













Optimisaties algoritmen spelen een cruciale rol in diep leren: ze finetunen modelgewichten om verliesfuncties te minimaliseren tijdens het trainen. Een dergelijk algoritme is deAdam optimizer.
Adam werd uitzonderlijk populair in diep leren door zijn mogelijkheid om de voordelen van momentum en aanpassende leerraten te combineren. Dit maakte hem erg efficiënt voor het trainen van diepe neurale netwerken. Ook vereist het minimaal het aanpassen van hyperparameters, waardoor hij breed toegankelijk en effectief is voor diverse taken.
In 2017 introduceerden Ilya Loshchilov en Frank Hutter een meer geavanceerde versie van de populaire Adam-algoritme in hun paper “Decoupled Weight Decay Regularization.” Ze noemden het AdamW, dat uitstekend is voor het decouplen van gewichtsverlies van de gradiënt-updateproces. Deze scheiding is een cruciale verbetering ten opzichte van Adam en helpt met betere modelgeneralisatie.
AdamW is steeds belangrijker in moderne diepgeleerde toepassingen, met name in het behandelen van grote modellen. zijn bovenstaande vermogen om gewichtswijzigingen te reguleren heeft bijgedragen aan zijn invoering in taken die hoge prestaties en stabiliteit vereisen.
In dit handleiding zullen we de kernverschillen tussen Adam en AdamW aansnijden, evenals de verschillende toepassingsgebieden, en we zullen een stap-voor-stap gids implementeren voor het toepassen van AdamW inPyTorch.
Adam vs AdamW
Adam en AdamW zijn beide adaptieve optimalizers die breed worden gebruikt in diep geleren. Het grote verschil tussen hen is hoe ze gewicht regularisatie behandelen, wat hun effectiviteit in verschillende scenario’s beïnvloedt.
Terwijl Adam momentum en adaptieve leerraten combineert om efficiente optimalisatie te bieden, incorporeert het L2-regularisatie in een manier die de prestatie kunnen belemmeren. AdamW werkt dit aan door de groepsdecompositie van gewichtsafname van de leeringsnelheid af te splitsen, waardoor een effectiever aanpak voor grote modellen ontstaat en de generalisatie verbeterd wordt. Gewichtsafname, een vorm van L2-regularisatie, strafte grote gewichten in het model. Adam integreert gewichtsafname in het proces van de gradiëntupdate, terwijl AdamW dit apart toepast na de gradiëntupdate
Hier zijn enkele andere manieren waarop ze verschillen:
Belangrijke verschillen tussen Adam en AdamW
Alhoewel beide optimalisatoren zijn ontworpen om momentum te beheren en leeringsnelheden dynamisch aan te passen, verschillen ze fundamenteel in hun behandeling van gewichtsafname.
In Adam wordt gewichtsafname indirect toegepast als onderdeel van de gradientenupdate, wat ongewenst de leeringsdynamiek kan wijzigen en de optimalisatieproces kan verstoren. AdamW, echter, scheidt gewichtsafname af van de gradienten stap, waardoor de regularisatie direct invloed uitoeft op de parameters zonder de adaptieve leermechaniek te veranderen.
Dit ontwerp leidt tot een nauwkeurigere regularisatie, die modellen beter helpt generaliseren, vooral bij taken die grote en complexe datasets bevatten. Als resultaat zijn de twee optimalisatoren vaak voor heel verschillende toepassingen geschikt.
Toepassingen voor Adam
Adam presteert beter in taken waarin regularisatie minder crucial is of wanneer de computatieve efficiëntie prioriteit heeft boven generalisatie. Voorbeelden hiervan zijn:
- Kleinere neurale netwerken. Voor taken als basislijn classificatie met kleine CNN’s (Convolutionele neurale netwerken) op datasetten als MNIST of CIFAR-10, waar de modelcomplexiteit laag is, kan Adam efficiënt optimaleren zonder uitgebreide regularisatie nodig te hebben.
- Eenvoudige regressieproblemen. Voor eenvoudige regressietaken met beperkte kenmerkensets, zoals het voorschatten van huizenprijzen met behulp van een lineaire regressiemodel, kan Adam snel convergeren zonder complexe regularisatietechnieken nodig te hebben.
- Eerste fase prototyping. Tijdens de beginfases van modelontwikkeling, waar snelle experimenten nodig zijn, staat Adam toe snelle iteraties uit te voeren op eenvoudige architecturen, die onderzoekers helpen problemen te identificeren zonder de overhead van het afstemmen van regularisatieparameters.
- Minder ruisige gegevens. Bij het werken met schone datasetten met minimale ruis, zoals goed gecurateerde tekstgegevens voor sentimentanalyse, kan Adam effectief patronen leren zonder het risico van overfitting dat misschien sterker regularisatie nodig maakt.
- Korte training cyclus. In scenario’s met tijdbeperkingen, zoals snelle modeluitrollen voor real-time-toepassingen, kan de efficiente optimalisatie van Adam snel acceptabele resultaten leveren, zelfs als ze niet volledig zijn geoptimaliseerd voor generalisatie.
Toepassingen van AdamW.
AdamW presteert uitstekend in scenario’s waar overfitting een probleem is en de grootte van het model substraat is. Bijvoorbeeld:
- Grote schaal transformatoren. Bij natuurlijke taalverwerkingstaken, zoals het finetuneren van modellen zoals GPT op uitgebreide tekstcorpora, helpt AdamW’s vermogen om gewichtsveroudering effectief te beheersen om overfitting te voorkomen, waardoor er betere generalisatie wordt gegarandeerd.
- Complexe computervisualisaties modellen. Voor taken die betrekking hebben op diepe convolutionele neurale netwerken (CNN’s) die zijn getraind op grote datasets zoals ImageNet, helpt AdamW de stabiliteit en prestatie van het model te behouden door de gewichtsveroudering van elkaar te decoupleren, wat crucial is voor het behalen van hoge nauwkeurigheid.
- Multi-taak lerenIn scenario’s waarin een model tegelijkertijd op meerdere taken wordt getraind, biedt AdamW de flexibiliteit om diverse datasets te behandelen en overkoppeling op een enkele taak te voorkomen.
- Generatieve modellenVoor het trainen van generatieve tegengestelde netwerken (GAN’s), waarbij het handhaven van een evenwicht tussen de generator en de discriminator cruciaal is, kan de verbeterde regularisatie van AdamW de training stabiliseren en de kwaliteit van de gegenereerde output verbeteren.
- Reinforcement learningIn reinforcement learning-toepassingen waar modellen zich moeten aanpassen aan complexe omgevingen en robuuste beleidslijnen moeten leren, helpt AdamW overfitting op specifieke staten of acties tegen te gaan, waardoor de algemene prestaties van het model in verschillende situaties worden verbeterd.
Voordelen van AdamW ten opzichte van Adam
Maar waarom zou iemand AdamW willen gebruiken in plaats van Adam? Simpel. AdamW biedt verschillende belangrijke voordelen die zijn prestaties, vooral in complexe modelleerscenario’s, verbeteren.
Het pakt enkele beperkingen aan die in de Adam-optimizer worden gevonden, waardoor het effectiever is bij optimalisatie en bijdraagt aan verbeterde modeltraining en robuustheid.
Hier zijn nog enkele opvallende voordelen:
- Ontkoppeld gewichtsverval.Door gewichtsverval te scheiden van gradiëntupdates, maakt AdamW een nauwkeurigere controle over regularisatie mogelijk, wat leidt tot betere modelgeneralisatie.
- Verbeterde generalisatie. AdamW vermindert het risico op overfitting, vooral bij grootschalige modellen, waardoor het geschikt is voor taken met uitgebreide datasets en ingewikkelde architecturen.
- Stabiliteit tijdens het trainen. Het ontwerp van AdamW helpt de stabiliteit te behouden gedurende het hele trainingsproces, wat essentieel is voor modellen die een voorzichtige afstemming van hun hyperparameters vereisen.
- Schaalbaarheid.AdamW is bijzonder effectief voor het scalen van modellen, omdat het de verhoogde complexiteit van diepe netwerken aan kan omgehen zonder de prestaties te vergelden, wat het toestaat toegepast te worden in moderne architecturen.
Hoe AdamW werkt
De kern van de sterkte van AdamW ligt in zijn aanpak van gewichtsveroudering, die losgekoppeld is van de adaptieve gradiëntupdates die kenmerkend zijn voor Adam. Deze aanpassing zorgt ervoor dat regulering direct toegepast wordt op de gewichten van het model, wat de generalisatie verbetert zonder negatief effect op de dynamiek van de learning rate.
De optimizer bouwt op op de aanpasbare eigenschappen van Adam, behoudende de voordelen van momentum en aanpassingen van de leeringssnelheid per parameter. Het toepassen van gewichtsafname onafhankelijk helpt aan een van Adam’s belangrijkste beperkingen: zijn neiging om gradienten bij de regularisatie te beïnvloeden. Deze scheiding maakt het mogelijk voor AdamW om stabiele leren te behouden, zelfs in complexe en op grote schaal opgebouwde modellen, terwijl overfitting wordt onder controle gehouden.
In de volgende secties zullen we de theorie achter gewichtsafname en regularisatie en de wiskunde die de optiesprocess van AdamW ondersteunt, verkennen.
De Theorie Achter Gewichtsafname en L2 Regularisatie
L2 regularisatie is een techniek die wordt gebruikt om overfitting te voorkomen. Het bereikt dit doel door een boetecomponent toe te voegen aan de verliesfunctie, die grote gewichtswaarden afkeurt. Deze techniek helpt bij het maken van eenvoudigere modellen die beter generaliseren op nieuwe gegevens.
In traditionele optimizers, zoals Adam, wordt gewichtsverloop toegepast als onderdeel van de gradiëntupdate, die onbewust de leerraten beïnvloedt en kan leiden tot suboptimale prestaties.
AdamW verbeterd dit door het loskoppelen van gewichtsverloop van de gradiëntberekening. Met andere woorden, in plaats van gewichtsverloop tijdens de gradiëntupdate toe te passen, behandelt AdamW dit als een aparte stap, die het direct aan de gewichten toepast na de gradiëntupdate. Dit voorkomt dat gewichtsverloop de optimeringsprocessen beïnvloedt, waardoor de training stabieler is en de generalisatie beter.
Wiskundige grondslag van AdamW
AdamW wijzigt de traditionele Adam-optimalisator door de manier waarop gewichtsverloop wordt toegepast te veranderen. De kernvergelijkingen voor AdamW kunnen als volgt weergegeven worden:
- Momentum en adaptieve leeringsnelheid:Net zoals in Adam, gebruikt AdamW momentum en adaptieve leeringsnelheden om parameterupdates uit te voeren op basis van de bewegende gemiddelden van gradiënten en kwadraten van gradiënten.
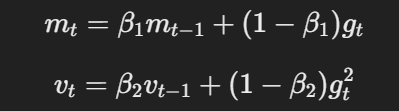
Het vergelijking voor momentum en adaptieve leeringsnelheid
- Bias-correcte schattingen:De eerste en tweede momenten worden gecorrigeerd voor bias door middel van:
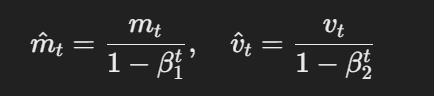
Het formule voor bias-correcte schattingen
- Parameters bijwerken met losgekoppelde gewichtsafname:In AdamW wordt de gewichtsafname direct toegepast op de parameters na de gradiëntupdate. Het bijwerken van de regel is:
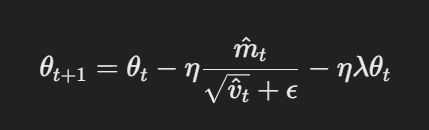
Parameters bijwerken met losgekoppelde gewichtsafname
Hierin is η de learning rate, λ de factor voor gewichtsafname, en θt de parameters. Deze losgekoppelde gewichtsafnameterm λθt zorgt ervoor dat regularisatie onafhankelijk van de gradiëntupdate wordt toegepast, wat de belangrijkste verschillende is van Adam.
Implementatie van AdamW in PyTorch
AdamW implementeren inPyTorch is eenvoudig; dit gedeelte biedt een uitgebreide handleiding voor het instellen ervan. Volg deze stappen om te leren hoe u modellen effectief met de Adam Optimizer kunt afstemmen.
Een stap-voor-stap gids voor AdamW in PyTorch
Notitie: deze handleiding gaat uit van het feit dat u PyTorch reeds geïnstalleerd heeft. Raadpleeg de Documentatie voor eventuele richtlijnen.
Stap 1: Importeer de noodzakelijke bibliotheken
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
Stap 2:Model definiëren
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
Stap 3:Stel de hyperparameters in
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # Aantal epochs
Stap 4:Initialiseer de AdamW optimizer en configureer de verliesfunctie
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
Voila!
Nu bent u klaar om uw CNN-model te trainen, en dat zal we in de volgende sectie doen.
Praktijkvoorbeeld: Fijnafstemmen van een model met AdamW
Hierboven hebben we het model gedefinieerd, de hyperparameters ingesteld, de optimizer (AdamW) geinitialiseerd en de verliesfunctie opgezet.
Om het model te trainen, moeten we enkele meer modules importeren;
from torch.utils.data import DataLoader # levert een doorlopend object van het dataset import torchvision import torchvision.transforms as transforms
Vervolgens definiëren we het dataset en de dataloaders. Voor dit voorbeeld zullen we gebruik maken van het CIFAR-10 dataset:
# Defineer transformaties voor de trainingsset transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # Laad CIFAR-10 dataset train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # Maak data loaders train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
Omdat we onze model reeds gedefinieerd hebben, is de volgende stap om de training loop uit te voeren om het model te optimaliseren met AdamW.
Hier ziet het eruit:
for epoch in range(num_epochs): model.train() # Stel het model in trainingsmodus running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # Leeg de gradiënten outputs = model(inputs) # Voorwaarts doorgang loss = criterion(outputs, labels) # Bereken de verliezen loss.backward() # Achterwaarts doorgang optimizer.step() # Bijwerken van de gewichten running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
De laatste stap is het validatie van de prestaties van het model op de validatieset die we eerder hebben gemaakt.
Hier is het code:
model.eval() # Stel het model in evaluatie modus correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # Voer de voorwaartse iteratie uit _, predicted = torch.max(outputs.data, 1) # Haal de voorspelde klasse op total += labels.size(0) # Bepaal het totaal aantal voorbeelden correct += (predicted == labels).sum().item() # Bepaal het aantal correct voorspelde voorbeelden accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
En daar hebben je het.
U kent nu hoe u AdamW in PyTorch kan implementeren.
Algemene toepassingen voor AdamW
Okay, we hebben gezien dat AdamW populairheid heeft behaald door zijn effectievere beheersing van gewichtsafname dan zijn voorganger, Adam.
Maar wat zijn enkele algemene toepassingen voor deze optimalisator?
We zullen dat in deze sectie behandelen…
Grote schaal diep leer modellen
AdamW is bijzonder nuttig bij het trainen van grote modellen zoals BERT, GPT en andere transformer architecturen. Zulke modellen hebben meestal miljoenen of zelfs miljarden parameters, wat vaak betekent dat ze efficiënte optimalisatieschema’s nodig hebben die complexe gewichts updates en algemene uitdagingen verwerken.
Computer Vision en NLP taken
AdamW is uitgegroeid tot de voorkeursmethode voor optimalisatie in computer visuele taken die CNN’s bevatten en NLP taken die transformers bevatten. Het vermogen om overfitting te voorkomen maakt het ideaal voor taken die grote datasets en complexe architecturen bevatten. Het loskoppelen van gewichtsafname betekend dat AdamW de problemen omzeilt die Adam tegenkomt bij over-regularisering van modellen.
Hyperparameter afstemming in AdamW
Hyperparameter aanpassing is het proces van het selecteren van de beste waarden voor parameters die de training van een machine learning model beheersen, maar niet van de data zelf worden geleert. Deze parameters beïnvloeden direct hoe het model optimaliseert en convergeert.
Een correcte aanpassing van deze hyperparameters in AdamW is essentieel voor het behalen van efficiente training, het voorkomen van overfitting en het waarborgen van goed gedifferentieleerded model voor onbekende data.
In dit gedeelte zullen we kijken hoe we de belangrijkste hyperparameters van AdamW kunnen afstemmen voor optimale prestaties.
Best practices voor het kiezen van leerraten en gewichtsverminderen
De leerrate is een hyperparameter die beheert hoeveel het model gewichten moeten worden aangepast ten opzichte van de verlieskromme tijdens elke trainings stap. Een hogere leerrate versnelt de training, maar kan ertoe leiden dat het model de optimale gewichten overschrijdt, terwijl een lagere rate de mogelijkheid biedt voor meer gedetailleerde aanpassingen, maar de training kan langzamer worden of vastlopen in lokale minimumen.
Gewichtsafname is een regularisatiest techniek die wordt gebruikt om overfitting te voorkomen door de grotere gewichten in het model te bestraffen. Concreet wordt bij gewichtsafname een kleine boete toegevoegd die proportioneel is aan de grootte van de modelgewichten tijdens het trainen, wat helpt de complexiteit van het model te reduceren en de generalisatie naar nieuwe gegevens te verbeteren.
Om optimale leerraten en gewichtsafname waarden te kiezen voor AdamW:
- Begin met een gematigde leeringssnelheid – Voor AdamW is een leeringssnelheid van ongeveer 1e-3 vaak een goed startpunt. U kunt het aanpassen op basis van hoe goed het model convergeert, het verlagen als het model moeite om converteren te krijgen of het verhogen als het trainen te langzaam is.
- Experimenteer met gewichtsafname. Begin met een waarde rond 1e-2 tot 1e-4, afhankelijk van de grootte van het model en het dataset. Een iets hogere gewichtsafname kan helpen bij het voorkomen van overfitting voor grotere, complexe modellen, terwijl kleinere modellen misschien minder regularisatie nodig hebben.
- Gebruik een leeringsnelheidsschema. Implementeer leeringsnelheidsschematen (zoals stapservering of cosinusverloop) om de leeringsnelheid dynamisch te verlagen als de training voortgaat, wat de model de mogelijkheid biedt zijn parameters finet te tuneren als het bijna convergeert.
- Bemonstering van prestaties. Bemonster continu de prestaties van het model op de validatieset. Als u overfitting observeert, overweeg om de gewichtsafname te verhogen, of als de trainingsverlieseling vastgaat, verlaag de leeringsnelheid voor een betere optimalisatie.
Eindgedachten
AdamW heeft zich ontwikkeld tot een van de meest effectieve optimalisatoren in diep leren, vooral voor grote schaal modellen. Dit komt door zijn vermogen de decouple van gewichtsafname van gradient updates te beheersen. Met name de ontwerp van AdamW verbeterd de regularisatie en helpt modellen beter te generaliseren, vooral bij het afhandelen van complexe architecturen en uitgebreide datasets.
ALS aangetoond in deze handleiding, is het implementeren van AdamW in PyTorch eenvoudig – het vereist alleen enkele aanpassingen van Adam. Echter, het aanpassen van de hyperparameters blijft een cruciale stap voor het maximale effect van AdamW. Het vinden van de juiste balans tussen de leeringssnelheid en de gewichtsafname is essentieel voor het ervoor zorgen dat de optimaliseerder effectief werkt zonder overfitting of underfitting van het model.
Nu je genoeg kent om AdamW te implementeren in uw eigen modellen, kun je uw leren vervolgen door onder andere deze resources te bekijken:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch