













Stehen Sie vor der Herausforderung, eine belastbare PostgreSQL-Datenbank in der sich ständig verändernden Landschaft der digitalen Anforderungen aufrechtzuerhalten? Wenn der Begriff „Patroni“ mit Ihren technischen Ambitionen resoniert, stehen Sie kurz davor, eine Lösung zu finden, die PostgreSQL zu einer Festung der Hochverfügbarkeit macht.
Gewiss erwartet Sie eine Herausforderung, aber fürchten Sie sich nicht – Sie begeben sich auf eine transformative Reise, um einen unerschütterlichen PostgreSQL-Cluster aufzubauen. Stellen Sie sich eine Zukunft vor, in der Datenbankstörungen nur noch kurze Aussetzer sind und Ihre PostgreSQL-Installation als Inbegriff von Zuverlässigkeit gilt.
Machen Sie sich bereit, Ihre PostgreSQL-Umgebung zu einer unerschütterlichen Festung zu stärken!
Voraussetzungen
Bevor Sie sich auf die Implementierung von Hochverfügbarkeit für PostgreSQL stürzen, stellen Sie sicher, dass Sie folgendes haben:
- Fünf (oder mehr) Linux-Server – In diesem Tutorial werden Debian 12-Server verwendet, von denen jeder über einen Nicht-Root-Benutzer mit sudo-/Administratorrechten verfügt, wie folgt:
| Hostname | IP Address | Used as |
|---|---|---|
| postgres01 | 192.168.5.20 | PostgreSQL Server |
| postgres02 | 192.168.5.21 | PostgreSQL Server |
| postgres03 | 192.168.5.22 | PostgreSQL Server |
| etcd | 192.168.5.15 | Cluster Data Store |
| haproxy | 192.168.5.16 | Load Balancer |
- A client machine (Linux, Windows, or MacOS) with a PostgreSQL client installed.
Installieren von PostgreSQL Server und Patroni
Mit allen Voraussetzungen erfüllt, stellen Sie sich diesen Moment als Grundstein für eine robuste, ausfallsichere Datenbankumgebung vor. Das Ziel besteht darin, mithilfe von PostgreSQL 15 eine hochverfügbare PostgreSQL-Bereitstellung zu erstellen. Aber zuerst müssen Sie die erforderlichen Pakete (PostgreSQL Server und Patroni) auf all Ihren PostgreSQL-Servern installieren.
Patroni ist eine auf Python basierende Anwendung zur Erstellung von hochverfügbaren PostgreSQL-Deployments in Ihren Rechenzentren, von Bare-Metal bis Kubernetes. Patroni ist im offiziellen PostgreSQL-Repository verfügbar und unterstützt PostgreSQL-Server 9.5-16.
Um PostgreSQL Server und Patroni zu installieren, führen Sie folgende Schritte aus:
? HINWEIS: Führen Sie die folgenden Operationen auf PostgreSQL-Servern durch. In diesem Fall
postgres01,postgres02undpostgres03.
1. Öffnen Sie ein Terminal und führen Sie den folgenden curl-Befehl aus. Dieser hat keine Ausgabe, fügt jedoch den GPG-Schlüssel für das PostgreSQL-Repository zu /usr/share/keyrings/pgdg.gpg hinzu.
? In diesem Tutorial wird ein Root-Konto für die Befehlsausführung verwendet, um die Kompatibilität mit der Demonstration sicherzustellen. Bedenken Sie jedoch, dass die Verwendung eines Nicht-Root-Kontos mit sudo-Berechtigungen sehr ratsam ist. Mit einem Nicht-Root-Konto müssen Sie Ihre Befehle mit
sudofür erhöhte Sicherheit und bewährte Verfahren versehen.
2. Führen Sie anschließend den folgenden Befehl aus. Dieser liefert keine Ausgabe, fügt jedoch das PostgreSQL-Repository zur Liste der Paketquellen in der Datei /etc/apt/sources.list.d/pgdg.list hinzu.
3. Nachdem Sie diese hinzugefügt haben, führen Sie den folgenden Befehl apt update aus, um Ihren Paketindex zu aktualisieren und neuere Paketinformationen abzurufen.
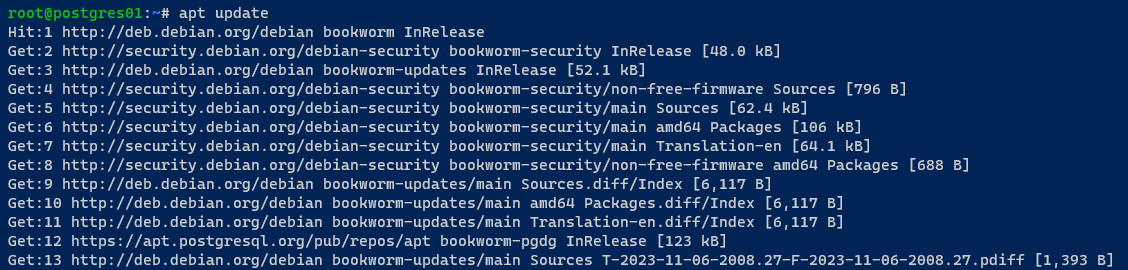
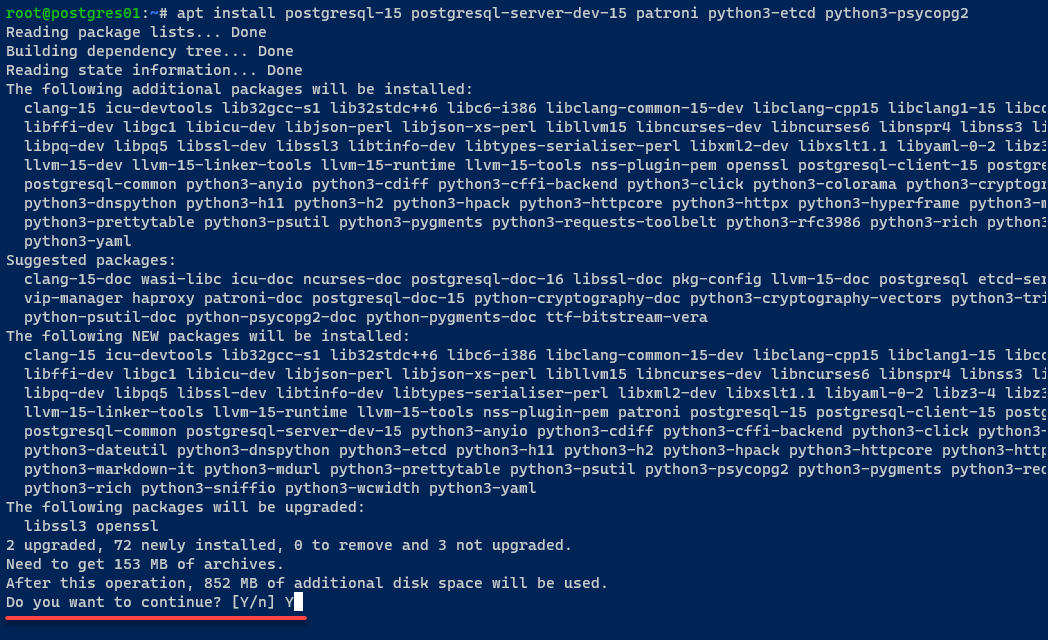
4. Sobald aktualisiert, führen Sie den folgenden Befehl aus, um die folgenden Pakete zu installieren:
postgresql-15– Das PostgreSQL-Datenbankverwaltungssystem Version 15.patroni– Eine Open-Source-Lösung für Hochverfügbarkeit in PostgreSQL, eine Vorlage für PostgreSQL-HA-Cluster unter Verwendung von Python und etcd.python3-etcd– Eine Python-Clientbibliothek zum Interagieren mit etcd, einem verteilten Schlüssel-Wert-Speicher. Diese Bibliothek ermöglicht es Python-Anwendungen, mit etcd-Clustern zu kommunizieren und sie zu verwalten.python3-psycopg2– Ein PostgreSQL-Adapter für Python 3, der Python-Anwendungen und PostgreSQL-Datenbanken verbindet.
Geben Sie bei Bedarf Y ein, um mit der Installation fortzufahren.
5. Nachdem die Pakete installiert sind, führen Sie jeden der folgenden Befehle aus, die keine Ausgabe im Terminal haben, aber folgendes bewirken:
- Stoppen Sie die
postgresql– undpatroni-Dienste. Auf Debian/Ubuntu werden diepostgresql– undpatroni-Dienste automatisch nach der Installation gestartet. - Erstellen Sie einen `symlink` für PostgreSQL-Binärdateien im Verzeichnis `/usr/sbin`. Dadurch kann `patroni` PostgreSQL-Binärdateien ausführen, um PostgreSQL zu erstellen und zu verwalten.
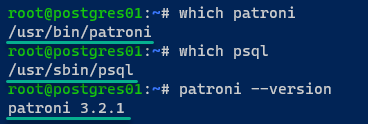
6. Führen Sie abschließend die folgenden Befehle aus, um den Binärpfad für `patroni` und `psql` zu überprüfen, und die installierte `–version` von `patroni`.
Unten finden Sie die Pfade zu den Binärdateien von `patroni` (/usr/bin/patroni) und `psql` (/usr/sbin/psql); die installierte Patroni-Version ist 3.2.1.
Einrichten und Konfigurieren des etcd-Servers
Jetzt, da Sie PostgreSQL-Server und Patroni installiert haben, benötigen Sie eine Grundlage, die die Koordination zwischen Ihren PostgreSQL-Servern für eine nahtlose Hochverfügbarkeit festigt. Sie richten etcd ein, einen Key-Value-Datenspeicher.
Dieser Key-Value-Datenspeicher ist der stille Architekt im Hintergrund, der dafür sorgt, dass Daten im Zusammenhang mit der Bereitstellung Ihres PostgreSQL-Clusters sicher gespeichert und effizient verwaltet werden.
? HINWEIS: Stellen Sie sicher, dass Sie etcd auf einem separaten Server installieren. In diesem Beispiel ist etcd auf dem etcd-Server installiert.
Um etcd zu installieren und zu konfigurieren, befolgen Sie diese Schritte:
1. Auf Ihrem etcd-Server führen Sie den folgenden Befehl aus, um den Repository-Index zu aktualisieren und die neuesten Paketinformationen zu erhalten.
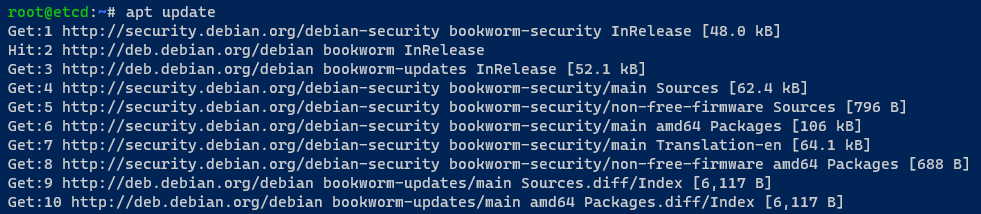
2. Führen Sie anschließend den folgenden Befehl aus, um etcd auf Ihrem Server zu installieren.
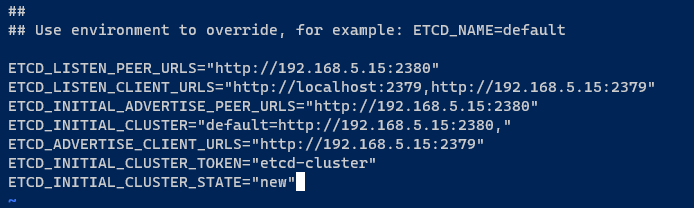
3. Nachdem Sie etcd installiert haben, öffnen Sie die Standardkonfiguration /etc/default/etcd mit Ihrem bevorzugten Editor und fügen Sie die folgende Konfiguration ein.
Diese Konfiguration richtet einen einzelnen etcd-Cluster ein. Stellen Sie sicher, dass Sie die IP-Adresse 192.168.5.15 durch Ihre interne IP-Adresse ersetzen.
ETCD_LISTEN_PEER_URLS="<http://192.168.5.15:2380>"
ETCD_LISTEN_CLIENT_URLS="<http://localhost:2379>,<http://192.168.5.15:2379>"
ETCD_INITIAL_ADVERTISE_PEER_URLS="<http://192.168.5.15:2380>"
ETCD_INITIAL_CLUSTER="default=http://192.168.5.15:2380,"
ETCD_ADVERTISE_CLIENT_URLS="<http://192.168.5.15:2379>"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new" Speichern Sie die Änderungen und verlassen Sie den Editor.
4. Führen Sie nun den folgenden systemctl-Befehl aus, um etcd neu zu starten und Ihre Änderungen anzuwenden.
Dieser Befehl gibt keine Ausgabe aus, aber Sie werden die Änderungen im nächsten Schritt überprüfen.
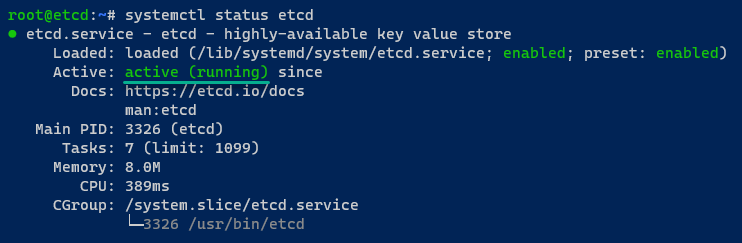
5. Überprüfen Sie nach dem Neustart von etcd, ob der etcd-Dienst läuft und aktiviert ist.
Wenn der etcd-Dienst läuft, sehen Sie die Ausgabe aktiv (läuft). Wenn aktiviert, wird die Ausgabe aktiviert angezeigt, was bedeutet, dass etcd beim Booten automatisch gestartet wird.
6. Führen Sie abschließend den folgenden etcdctl-Befehl aus, um die Liste der verfügbaren Server im etcd-Cluster zu überprüfen.
In diesem Fall läuft etcd als Einzelknoten-Cluster unter der lokalen IP-Adresse http://192.168.5.15:2379/.

Bootstrapping PostgreSQL Cluster via Patroni
Mit dem etcd-Server fest an seinem Platz befinden Sie sich an der Schwelle zur nächsten entscheidenden Phase. Durch Initiieren des Bootstrapping-Prozesses mit Patroni heben Sie Ihre PostgreSQL-Konfiguration auf ein robustes und fehlertolerantes Cluster-Niveau.
? Sichern Sie Ihre Datenbank, bevor Sie ein PostgreSQL-Cluster auf einem vorhandenen PostgreSQL-Server bereitstellen.
Um Ihr PostgreSQL-Cluster über Patroni zu bootstrappen, führen Sie Folgendes auf jedem PostgreSQL-Server aus:
1. Öffnen Sie die Standardkonfiguration von Patroni (/etc/patroni/config.yml) in Ihrem Texteditor und fügen Sie die folgende Konfiguration hinzu.
Stellen Sie sicher, dass Sie den Wert der Option name durch den Hostnamen Ihres PostgreSQL-Servers (z.B. postgres01) ersetzen, schließen Sie den Editor jedoch noch nicht.
Diese Konfiguration richtet Ihr PostgreSQL-Cluster namens postgres ein.
2. Fügen Sie anschließend die folgende Konfiguration hinzu, um die Patroni REST-API unter 192.168.5.20:8008 einzurichten.
Stellen Sie sicher, dass jeder PostgreSQL-Server im Cluster über die API eine Verbindung herstellen kann. Ändern Sie daher die IP-Adresse 192.168.5.20 durch die jeweilige IP-Adresse jedes PostgreSQL-Servers.
3. Fügen Sie die folgende Konfiguration hinzu, um die Integration mit etcd zu aktivieren. In diesem Fall läuft der etcd-Server unter der IP-Adresse 192.168.5.15.
4. Fügen Sie nun die folgende Konfiguration hinzu, um den PostgreSQL-Server über initdb zu bootstrapen.
Diese Konfiguration richtet die Standardregeln und Einstellungen für die Benutzerauthentifizierung (pg_hba.conf) und einen neuen Benutzer admin mit dem Passwort admin ein.
Stellen Sie sicher, dass Sie die IP-Adressen des PostgreSQL-Clusters im Abschnitt pg_hba eingeben und das Standard-Passwort admin im Abschnitt users ändern.
5. Nachdem Sie konfiguriert haben, wie PostgreSQL startet, fügen Sie die folgende Konfiguration ein, um festzulegen, wie PostgreSQL auf jedem Server ausgeführt wird.
Für den Server postgres01 wird PostgreSQL unter der IP-Adresse 192.168.5.20 mit dem Datenverzeichnis /var/lib/patroni ausgeführt.
Zusätzlich erstellt diese Konfiguration einen neuen Benutzer namens replicator für Replikationsoperationen und den Benutzer postgres als Superuser/Administrator mit dem Passwort (secretpassword).
Vergewissern Sie sich, dass Sie die IP-Adresse und das Standardpasswort (secretpassword) ändern.
6. Fügen Sie die folgende Konfiguration ein, um Tags für Ihren PostgreSQL-Server einzurichten, die sein Verhalten im Cluster bestimmen, speichern Sie die Änderungen und schließen Sie die Datei.
7. Mit den gespeicherten Konfigurationen führen Sie die unten stehenden Befehle aus, um das Patroni-Datenverzeichnis gemeinsam vorzubereiten und sicherzustellen, dass es angemessen im Besitz ist und für die Verwendung von PostgreSQL gesichert ist.
Diese Befehle geben keine Ausgabe zurück, aber dieser Schritt ist entscheidend für die Einrichtung eines PostgreSQL-Datenbankclusters mit Patroni für hohe Verfügbarkeit.
8. Führen Sie anschließend die systemctl-Befehle unten aus, um den patroni-Dienst zu starten und zu überprüfen.
Auf dem postgres01-Server läuft der PostgreSQL-Server, und der Cluster initialisiert sich. Außerdem wird der postgres01-Server als Cluster-Leiter ausgewählt.
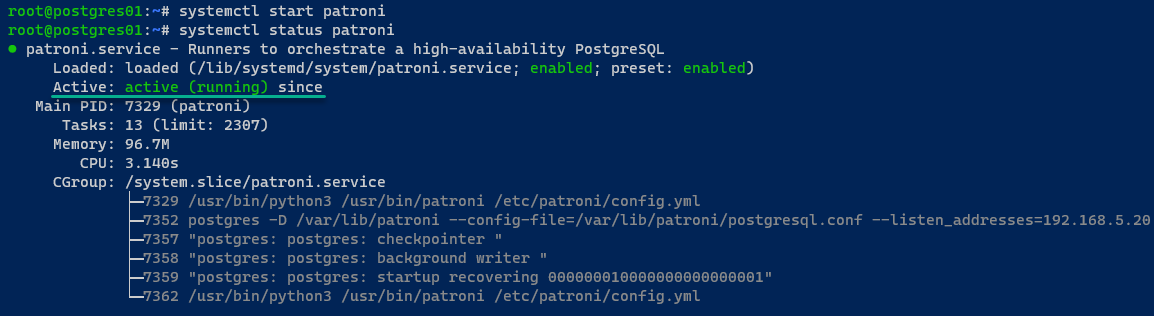
Auf dem postgres02-Server startet der PostgreSQL-Server über Patroni und tritt über die REST-API dem PostgreSQL-Cluster bei.
Wenn alles gut läuft, sehen Sie die folgende Nachricht:
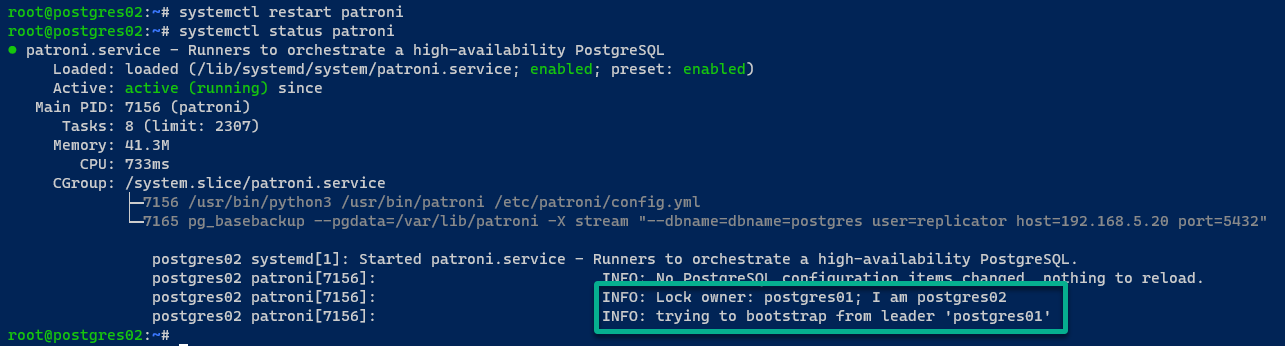
Auf dem postgres03-Server ist die Ausgabe ähnlich wie auf dem postgres02-Server.
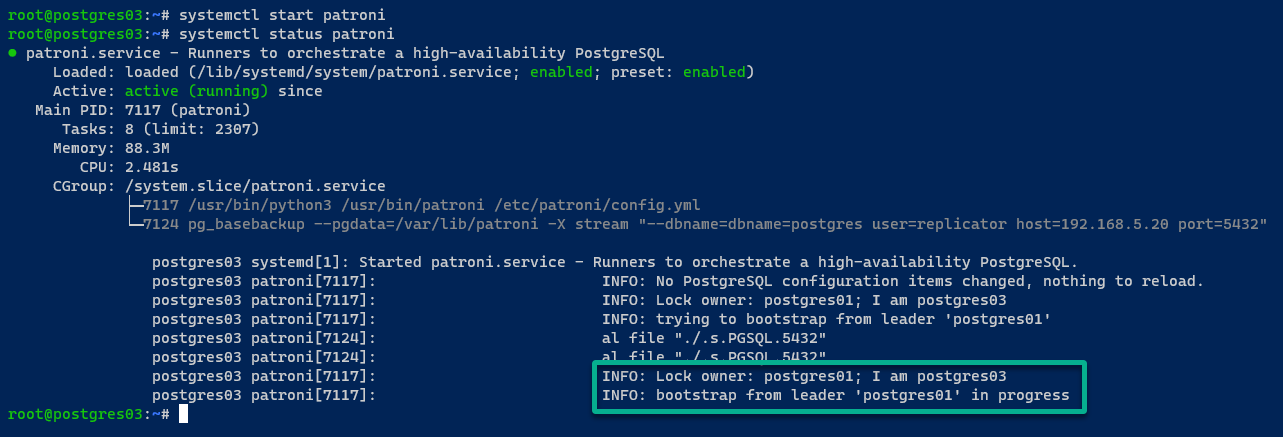
9. Mit Ihrem initialisierten PostgreSQL-Cluster führen Sie den folgenden patronictl-Befehl aus, um eine Liste der von Patroni verwalteten PostgreSQL-Instanzen anzuzeigen.
In der folgenden Ausgabe sehen Sie Ihren PostgreSQL-Cluster (postgres).
Beachten Sie, dass Ihr Cluster mit drei Mitgliedern läuft: postgres01 als Cluster-Leader, postgres02 und postgres03 als Replika im Modus/Zustand Streaming.
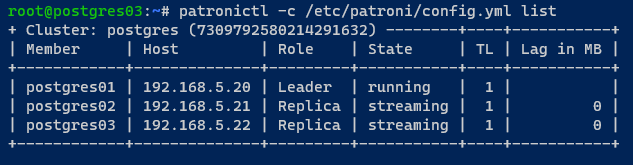
10. Führen Sie abschließend den folgenden systemctl-Befehl aus, um den automatischen Start des postgresql-Dienstes während des Systemstarts zu deaktivieren.
Dieser Befehl gibt keine Ausgabe aus, wenn er erfolgreich ist, ist jedoch entscheidend, da Patroni den neuen PostgreSQL-Server steuert.
Installation und Konfiguration von HAProxy als Lastenausgleicher
Mit Ihrem bereitgestellten PostgreSQL-Cluster, wie können Sie ihn für Clients zugänglich machen und Failover aktivieren, wenn ein Problem auftritt? Die Lösung ist HAProxy als Lastenausgleicher vor Ihrem PostgreSQL-Cluster.
HAProxy ist Ihr Dreh- und Angelpunkt, der es Ihrem PostgreSQL-Cluster ermöglicht, unterschiedliche Workloads zu bewältigen, Anfragen intelligent zu verteilen und eine hohe Verfügbarkeit aufrechtzuerhalten.
? HINWEIS: Installieren Sie HAProxy auf einem separaten Server. In diesem Fall wird der HAProxy-Server auf dem Server mit der IP-Adresse 192.168.5.16 installiert.
Um HAProxy als Lastenausgleicher für den PostgreSQL-Cluster zu installieren und zu konfigurieren, fahren Sie mit diesen Schritten fort:
1. Öffnen Sie die Datei /etc/hosts mit Ihrem bevorzugten Texteditor, fügen Sie die IP-Adressen und Hostnamen Ihrer PostgreSQL-Server ein, speichern Sie die Änderungen und schließen Sie die Datei.
192.168.5.20 postgres01
192.168.5.21 postgres02
192.168.5.22 postgres032. Führen Sie anschließend den folgenden Befehl aus, um Ihren Paketindex zu aktualisieren.
3. Sobald aktualisiert, führen Sie den folgenden Befehl aus, um das haproxy-Paket auf Ihrem System zu installieren.
4. Führen Sie nun den folgenden Befehl aus, um die Standard-HAProxy-Konfiguration in /etc/haproxy/haproxy.cfg.orig zu sichern.
Dieser Befehl gibt keine Ausgabe aus, sondern dient als Vorsichtsmaßnahme, bevor Änderungen vorgenommen werden.
5. Erstellen Sie als nächstes eine neue Datei namens /etc/haproxy/haproxy.cfg mit Ihrem bevorzugten Editor und fügen Sie die folgende Konfiguration ein. Stellen Sie sicher, dass Sie jede PostgreSQL-Server-IP-Adresse durch Ihre eigene ersetzen, speichern Sie die Datei und schließen Sie den Editor.
Diese HAProxy-Konfiguration richtet HAProxy als Lastenausgleicher für Ihren PostgreSQL-Cluster mit zwei Proxys wie folgt ein:
stats– Dieser Block läuft auf Port8080und überwacht die Leistung und Backends des HAProxy-Servers.postgres– Dieser Block ist die Lastenausgleichskonfiguration für den PostgreSQL-Cluster.
# Globale Konfigurationseinstellungen
global
# Maximale Verbindungen global
maxconn 100
# Logging-Einstellungen
log 127.0.0.1 local2
# Standard-Einstellungen
defaults
# Globale Log-Konfiguration
log global
# Modus auf TCP setzen
mode tcp
# Anzahl der Wiederholungsversuche
retries 2
# Client-Timeout
timeout client 30m
# Verbindungs-Timeout
timeout connect 4s
# Server-Timeout
timeout server 30m
# Prüfungs-Timeout
timeout check 5s
# Statistik-Konfiguration
listen stats
# Modus auf HTTP setzen
mode http
# An Port 8080 binden
bind *:8080
# Statistiken aktivieren
stats enable
# Statistik-URI
stats uri /
# PostgreSQL-Konfiguration
listen postgres
# An Port 5432 binden
bind *:5432
# HTTP-Prüfung aktivieren
option httpchk
# Erwarte Status 200
http-check expect status 200
# Server-Einstellungen
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
# PostgreSQL-Server definieren
server postgres01 192.168.5.20:5432 maxconn 100 check port 8008
server postgres02 192.168.5.21:5432 maxconn 100 check port 8008
server postgres03 192.168.5.22:5432 maxconn 100 check port 80086. Nachdem HAProxy konfiguriert wurde, führen Sie die folgenden systemctl-Befehle aus, um den haproxy-Dienst zu neustarten und dessen Status (status) zu überprüfen.
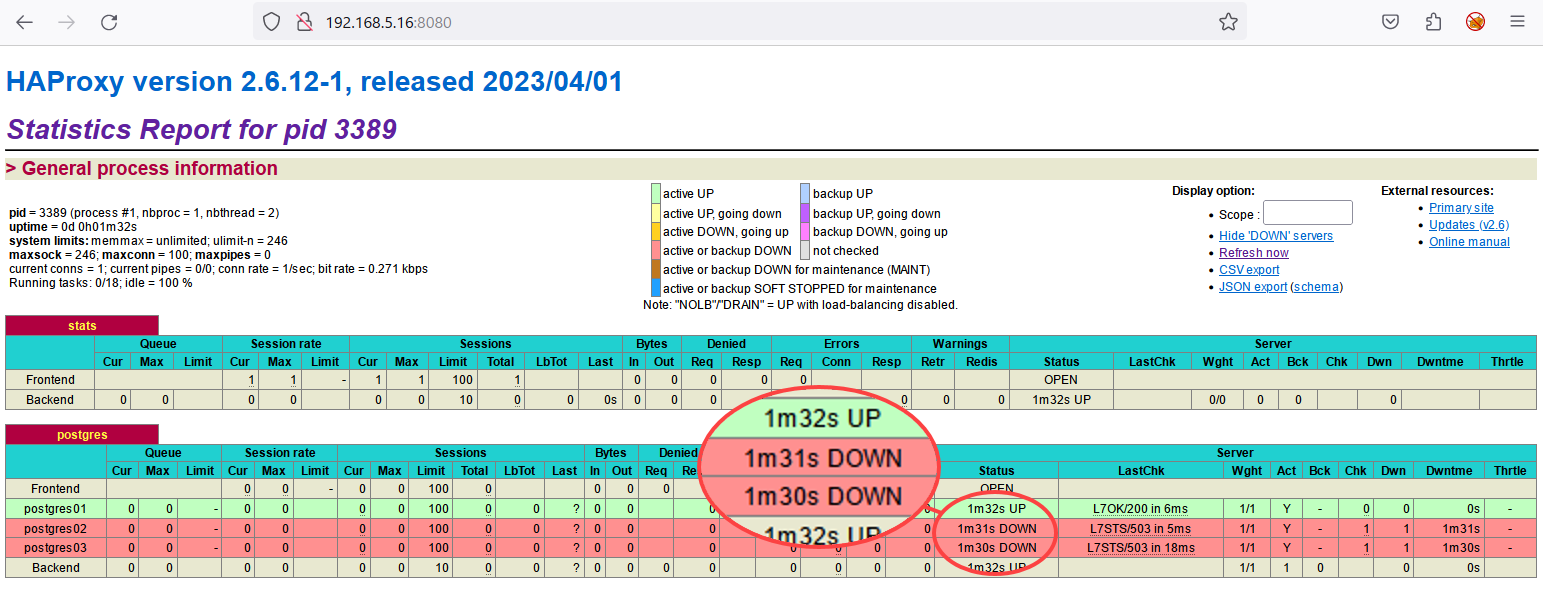
7. Öffnen Sie schließlich Ihren bevorzugten Webbrowser und besuchen Sie die HAProxy-IP-Adresse mit Port 8080 (z.B. http://192.168.5.16:8080/). Im folgenden Ausgabebereich sehen Sie Folgendes:
Im folgenden Ausgabebereich sehen Sie Folgendes:
- Der stats-Proxy zur Überwachung des HAProxy-Status.
- Der postgres-Proxy ist der Load Balancer für den PostgreSQL-Cluster.
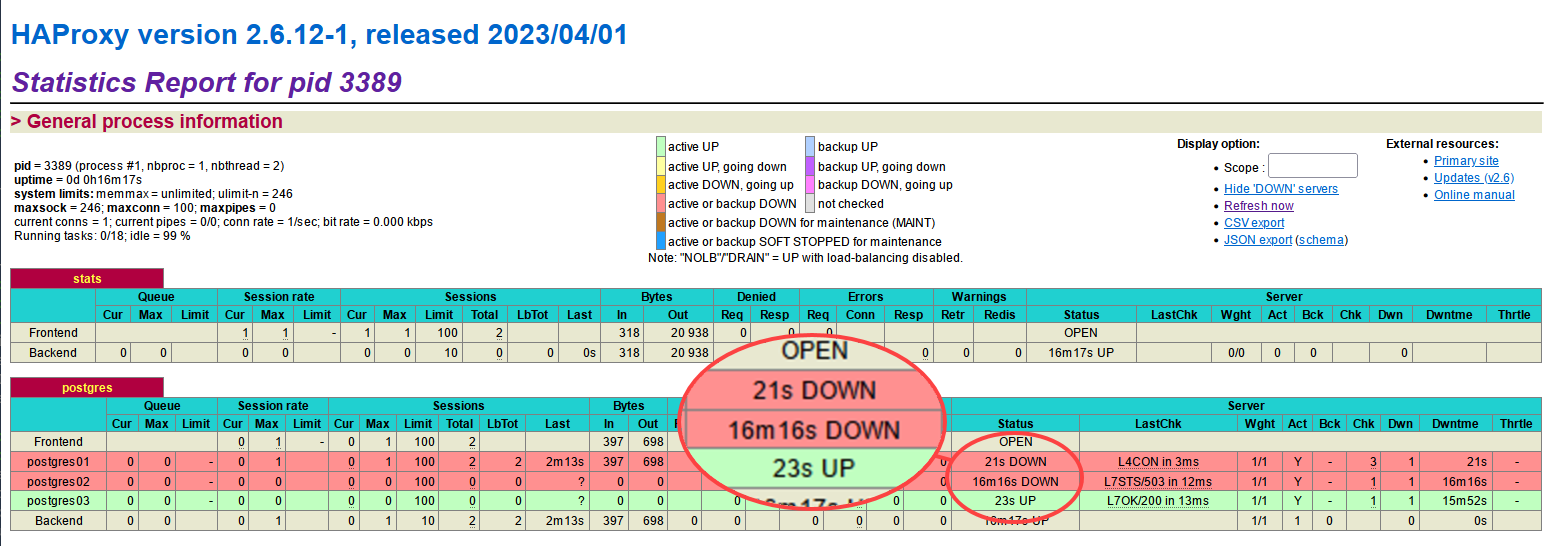
Beachten Sie, dass die Server postgres02 und postgres03 als „down“ markiert sind, da beide im streaming-Modus ausgeführt werden.
Testen des PostgreSQL-Clusters Failover
Nachdem Sie HAProxy als zuverlässigen Lastenausgleicher eingerichtet haben, ist es nun an der Zeit, Ihren PostgreSQL-Cluster zu testen. Dieser entscheidende Schritt wird die Robustheit Ihrer Hochverfügbarkeitskonfiguration offenbaren. Sie müssen sicherstellen, dass Ihr PostgreSQL-Cluster auch bei möglichen Ausfällen robust und reaktionsschnell bleibt.
Um den Failover Ihres PostgreSQL-Clusters zu testen, stellen Sie eine Verbindung zum Cluster von Ihrem Client-Computer her und überprüfen Sie die Failover-Vorgänge mit den folgenden Schritten:
1. Melden Sie sich auf Ihrem Client-Computer an, öffnen Sie ein Terminal und führen Sie den unten stehenden psql-Befehl aus, um eine Verbindung zum PostgreSQL über den HAProxy-Lastenausgleicher herzustellen.
Geben Sie Ihr PostgreSQL-Passwort ein, wenn Sie dazu aufgefordert werden. Die erforderlichen Passwortinformationen finden Sie in der Datei /etc/patroni/config.yml.
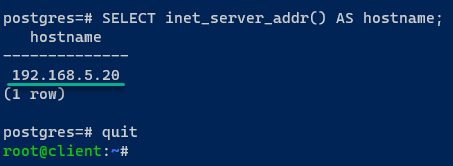
2. Sobald die Verbindung hergestellt ist, führen Sie die folgende Abfrage aus, um zu ermitteln, mit welchem PostgreSQL-Server Sie verbunden sind, und beenden Sie die aktuelle PostgreSQL-Sitzung mit quit.
Wenn Ihre PostgreSQL-Installation erfolgreich ist, sind Sie mit dem Server postgres01 verbunden.
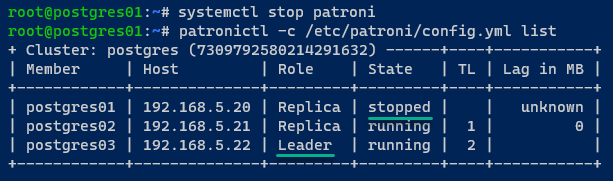
3. Wechseln Sie nun zum Server postgres01, führen Sie die folgenden Befehle aus, um den Dienst patroni zu stoppen und den Status der PostgreSQL-Cluster aufzulisten.
Mit diesem Schritt können Sie den PostgreSQL-Failover testen.
Sie können sehen, dass der Status des Servers postgres01 auf stopped geändert wurde und der neue Cluster-Leader auf den Server postgres03 übertragen wurde.
4. Kehren Sie zu den HAProxy-Überwachungsstatistiken zurück, und Sie werden sehen, dass der Server postgres01 AUS ist, während postgres03 jetzt UP ist.
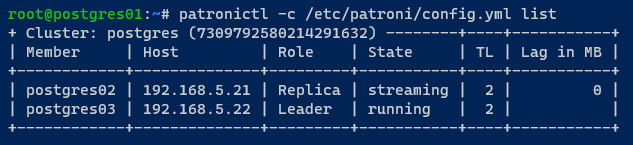
Alternativ führen Sie den folgenden patronictl-Befehl aus, um den Status des PostgreSQL-Clusters zu überprüfen.
Wie Sie unten sehen können, ist der Server postgres01 nicht mehr im Cluster.
5. Wechseln Sie zurück zum Client-Rechner und führen Sie den folgenden psql-Befehl aus, um sich über HAProxy mit dem PostgreSQL-Server zu verbinden.
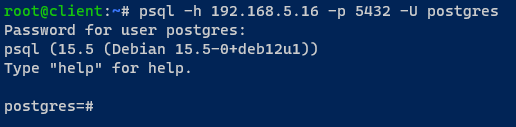
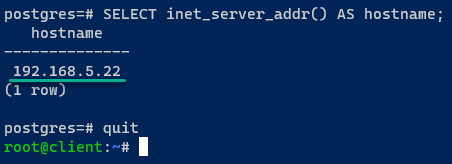
6. Sobald verbunden, führen Sie die folgende Abfrage aus, um den aktuellen PostgreSQL-Server zu überprüfen, mit dem Sie verbunden sind.
Wenn das Failover erfolgreich ist, sind Sie mit einem der ausgeführten Server verbunden, der in diesem Fall postgres03 ist.
Zusammenfassung
Bei dieser Reise haben Sie sich in die Komplexitäten eingetaucht, um die hohe Verfügbarkeit Ihrer PostgreSQL-Datenbank zu gewährleisten, indem Sie die leistungsstarke Kombination aus Patroni und HAProxy eingesetzt haben. Sie haben sich nahtlos durch die Einrichtungsphasen von PostgreSQL und Patroni navigiert und dabei geschickt die Feinheiten der Konfiguration des etcd-Servers gehandhabt.
Ihre Orchestrierungsfähigkeiten kamen zum Vorschein, als Sie einen belastbaren PostgreSQL-Cluster mit Patroni aufgebaut und die Kunst des Lastenausgleichs mit HAProxy verfeinert haben. Der Höhepunkt dieses Abenteuers mit hohem Einsatz war die gründliche Prüfung der Failover-Fähigkeiten Ihres PostgreSQL-Clusters.
Betrachten Sie die Erweiterung Ihres Fachwissens, während Sie über Ihre Erfolge bei der Einrichtung einer robusten und fehlertoleranten PostgreSQL-Umgebung nachdenken. Warum nicht die Implementierung von Patroni mit Kubernetes für eine dynamischere Umgebung erkunden? Oder tauchen Sie in die Feinheiten der Einrichtung von PostgreSQL-Hochverfügbarkeit über mehrere Rechenzentren ein?