













サーバーレスコンピューティングは、従来のサーバーベースのアーキテクチャの課題に対する対策として登場しました。サーバーレスでは、開発者はもはやサーバーの管理や手動でのスケーリングを行う必要はありません。
クラウドプロバイダがインフラストラクチャの管理を行うため、チームはコードの書き込みとデプロイに専念することができます。サーバーレスソリューションは、需要に応じて自動的にスケールし、Pay-as-you-goのモデルを提供します。つまり、アプリケーションが実際に使用するリソースに対してのみ支払う必要があるということです。このアプローチは、運用の過程のオーバーヘッドを大幅に削減し、柔軟性を高め、開発サイクルを加速させるため、現代のアプリケーション開発には魅力的な選択肢です。
サーバー管理を抽象化することで、サーバーレスプラットフォームは、ビジネスロジックとアプリケーション機能に集中することができます。これにより、迅速なデプロイとより多くのイノベーションが可能です。サーバーレスアーキテクチャは、イベント駆動型でもあり、手動の介入無しにリアルタイムのイベントに自動的に反応し、ユーザーの要求に応じてスケールすることができます。
目次
技術的な詳細に入り込む前に、いくつかの主要な背景コンセプトを复习します。
重要な概念を理解する
アプリケーションプログラミングインターフェース(API)
アプリケーションプログラミングインターフェース(API)は、異なるソフトウェアアプリケーションがお互いに通信し、互いに影響を及ぼすことを可能にする。これは、アプリケーションが、統合とデータ共有のために、リクエストと返信する情報にアクセスする方法とデータ形式を定義する。
HTTPメソッド
HTTPメソッドは、webサービスおよびAPIの重要な组成部分であり、与えられたリクエストURL上のリソースに対する希望する动作を示します。
RESTful APIで最も一般的に使用されるメソッドは以下の通りです。
-
GET: サーバからデータを取得する
-
POST: リクエストの本文に含まれるデータを送信し、リソースを作成または更新する
-
PUT: 既存のリソースを更新または置換したり、存在しない場合に新しいリソースを作成する
-
DELETE: サーバから指定したデータを削除する
アマゾンAPIゲートウェイ
Amazon API Gatewayは、開発者がマススケールでAPIを作成、公開、保守、モニタリング、および保護するのを簡単にする完全に管理されたサービスです。複数のAPIの入り口として機能し、クライアント(例えばウェブやモバイルアプリ)とバックエンドサービスの間のやり取りを管理および制御します。
また、要求 routing、安全性、認証、キャッシング、レート制限など、APIの管理およびデプロイを簡素化するための様々な機能を提供します。
Amazon DynamoDB
DynamoDBは、高スケール性、低遅延性、およびデータのマルチレジオン replication をサポートする完全に管理されたNoSQLデータベースサービスです。
DynamoDBはスキーマレスの形式でデータを格納し、構造化されたや半構造化されたデータの柔軟なと快速なストレージおよび取得を可能にします。これは、クラウドベース環境でスケーラブルで応答性のあるアプリケーションの構築に一般的に使用されます。
Serverless CRUD Application
Serverless CRUDアプリケーションは、作成、読み取り、更新、および削除データの能力を指します。しかし、そのアーキテクチャと関連するコンポーネントは、従来のサーバーベースのアプリケーションとは異なります。
Createは、DynamoDBテーブルに新しいエントリーを追加することを指します。Read操作は、DynamoDBテーブルからデータを取得します。Updateは、DynamoDBに既存のデータを更新します。そして、Delete操作は、DynamoDBからデータを削除します。
The Serverless Framework
The Serverless Frameworkは、AWSを含む複数のクラウド提供者間でserverlessアプリケーションのデプロイや管理を簡素化する開源ツールです。開発者はYAMLファイルを使用してインフラを定義することで、インフラの準備や管理の複雑性を抽象化します。
フレームワークは、serverless関数、APIその他のリソースのデプロイ、スケーリング、更新を处理します。
GitHub Actions
GitHub Actionsは、開発者がGitHubリポジトリ直下でソフトウェアのワークフローを自動化する強力なCI/CD自動化ツールです。
GitHub Actionsを使用すると、コードのプッシュ、プルリクエスト、ブランチのマージなどの事件によってカスタムパイプラインを作成することができます。これらのワークフローは、リポジトリ内のYAMLファイルに定義され、さまざまな環境にアプリケーションをテスト、構築、デプロイするタスクを行うことができます。
Postman
Postmanは、APIの設計、テスト、文書化を簡素化する人気の協力プラットフォームです。開発者は、HTTP要求を作成して送信、APIエンドポイントのテスト、テストワークフローの自動化を行うためのユーザーフrendlyなインターフェースを提供します。
今回は使うツールや技術について熟悉したので、いきなりに入りましょう。
前提条件
-
Node.jsとnpmをインストールしている
-
AWS CLIを設定してAWSアカウントにアクセスできる
-
Serverless Frameworkアカウント
-
Serverlesss Framework がローカル CLI にグローバルにインストールされています
Serverlesss Framework がローカル CLI にグローバルにインストールされています
アリックスは最近サーバーレスアーキテクチャについて学び始めた起業家です。ウェブアプリケーションのバックエンドを構築する強力で効率的な方法で、ウェブアプリケーション開発のより現代的なアプローチを提供するということを読んでいます。
彼女は今まで学んだ AWS サーバーレス計算の基本原則を応用しようとしています。サーバーレスとはサーバーが存在しないという意味ではなく、サーバーの管理とプロビジョニングを抽象化するだけだと理解しています。そして今はコードを書くこととビジネスロジックの実装に集中したいと考えています。
アリックスは成長するカフェの所有者として、ウェブアプリケーションのバックエンドでサーバーレスアーキテクチャを活用し始める方法を見てみましょう。
オンラインカフェのアリックスのコーヒーヘブンは、様々なコーヒーブレンドとお食事を販売しています。当初、アリックスは伝統的なウェブホスティングサービスと運用を使ってショップの注文と在庫を管理していました。複数のサーバーとリソースを扱っていました。しかし、彼女のカフェが人気が出てきたため、特にピーク時と季節のプロモーション時には注文が増え始めました。
サーバーの管理とアプリケーションがトラフィックの波を処理できることを保証することがアリックスの課題になりました。彼女は常にサーバーのキャパシティ、拡張性、そしてインフラの維持コストを心配していました。
彼女はまた、個人化された推奨とレートプログラムなどの新機能を紹介したいと考えていましたが、伝統的な環境の限りまったく大変な課題となっていました。
その後、Alyxは、サーバーレスという概念を学びました。彼女は、サーバーレスのバックエンドを、 automagically コーヒーを泡を立てるバースタに例えました。彼女は、コーヒー作り上げの詳細な手順について心配する必要はなく、实时にコーヒーを泡を立てることができます。
このアイデアに興奮したAlyxは、AWS Lambda、AWS API Gateway、Amazon DynamoDBを使用して、自分のコーヒーショップのバックエンドをサーバーレスプラットフォームに移行することにしました。この設定により、彼女は、よりよくコーヒーブレンドと顧客のためのデザートを作り上げることに集中することができます。
サーバーレスで、各顧客の注文がイベントとして認識され、一連のサーバーレス関数をトリガーします。AWS Lambda関数の別々のものが注文を処理し、背景で行われるすべてのビジネスロジックを処理します。たとえば、顧客の注文を作成し、その注文を取得することができます。また、注文を削除したり、注文のステータスを更新したりすることもできます。
Alyxは、サーバーの管理を心配する必要がなくなりました。なぜなら、サーバーレスプラットフォームは、入力の注文リクエストに応じて自動的にスケールアップおよびスケールダウンするからです。また、サーバーレスのコスト効率はAlyxにとって非常に大きです。プレイ・あたしによるモデルにより、関数が消費する実際の計算時間に基づいてだけ料金を支払うことができます。これは、彼女の成長する事業に最適なコスト効率の解決策を提供します。
しかし、それだけではありません!彼女は、インフラのデプロイからアプリケーションの新しい変更による更新までをすべて自動化したいと考えています。Serverless Frameworkを使用してインフラ作为コード(IaC)を活用することで、すべてのインフラをコードで定義し、簡単に管理できるようになります。
それに加えて、GitHub Actionsを設定して、継続的な統合とデリvery(CI/CD)を行い、開発中の新機能やプロダクション用の热修复など、彼女が行うすべての変更が pipeline を通って自動的にデプロイされるようにしました。
チュートリアルの目的
-
Serverless Framework 環境の設定
-
YAML ファイルで API を定義する
-
AWS Lambda 関数を開発し、CRUD 操作を処理する
-
DevとProd用のマルチステージデプロイを設定する
-
DevとProdのパイプラインをテストする
-
Postmanを使用してDevとProd APIをテストし、確認する
はじめに:Git リポジトリをクローンする方法
理解を深め、このチュートリアルをより効果的に進めるために、私のGitHubからプロジェクトのリポジトリをクローンしてください。ここからできます。
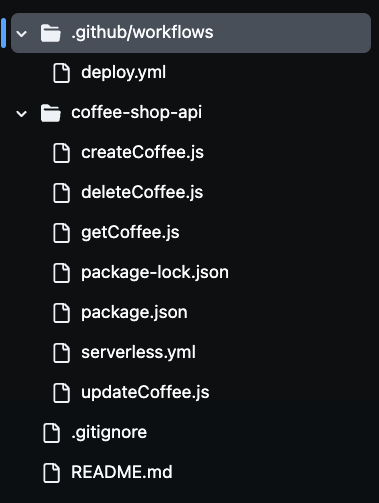
リポジトリをクローンした後、下の画像のようにフォルダ内に複数のファイルがあることに気づくでしょう。
ステップ1: Serverless Framework環境のセットアップ
自動デプロイのためにServerless Framework環境をセットアップするには、CLIを介してServerless Frameworkアカウントを認証する必要があります。
これには、CI/CDパイプラインを有効にし、認証情報を公開せずにアカウントに安全に認証するためにServerless Frameworkを利用するアクセスキーを作成する必要があります。サーバーレスアカウントにサインインしてアクセスキーを生成することで、パイプラインはビルド設定ファイルからサーバーレスアプリケーションを自動的にデプロイすることができます。
これを行うには、サーバーレスアカウントに向かい、アクセスキーセクションに移動します。
アクセスキーを作成したら、必ずコピーして安全に保管してください。このキーを GitHub リポジトリの秘密変数として使い、CI/CD パイプラインの認証や認可を行います。
デプロイプロセス中にServerless Frameworkアカウントへのアクセスが提供されます。後でGitHubリポジトリの秘密情報にこのキーを追加します。これにより、パイプラインは機密情報を露出することなく、無サーバーのリソースをデプロイする際に安全にこのキーを使用することができます。
次に、AWSリソースをseverless.yamlファイル内のコードとして定義しましょう。
ステップ2: Serverless YAMLファイル内でAPIを定義する
このファイルでは、Serverless FrameworkのYAML設定を使用して、コーヒーショップAPIの核心的なインフラストラクチャと機能を定義します。
このファイルは、API Gateway、CRUD操作用のLambda関数、以及びデータストレージ用のDynamoDBを含む利用されているAWSサービスを定義します。
また、IAMロールを設定して、Lambda関数がDynamoDBサービスとやりとりするために必要な権限を持つようにします。
API Gatewayは、受信リクエストを処理し、対応するLambda関数をトリガーする適切なHTTPメソッド(POST, GET, PUT, DELETE)で設定されています。
コードを確認しましょう:
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
serverless.ymlの設定は、AlyxのコーヒーショップAPIがAWS上の無サーバー環境でどのように実行されるかを定義します。providerセクションは、アプリケーションがAWSをクラウドプロバイダとして使用し、Node.jsをランタイム環境として指定します。
リージョンはus-east-1に設定されており、stage変数は開発環境(dev)や本番環境(prod)など異なる環境間で動的にデプロイすることを可能にします。これは、同じコードを異なる環境にデプロイし、リソースが衝突を避けるように適切に名付けられることを意味します。
iamセクションでは、Lambda関数がDynamoDBテーブルとやりとりする権限が付与されています。${self:provider.stage}構文はDynamoDBテーブルの名前を動的に設定し、各環境に独自のリソースがあり、開発環境用のCoffeeOrders-devや本番環境用のCoffeeOrders-prodなどになります。この動的な名前付けは、各環境用に別のテーブルを手動で設定することなく、複数の環境を管理するのに役立ちます。
functionsセクションでは、4つの主要なLambda関数createCoffee、getCoffee、updateCoffee、deleteCoffeeが定義されています。これらは、コーヒーショップAPIのCRUD操作を処理します。
各関数は、APIゲートウェイ内の特定のHTTPメソッドに接続されており、POST、GET、PUT、DELETEなどです。これらの関数は、現在のステージに基づいて動的に名前付けられたDynamoDBテーブルとやりとりします。
最後のresourcesセクションでは、DynamoDBテーブル自体を定義しています。これにはOrderIdとCustomerName属性があり、これらは主キーとして使用されます。テーブルは、要求ごとに料金を請求するモードを設定されており、Alyxの成長するビジネスには効果的なコストとなります。
これらのリソースのデプロイをServerless Frameworkを使用して自動化することで、Alyxはインフラストラクチャを簡単に管理でき、リソースの手動のプロビジョニングとスケーリングの負担から解放されます。
ステップ3:CRUD操作のLambda関数を開発
このステップでは、JavaScriptでLambda関数を作成して、AlyxのコーヒーショップAPIの核心ロジックを実装します。これらの関数はcreateCoffee、getCoffee、updateCoffee、およびdeleteCoffeeという基本的なCRUD操作を行います。
これらの関数は、特にDynamoDBと対話するためにAWS SDKを使用します。各関数は、新しい注文の作成、注文の取得、注文状況の更新、注文の削除など、特定のAPIリクエストを処理する責任があります。
コーヒー作成Lambda関数
この関数は注文を作成します:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order created successfully!', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not create order: ${error.message}` })
};
}
};
このLambda関数はDynamoDBテーブルに新しいコーヒー注文を作成することを処理します。まずAWS SDKをimportし、DynamoDBと対話するためにDynamoDB.DocumentClientを初期化します。また、一意の注文IDを生成するためにuuidライブラリもimportされます。
handler関数の内部で、来るリクエストボディを解析して、顧客の名前や好みのコーヒーブレンドなどの顧客情報を抽出します。一意のorderIdはuuidv4()を使用して生成され、DynamoDBに挿入するためのデータを準備します。
paramsオブジェクトは、データを格納するテーブルを定義します。TableNameは環境変数COFFEE_ORDERS_TABLEの値に動的に設定されます。新しい注文にはOrderId、CustomerName、CoffeeBlendなどのフィールドが含まれ、初期のステータスはPendingです。
tryブロック内で、コードはput()メソッドを使用してDynamoDBテーブルに注文を追加しようとします。成功すると、関数は200のステータスコードと成功メッセージとOrderIdを返します。エラーがある場合、コードはそれを捕まえてOrderIdとともに500のステータスコードとエラーメッセージを返します。
コーヒーを取得するLambda関数
この関数はすべてのコーヒーアイテムを取得します:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not retrieve orders: ${error.message}` })
};
}
};
このLambda関数は、DynamoDBテーブルからすべてのコーヒー注文を取得し、DynamoDBからデータを取得する無服务器の方法を示しています。
再び、AWS SDKを使用してDynamoDB.DocumentClientインスタンスを初期化し、DynamoDBとやり取りするようにします。handler関数はparamsオブジェクトを構築し、TableNameを指定します。これはCOFFEE_ORDERS_TABLE環境変数を使用して動的に設定されます。
scan()メソッドは、テーブルからすべてのアイテムを取得します。もう一度、操作が成功する場合、機能はJSON形式で取得したアイテムとともに200のステータスコードを返します。エラーが発生した場合、500ステータスコードとエラーメッセージが返されます。
コーヒーLambda機能の更新
この機能は、IDに基づいてコーヒーアイテムを更新します。
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order status updated successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not update order: ${error.message}` })
};
}
};
このLambda機能は、DynamoDBテーブルで特定のコーヒーオーダーのステータスを更新するための処理を処理します。
ハンドラ関数は、リクエストボディからorder_id、new_status、customer_nameを抽出します。それから、paramsオブジェクトを構築し、テーブル名と注文の主キー(OrderIdとCustomerNameを使用)を指定します。UpdateExpressionは、注文的なステータスを設定します。
tryブロックで、update()メソッドを使用してDynamoDBに注文を更新しようとします。もちろん、成功すると、機能は200のステータスコードと成功メッセージとともに返ります。エラーが発生した場合、それはエラーを捕らえ、500ステータスコードとエラーメッセージとともに返ります。
コーヒーLambda機能の削除
この機能は、IDに基づいてコーヒーアイテムを削除します。
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order deleted successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not delete order: ${error.message}` })
};
}
};
Lambda関数は、DynamoDBテーブルから特定のコーヒーオーダーを削除します。ハンドラ関数内で、コードはリクエストボディを解析してorder_idとcustomer_nameを抽出します。これらの値は、削除するアイテムを识別するための主キーとして使用されます。paramsオブジェクトは、削除するアイテムのテーブル名とキーを指定します。
tryブロック内で、delete()メソッドを使用してDynamoDBからオーダーを削除しようとします。成功すると、再度200ステータスコードと成功メッセージを返し、オーダーが削除されたことを示します。エラーが発生した場合、コードはそれを捕まえて500ステータスコードとエラーメッセージとともに返します。
今度は各Lambda関数を説明したので、マルチステージのCI/CDパイプラインを設定しましょう。
手順4: DevとProd環境のマルチステージCI/CDパイプラインの設定
GitHubリポジトリにAWSの秘密を設定するには、まずリポジトリの設定に移動します。右上にSettingsを選択し、左下にSecrets and variables.を選択します。

次に、以下の画像のようにActionsをクリックします。
そこから、New repository secretを選択して秘密を作成します。
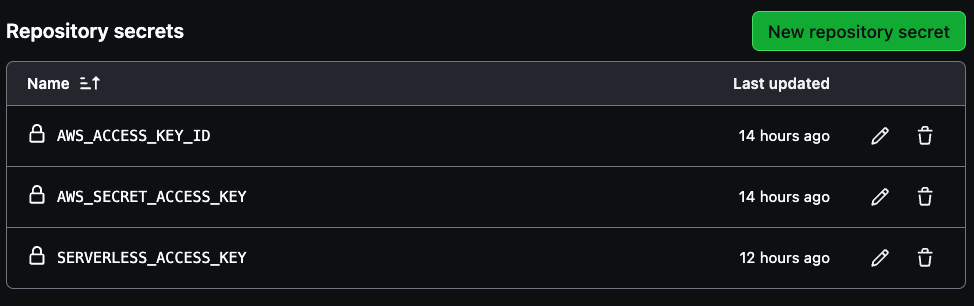
パイプラインを作成するために3つの秘密が必要です。それは、AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY、SERVERLESS_ACCESS_KEYです。
アカウントのAWSアクセスキー認証情報を最初の2つの変数に使用し、保存済みのサーバーレスアクセスキーを使用してSERVERLESS_ACCESS_KEYを作成します。これらの秘密情報は、以下の画像に示されるように、CI/CDパイプラインの安全な認証を行います。
主なブランチを“main”と名付け、これをプロダクションブランチとして使用してください。次に、開発作業用に“dev”という新しいブランチを作成します。
また、より細分化された開発のために“dev/feature”のような機能固有のブランチを作成することもできます。GitHub Actionsはこれらのブランチを使用して自動的に変更をデプロイし、devは開発環境を、mainはプロダクションを表します。
このブランチング戦略により、devやprod環境にマージが行われるたびに新しいコード変更をデプロイすることができ、CI/CDパイプラインを効率的に管理することができます。
GitHub Actionsを使用してYAMLファイルをデプロイする方法
Coffee Shop APIのデプロイプロセスを自動化するために、GitHub Actionsを使用します。これはGitHubリポジトリと統合されます。
このデプロイパイプラインは、mainまたはdevブランチにコードがプッシュされるたびにトリガーされます。環境固有のデプロイを設定することで、devブランチへの更新が開発環境にデプロイされ、mainブランチへの変更がプロダクションデプロイをトリガーするようになります。
では、コードを確認しましょう。
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
GitHub ActionsのYAML設定は、Coffee Shop APIをAWSにServerless Frameworkを使用してデプロイするプロセスを自動化します。 workflowは、メインまたは開発ブランチに変更が推送されるたびに発生します。
これは、リポジトリのコードをチェックアウトし、Node.jsのバージョン20.xを設定して、Lamba関数で使用されているランタイムに合わせます。その後、coffee-shop-apiディレクトリに移動してnpm installを実行してプロジェクト依存性をインストールします。
また、WorkflowはServerless Frameworkをgloballyインストールし、serverless CLIの使用を許可します。更新されたブランチによって、適切な環境に条件付きでデプロイを行います。
変更が開発ブランチに推送された場合、開発ステージにデプロイします。メインブランチに推送された場合は、プロダクションステージにデプロイします。デプロイコマンド、npx serverless deploy --stage devまたはnpx serverless deploy --stage prodは、coffee-shop-apiディレクトリ内で実行されます。
安全なデプロイには、GitHub Secretsに格納された環境変数を通じてAWS資格とServerlessアクセスキーにアクセスします。これにより、CI/CDパイプラインはAWSとServerless Frameworkに対して認証を行い、リポジトリ内に敏感な情報を exposureする必要はありません。
今、パイプラインのテストを行うことができます。
ステップ5: 開発とプロダクションのパイプラインをテストします。
まず、メイン(本番)ブランチが「main」と呼ばれていることを確認する必要があります。次に、「dev」という名前の開発ブランチを作成します。有効な変更をdevブランチに行ったら、それをコミットしてGitHub Actionsパイプラインをトリガーします。これにより、更新されたリソースが自動で開発環境にデプロイされます。devですべてを確認した後、devブランチをmainブランチにマージできます。
変更をメインブランチにマージすると、本番環境のデプロイメントパイプラインも自動的にトリガーされます。これにより、必要なすべての更新が適用され、本番リソースがシームレスにデプロイされます。
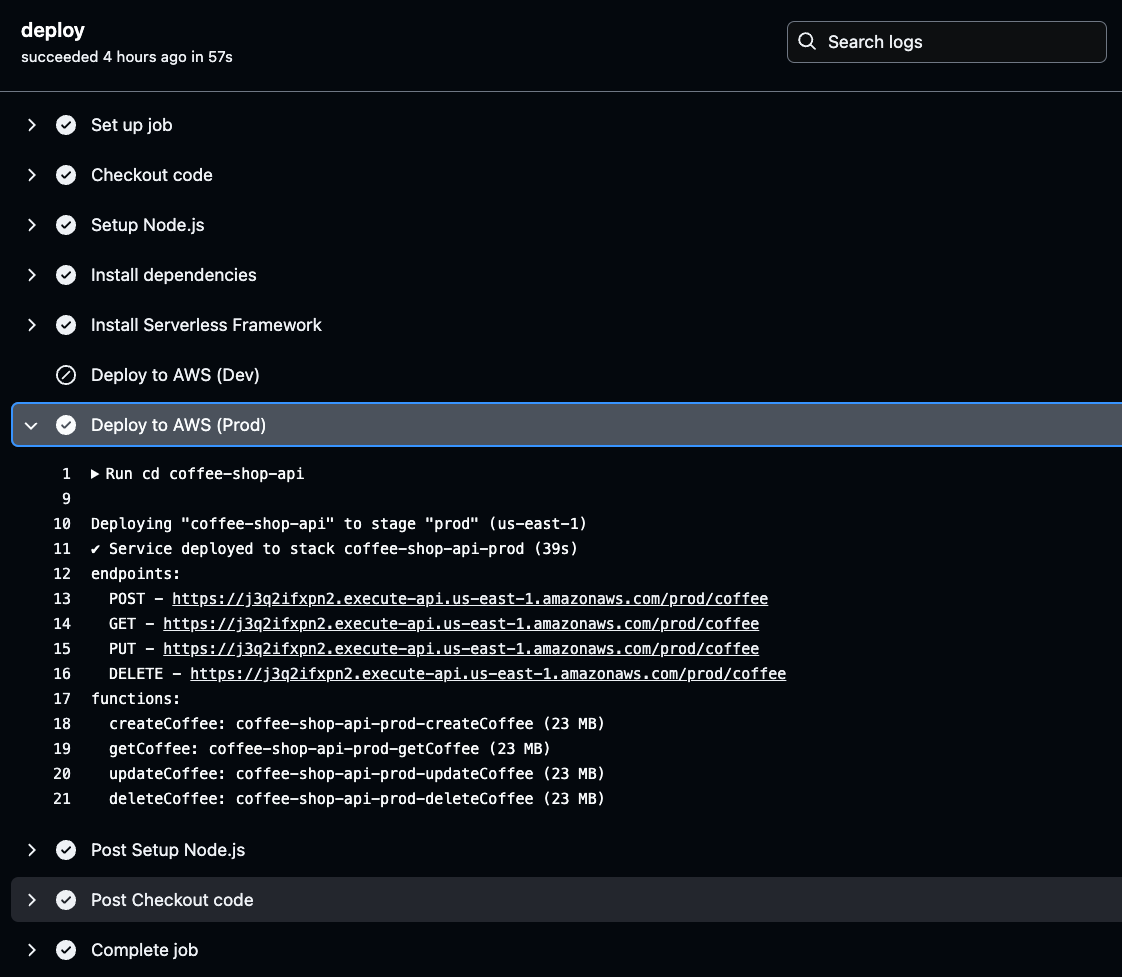
GitHubリポジトリのActionsタブに移動して、デプロイプロセスを監視し、各GitHub Actions実行の詳細なログを確認できます。
ログは、パイプラインの各ステップに対する可視性を提供し、すべてが予想どおりに動作していることを確認するのに役立ちます。
開発環境と本番環境のデプロイメントの詳細なログを確認するために、任意のビルド実行を選択できます。進行状況を追跡し、すべてがスムーズに動作していることを確認できます。
GitHub Actionsの特定のビルド実行に移動して、以下の画像で示されているように、実行の詳細と結果を表示できます。そこで、開発または本番のパイプラインに関する実行の詳細なログを確認できます。

パイプラインの実行が成功したことを確認するために、開発環境と本番環境の両方を徹底的にテストしてください。
ステップ6:Postmanを使用して、DevおよびProdのAPIをテストおよび検証します。
APIとリソースがデプロイされ設定された後、AWSによって生成された一意のAPIエンドポイント(URL)を特定する必要があります。これにより、機能テストのためのリクエストを開始できます。
これらのURLをWebブラウザに貼り付けるだけでAPIの機能をテストすることができます。APIのURLは、CI/CDビルドの出力結果にあります。
これらを取得するには、GitHub Actionsのログに移動し、最新の環境の成功したビルドを選択し、deployをクリックして生成されたAPIエンドポイントのデプロイ詳細を確認します。
GitHub Actionsのログで選択した環境(ProdまたはDev)のDeploy to AWSステージをクリックします。そこには生成されたAPI URLがあります。
このURLをコピーして保存しておきます。これはAPIの機能をテストする際に必要です。このURLは、デプロイされたAPIが期待通りに動作していることを確認するためのゲートウェイです。
生成されたAPI URLの1つをコピーし、ブラウザに貼り付けます。レスポンスとして空の配列またはリストが表示されます。これは実際にAPIが正しく機能しており、DynamoDBテーブルからデータを正常に取得していることを確認します。
リストが空であっても、APIがデータベースに接続できて情報を返すことができることを示しています。
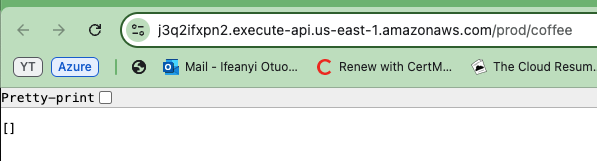
APIが両方の環境で動作することを確認するために、他のAPI環境(ProdとDev)についても同じ手順を繰り返します。
Postmanを使用して、すべてのAPIメソッドをテストします。作成、読み取り、更新、および削除を開発環境と生成環境の両方で実行します。
GETメソッドをテストするために、Postmanを使用してURLでAPIのエンドポイントにGETリクエストを送信します。以下の画像の下部に示されるように、空のコーヒー注文リストが返信されます。これは、以下の画像に示されるように、APIがデータを正常に取得する能力を確認します。

実際の注文を作成するために、POSTメソッドをテストしましょう。再度Postmanを使用して、APIエンドポイントにPOSTリクエストを行い、以下に示されるように、リクエストボディに顧客名とコーヒーブレンドを提供します:
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
返信は、注文された注文の一意のOrderIdと共に成功メッセージです。
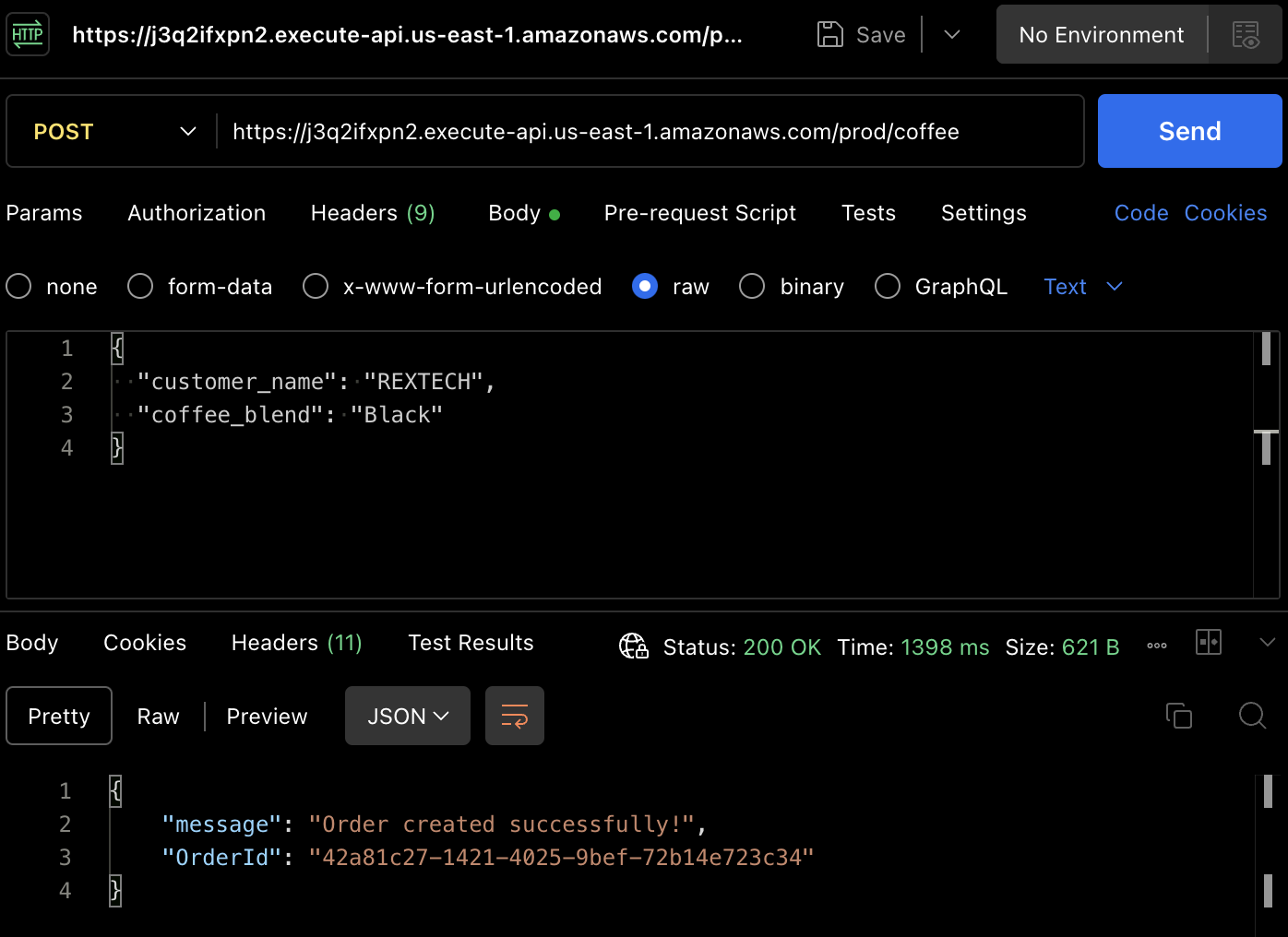
新しい注文が特定の環境のテーブルに保存されたことを、DynamoDBテーブルのアイテムを確認して確認します。

PUTメソッドをテストするために、以下に示されるように、前の注文IDと新しい注文ステータスをリクエストボディに提供してAPIエンドポイントにPUTリクエストを行います:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
返信は、注文された注文のOrderIdと共に注文更新の成功メッセージです。
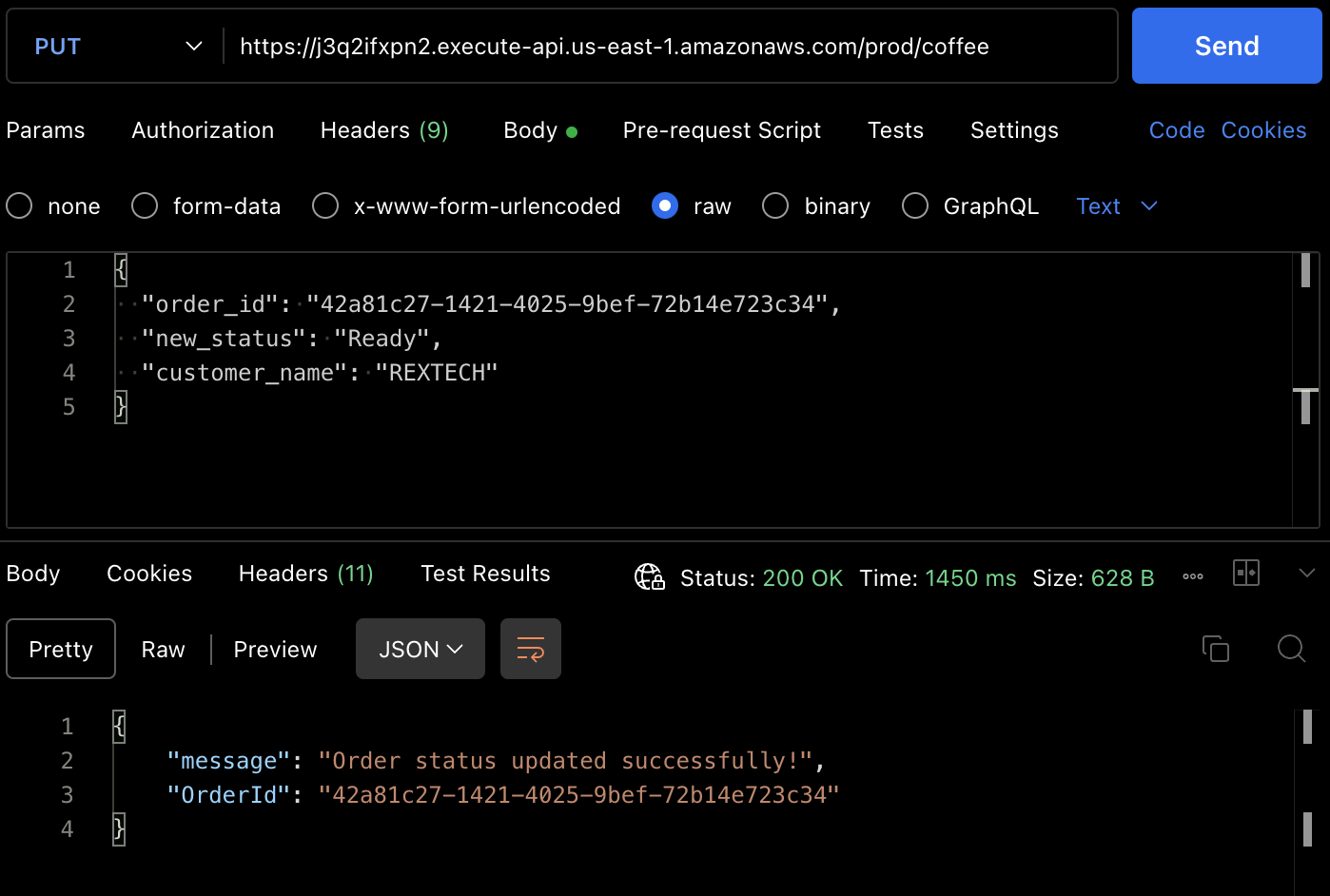
また、DynamoDBテーブルのアイテムから注文ステータスが更新されたことも確認できます。

DELETEメソッドをテストするために、Postmanを使用して、以下に示されるように、前の注文IDと顧客名をリクエストボディに提供してDELETEリクエストを行います:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
注文が削除され成功しました。
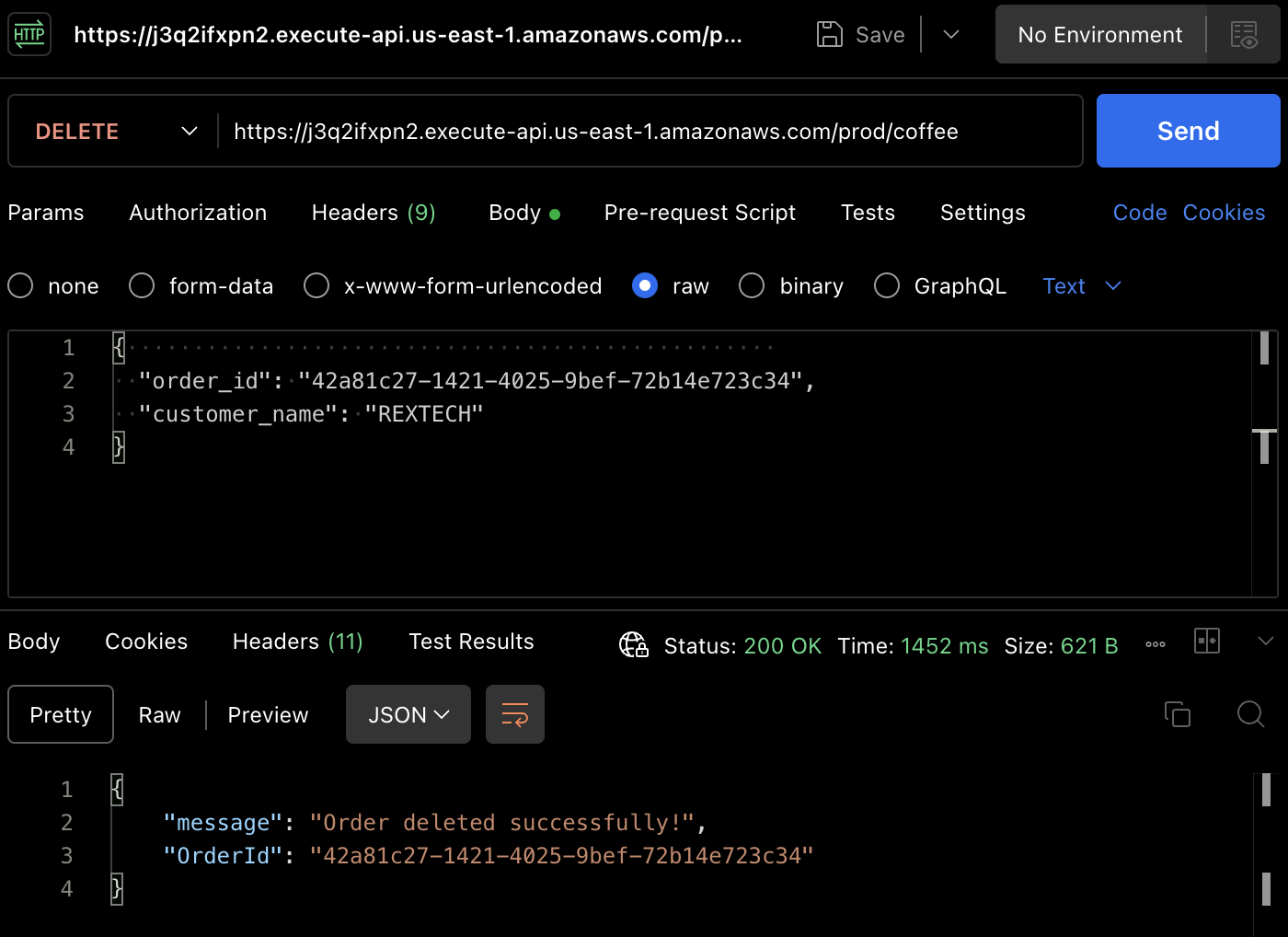
再度、DynamoDB テーブルで注文が削除されたことを確認することができます。

結論
これで完了しました。API Gateway、Lambda、DynamoDB、Serverless Framework および Node.js を使用して CRUD (Create, Read, Update, Delete)機能をサポートするサーバーレス REST API を構築し、Github Actions を使用して承認されたコード変更の自動部署を実装しました。
これまでに読んだことがあれば、ありがとうございます!有益でしたか?
Ifeanyi Otuonyeは、DevOps、技術書寫、そして技術指導に精通した 6X AWS 認定クラウドエンジニアです。彼は学び続けることと開発に取り組むことが動機づけられ、協力の環境に适しています。クラウドに移行する前は、6年間のプロフESSIONAL TRACK AND FIELD 選手でした。
2022年初めに、自習と6ヶ月の加速クラウドプログラムに参加して、CLOUD/DEVOPS エンジニアになるための計画的なミッションを立てました。
2023年5月に、その目標を達成して、最初のクラウドエンジニアの役を得ました。そして今、他の人々がクラウドへの道を探るために力量を提供することを個人的な使命にしています。
Source:
https://www.freecodecamp.org/news/how-to-build-a-serverless-crud-rest-api/