













Inleiding
Methodes van modelleerbaarheid zijn in de afgelopen jaren steeds meer significant geworden als directe gevolg van de toenemende complexiteit van modellen en de daarmee gekoppelde ontoelaatbare透明heid. Modelbegrip is een actueel onderzoeksonderwerp en een focusgebied voor praktische toepassingen die machinelearning gebruiken over verschillende sectoren.
Captum biedt academici en ontwikkelaars de meest geavanceerde technieken, zoals Integrated Gradients, die het gemakkelijk maken om de elementen te identificeren die bijdragen aan het uitkomst van een model. Captum maakt het gemakkelijker voor ML-onderzoekers om PyTorch-modellen te gebruiken om interpretabiliteitstechnieken te bouwen.
door middel van het gemakkelijker identificeren van de vele elementen die bijdragen aan het uitkomst van een model, helpt Captum modelontwikkelaars beter modellen te maken en modeltypen die onverwachte resultaten geven op te lossen.
Algoritmeomschrijvingen
Captum is een bibliotheek die het mogelijk maakt om verschillende interpretabiliteitsmethodes uit te voeren. Het is mogelijk om de toeschrijving algoritmen van Captum te classificeren in drie breede categorieën:
- primair toeschrijven: Berekent de bijdrage van elke invoerkenmerk aan het uitkomst van een model.
- Laag Attributie: Elke neuron in een bepaalde laag wordt beoordeeld op zijn bijdrage aan het uitvoergedrag van het model.
- Neuron Attributie: De activatie van een verborgen neuron wordt bepaald door de bijdrage van elk invoerkenmerk te evalueren.
Hieronder volgt een korte overzicht van de verschillende methodes die momenteel zijn geïmplementeerd binnen Captum voor primaire, laag en neuron attributie. Ook wordt een beschrijving gegeven van de ruisgang, die kan worden gebruikt om de resultaten van elke attributie methode af te smoothen.
Captum levert meetwaarden om de betrouwbaarheid van modelverklaringen te schatten, naast zijn attributiealgoritmen.momenteel leveren ze onnauwkeurigheid en gevoeligheid meetwaarden die helpen de nauwkeurigheid van verklaringen te evalueren.
Primaire Attributie Technieken
Geïntegreerde Gradienten
Stel dat we een formele representatie hebben van een diepe netwerk, F : Rn → [0, 1].
Laat x ∈ Rn de huidige invoer en x′ ∈ Rn de basisinvoer zijn.
De basis in beeldenetwerken zou het zwarte beeld kunnen zijn, terwijl het in tekstmodellen een nul embeddingvector zou kunnen zijn.
Van de basis x′ naar de invoer x berekenen we de gradiënten op alle punten langs de rechte lijnbaan (in Rn). door deze gradiënten te accumuleren, kunnen we geïntegreerde gradiënten genereren. Geïntegreerde gradiënten zijn gedefinieerd als de padintegrale van gradiënten langs een directe baan van de basis x′ naar de invoer x.
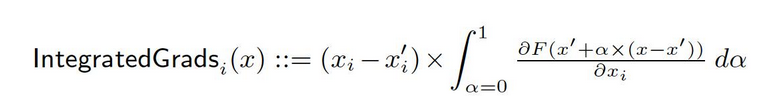
De twee basisongelijkheden, gevoeligheid en implementatieonveranderlijkheid, vormen de basis van dit method. Raadpleeg de oorspronkelijke paper voor meer informatie over deze axiomen.
Gradient SHAP
Shapley-waarden in coöperatieve speltheorie worden gebruikt om Gradient SHAP-waarden te berekenen, die worden berekend met behulp van een gradientenmethode. Gradient SHAP voegt elke invoerstam meermaals Gaussiaanse ruis toe, selecteert vervolgens een willekeurig punt op de weg tussen de referentielijn en de invoer om de gradiënten van de uitvoer te bepalen. Als resultaat vertegenwoordigen de uiteindelijke SHAP-waarden de verwachtingswaarde van de gradiënten. * (invoer – referentielijn). SHAP-waarden worden benaderd op het voorwaarde dat inputkenmerken onafhankelijk zijn en dat het toevalmodel lineair is tussen de invoer en de geleverde referentielijnen.
DeepLIFT
Het is mogelijk om DeepLIFT (een backpropagationtechniek) te gebruiken om inputwijzigingen toe te kennen op basis van de verschillen tussen inputs en hun passende referentie (of basislijn). DeepLIFT probeert de verschillen tussen de uitvoer van de referentie en de input te verklaren door de verschillen tussen de inputs van de referentie te gebruiken. DeepLIFT gebruikt het concept van multipliers om individuele neuronen de schuld te geven van de verschillen in uitvoeringen. Voor een gegeven inputneuron x met verschil ten opzichte van de referentie ∆x, en een doelneuron t met verschil ten opzichte van de referentie ∆t die we willen bepalen bijdrage aan, definiëren we de multiplier m∆x∆t als:
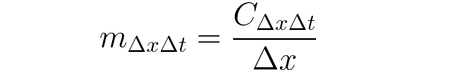
DeepLIFT SHAP
DeepLIFT SHAP is een uitbreiding van DeepLIFT gebaseerd op Shapley-waarden uit de coöperatieve game-theorie. DeepLIFT SHAP berekent de DeepLIFT-toewijzing voor elke input-basispaar en verdeelt de resulterende toewijzingen per inputvoorbeeld door middel van een verdeling van basislijnen. De niet-lineaire regels van DeepLIFT helpen de niet-lineaire functies van het netwerk lineair te maken, en de benadering van de SHAP-waarden van het methodiek is ook van toepassing op de ge线性iseerde netwerk. In deze methode worden de invoerkenmerken eveneens aangenomen als onafhankelijk.
Saliëntie
Berekening van invoerattributie via saliëntie is een eenvoudig proces dat de gradiënten van het uitvoer ten opzichte van de invoer oplevert. Een eerste-orde Taylor netwerk wordt gebruikt bij de invoer, en de gradiënten zijn de coëfficients van elk kenmerk in de lineaire weergave van het model. De absolute waarden van deze coëfficients kunnen worden gebruikt om de relevantie van een kenmerk aan te geven. U kunt meer informatie over de aanpak van de saliëntie vinden in de oorspronkelijke paper.
Invoer X Gradiënt
Invoer X Gradiënt is een verlenging van de saliënt benadering, die de gradiënten van de uitvoer ten opzichte van de invoer neemt en deze vermenigvuldigd met de invoer kenmerk waarden. Een intuïtieve kijk op deze aanpak beschouwt een lineaire model; de gradiënten zijn eenvoudigweg de coëfficients van elke invoer, en de product van de invoer met een coëfficiënt komt overeen met de totale bijdrage van het kenmerk tot de uitvoer van het lineaire model.
Geadviseerde Backpropagatie en Deconvolutie
Gradiëntberekening wordt uitgevoerd via geadviseerde backpropagatie en deconvolutie, hoewel de backpropagatie van ReLU-functies wordt overschreven zodat alleen niet-negatieve gradiënten worden teruggevoerd. Terwijl de ReLU-functie aan de invoer gradiënten wordt toegepast in geadviseerde backpropagatie, wordt deze direct aan de uitvoer gradiënten toegepast in deconvolutie. Het is een algemeen gebruik deze methodes in combinatie met convolutionele netwerken te gebruiken, maar ze kunnen ook in andere typen van neurale netwerk architecturen worden gebruikt.
Guidende GradCAM
Guidende backpropagatieattributies berekenen de elementproduct van guidende GradCAM-attributies (guided GradCAM) met opgehoogde (laag) GradCAM-attributies. Attributies worden berekend voor een gegeven laag en worden opgehoogd om aan de inputgrootte te passen. Convolutie neural netwerken zijn het focus van deze techniek. Echter, elke laag die spatiaal met de invoer kan worden gealigneerd kan worden geleverd. Meestal wordt de laatste convolutielaag geleverd.
Functieablating
Om attributies te berekenen, gebruikt een techniek bekend als “functieablating” een verstoring-gebaseerde methode die een bekende “basislijn” of “referentiewaarde” (zoals 0) voor elke invoerfunctie gebruikt voordat de uitvoerverschillen worden berekend. Groeperen en ablatie van invoerfuncties is een betere alternatief voor het individueel doen van dit soort dingen, en veel verschillende toepassingen kunnen daarvan profiteren. Door groepen en ablatie van segmenten van een afbeelding uit te voeren, kunnen we de relatieve belangrijkheid van het segment bepalen.
Functie Permutatie
Functie permutatie is een verstoring gebaseerde methode waarin elke eigenschap binnen een batch arbitraair gepermuteerd wordt, en de verandering in uitvoer (of verlies) berekend wordt als gevolg van deze wijziging. Functies kunnen ook in groepen samen gebracht worden in plaats van individueel, net zoals functie ablatie. Noteer dat in tegenstelling tot de andere algoritmen beschikbaar in Captum, deze algoritme de enige is die correct toewijzingen kan leveren wanneer het een batch van meerdere invoervoorbeelden ontvangt. Andere algoritmen hebben slechts een enkele voorbeeld nodig als invoer.
Vervaging
Vervaging is een verstoring gebaseerde aanpak om toewijzingen te berekenen, waarbij elk samenhangend rechthoekig gebied vervangen wordt door een gegeven basislijn/referentie, en de verschillen in uitvoer worden berekend. Voor kenmerken gelegen in meerdere gebieden (hyperrechthoeken), worden de corresponderende uitvoerverschillen gemiddeld om de toewijzing voor dat kenmerk te berekenen. Vervaging is het meest nuttig in gevallen als afbeeldingen, waarin pixels in een samenhangend rechthoekig gebied waarschijnlijk hoog geassocieerd zijn.
Shapley-waarden-onderzoek
De toewijzingstechniek Shapley-waarden is gebaseerd op de coöperatieve game-theorie. Deze techniek neemt elke permutatie van de invoerkenmerken en voegt ze één voor één toe aan een gespecificeerde basislijn. De verschillen in uitvoer na toevoeging van elk kenmerk zijn aan elkaar gelijk en deze verschillen worden over alle permutaties gecumuleerd om de toewijzing vast te stellen.
Lime
Een van de meest breed toegepaste methodes voor interpretabiliteit is Lime, die een begrijpelijke standaardmodel traint door data-punten rond een invoervoorbeeld te samplen en modelevaluaties aan deze punten te gebruiken om een eenvoudigere begrijpelijke ‘standaard’ model, zoals een lineair model, te trainen.
KernelSHAP
Kernel SHAP is een techniek voor het berekenen van Shapley-waarden die gebruik maakt van de LIME-framework. Shapley-waarden kunnen efficiënter worden verkregen binnen het LIME-framework door de verliesfunctie in te stellen, de kernel te wegen en de termen goed te regulariseren.
Laagtoewijzingstechnieken
Laagdoorlaatbaarheid
Laagdoorlaatbaarheid is een methode die een meer uitgebreidere weergave van de belangrijkheid van een neuron creëert door de activatie van de neuron samen te brengen met de deelderivaten van zowel de neuron ten opzichte van de invoer als de uitvoer ten opzichte van de neuron. Door middel van de verborgen neuron bouwt laagdoorlaatbaarheid voort op de toewijzingstrekking van Integrated Gradients (IG). De totale doorlaatbaarheid van een verborgen neuron y wordt als volgt gedefinieerd in het oorspronkelijke artikel:
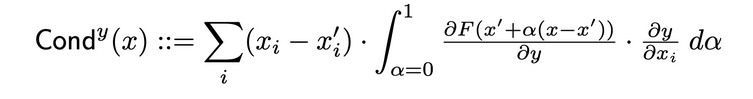
Interne invloed
Met Interne invloed kan men de integraal van de gradienten langs de weg van een basisinput tot de geleverde input bepalen. Deze techniek is vergelijkbaar met het toepassen van geïntegreerde gradiënten, die betrekking heeft op de laag (in plaats van de input).
Laag Gradiënt X Activatie
Laag Gradiënt X Activatie is het equivalent van de Input X Gradiënt techniek voor verborgen lagen in een netwerk…
Het multipliceert de activiteit van het laag element elementair met de gradiënten van het doeloutput ten opzichte van de gespecificeerde laag.
GradCAM
GradCAM is een attributietechniek voor laag van een convolutieel neurale netwerk die meestal wordt toegepast op de laatste convolutieel laag. GradCAM berekent de gradiënten van het doeloutput ten opzichte van de gespecificeerde laag, bedekt elke output kanaal (uitvoer dimensie 2) gemiddeld en multipliceert de gemiddelde gradient voor elk kanaal door de laag activaties. Een ReLU wordt toegepast op de uitvoer om erop te zorgen dat alleen niet-negatieve toewijzingen worden teruggegeven uit de som van de resultaten over alle kanalen.
