Interrompa os serviços
postgresqlepatroni. No Debian/Ubuntu, os serviçospostgresqlepatronisão iniciados automaticamente após a instalação. - Crie um
symlinkpara os arquivos binários do PostgreSQL no diretório/usr/sbin. Fazê-lo garante que opatronipode executar os arquivos binários do PostgreSQL para criar e gerenciar o PostgreSQL.
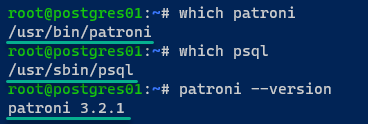
6. Por fim, execute os seguintes comandos para verificar o caminho binário do patroni e psql, e a versão instalada do patroni.
Abaixo estão os caminhos para os arquivos binários do patroni (/usr/bin/patroni) e psql (/usr/sbin/psql); a versão do Patroni instalada é 3.2.1.
Configurando e Configurando o Servidor etcd
Agora que você tem o Servidor PostgreSQL e o Patroni instalados, você precisa de uma base que solidifique a coordenação entre seus servidores PostgreSQL para uma alta disponibilidade contínua. Você irá configurar e configurar o etcd, um armazenamento de dados chave-valor.
Este armazenamento de dados chave-valor é o arquiteto silencioso nos bastidores, garantindo que os dados relacionados à implantação do seu cluster PostgreSQL sejam armazenados com segurança e gerenciados eficientemente.
? NOTA: Certifique-se de instalar o etcd em um servidor separado. Neste exemplo, o etcd está instalado no servidor etcd.
Para instalar e configurar o etcd, siga estas etapas:
1. No seu servidor etcd, execute o comando abaixo para atualizar o índice do repositório e obter as informações mais recentes sobre o pacote.
2. Em seguida, execute o comando abaixo para instalar o etcd no seu servidor.
3. Depois de instalar o etcd, abra a configuração padrão /etc/default/etcd usando seu editor preferido e insira a seguinte configuração.
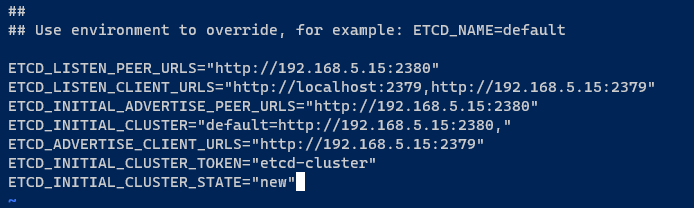
Esta configuração configura um único cluster etcd, então certifique-se de alterar o endereço IP 192.168.5.15 pelo seu endereço IP interno.
ETCD_LISTEN_PEER_URLS="<http://192.168.5.15:2380>"
ETCD_LISTEN_CLIENT_URLS="<http://localhost:2379>,<http://192.168.5.15:2379>"
ETCD_INITIAL_ADVERTISE_PEER_URLS="<http://192.168.5.15:2380>"
ETCD_INITIAL_CLUSTER="default=http://192.168.5.15:2380,"
ETCD_ADVERTISE_CLIENT_URLS="<http://192.168.5.15:2379>"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new" Salve as alterações e saia do editor.
4. Agora, execute o comando systemctl abaixo para reiniciar o etcd e aplicar suas modificações.
Este comando não possui saída, mas você verificará as mudanças no próximo passo.
5. Uma vez que o etcd reinicie, verifique se o serviço etcd está em execução e habilitado.
Se o serviço etcd estiver em execução, você deverá ver uma saída active (running). Quando habilitado, você verá a saída enabled, o que também significa que o etcd será iniciado automaticamente no boot.
6. Por último, execute o seguinte comando etcdctl abaixo para verificar a lista de servidores disponíveis no cluster etcd.
Neste caso, o etcd é executado como um cluster de nó único em um endereço IP local http://192.168.5.15:2379/.

Inicializando o Cluster PostgreSQL via Patroni
Com o servidor etcd agora firmemente em funcionamento, você está no limiar da próxima fase crucial. Ao iniciar o processo de inicialização usando o Patroni, você eleva a configuração do seu PostgreSQL para um cluster robusto e tolerante a falhas.
? Certifique-se de fazer backup do seu banco de dados primeiro se estiver implantando um cluster PostgreSQL em um servidor PostgreSQL existente.
Para inicializar seu cluster PostgreSQL via Patroni, execute o seguinte em cada servidor PostgreSQL:
1. Abra a configuração padrão do Patroni (/etc/patroni/config.yml) no seu editor de texto e adicione a seguinte configuração.
Certifique-se de substituir o valor da opção name pelo nome do host do seu servidor PostgreSQL (ou seja, postgres01), mas não feche o editor ainda.
Esta configuração cria o seu cluster PostgreSQL chamado postgres.
2. Em seguida, adicione a configuração abaixo para configurar a API REST do Patroni para ser executada em 192.168.5.20:8008.
Você deve garantir que cada um dos servidores PostgreSQL dentro do cluster pode se conectar via API. Portanto, altere o endereço IP 192.168.5.20 pelo endereço IP respectivo de cada servidor PostgreSQL.
3. Adicione a configuração abaixo para habilitar a integração com etcd. Neste caso, o servidor etcd está em execução no endereço IP 192.168.5.15.
4. Agora, adicione a configuração abaixo para inicializar o servidor PostgreSQL via initdb.
Esta configuração define as regras e configurações padrão para autenticação de cliente (pg_hba.conf) e um novo usuário admin com a senha admin.
Verifique se os endereços IP do cluster PostgreSQL estão na seção pg_hba e altere a senha padrão admin na seção users.
5. Após configurar como o PostgreSQL inicia, insira a seguinte configuração para definir como o PostgreSQL será executado em cada servidor.
Quanto ao servidor postgres01, o PostgreSQL será executado no endereço IP 192.168.5.20 com o diretório de dados /var/lib/patroni.
Além disso, esta configuração cria um novo usuário chamado replicator para operações de replicação e o usuário postgres como superusuário/administrador com a senha (secretpassword).
Certifique-se de alterar o endereço IP e a senha padrão (secretpassword).
6. Insira a seguinte configuração para definir tags para o seu servidor PostgreSQL, determinando seu comportamento no cluster, salve as alterações e feche o arquivo.
7. Com as configurações salvas, execute os comandos abaixo para preparar coletivamente o diretório de dados do Patroni, garantindo que ele esteja apropriadamente possuído e seguro para uso do PostgreSQL.
Esses comandos não fornecem saída, mas esta etapa é crucial para configurar um cluster de banco de dados PostgreSQL com o Patroni para alta disponibilidade.
8. Em seguida, execute os comandos systemctl abaixo para iniciar e verificar o serviço patroni.
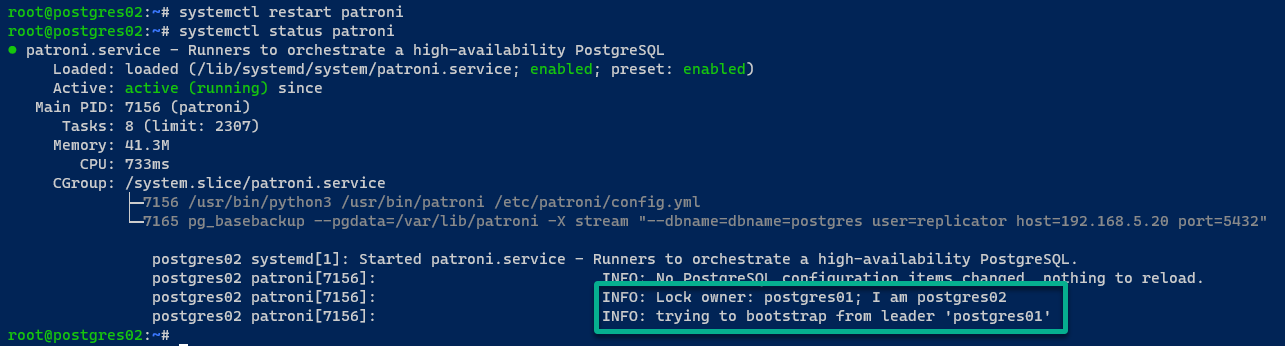
No servidor postgres01, o servidor PostgreSQL é iniciado, e o cluster é inicializado. Além disso, o servidor postgres01 é selecionado como líder do cluster.
No servidor postgres02, o servidor PostgreSQL é iniciado via Patroni e se junta ao cluster PostgreSQL via REST API.
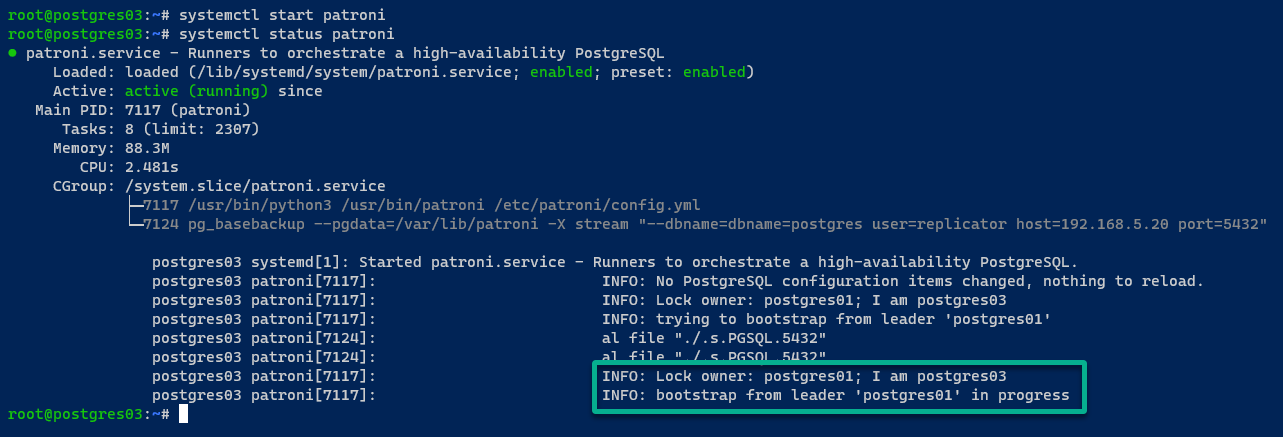
Se tudo correr bem, você verá a seguinte mensagem:
No servidor postgres03, a saída é semelhante à do servidor postgres02.
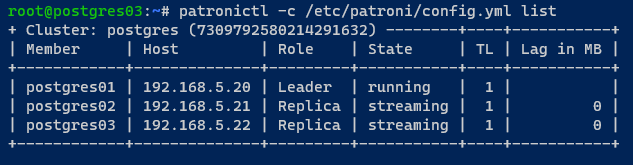
9. Com o seu cluster PostgreSQL inicializado, execute o seguinte comando patronictl para exibir uma lista das instâncias do PostgreSQL gerenciadas pelo Patroni.
No seguinte resultado, você pode ver o seu cluster PostgreSQL (postgres) em execução.
Observe que o seu cluster está em execução com três membros: postgres01 como Líder, postgres02, e postgres03 como Replica com o modo/estado streaming.
10. Por fim, execute o comando systemctl abaixo para desabilitar a inicialização automática do serviço postgresql durante a inicialização do sistema.
Este comando não possui saída se for bem-sucedido, mas é crucial, já que o Patroni controla o novo servidor PostgreSQL.
Instalando e Configurando o HAProxy como Balanceador de Carga
Com o seu cluster PostgreSQL implantado, como você pode torná-lo acessível para os clientes e habilitar a falha quando ocorrer um problema? A solução é o HAProxy como balanceador de carga antes do seu cluster PostgreSQL.
O HAProxy é o seu ponto de apoio que permite que o seu cluster PostgreSQL lide com cargas de trabalho variáveis, distribua solicitações inteligentemente e mantenha alta disponibilidade.
? NOTA: Instale o HAProxy em um servidor separado. Neste caso, o servidor HAProxy é instalado no servidor haproxy com o endereço IP 192.168.5.16.
Para instalar e configurar o HAProxy como balanceador de carga para o cluster PostgreSQL, siga estes passos:
1. Abra o arquivo /etc/hosts usando seu editor de texto preferido, insira os endereços IP e nomes de host dos seus servidores PostgreSQL, salve as alterações e feche o arquivo.
192.168.5.20 postgres01
192.168.5.21 postgres02
192.168.5.22 postgres032. Em seguida, execute o comando abaixo para atualizar o índice de pacotes.
3. Uma vez atualizado, execute o comando abaixo para instalar o pacote haproxy no seu sistema.
4. Agora, execute o seguinte comando para fazer backup da configuração padrão do HARPOXY para /etc/haproxy/haproxy.cfg.orig.
Este comando não gera saída, mas é uma medida de precaução antes de fazer qualquer modificação.
5. Em seguida, crie um novo arquivo chamado /etc/haproxy/haproxy.cfg usando seu editor preferido e insira a seguinte configuração. Certifique-se de substituir cada endereço IP do servidor PostgreSQL pelos seus, salve o arquivo e feche o editor.
Esta configuração do HAProxy configura o HAProxy como um balanceador de carga para o seu cluster PostgreSQL com dois proxies, da seguinte forma:
stats– Este bloco é executado na porta8080e monitora o desempenho do servidor HAProxy e dos backends.postgres– Este bloco é a configuração do balanceador de carga para o cluster PostgreSQL.
# Configurações globais de configuração
global
# Máximo de conexões globalmente
maxconn 100
# Configurações de registro
log 127.0.0.1 local2
# Configurações padrão
defaults
# Configuração global de registro
log global
# Definir modo para TCP
mode tcp
# Número de tentativas
retries 2
# Tempo limite do cliente
timeout client 30m
# Tempo limite de conexão
timeout connect 4s
# Tempo limite do servidor
timeout server 30m
# Tempo limite de verificação
timeout check 5s
# Configuração de estatísticas
listen stats
# Definir modo para HTTP
mode http
# Conectar à porta 8080
bind *:8080
# Habilitar estatísticas
stats enable
# URI de estatísticas
stats uri /
# Configuração do PostgreSQL
listen postgres
# Conectar à porta 5432
bind *:5432
# Habilitar verificação HTTP
option httpchk
# Esperar status 200
http-check expect status 200
# Configurações do servidor
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
# Definir servidores PostgreSQL
server postgres01 192.168.5.20:5432 maxconn 100 check port 8008
server postgres02 192.168.5.21:5432 maxconn 100 check port 8008
server postgres03 192.168.5.22:5432 maxconn 100 check port 80086. Com o HAProxy configurado, execute os comandos systemctl abaixo para reiniciar e verificar (status) o serviço haproxy.
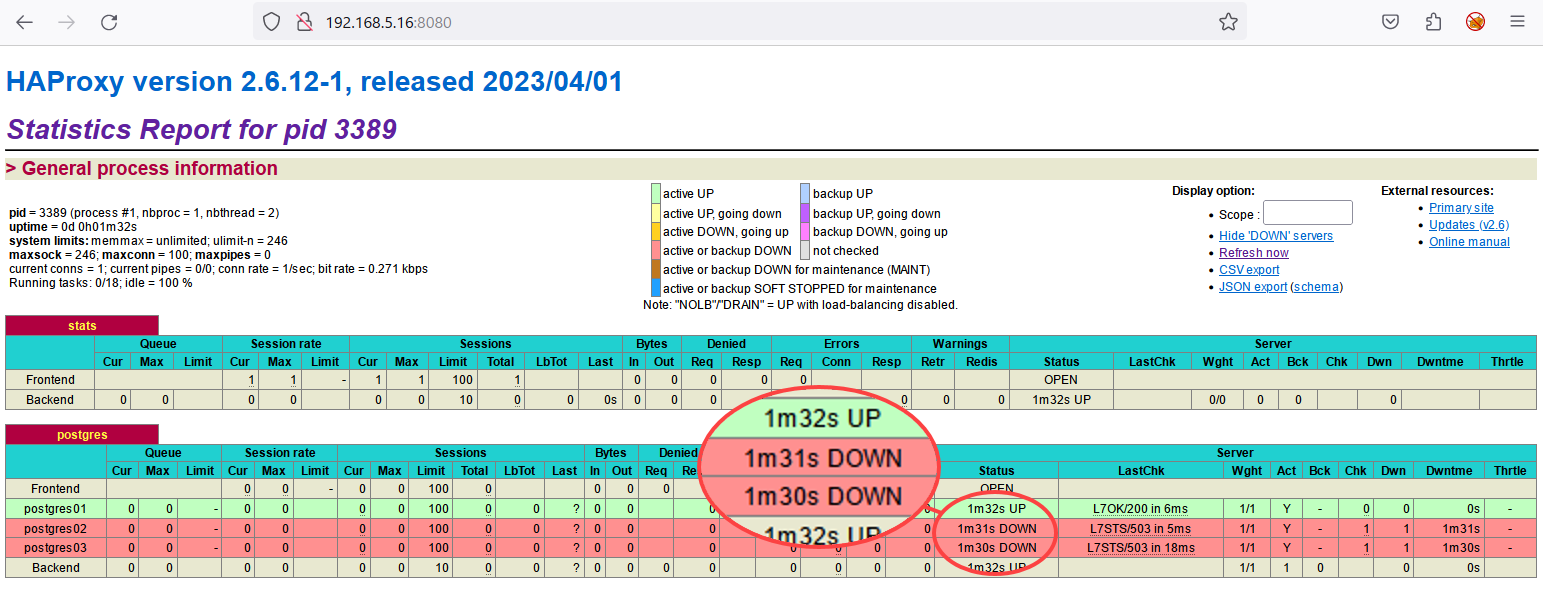
7. Por fim, abra seu navegador preferido e visite o endereço IP do HAProxy com a porta 8080 (ou seja, http://192.168.5.16:8080/). Na saída abaixo, você pode ver o seguinte:
Na saída abaixo, você pode ver o seguinte:
- O proxy stats para monitorar o status do HAProxy.
- O proxy postgres é o balanceador de carga para o cluster PostgreSQL.
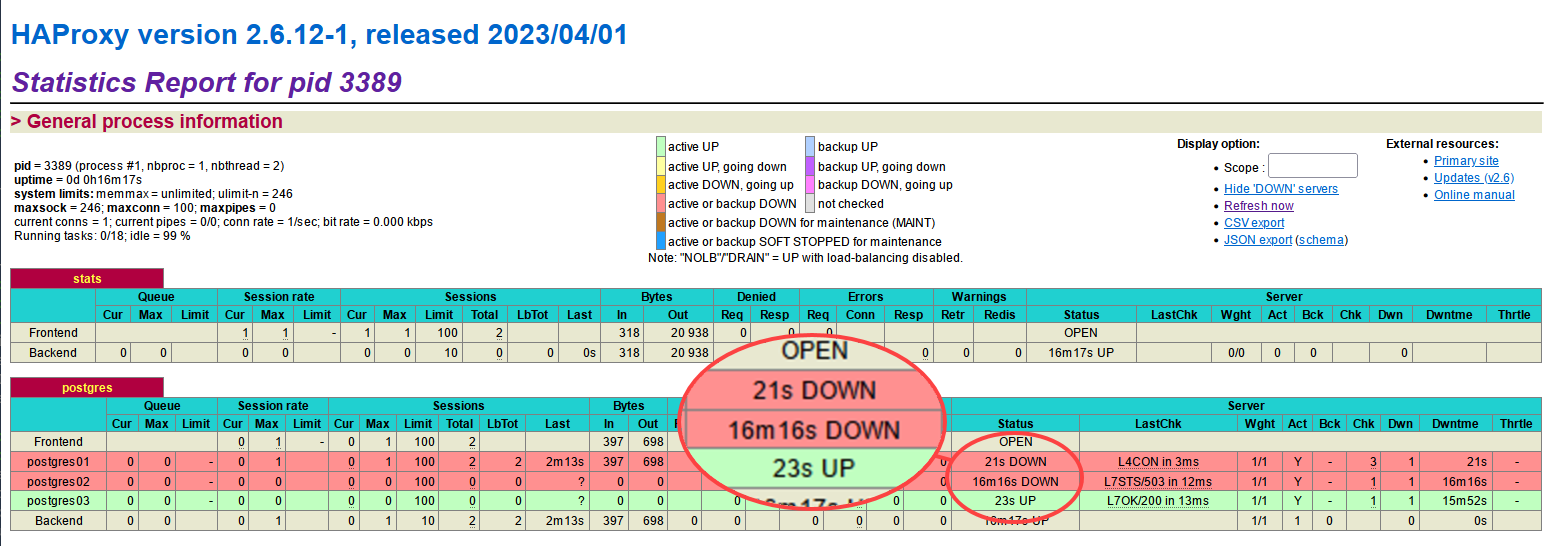
Observe que os servidores postgres02 e postgres03 estão marcados como inativos porque ambos estão funcionando no modo streaming.
Testando a Failover do Cluster do PostgreSQL
Saindo da configuração do HAProxy como seu confiável balanceador de carga, é hora de testar seu cluster do PostgreSQL. Este passo crucial revelará a resistência da sua configuração de alta disponibilidade. Você deve garantir que seu cluster do PostgreSQL permaneça robusto e responsivo mesmo diante de possíveis falhas.
Para testar a failover do seu cluster do PostgreSQL, você se conectará ao cluster a partir da sua máquina cliente e verificará as operações de failover com as seguintes etapas:
1. Faça login na sua máquina cliente, abra um terminal e execute o comando psql abaixo para se conectar ao PostgreSQL via balanceador de carga HAProxy.
Insira sua senha do PostgreSQL quando solicitado. Você pode encontrar as informações necessárias da senha no arquivo /etc/patroni/config.yml.
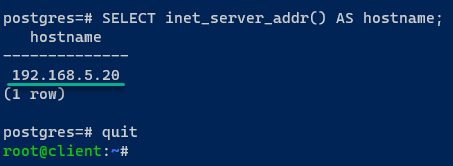
2. Uma vez conectado, execute a seguinte consulta para descobrir a qual servidor do PostgreSQL você está conectado e sair da sessão atual do PostgreSQL.
Se a instalação do seu PostgreSQL for bem-sucedida, você estará conectado ao servidor postgres01.
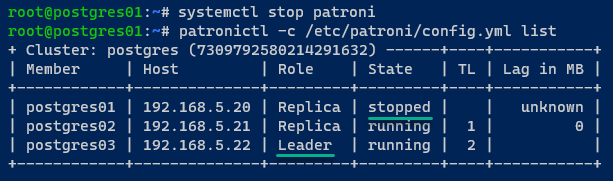
3. Agora, mude para o servidor postgres01, execute os seguintes comandos para parar o serviço patroni e listar o status dos clusters do PostgreSQL.
Este passo permite testar a failover do PostgreSQL.
Você verá que o estado do servidor postgres01 mudou para parado, e a nova líder do cluster é delegada ao servidor postgres03.
Volte para as estatísticas de monitoramento do HAProxy e você verá que o servidor postgres01 está INATIVO, enquanto o postgres03 agora está ATIVO-PASSIVO.
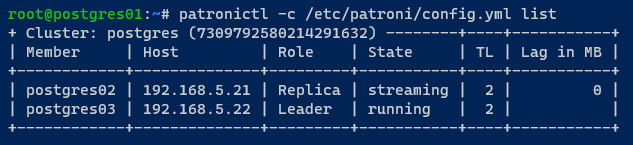
Alternativamente, execute o seguinte comando patronictl para verificar o status do cluster do PostgreSQL.
Como você pode ver abaixo, o servidor postgres01 não está mais no cluster.
Troque de volta para a máquina cliente e execute o comando psql abaixo para se conectar ao servidor PostgreSQL via HAProxy.
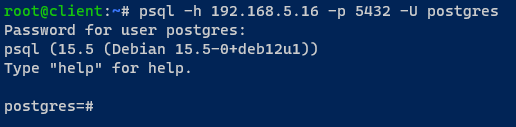
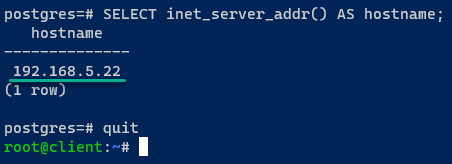
Ao se conectar, execute a seguinte consulta para verificar o servidor PostgreSQL atual ao qual você está conectado.
Se o failover for bem-sucedido, você estará conectado a um dos servidores em execução, que neste caso é o postgres03.
Conclusão
Ao embarcar nesta jornada, você mergulhou nas complexidades de garantir alta disponibilidade para seu banco de dados PostgreSQL, empregando a poderosa combinação de Patroni e HAProxy. Navegando sem esforço através das etapas de configuração do PostgreSQL e do Patroni, você lidou habilmente com as nuances de configurar o servidor etcd.
Suas habilidades de orquestração vieram à tona enquanto você construía um cluster PostgreSQL resiliente com Patroni e afinava a arte do balanceamento de carga usando o HAProxy. A culminação desta aventura de alto risco foi o teste minucioso das capacidades de failover do seu cluster PostgreSQL.
Considere expandir sua experiência enquanto reflete sobre suas conquistas na criação de um ambiente PostgreSQL robusto e tolerante a falhas. Que tal explorar a implementação do Patroni com Kubernetes para um ambiente mais dinâmico? Ou aprofundar-se nas complexidades de configurar a Alta Disponibilidade do PostgreSQL em múltiplos data centers?