













Faisant face au défi de maintenir une base de données PostgreSQL résiliente dans le paysage en constante évolution des exigences numériques ? Si le terme « Patroni » résonne avec vos aspirations technologiques, vous êtes sur le point de débloquer une solution qui élève PostgreSQL au rang de forteresse de haute disponibilité.
Certes, un défi vous attend, mais ne craignez rien – vous vous lancez dans un voyage transformateur pour construire un cluster PostgreSQL inébranlable. Envisagez un avenir où les perturbations de la base de données ne sont que des pépins, et votre configuration PostgreSQL se tient comme l’épitomé de la fiabilité.
Préparez-vous à fortifier votre environnement PostgreSQL en une bastion inébranlable!
Prérequis
Avant de vous lancer dans la mise en place de la haute disponibilité pour PostgreSQL, assurez-vous d’avoir les éléments suivants en place:
- Cinq (ou plus) serveurs Linux – Ce tutoriel utilise des serveurs Debian 12, chacun avec un utilisateur non root disposant de privilèges sudo/administrateur comme suit:
| Hostname | IP Address | Used as |
|---|---|---|
| postgres01 | 192.168.5.20 | PostgreSQL Server |
| postgres02 | 192.168.5.21 | PostgreSQL Server |
| postgres03 | 192.168.5.22 | PostgreSQL Server |
| etcd | 192.168.5.15 | Cluster Data Store |
| haproxy | 192.168.5.16 | Load Balancer |
- A client machine (Linux, Windows, or MacOS) with a PostgreSQL client installed.
Installation du serveur PostgreSQL et de Patroni
Avec tous les prérequis remplis, imaginez ce moment comme la pose des fondations pour un environnement de base de données robuste et sûr. L’objectif est de créer un déploiement PostgreSQL haute disponibilité via PostgreSQL 15. Mais d’abord, vous devez installer les paquets requis (serveur PostgreSQL et Patroni) sur tous vos serveurs PostgreSQL.
Patroni est une application basée sur Python pour créer un déploiement PostgreSQL haute disponibilité dans vos centres de données, du métal nu à Kubernetes. Patroni est disponible sur le référentiel officiel de PostgreSQL et prend en charge les serveurs PostgreSQL 9.5-16.
Pour installer le serveur PostgreSQL et Patroni, suivez les étapes suivantes :
? REMARQUE : Effectuez les opérations suivantes sur les serveurs PostgreSQL. Dans ce cas,
postgres01,postgres02etpostgres03.
1. Ouvrez un terminal et exécutez la commande curl ci-dessous, qui n’affiche aucune sortie mais ajoute la clé GPG du référentiel PostgreSQL à /usr/share/keyrings/pgdg.gpg.
? Ce tutoriel utilise un compte root pour l’exécution des commandes afin de garantir la compatibilité de la démonstration. Mais rappelez-vous qu’il est fortement recommandé d’utiliser un compte non root avec des privilèges sudo. Avec un compte non root, vous devez préfixer vos commandes avec
sudopour une sécurité renforcée et les meilleures pratiques.
2. Ensuite, exécutez la commande suivante, qui n’affiche pas de sortie mais ajoute le référentiel PostgreSQL à la liste des sources de paquets dans le fichier /etc/apt/sources.list.d/pgdg.list.
3. Une fois ajouté, exécutez la commande apt update ci-dessous pour rafraîchir votre index de paquets et récupérer les informations sur les nouveaux paquets.
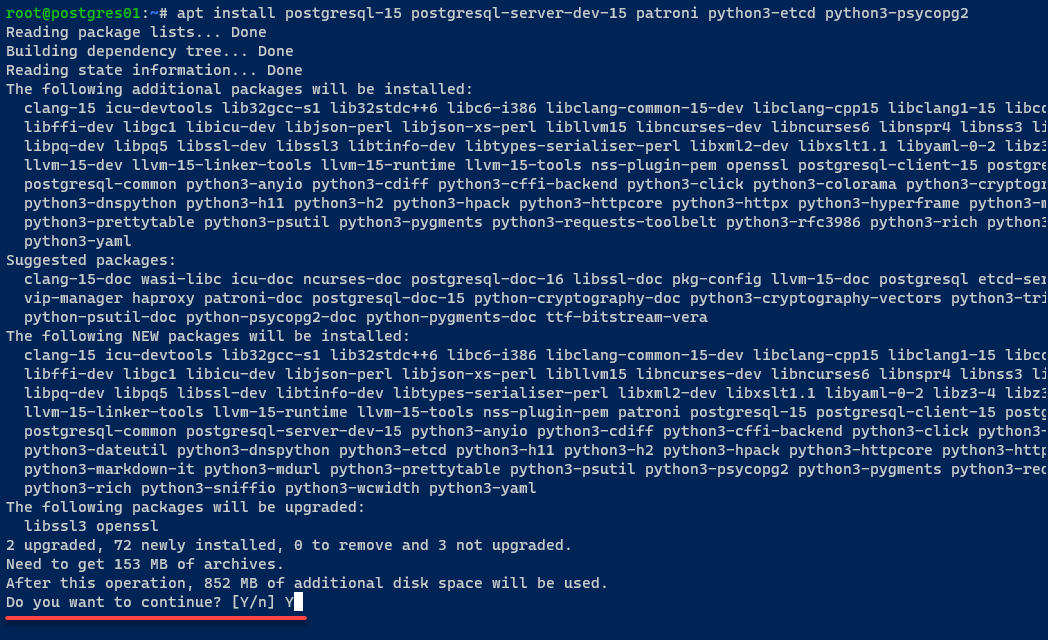
4. Une fois la mise à jour effectuée, exécutez la commande suivante pour installer les paquets suivants :
postgresql-15– Le système de gestion de base de données PostgreSQL version 15.patroni– Une solution open source pour la haute disponibilité dans PostgreSQL, un modèle pour les clusters HA PostgreSQL utilisant Python et etcd.python3-etcd– Une bibliothèque cliente Python pour interagir avec etcd, un magasin de clés-valeurs distribué. Cette bibliothèque permet aux applications Python de communiquer avec et de gérer les clusters etcd.python3-psycopg2– Un adaptateur PostgreSQL pour Python 3, connectant les applications Python et les bases de données PostgreSQL.
Appuyez sur Y pour procéder à l’installation lorsqu’on vous le demande.
5. Avec les paquets installés, exécutez chaque commande ci-dessous, qui n’affiche aucune sortie dans le terminal mais effectue ce qui suit :
- Arrêtez les services
postgresqletpatroni. Sur Debian/Ubuntu, les servicespostgresqletpatronidémarrent automatiquement après l’installation. - Créez un lien symbolique pour les fichiers binaires de PostgreSQL vers le répertoire `/usr/sbin`. Cela garantit que `patroni` peut exécuter les fichiers binaires de PostgreSQL pour la création et la gestion de PostgreSQL.
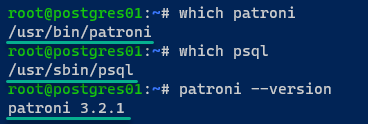
6. Enfin, exécutez les commandes suivantes pour vérifier le chemin binaire de patroni et psql, et la version installée avec --version de patroni.
Voici les chemins vers les fichiers binaires de patroni (/usr/bin/patroni) et psql (/usr/sbin/psql); la version de Patroni installée est 3.2.1.
Configuration et installation du serveur etcd
Maintenant que vous avez installé PostgreSQL Server et Patroni, vous avez besoin d’une base solide qui consolide la coordination entre vos serveurs PostgreSQL pour une disponibilité élevée sans faille. Vous allez configurer et installer etcd, un magasin de données clé-valeur.
Ce magasin de données clé-valeur est l’architecte silencieux en arrière-plan, garantissant que les données liées au déploiement de votre cluster PostgreSQL sont stockées de manière sécurisée et gérées efficacement.
? REMARQUE : Assurez-vous d’installer etcd sur un serveur distinct. Dans cet exemple, etcd est installé sur le serveur etcd.
Pour installer et configurer etcd, suivez ces étapes :
1. Sur votre serveur etcd, exécutez la commande ci-dessous pour mettre à jour l’index du référentiel et obtenir les dernières informations sur le package.
2. Ensuite, exécutez la commande ci-dessous pour installer le etcd sur votre serveur.
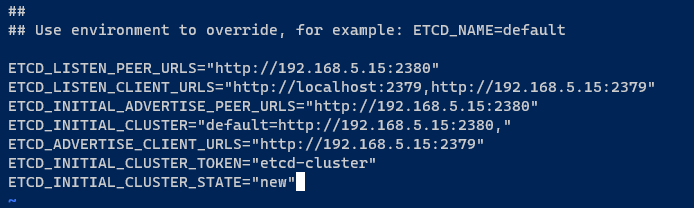
3. Une fois que vous avez installé etcd, ouvrez la configuration par défaut /etc/default/etcd à l’aide de votre éditeur préféré, et insérez la configuration suivante.
Cette configuration configure un seul cluster etcd, alors assurez-vous de changer l’adresse IP 192.168.5.15 avec votre adresse IP interne.
ETCD_LISTEN_PEER_URLS="<http://192.168.5.15:2380>"
ETCD_LISTEN_CLIENT_URLS="<http://localhost:2379>,<http://192.168.5.15:2379>"
ETCD_INITIAL_ADVERTISE_PEER_URLS="<http://192.168.5.15:2380>"
ETCD_INITIAL_CLUSTER="default=http://192.168.5.15:2380,"
ETCD_ADVERTISE_CLIENT_URLS="<http://192.168.5.15:2379>"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new" Enregistrez les modifications et quittez l’éditeur.
4. Maintenant, exécutez la commande systemctl ci-dessous pour redémarrer etcd et appliquer vos modifications.
Cette commande n’a pas de sortie, mais vous vérifierez les modifications à l’étape suivante.
5. Une fois que etcd redémarre, vérifiez que le service etcd est en cours d’exécution et activé.
Si le service etcd est en cours d’exécution, vous devriez voir une sortie actif (en cours d'exécution). Lorsqu’il est activé, vous verrez la sortie activé, ce qui signifie également que etcd démarrera automatiquement au démarrage.
6. Enfin, exécutez la commande suivante de etcdctl ci-dessous pour vérifier la liste des serveurs disponibles sur le cluster etcd.
Dans ce cas, etcd fonctionne comme un cluster à nœud unique sur une adresse IP locale http://192.168.5.15:2379/.

Amorçage du cluster PostgreSQL via Patroni
Avec le serveur etcd désormais solidement en place, vous vous tenez au seuil de la prochaine phase cruciale. En initiant le processus de démarrage avec Patroni, vous élevez la configuration de votre PostgreSQL vers un cluster robuste et tolérant aux pannes.
? Assurez-vous de sauvegarder votre base de données d’abord si vous déployez un cluster PostgreSQL sur un serveur PostgreSQL existant.
Pour amorcer votre cluster PostgreSQL via Patroni, effectuez les étapes suivantes sur chaque serveur PostgreSQL:
1. Ouvrez la configuration par défaut de Patroni (/etc/patroni/config.yml) dans votre éditeur de texte, et ajoutez la configuration suivante.
Assurez-vous de remplacer la valeur de l’option name par le nom d’hôte de votre serveur PostgreSQL (c’est-à-dire, postgres01), mais ne fermez pas encore l’éditeur.
Cette configuration met en place votre cluster PostgreSQL nommé postgres.
2. Ensuite, ajoutez la configuration ci-dessous pour configurer l’API REST de Patroni pour qu’elle fonctionne sur 192.168.5.20:8008.
Assurez-vous que chacun des serveurs PostgreSQL dans le cluster peut se connecter via l’API. Ainsi, changez l’adresse IP 192.168.5.20 avec l’adresse IP respective de chaque serveur PostgreSQL.
3. Ajoutez la configuration ci-dessous pour activer l’intégration avec etcd. Dans ce cas, le serveur etcd fonctionne à l’adresse IP 192.168.5.15.
4. Maintenant, ajoutez la configuration ci-dessous pour amorcer le serveur PostgreSQL via initdb.
Cette configuration établit les règles et paramètres par défaut pour l’authentification client (pg_hba.conf) et crée un nouvel utilisateur admin avec le mot de passe admin.
Assurez-vous d’entrer les adresses IP du cluster PostgreSQL dans la section pg_hba et de changer le mot de passe admin par défaut dans la section users.
5. Après avoir configuré le démarrage de PostgreSQL, insérez la configuration suivante pour définir le fonctionnement de PostgreSQL sur chaque serveur.
Concernant le serveur postgres01, PostgreSQL s’exécutera sur l’adresse IP 192.168.5.20 avec le répertoire de données /var/lib/patroni.
De plus, cette configuration crée un nouvel utilisateur appelé replicator pour les opérations de réplication, et l’utilisateur postgres en tant que superutilisateur/administrateur avec le mot de passe (secretpassword).
Assurez-vous de changer l’adresse IP et le mot de passe par défaut (secretpassword).
6. Insérez la configuration suivante pour définir des balises pour votre serveur PostgreSQL qui déterminent son comportement sur le cluster, enregistrez les modifications et fermez le fichier.
7. Avec les configurations enregistrées, exécutez les commandes ci-dessous pour préparer collectivement le répertoire de données de Patroni, en veillant à ce qu’il soit approprié et sécurisé pour l’utilisation de PostgreSQL.
Ces commandes ne fournissent pas de sortie, mais cette étape est cruciale pour la mise en place d’un cluster de base de données PostgreSQL avec Patroni pour une haute disponibilité.
8. Ensuite, exécutez les commandes systemctl ci-dessous pour démarrer et vérifier le service patroni.
Sur le serveur postgres01, le serveur PostgreSQL fonctionne et le cluster s’initialise. De plus, le serveur postgres01 est sélectionné comme chef de cluster.
Sur le serveur postgres02, le serveur PostgreSQL démarre via Patroni et rejoint le cluster PostgreSQL via l’API REST.
Si tout se passe bien, vous verrez le message suivant :
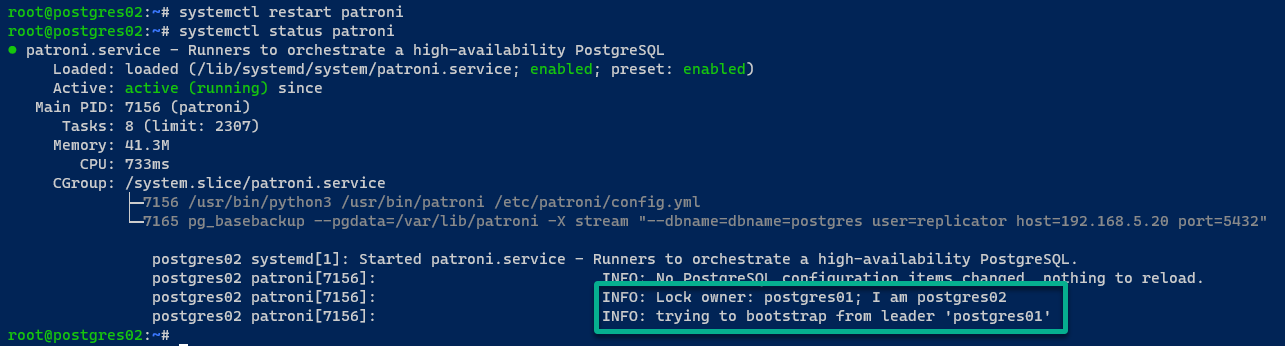
Sur le serveur postgres03, la sortie est similaire à celle du serveur postgres02.
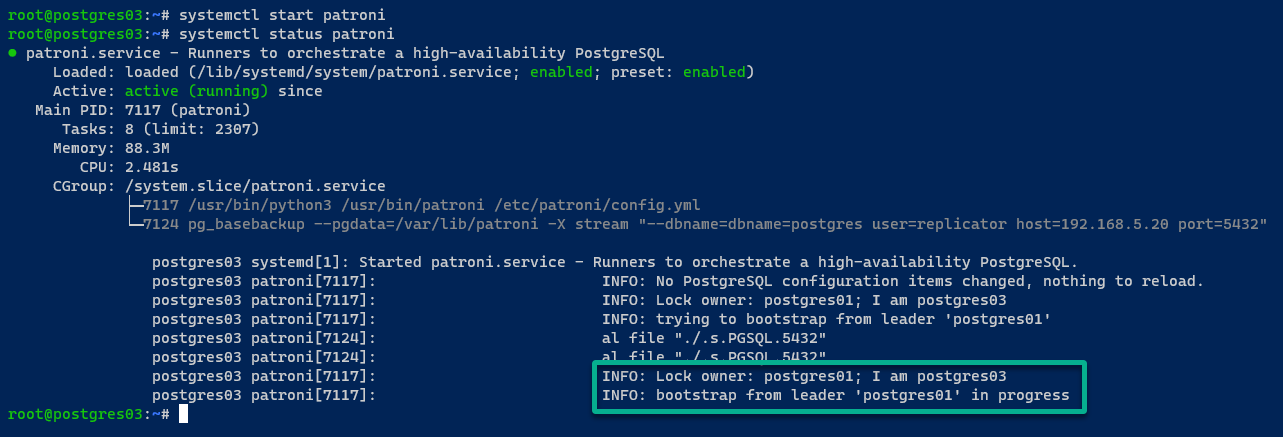
9. Avec votre cluster PostgreSQL initialisé, exécutez la commande patronictl suivante pour afficher une liste des instances PostgreSQL gérées par Patroni.
Dans la sortie suivante, vous pouvez voir que votre cluster PostgreSQL (postgres) est en cours d’exécution.
Remarquez que votre cluster fonctionne avec trois membres : postgres01 en tant que Leader, postgres02, et postgres03 en tant que Replica en mode/état streaming.
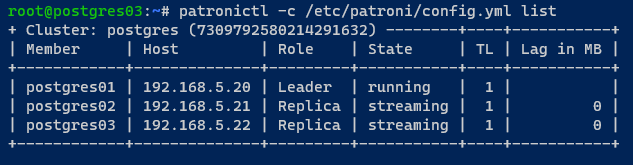
10. Enfin, exécutez la commande systemctl ci-dessous pour désactiver le démarrage automatique du service postgresql lors du démarrage du système.
Cette commande n’a pas de sortie en cas de réussite, mais elle est cruciale car Patroni contrôle le nouveau serveur PostgreSQL.
Installation et configuration de HAProxy en tant qu’équilibreur de charge
Avec votre cluster PostgreSQL déployé, comment le rendre accessible depuis les clients et activer le basculement en cas de problème? La solution est HAProxy en tant qu’équilibreur de charge avant votre cluster PostgreSQL.
HAProxy est votre pivot qui permet à votre cluster PostgreSQL de gérer des charges de travail variées, de distribuer intelligemment les demandes et de maintenir une haute disponibilité.
? REMARQUE : Installez HAProxy sur un serveur distinct. Dans ce cas, le serveur HAProxy est installé sur le serveur haproxy avec une adresse IP de 192.168.5.16.
Pour installer et configurer HAProxy en tant qu’équilibreur de charge pour le cluster PostgreSQL, suivez ces étapes :
1. Ouvrez le fichier /etc/hosts en utilisant votre éditeur de texte préféré, insérez les adresses IP et les noms d’hôtes de vos serveurs PostgreSQL, enregistrez les modifications et fermez le fichier.
192.168.5.20 postgres01
192.168.5.21 postgres02
192.168.5.22 postgres032. Ensuite, exécutez la commande ci-dessous pour mettre à jour votre index de paquets.
3. Une fois la mise à jour terminée, exécutez la commande ci-dessous pour installer le paquet haproxy sur votre système.
4. Maintenant, exécutez la commande suivante pour sauvegarder la configuration HARPOXY par défaut dans /etc/haproxy/haproxy.cfg.orig.
Cette commande ne produit pas de sortie mais est une mesure de précaution avant d’apporter des modifications.
5. Ensuite, créez un nouveau fichier appelé /etc/haproxy/haproxy.cfg en utilisant votre éditeur préféré, et insérez la configuration suivante. Assurez-vous de remplacer chaque adresse IP de serveur PostgreSQL par la vôtre, enregistrez le fichier et fermez l’éditeur.
Cette configuration HAProxy configure HAProxy en tant que répartiteur de charge pour votre cluster PostgreSQL avec deux proxys, comme suit :
stats– Ce bloc s’exécute sur le port8080et surveille les performances du serveur HAProxy et des backends.postgres– Ce bloc est la configuration du répartiteur de charge pour le cluster PostgreSQL.
# Paramètres de configuration globale
global
# Nombre maximum de connexions globalement
maxconn 100
# Paramètres de journalisation
log 127.0.0.1 local2
# Paramètres par défaut
defaults
# Configuration du journal global
log global
# Définir le mode en TCP
mode tcp
# Nombre de tentatives
retries 2
# Délai d'attente du client
timeout client 30m
# Délai de connexion
timeout connect 4s
# Délai d'attente du serveur
timeout server 30m
# Délai d'attente de vérification
timeout check 5s
# Configuration des statistiques
listen stats
# Définir le mode en HTTP
mode http
# Se lier au port 8080
bind *:8080
# Activer les statistiques
stats enable
# URI des statistiques
stats uri /
# Configuration de PostgreSQL
listen postgres
# Se lier au port 5432
bind *:5432
# Activer la vérification HTTP
option httpchk
# Attendre le statut 200
http-check expect status 200
# Paramètres du serveur
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
# Définir les serveurs PostgreSQL
server postgres01 192.168.5.20:5432 maxconn 100 check port 8008
server postgres02 192.168.5.21:5432 maxconn 100 check port 8008
server postgres03 192.168.5.22:5432 maxconn 100 check port 80086. Avec HAProxy configuré, exécutez les commandes systemctl ci-dessous pour redémarrer et vérifier (status) le service haproxy.
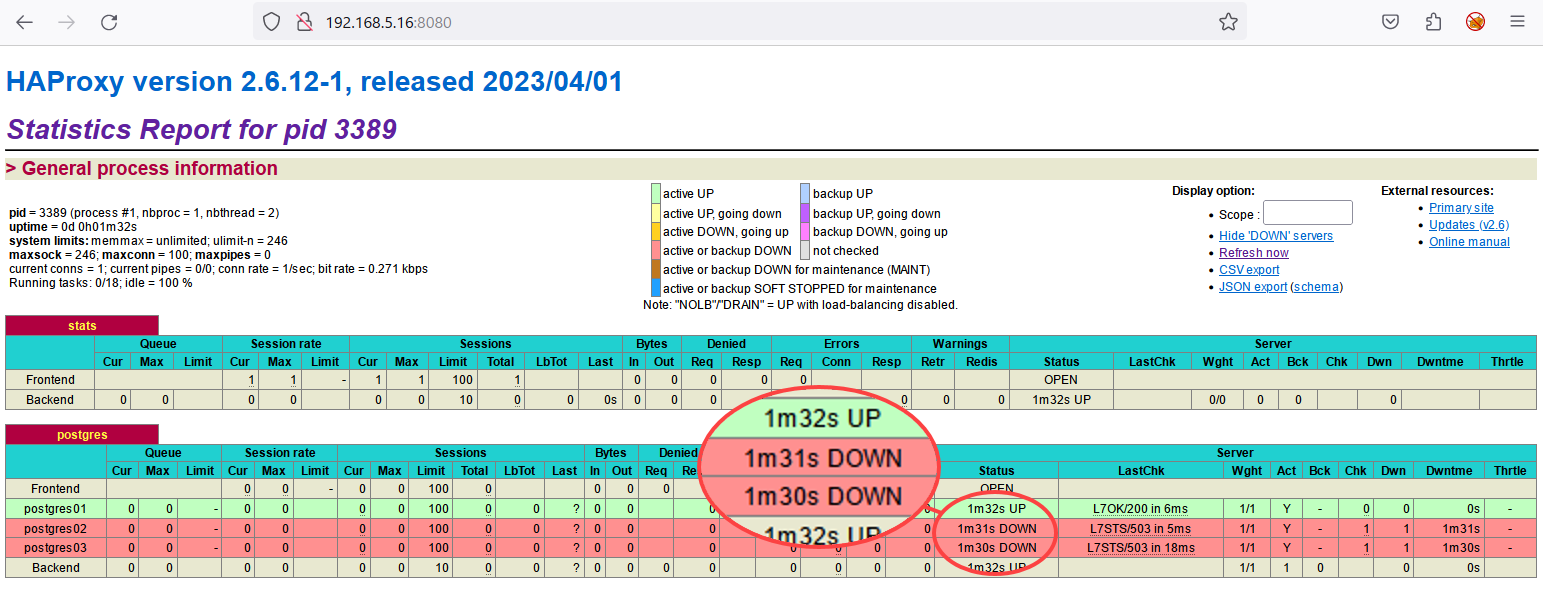
7. Enfin, ouvrez votre navigateur web préféré et visitez l’adresse IP de HAProxy avec le port 8080 (c’est-à-dire, http://192.168.5.16:8080/). Dans la sortie ci-dessous, vous pouvez voir ce qui suit:
Dans la sortie ci-dessous, vous pouvez voir ce qui suit:
- Le proxy stats pour surveiller l’état de HAProxy.
- Le proxy postgres est l’équilibreur de charge pour le cluster PostgreSQL.
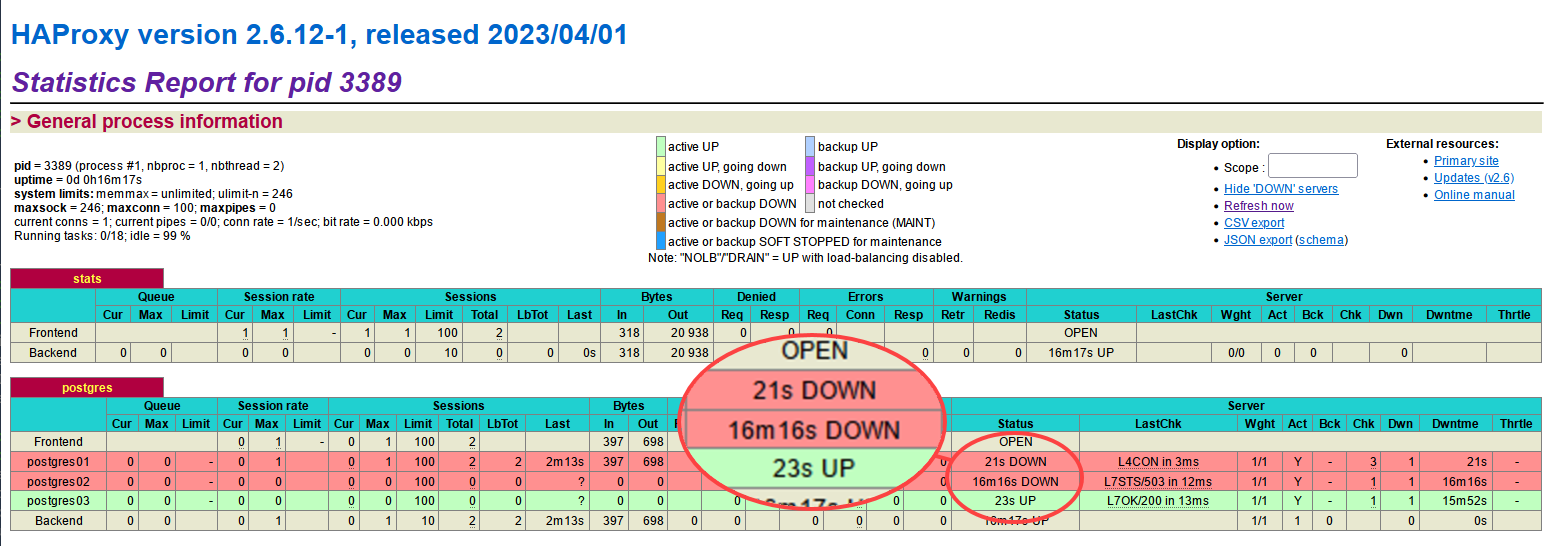
Remarquez que les serveurs postgres02 et postgres03 sont marqués comme étant en panne parce qu’ils fonctionnent tous les deux en mode streaming.
Test de basculement du cluster PostgreSQL
Après avoir configuré HAProxy comme votre équilibreur de charge fiable, il est maintenant temps de mettre votre cluster PostgreSQL à l’épreuve. Cette étape cruciale révélera la résilience de votre configuration haute disponibilité. Vous devez vous assurer que votre cluster PostgreSQL reste robuste et réactif même en cas de défaillance potentielle.
Pour tester le basculement du cluster PostgreSQL, vous vous connecterez au cluster depuis votre machine cliente et vérifierez les opérations de basculement avec les étapes suivantes :
1. Connectez-vous à votre machine cliente, ouvrez un terminal et exécutez la commande psql ci-dessous pour vous connecter au PostgreSQL via l’équilibreur de charge HAProxy.
Saisissez votre mot de passe PostgreSQL lorsque vous y êtes invité. Vous pouvez trouver les informations de mot de passe nécessaires dans le fichier /etc/patroni/config.yml.
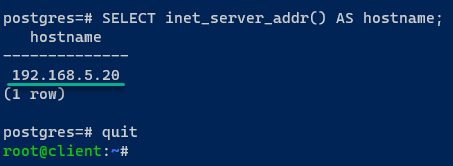
2. Une fois connecté, exécutez la requête suivante pour déterminer à quel serveur PostgreSQL vous êtes connecté, puis quit la session PostgreSQL en cours.
Si votre installation PostgreSQL est réussie, vous serez connecté au serveur postgres01.
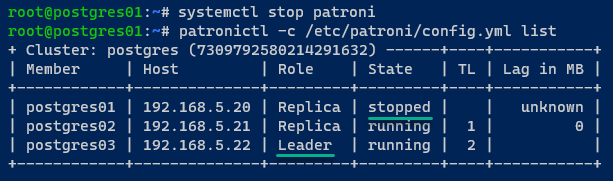
3. Maintenant, basculez vers le serveur postgres01, exécutez les commandes suivantes pour arrêter le service patroni et list l’état des clusters PostgreSQL.
Cette étape vous permet de tester le basculement de PostgreSQL.
Vous pouvez voir que l’état du serveur postgres01 a changé pour stopped, et que le nouveau leader du cluster est délégué au serveur postgres03.
4. Revenez aux statistiques de surveillance de HAProxy, et vous verrez que le serveur postgres01 est DOWN, tandis que le serveur postgres03 est maintenant UP.
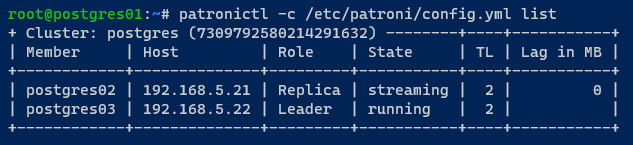
En alternative, exécutez la commande patronictl suivante pour vérifier l’état du cluster PostgreSQL.
Comme vous pouvez le voir ci-dessous, le serveur postgres01 n’est plus dans le cluster.
5. Revenez à la machine cliente et exécutez la commande psql suivante pour vous connecter au serveur PostgreSQL via HAProxy.
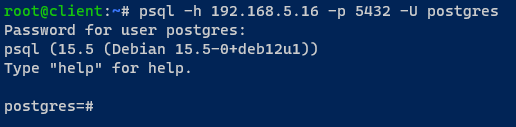
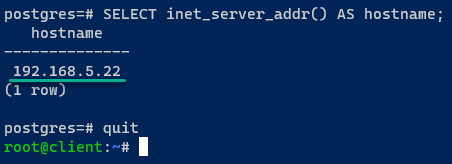
6. Une fois connecté, exécutez la requête suivante pour vérifier le serveur PostgreSQL actuel auquel vous êtes connecté.
Si la bascule est réussie, vous serez connecté à l’un des serveurs en cours d’exécution, qui dans ce cas est postgres03.
Conclusion
En entreprenant ce voyage, vous vous êtes plongé dans les complexités de garantir une disponibilité élevée pour votre base de données PostgreSQL, en utilisant la puissante combinaison de Patroni et HAProxy. Naviguant sans heurts à travers les étapes de configuration de PostgreSQL et Patroni, vous avez géré avec dextérité les subtilités de la configuration du serveur etcd.
Vos compétences en orchestration ont été mises en avant lorsque vous avez construit un cluster PostgreSQL résilient avec Patroni et affiné l’art de l’équilibrage de charge en utilisant HAProxy. La culmination de cette aventure à enjeux élevés était le test approfondi des capacités de basculement de votre cluster PostgreSQL.
Considérez élargir votre expertise en réfléchissant à vos succès dans l’établissement d’un environnement PostgreSQL robuste et tolérant aux erreurs. Pourquoi ne pas explorer la mise en œuvre de Patroni avec Kubernetes pour un environnement plus dynamique ? Ou plonger dans les subtilités de la mise en place de la haute disponibilité PostgreSQL à travers plusieurs centres de données ?