Neuron Attribuuttechnieken
Neuron Conducteur
Conducteur combineert neuronale activatie met deelverhoudingen van zowel de neuron aan de input als de output aan de neuron, om een meer alomvattend beeld van de relevantie van de neuron te geven. Om de conducteur van een specifieke neuron te bepalen, wordt de stroom van IG-toewijzing van elke input onderzocht, die via deze neuron stroomt. Hier volgt de formele definitie van de conducteur van de neuron y gegeven de inputtoewijzing i uit het originele artikel:
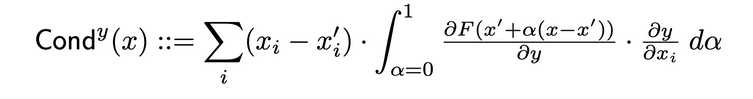
Volgens deze definitie moet worden opgemerkt dat het optellen van de conducteur van een neuron (over alle inputkenmerken) altijd gelijk is aan de conducteur van het laagje waarin die specifieke neuron zit.
Neuron Gradiënt
De neuron gradient-benadering is de equivalentie van de saliëntiemethode voor een enkele neuron in het netwerk.
Het berekenen van de gradiënt van de neuronenoutput ten opzichte van het modelinput is simpelweg het equivalent van deze methode.
Deze methode, net als Saliency, kan worden opgevat als een eerste-orde Taylorbreuk van de neuronenoutput bij de gegeven input, met de gradiënten die overeenkomen met de coëfficiënten van elk kenmerk in de lineaire representatie van het model.
Neuron Integrated Gradients
Met de techniek “Neuron Integrated Gradients” is het mogelijk de integraal van de inputgradiënten ten opzichte van een specifieke neuron uit te rekenen over de hele pad van een basisinput tot de interesse-input. De integraalgradiënten zijn equivalent aan deze methode, onder de voorwaarde dat het output van het gekende neuron alleen wordt geacht. U vindt meer informatie over de geïntegreerde gradiëntbenadering in het originele artikel hier.
Neuron GradientSHAP
Neuron GradientSHAP is het equivalent van GradientSHAP voor een specifieke neuron. Neuron GradientSHAP voegt elk invoertestenis meerdere malen Gaussiaanse ruis toe, kiest een willekeurig punt langs de weg tussen basislijn en invoer, en bereidt de gradiënt van het doelneuron ten opzichte van elk willekeurig gekozen punt.
De resulterende SHAP-waarden zijn dicht bij de voorspelde gradiëntwaarden * (ingaves – basislijnen).
Neuron DeepLIFT SHAP
Neuron DeepLIFT SHAP is het equivalent van DeepLIFT voor een specifieke neuron. Met behulp van de verdeling van basislijnen, bereidt de DeepLIFT SHAP-algoritme de Neuron DeepLIFT-toewijzing voor elke invoer-basislijncombinatie en averageert de resulterende toewijzingen per invoertest.
Ruisgang
Ruisgang is een toewijzings techniek die gebruikt kan worden in combinatie met andere methodes. De ruisgang bereidt de toewijzing meerdere malen voor, voegt elke keer Gaussiaanse ruis toe aan de invoer, en combineert vervolgens de resulterende toewijzingen afhankelijk van de gekozen type. De volgende ruisgangstypen worden ondersteund:
- Smoothgrad: wordt de gemiddelde van de geëvalueerde toewijzingen teruggegeven. Het gladmaken van de gespecificeerde toewijzings techniek met behulp van een Gaussische Kern is een benadering van dit proces.
- Smoothgrad Verhoogd: wordt de gemiddelde van de verhoogde geëvalueerde toewijzingen teruggegeven.
- Vargrad: wordt de variantie van de geëvalueerde toewijzingen teruggegeven.
Metriek
Infideliteit
Infideliteit meet de gemiddelde kwadratische fout tussen modeltoewijzingen in de grootte van invoerverstoringen en de veranderingen van de voorspellingsfunctie bij die invoerverstoringen. Infideliteit is als volgt gedefinieerd:
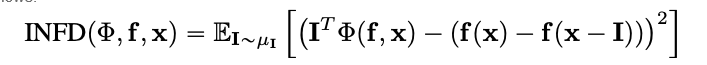
Van bekende toewijzingstechnieken zoals de geïntegreerde gradient is dit een computationally meer efficiënte en uitgebreidere concept van Sensitivy-n. Laatstgenoemd onderzoekt de correlaties tussen de som van de toewijzingen en de verschillen van de voorspellingsfunctie bij haar invoer en een gedefinieerde basislijn.
Sensitiviteit
Sensitivity, die gedefinieerd is als de mate van verandering van de verklaring door kleine inputverstoringen aan de hand van een Monte Carlo-monteuringsgebaseerde benadering, wordt gemeten als volgt:

Standaard neemt men monsters ontwijken uit een subruimte van een L-Infinity-bal met een standaard straal om gevoeligheid te benaderen. Gebruikers kunnen de straal van de bal en de monsterfunctie wijzigen.
Modeluitleg voor geïntegreerd ResNet-model
Dit handleiding laat zien hoe modeluitlegmethodes gebruikt kunnen worden op een geïntegreerd ResNet-model met een gekozen afbeelding, en visualiseert de toewijzingen voor elk pixel door ze op de afbeelding over te lopen. In deze handleiding zullen we de uitlegalgoritmen Integrated Gradients, GradientShape, Attribution met Layer GradCAM en Occlusion gebruiken.
Voordat u begint, moet u een Python-omgeving hebben die de volgende onderdelen bevat:
- Python versie 3.6 of hoger
- PyTorch versie 1.2 of hoger (de nieuwste versie wordt aanbevolen)
- TorchVision versie 0
- .6 of hoger (de nieuwste versie wordt aanbevolen)
- Captum (de nieuwste versie wordt aanbevolen)
Afhankelijk van of u Anaconda of pip virtuele omgevingen gebruikt, zullen de volgende opdrachten u helpen om Captum in te stellen:
Met conda:
conda install pytorch torchvision captum -c pytorch
Met pip:
pip install torch torchvision captum
Laat ons bibliotheken importeren.
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
Laadt de geïmplementeerde Resnet-model en stelt het in eval-modus.
model = models.resnet18(pretrained=True)
model = model.eval()
ResNet is geëvalueerd op de ImageNet dataset.下载 en leest de lijst van ImageNet dataset klassen/labels in de geheugen in.
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
Nu we het model hebben voltooid, kunnen we de afbeelding downloaden voor analyse.
Bij mij koos ik een afbeelding van een kat.

Uw afbeeldingsmap moet de bestand cat.jpg bevatten. Zoals we hieronder kunnen zien, Image.open() opent en identificeert het gegeven afbeeldingsbestand en np.asarry() converteert het naar een array.
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
In het volgende code zullen we transformators en normalisatiefuncties voor de afbeelding definiëren. Om ons ResNet-model te trainen, hebben we de ImageNet-dataset gebruikt, dat vereist dat de afbeeldingen een bepaalde grootte hebben, met kanaalgegevens normaliseerd naar een bepaalde waardenbereik. transforms.Compose() combineert verschillende transformaties en transforms.Normalize() normaliseert een tensorafbeelding met gemiddelde en standaardafwijking.
# model verwachting is 224x224 3-kleur afbeelding
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# ImageNet normalisatie
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
#unsqueeze geeft een nieuwe tensor terug met een dimensie van grootte één ingevoegd aan de #gegeven positie.
input = input.unsqueeze(0)
Nu zal we de klasse van de invoerafbeelding voorspellen. De vraag die kan worden gesteld is, “Wat denkt onze model dat deze afbeelding voorstelt?”
#roep ons model aan
output = model(input)
## toegepaste softmax() functie
output = F.softmax(output, dim=1)
#torch.topk geeft de k grootste elementen terug van de gegeven invoertensor langs een gegeven #dimensie. K hier is 1
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
#converteer in een dictionnaire van sleutelwaardeparen voor de voorspelde label, converteer het #in een string om het voorspelde label te krijgen
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
uitvoer:
Predicted: tabby ( 0.5530276298522949 )
Het feit dat ResNet onze afbeelding van een kat denkt voor te stellen een echte kat wordt bevestigd. Maar wat geeft de model de indruk dat dit een afbeelding van een kat is? Om de oplossing voor die vraag te krijgen, zal ik Captum raadplegen.
Functie toewijzing met geïntegreerde gradiënten
Eén van de verschillende functietoewijzingstechnieken in Captum is geïntegreerde gradiënten. Geïntegreerde gradiënten geeft aan elk invoerfunctie een relevantie score door de integraal van de gradiënten van het models uitvoer ten opzichte van de invoer te schatten.
Voor ons geval zal ons geïntegreerde gradiënten helpen te ontdekken welke aspecten van de invoerafbeelding tot deze uitkomst bijgedragen hebben. Dit zal ons in staat stellen te bepalen welke delen van de afbeelding het meest belangrijk waren bij de productie van dit resultaat.
Nadat we de belangrijkheidskaart hebben geoptimaliseerd met behulp van geïntegreerde gradiënten, zullen we de visualisatietools gebruiken die zijn opgenomen in Captum om deze belangrijkheidskaart in een duidelijke en begrijpelijke weergave te geven.
Geïntegreerde gradiënten zullen de integraal van de gradiënten van de uitkomst van het model voor de voorspelde klasse pred_label_idx bepalen met betrekking tot de invoerafbeeldingspixels langs de weg van het zwarte beeld tot onze invoerafbeelding.
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
#Maak een IntegratedGradients object en verkrijg eigenschappen
integrated_gradients = IntegratedGradients(model)
#Vraag het algoritme om onze uitvoerdoel aan te geven
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
Uitvoer:
Predicted: tabby ( 0.5530276298522949 )
Bekijk de afbeelding en de toewijzingen die erbij gaan door de laatste over de afbeelding te plaatsen. De visualize_image_attr() methode die Captum aanbiedt biedt een set mogelijkheden voor het aanpassen van de presentatie van de toewijzingendata aan uw voorkeuren. Hier geven we een aangepaste Matplotlib kleurverdeling (zie LinearSegmentedColormap()) mee.
#Resultaatvisualisatie met aangepaste kleurverdeling
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
#Gebruik de helpermethode visualize_image_attr voor visualisatie om de #oorspronkelijke afbeelding voor vergelijking te tonen
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
Uitvoer:
U zou moeten kunnen merken in de bovenstaande afbeelding dat de omgeving van de kat in de afbeelding de plek is waar het algoritme Integrated Gradients ons de sterkste signaal gegeven krijgt.
Laten we attributies berekenen door middel van Integrated Gradients en vervolgens ze door elkaar mengen over verschillende afbeeldingen die zijn gegenereerd door een noisetunnel.
De laatste verandert de invoer door Gaussische ruis toe te voegen met een standaarddeviatie van één, 10 keer (nt_samples=10). Het smoothgrad_sq aanpak wordt door de noisetunnel gebruikt om de attributies consistent te maken over alle nt_samples ruisige voorbeelden.
Het waarden van smoothgrad_sq is de gemiddelde van de kwadraten van de attributies over nt_samples voorbeelden.
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
Uitvoer:

Ik kan zien in de bovenstaande afbeeldingen dat het model zich concentreert op de kop van de kat.
Laat ons eindigen door GradientShap te gebruiken. GradientShap is een gradientenmethode die gebruikt kan worden om SHAP-waarden te berekenen en is ook een uitstekende tool voor inzicht te krijgen in het gedrag van het algemeen. Het is een lineaire verklaringmodel dat de voorspellingen van het model uitlegt door middel van een verdeling van referentiesamples te gebruiken. Het berekend de verwachte gradiënten voor een invoer die willekeurig gekozen wordt tussen de invoer en een basislijn.
De basislijn wordt willekeurig gekozen uit de aangeboden verdeling van basislijnen.
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
# Definitie van de verdeling van de basislijnen van afbeeldingen
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
Uitvoer:

Laagtoewijzing met Laag GradCAM
U kunt de activiteit van de verborgen lagen binnen uw model relateren aan kenmerken van uw invoer met behulp van Laagtoewijzing.
We zullen een algoritme voor laagtoewijzing toepassen om de activiteit van een van de convolutie lagen in ons model te onderzoeken.
GradCAM is verantwoordelijk voor het berekenen van de gradiënten van de doel uitvoer ten opzichte van de gespecificeerde laag. Deze gradiënten worden vervolgens gemiddeld voor elke uitvoer kanaal (dimensie 2 van de uitvoer) en de laagactiviteiten worden vermenigvuldigd met de gemiddelde gradiënt voor elk kanaal.
De resultaten worden opgeteld over alle kanalen. Aangezien de activiteit van convolutie lagen vaak ruimtelijk aan de invoer is gekoppeld, worden GradCAM toewijzingen vaak upsampled en gebruikt om de invoer te maskeren. Het is waardoor te merken dat GradCAM specifiek is ontwikkeld voor convolutie neurale netwerken (convnets). Laagtoewijzing is ingericht in dezelfde manier als invoer toewijzing, met inachtneming van het feit dat u, naast het model, een verborgen laag binnen het model moet opgeven die u wilt analyseren. Net zoals eerder besproken, als we attribute() roepen, geven we de interesseerde doel klasse aan.
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
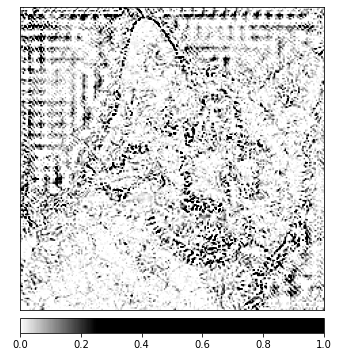
Om een exactere vergelijking te kunnen maken tussen de invoer afbeelding en deze toewijzing gegevens, zullen we deze upsample met behulp van de functie interpolate(), gelegen in de LayerAttribution basis klasse.
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
Uitvoer:
Visualisaties zoals deze kunnen u voorzien van unieke inzichten in hoe uw verborgen lagen reageren op de invoer die u voorlegt.
Functieattributie met occlusie
Methodes gebaseerd op gradiënten helpen ons de model te begrijpen in termen van het rechtstreeks bepalen van de veranderingen in de uitvoer ten opzichte van de invoer.
De techniek die bekendstaat als verstoring-gebaseerde attributie neemt een directere aanpak aan dit probleem door aanpassingen aan de invoer te maken om de impact van deze veranderingen op de uitvoer te kwalificeren. Een derdige strategie wordt occlusie genoemd.
Dit omvat het vervangen van delen van de invoerafbeelding en het analyseren hoe deze verandering de signaalproductie op de uitvoer beïnvloedt.
In het volgende zullen we de occlusieattributie configureren. Net zoals de configuratie van een convolutionele neurale netwerk, kun je de grootte van het doelgebied kiezen en een stride-lengte, die de afstand tussen de individuele metingen bepaalt.
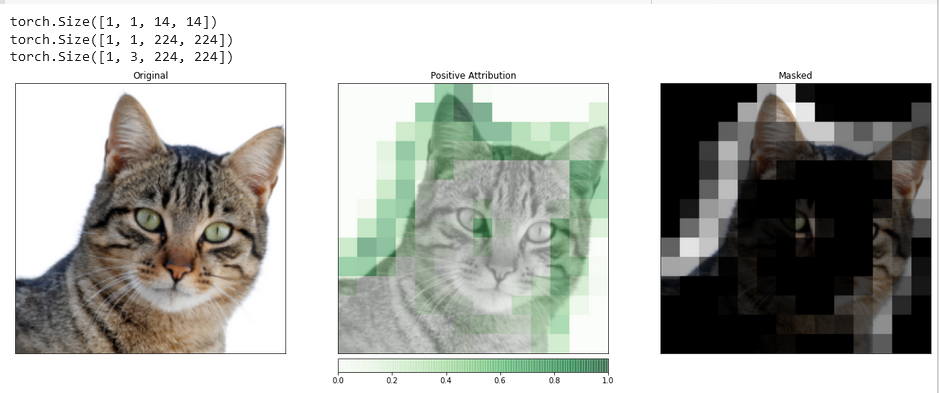
We zullen de visualize_image_attr_multiple() functie gebruiken om de resultaten van onze Occlusion attributie te bekijken. Deze functie zal warmtekaarten van zowel positieve als negatieve attributie per gebied weergeven en de originele afbeelding maskeren met de gebieden van positieve attributie.
De maskering biedt een zeer helder beeld van de gebieden op onze katfoto die het model als het meest “kattig” heeft gemarkeerd.
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
Uitvoer:
De afbeeldingssectie die de kat bevat lijkt een hoger niveau van belang te krijgen.
Conclusie
Captum is een modelleerbaarheidslibrary voor PyTorch die verschillend en eenvoudig is. Hij biedt de meest geavanceerde technieken voor het begrijpen van hoe specifieke neuronen en lagen de voorspellingsresultaten beïnvloeden.
Hij beschikt over drie hoofdsoorten toewijzingstechnieken: Primaire Toewijzingstechnieken, Laag Toewijzingstechnieken en Neuron Toewijzingstechnieken.
Referenties
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf