













Affrontare la sfida di mantenere un database PostgreSQL resiliente nel sempre mutevole panorama delle esigenze digitali? Se il termine “Patroni” risuona con le tue aspirazioni tecniche, sei sull’orlo di sbloccare una soluzione che eleva PostgreSQL a una fortezza di alta disponibilità.
Certo, una sfida ti attende, ma non temere: stai intraprendendo un viaggio trasformativo per costruire un cluster PostgreSQL imperturbabile. Immagina un futuro in cui le interruzioni del database sono solo piccoli intoppi e il tuo setup PostgreSQL si erge come epitome di affidabilità.
Preparati a fortificare il tuo ambiente PostgreSQL in una bastione indistruttibile!
Prerequisiti
Prima di passare all’implementazione dell’alta disponibilità per PostgreSQL, assicurati di avere quanto segue:
- Cinque (o più) server Linux – Questo tutorial utilizza server Debian 12, ognuno con un utente non-root con privilegi sudo/amministratore come segue:
| Hostname | IP Address | Used as |
|---|---|---|
| postgres01 | 192.168.5.20 | PostgreSQL Server |
| postgres02 | 192.168.5.21 | PostgreSQL Server |
| postgres03 | 192.168.5.22 | PostgreSQL Server |
| etcd | 192.168.5.15 | Cluster Data Store |
| haproxy | 192.168.5.16 | Load Balancer |
- A client machine (Linux, Windows, or MacOS) with a PostgreSQL client installed.
Installazione del server PostgreSQL e di Patroni
Con tutti i prerequisiti soddisfatti, immagina questo momento come il fondamento per un ambiente database robusto e sicuro. L’obiettivo è creare un’implementazione di PostgreSQL ad alta disponibilità tramite PostgreSQL 15. Ma prima, devi installare i pacchetti richiesti (server PostgreSQL e Patroni) su tutti i tuoi server PostgreSQL.
Patroni è un’applicazione basata su Python per creare un’implementazione di PostgreSQL ad alta disponibilità nei tuoi data center, da metallo nudo a Kubernetes. Patroni è disponibile nel repository ufficiale di PostgreSQL e supporta server PostgreSQL dalla versione 9.5 alla 16.
Per installare il server PostgreSQL e Patroni, esegui le seguenti operazioni:
? NOTA: Completa le seguenti operazioni sui server PostgreSQL. In questo caso,
postgres01,postgres02epostgres03.
1. Apri un terminale e esegui il comando curl di seguito, che non produce output ma aggiunge la chiave GPG per il repository di PostgreSQL a /usr/share/keyrings/pgdg.gpg.
? Questo tutorial utilizza un account root per l’esecuzione dei comandi per garantire la compatibilità della dimostrazione. Tuttavia, ricorda che è altamente consigliabile utilizzare un account non-root con privilegi sudo. Con un account non-root, è necessario prefissare i comandi con
sudoper una maggiore sicurezza e le migliori pratiche.
2. Successivamente, esegui il seguente comando, che non fornisce output ma aggiunge il repository di PostgreSQL alla lista delle fonti dei pacchetti nel file /etc/apt/sources.list.d/pgdg.list.
3. Una volta aggiunto, esegui il seguente comando apt update per aggiornare l’indice dei pacchetti e ottenere informazioni sui pacchetti più recenti.
4. Una volta aggiornato, esegui il seguente comando per installare i pacchetti seguenti:
postgresql-15– Il sistema di gestione del database PostgreSQL versione 15.patroni– Una soluzione open-source per l’alta disponibilità in PostgreSQL, un modello per cluster HA di PostgreSQL che utilizza Python ed etcd.python3-etcd– Una libreria client Python per interagire con etcd, uno store chiave-valore distribuito. Questa libreria permette alle applicazioni Python di comunicare con e gestire cluster etcd.python3-psycopg2– Un adattatore PostgreSQL per Python 3, che connette applicazioni Python e database PostgreSQL.
Immetti Y per procedere con l’installazione quando richiesto.
5. Con i pacchetti installati, esegui ciascun comando qui sotto, che non produce output nel terminale ma esegue le seguenti operazioni:
- Ferma i servizi
postgresqlepatroni. Su Debian/Ubuntu, i servizipostgresqlepatronivengono avviati automaticamente dopo l’installazione. - Creare un symlink per i file binari di PostgreSQL nella directory `/usr/sbin`. In questo modo si assicura che `patroni` possa eseguire i file binari di PostgreSQL per creare e gestire PostgreSQL.
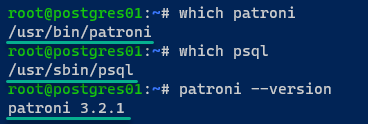
6. Infine, eseguire i seguenti comandi per verificare il percorso binario per `patroni` e `psql`, e la versione installata di `patroni` con `–version`.
Di seguito i percorsi per i file binari di `patroni` (/usr/bin/patroni) e `psql` (/usr/sbin/psql); la versione di Patroni installata è 3.2.1.
Configurazione e installazione del server etcd
Ora che hai installato il server PostgreSQL e Patroni, hai bisogno di un supporto che solidifichi il coordinamento tra i tuoi server PostgreSQL per un’alta disponibilità senza interruzioni. Configurerai e installerai etcd, un archivio dati chiave-valore.
Questo archivio dati chiave-valore è l’architetto silenzioso dietro le quinte, garantendo che i dati relativi alla distribuzione del tuo cluster PostgreSQL siano archiviati in modo sicuro e gestiti in modo efficiente.
? NOTA: Assicurati di installare etcd su un server separato. In questo esempio, etcd è installato sul server etcd.
Per installare e configurare etcd, segui questi passaggi:
1. Sul tuo server etcd, esegui il comando seguente per aggiornare l’indice del repository e ottenere le ultime informazioni sui pacchetti.
2. Successivamente, esegui il comando sottostante per installare etcd sul tuo server.
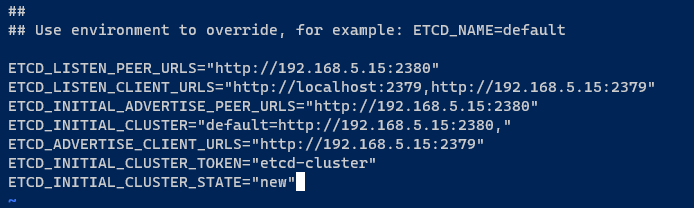
3. Una volta installato etcd, apri la configurazione predefinita /etc/default/etcd utilizzando l’editor preferito e inserisci la seguente configurazione.
Questa configurazione imposta un singolo cluster etcd, quindi assicurati di cambiare l’indirizzo IP 192.168.5.15 con il tuo indirizzo IP interno.
ETCD_LISTEN_PEER_URLS="<http://192.168.5.15:2380>"
ETCD_LISTEN_CLIENT_URLS="<http://localhost:2379>,<http://192.168.5.15:2379>"
ETCD_INITIAL_ADVERTISE_PEER_URLS="<http://192.168.5.15:2380>"
ETCD_INITIAL_CLUSTER="default=http://192.168.5.15:2380,"
ETCD_ADVERTISE_CLIENT_URLS="<http://192.168.5.15:2379>"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new" Salva le modifiche ed esci dall’editor.
4. Ora, esegui il comando systemctl qui sotto per riavviare etcd e applicare le tue modifiche.
Questo comando non ha output, ma verificherai le modifiche nel passaggio successivo.
5. Una volta riavviato etcd, verifica che il servizio etcd sia in esecuzione e abilitato.
Se il servizio etcd è in esecuzione, dovresti vedere un output attivo (in esecuzione). Quando abilitato, vedrai l’output abilitato, che significa anche che etcd si avvierà automaticamente all’avvio.
6. Infine, esegui il seguente comando etcdctl qui sotto per verificare l’elenco dei server disponibili nel cluster etcd.
In questo caso, etcd funziona come un cluster a singolo nodo su un indirizzo IP locale http://192.168.5.15:2379/.

Avvio del Cluster PostgreSQL tramite Patroni
Con il server etcd ora saldamente in posizione, ti trovi alla soglia della fase cruciale successiva. Iniziando il processo di avvio tramite Patroni, elevi la configurazione di PostgreSQL in un cluster robusto e tollerante ai guasti.
? Assicurati di eseguire il backup del tuo database prima se stai implementando un cluster PostgreSQL su un server PostgreSQL esistente.
Per avviare il tuo cluster PostgreSQL tramite Patroni, esegui quanto segue su ciascun server PostgreSQL:
1. Apri la configurazione predefinita di Patroni (/etc/patroni/config.yml) nel tuo editor di testo e aggiungi la seguente configurazione.
Assicurati di sostituire il valore dell’opzione name con l’hostname del tuo server PostgreSQL (cioè postgres01), ma non chiudere ancora l’editor.
Questa configurazione imposta il tuo cluster PostgreSQL chiamato postgres.
2. Successivamente, aggiungi la configurazione seguente per impostare l’API REST di Patroni in esecuzione su 192.168.5.20:8008.
Assicurati che ciascuno dei server PostgreSQL all’interno del cluster possa connettersi tramite API. Cambia quindi l’indirizzo IP 192.168.5.20 con l’indirizzo IP rispettivo di ciascun server PostgreSQL.
3. Aggiungi la configurazione di seguito per abilitare l’integrazione con etcd. In questo caso, il server etcd è in esecuzione sull’indirizzo IP 192.168.5.15.
4. Ora, aggiungi la configurazione di seguito per bootstrap il server PostgreSQL tramite initdb.
Questa configurazione imposta le regole e le impostazioni predefinite per l’autenticazione del client (pg_hba.conf) e un nuovo utente admin con la password admin.
Assicurati di inserire gli indirizzi IP del cluster PostgreSQL nella sezione pg_hba e cambiare la password predefinita admin nella sezione users.
5. Dopo aver configurato come avvia PostgreSQL, inserisci la seguente configurazione per impostare come PostgreSQL funziona su ogni server.
Per quanto riguarda il server postgres01, PostgreSQL funzionerà sull’indirizzo IP 192.168.5.20 con la directory dei dati /var/lib/patroni.
Inoltre, questa configurazione crea un nuovo utente chiamato replicator per l’operazione di replica, e l’utente postgres come superutente/amministratore con la password (secretpassword).
Assicurati di cambiare l’indirizzo IP e la password predefinita (secretpassword).
6. Inserire la seguente configurazione per impostare i tag del server PostgreSQL che ne determinano il comportamento nel cluster, salvare le modifiche e chiudere il file.
7. Con le configurazioni salvate, esegui i comandi di seguito per preparare collettivamente la directory dei dati di Patroni, assicurandoti che sia di proprietà e sicura per l’uso di PostgreSQL.
Questi comandi non forniscono output, ma questo passaggio è cruciale per configurare un cluster di database PostgreSQL con Patroni per l’alta disponibilità.
8. Successivamente, esegui i comandi systemctl di seguito per avviare e verificare il servizio patroni.
Sul server postgres01, viene eseguito il server PostgreSQL e si inizializza il cluster. Inoltre, il server postgres01 viene selezionato come leader del cluster.
Sul server postgres02, il server PostgreSQL viene avviato tramite Patroni e si unisce al cluster PostgreSQL tramite REST API.
Se tutto va bene, vedrai il seguente messaggio:
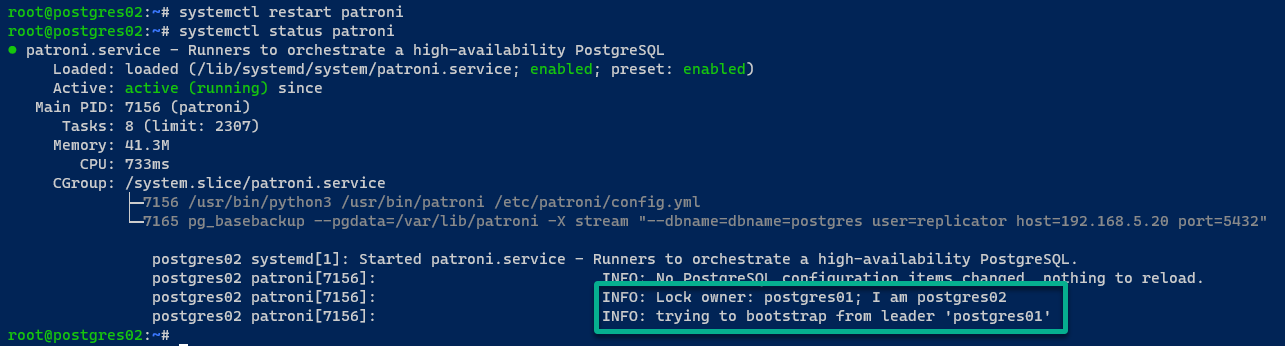
Sul server postgres03, l’output è simile a quello del server postgres02.
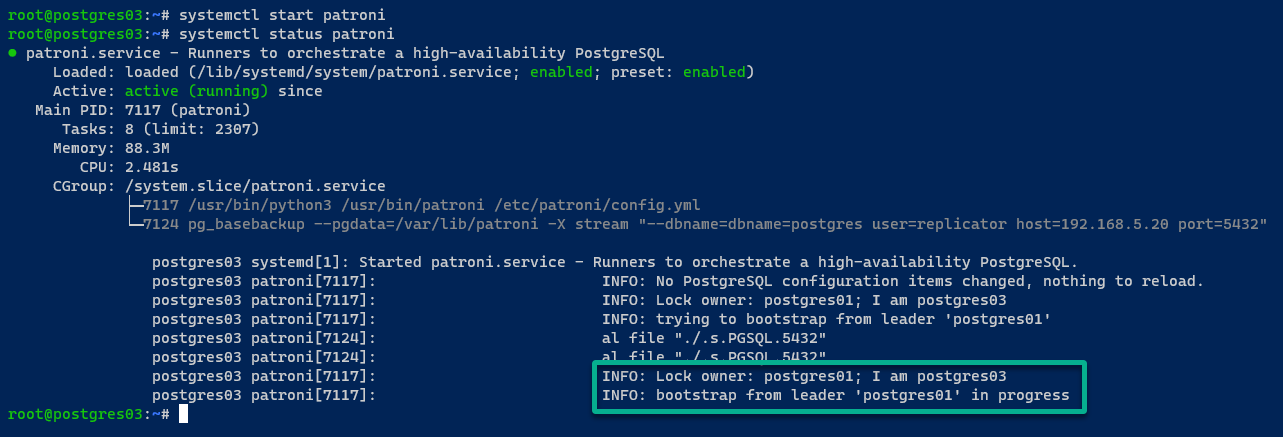
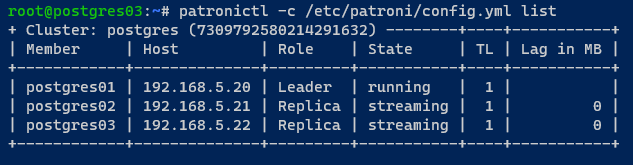
9. Con il tuo cluster PostgreSQL inizializzato, esegui il seguente comando patronictl per visualizzare un elenco delle istanze PostgreSQL gestite da Patroni.
Nell’output seguente, puoi vedere che il tuo cluster PostgreSQL (postgres) è in esecuzione.
Nota che il tuo cluster è in esecuzione con tre membri: postgres01 come Leader, postgres02 e postgres03 come Replica con modalità/stato streaming.
10. Infine, esegui il comando systemctl qui sotto per disabilitare l’avvio automatico del servizio postgresql durante l’avvio del sistema.
Questo comando non ha output se eseguito con successo ma è cruciale poiché Patroni controlla il nuovo server PostgreSQL.
Installazione e Configurazione di HAProxy come Bilanciatore di Carico
Con il tuo cluster PostgreSQL distribuito, come puoi renderlo accessibile dai client e abilitare il failover in caso di problemi? La soluzione è HAProxy come bilanciatore di carico prima del tuo cluster PostgreSQL.
HAProxy è il tuo perno che consente al tuo cluster PostgreSQL di gestire carichi di lavoro variabili, distribuire richieste intelligentemente e mantenere un’elevata disponibilità.
? NOTA: Installa HAProxy su un server separato. In questo caso, il server HAProxy è installato sul server haproxy con l’indirizzo IP 192.168.5.16.
Per installare e configurare HAProxy come bilanciatore di carico per il cluster PostgreSQL, procedi con questi passaggi:
1. Apri il file /etc/hosts utilizzando il tuo editor di testo preferito, inserisci gli indirizzi IP e i nomi host dei tuoi server PostgreSQL, salva le modifiche e chiudi il file.
192.168.5.20 postgres01
192.168.5.21 postgres02
192.168.5.22 postgres032. Successivamente, esegui il comando di seguito per aggiornare l’indice dei pacchetti.
3. Una volta aggiornato, esegui il comando seguente per installare il pacchetto haproxy nel tuo sistema.
4. Ora, esegui il seguente comando per eseguire il backup della configurazione predefinita di HARPOXY in /etc/haproxy/haproxy.cfg.orig.
Questo comando non produce output ma è una misura precauzionale prima di apportare modifiche.
5. Successivamente, crea un nuovo file chiamato /etc/haproxy/haproxy.cfg utilizzando il tuo editor preferito e inserisci la seguente configurazione. Assicurati di sostituire ogni indirizzo IP del server PostgreSQL con il tuo, salva il file e chiudi l’editor.
Questa configurazione di HAProxy imposta HAProxy come bilanciatore di carico per il tuo cluster PostgreSQL con due proxy, come segue:
stats– Questo blocco funziona sulla porta8080e monitora le prestazioni del server HAProxy e dei backend.postgres– Questo blocco è la configurazione del bilanciatore di carico per il cluster PostgreSQL.
# Impostazioni di configurazione globale
global
# Numero massimo di connessioni globali
maxconn 100
# Impostazioni di registrazione
log 127.0.0.1 local2
# Impostazioni predefinite
defaults
# Configurazione globale dei log
log global
# Imposta la modalità su TCP
mode tcp
# Numero di tentativi
retries 2
# Timeout del client
timeout client 30m
# Timeout di connessione
timeout connect 4s
# Timeout del server
timeout server 30m
# Timeout del controllo
timeout check 5s
# Configurazione delle statistiche
listen stats
# Imposta la modalità su HTTP
mode http
# Associa alla porta 8080
bind *:8080
# Abilita le statistiche
stats enable
# URI delle statistiche
stats uri /
# Configurazione di PostgreSQL
listen postgres
# Associa alla porta 5432
bind *:5432
# Abilita il controllo HTTP
option httpchk
# Si aspetta lo status 200
http-check expect status 200
# Impostazioni del server
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
# Definizione dei server PostgreSQL
server postgres01 192.168.5.20:5432 maxconn 100 check port 8008
server postgres02 192.168.5.21:5432 maxconn 100 check port 8008
server postgres03 192.168.5.22:5432 maxconn 100 check port 80086. Con HAProxy configurato, eseguire i comandi di systemctl di seguito per riavviare e verificare (status) il servizio haproxy.
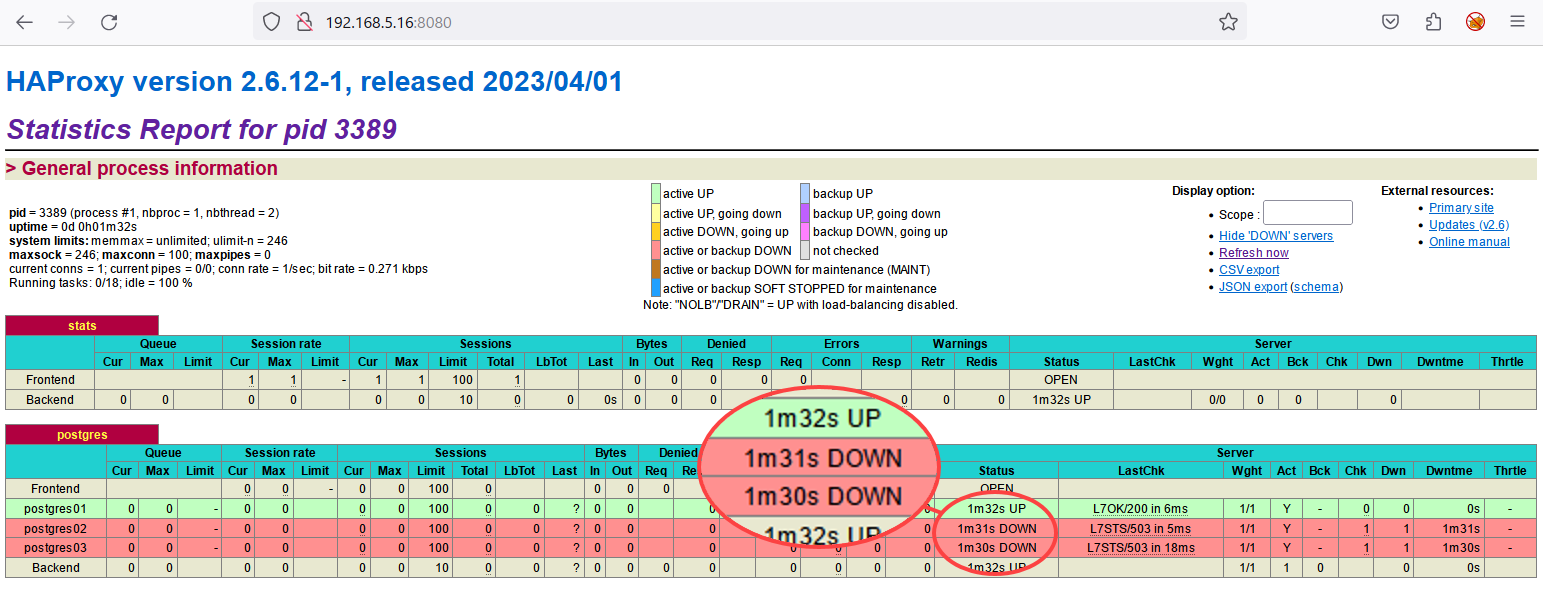
7. Infine, aprire il browser web preferito e visitare l’indirizzo IP di HAProxy con la porta 8080 (ad esempio, http://192.168.5.16:8080/). Nel risultato seguente, è possibile vedere quanto segue:
Nel risultato seguente, è possibile vedere quanto segue:
-
Il proxy stats per monitorare lo stato di HAProxy.
-
Il proxy postgres è il bilanciatore di carico per il cluster PostgreSQL.
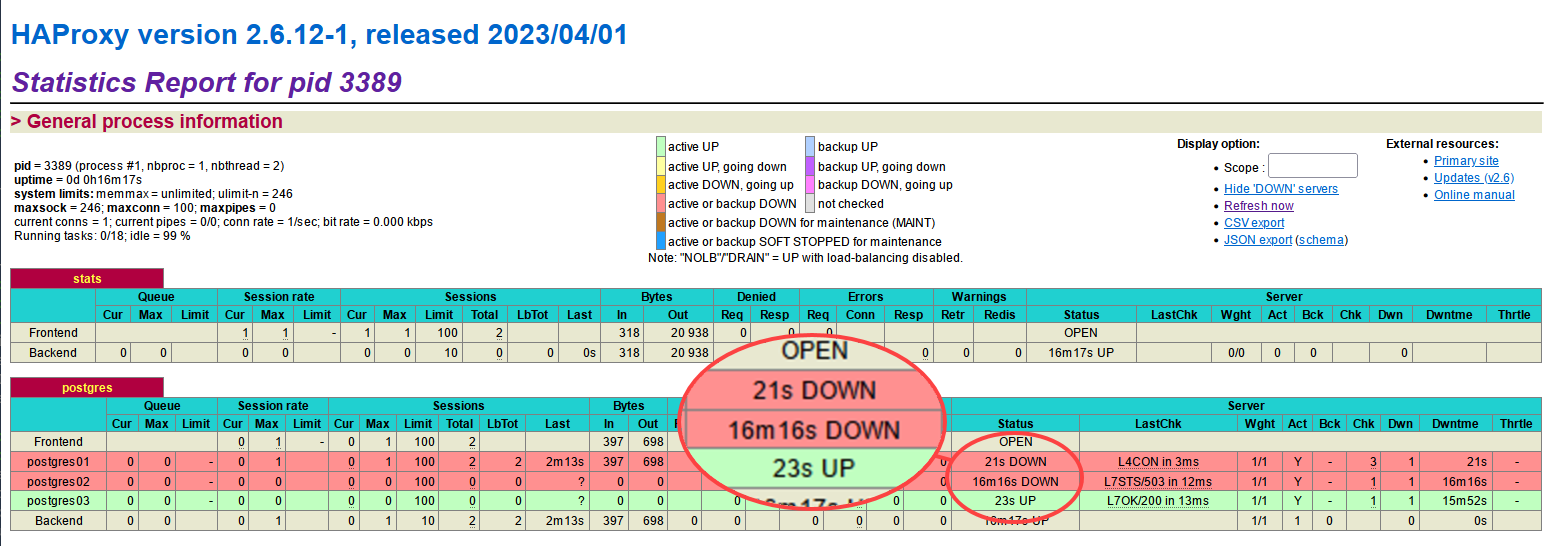
Notare che i server postgres02 e postgres03 sono contrassegnati come inattivi perché entrambi sono in modalità streaming.
Testing del Failover del Cluster PostgreSQL
Emergendo dalla configurazione di HAProxy come il tuo affidabile bilanciatore di carico, è ora il momento di mettere alla prova il tuo cluster PostgreSQL. Questo passaggio cruciale rivelerà la resilienza della tua configurazione ad alta disponibilità. Devi assicurarti che il tuo cluster PostgreSQL rimanga robusto e reattivo anche di fronte a potenziali guasti.
Per testare il failover del tuo cluster PostgreSQL, ti connetterai al cluster dalla tua macchina client e verificherai le operazioni di failover con i seguenti passaggi:
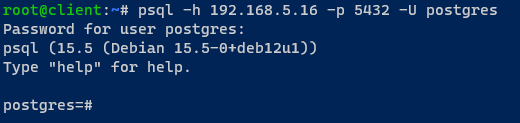
1. Accedi alla tua macchina client, apri un terminale e esegui il comando psql di seguito per connetterti a PostgreSQL tramite il bilanciatore di carico HAProxy.
Inserisci la password del tuo PostgreSQL quando richiesto. Puoi trovare le informazioni sulla password necessarie nel file /etc/patroni/config.yml.
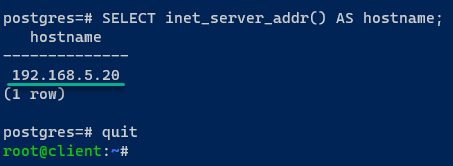
2. Una volta connesso, esegui la query seguente per scoprire a quale server PostgreSQL sei connesso, e quit dalla sessione corrente di PostgreSQL.
Se l’installazione di PostgreSQL è riuscita, sarai connesso al server postgres01.
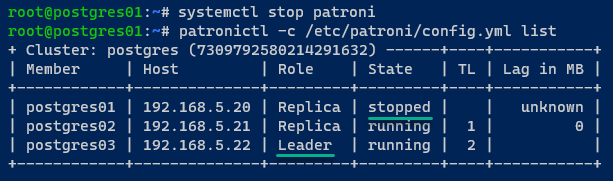
3. Ora, passa al server postgres01, esegui i comandi seguenti per fermare il servizio patroni e list lo stato dei cluster PostgreSQL.
Questo passaggio ti consente di testare il failover di PostgreSQL.
Puoi vedere che lo stato del server postgres01 è cambiato a stopped, e il nuovo leader del cluster è delegato al server postgres03.
4. Torna alle statistiche di monitoraggio di HAProxy e vedrai che il server postgres01 è INATTIVO, mentre postgres03 è ora ATTIVO.
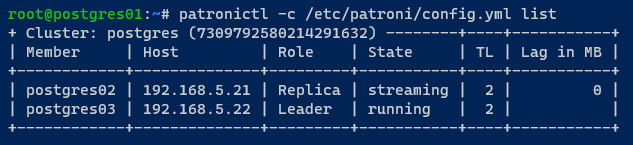
In alternativa, esegui il seguente comando patronictl per verificare lo stato del cluster PostgreSQL.
Come puoi vedere qui sotto, il server postgres01 non fa più parte del cluster.
5. Torna alla macchina client e esegui il seguente comando psql per connetterti al server PostgreSQL tramite HAProxy.
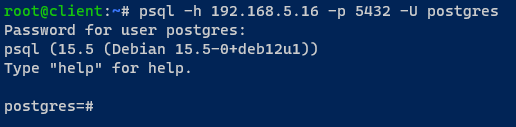
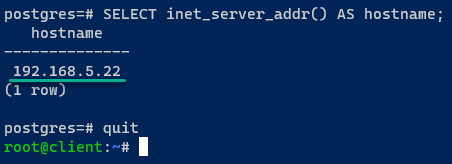
6. Una volta connesso, esegui la seguente query per verificare il server PostgreSQL attualmente connesso.
Se il failover ha avuto successo, sarai connesso a uno dei server attivi, che in questo caso è postgres03.
Conclusion
Imbarcandoti in questo viaggio, ti sei immerso nelle complessità dell’assicurare l’alta disponibilità per il tuo database PostgreSQL, impiegando la potente combinazione di Patroni e HAProxy. Navigando senza intoppi attraverso le fasi di configurazione di PostgreSQL e Patroni, hai gestito abilmente le sfumature della configurazione del server etcd.
Le tue competenze di orchestrazione sono emerse mentre costruivi un cluster PostgreSQL resiliente con Patroni e affinavi l’arte del bilanciamento del carico usando HAProxy. La culminazione di questa avventura ad alto rischio è stata la completa prova delle capacità di failover del tuo cluster PostgreSQL.
Considera l’espansione delle tue competenze mentre rifletti sui tuoi successi nell’istituire un ambiente PostgreSQL robusto e tollerante ai guasti. Perché non esplorare l’implementazione di Patroni con Kubernetes per un ambiente più dinamico? O approfondire le complessità dell’implementazione dell’Alta Disponibilità di PostgreSQL su più data center?