













参考にする:接続プールの高可用性について議論した以前の記事をチェックしてください、”CockroachDBとPgCatによる接続プールの高可用性.”
動機
ロードバランサはCockroachDBの中心的なアーキテクチャの一部です。その重要性から、SPOFシナリオを克服する方法について議論したいと思います。
大まかな手順
- DockerでCockroachDBとHAProxyを開始する
- ワークロードを実行する
- 障害耐性を示す
- 結論
ステップバイステップの手順
DockerでCockroachDBとHAProxyを開始する
I have a Docker Compose environment with all of the necessary services here. Primarily, we are adding a second instance of HAProxy and overriding the ports not to overlap with the existing load balancer in the base Docker Compose file.
I am in the middle of refactoring my repo to remove redundancy and decided to split up my Compose files into a base docker-compose.yml and any additional services into their own YAML files.
lb2:
container_name: lb2
hostname: lb2
build: haproxy
ports:
- "26001:26000"
- "8082:8080"
- "8083:8081"
depends_on:
- roach-0
- roach-1
- roach-2
以下を実行してコンポーズ環境を開始する必要があります。
docker compose -f docker-compose.yml -f docker-compose-lb-high-availability.yml up -d --build
以下のサービスのリストが表示されます。
✔ Network cockroach-docker_default Created 0.0s ✔ Container client2 Started 0.4s ✔ Container roach-1 Started 0.7s ✔ Container roach-0 Started 0.6s ✔ Container roach-2 Started 0.5s ✔ Container client Started 0.6s ✔ Container init Started 0.9s ✔ Container lb2 Started 1.1s ✔ Container lb Started
以下の図は、全体のクラスタトポロジを示しています。
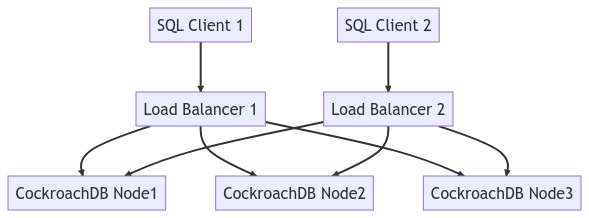
ワークロードを実行する
この時点で、クライアントの1つに接続してワークロードを初期化できます。書き込みおよび読み取りトラフィックを示すのに優れたワークロードであるtpccを使用しています。
cockroach workload fixtures import tpcc --warehouses=10 'postgresql://root@lb:26000/tpcc?sslmode=disable'
次に、両方のクライアントコンテナからワークロードを開始できます。
- ロードバランサ1:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable'
- ロードバランサ2:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
以下のような出力が表示されます。
488.0s 0 1.0 2.1 44.0 44.0 44.0 44.0 newOrder 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 488.0s 0 2.0 2.1 11.0 16.8 16.8 16.8 payment 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel 489.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 delivery 489.0s 0 2.0 2.1 15.2 17.8 17.8 17.8 newOrder 489.0s 0 1.0 0.2 5.8 5.8 5.8 5.8 orderStatus
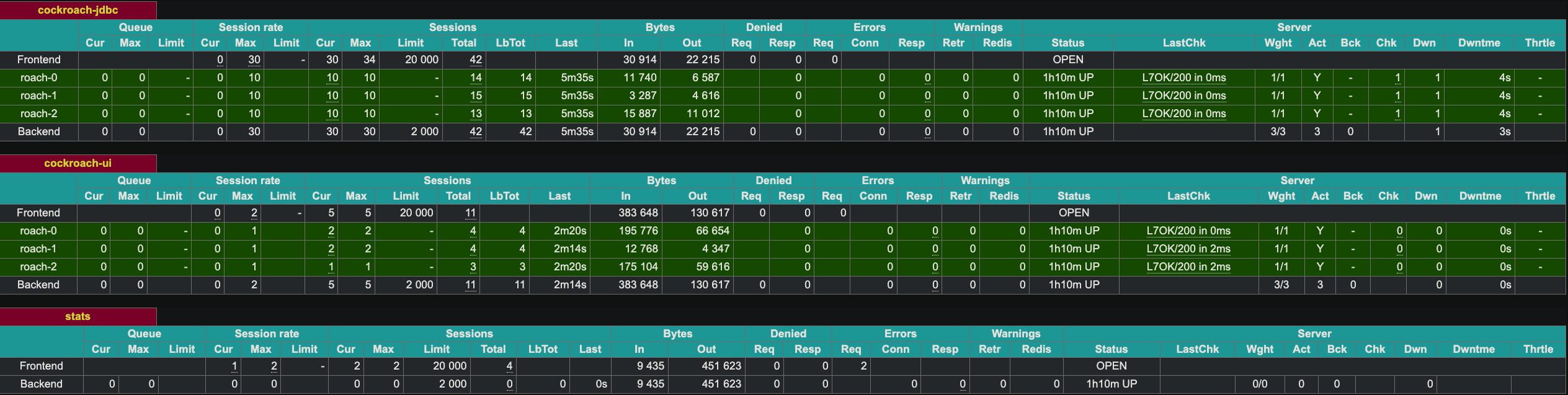
各HAProxyインスタンスのログは、以下のような内容が表示されます。
192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/0 28724 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/816 28846 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:40.744] stats stats/<STATS> 0/0/553 28900 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:41.297] stats stats/<STATS> 0/0/1545 28898 LR 2/2/0/0/0 0/0 192.168.160.1:60582 [27/Apr/2023:14:51:39.927] stats stats/<NOSRV> -1/-1/61858 0 CR 2/2/0/0/0 0/0
HAProxyはポート8081でWeb UIを公開しています。HAProxyのインスタンスが2つあるため、2番目のインスタンスをポート8083で公開しました。
障害耐性の実証
これでHAProxyインスタンスを終了して、障害耐性を実証できます。インスタンス1から始めましょう。
docker kill lb lb
ワークロードはエラーメッセージを開始します。
7 17:41:18.758669 357 workload/pgx_helpers.go:79 [-] 60 + RETURNING d_tax, d_next_o_id] W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 error preparing statement. name=new-order-1 sql= W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + UPDATE district W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + SET d_next_o_id = d_next_o_id + 1 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + WHERE d_w_id = $1 AND d_id = $2 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + RETURNING d_tax, d_next_o_id unexpected EOF 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 delivery 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 newOrder 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 payment
ワークロードはまだHAProxy 2接続を使用して実行されています。
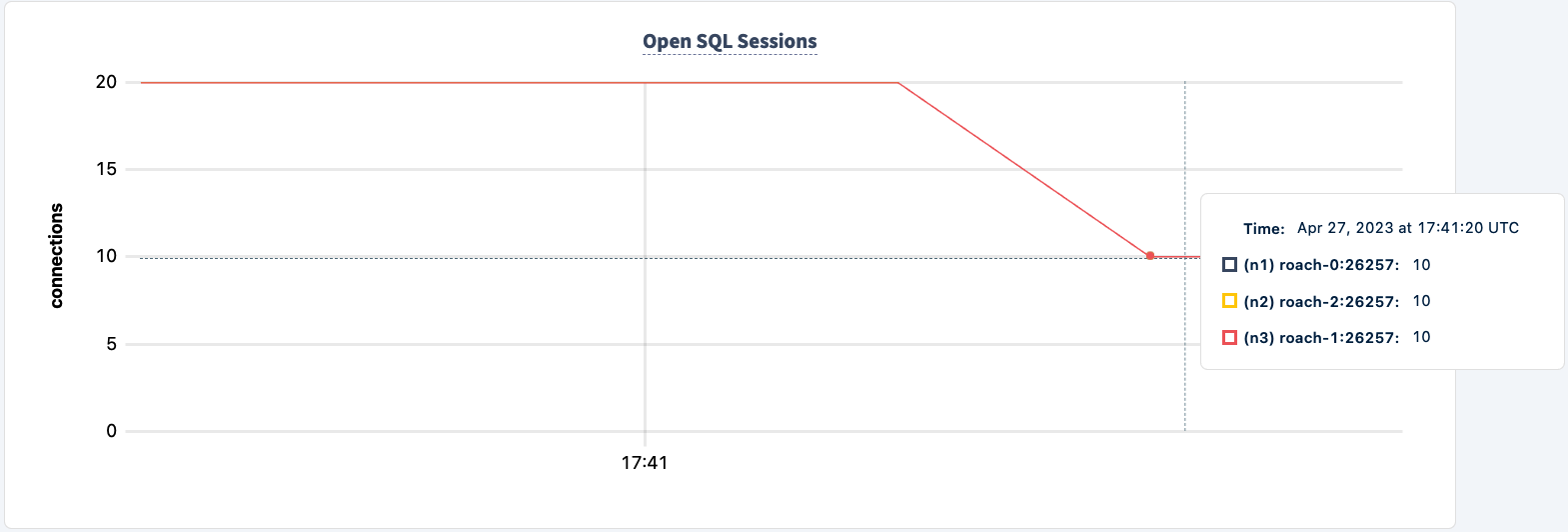
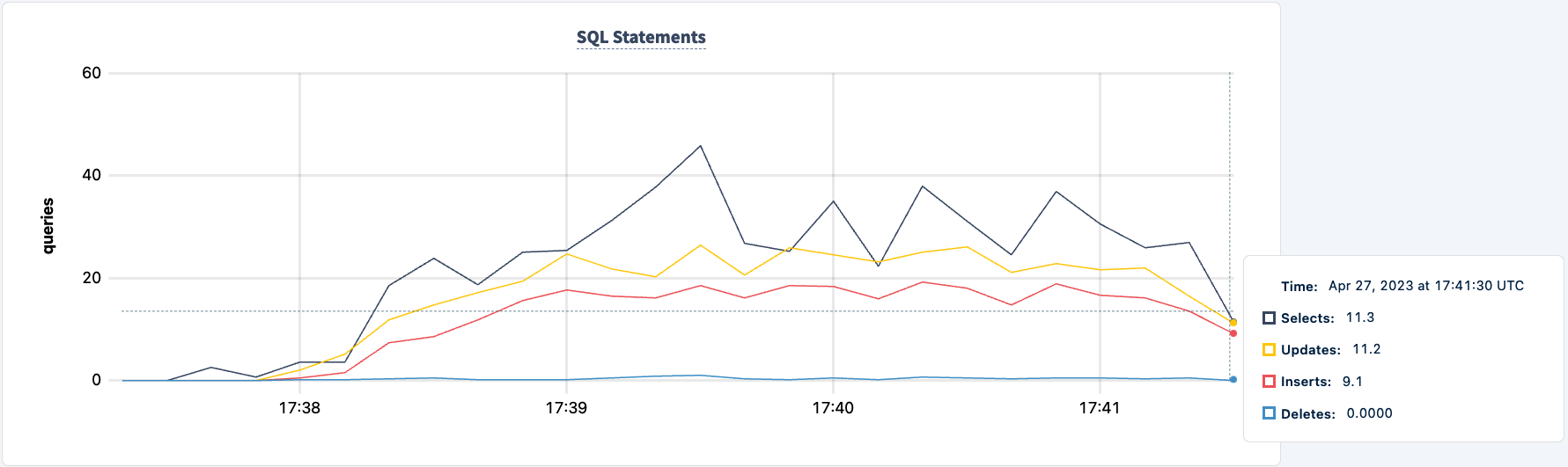
再起動しましょう:
docker start lb
クライアントが再接続してワークロードを継続するのに気付くでしょう。
335.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 336.0s 1780 7.0 1.1 19.9 27.3 27.3 27.3 newOrder 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 orderStatus 336.0s 1780 2.0 1.0 10.5 11.0 11.0 11.0 payment 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel 337.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 337.0s 1780 7.0 1.1 21.0 32.5 32.5 32.5 ne
2番目のクライアントが正常に接続すると実行されたステートメントの数が増加します。
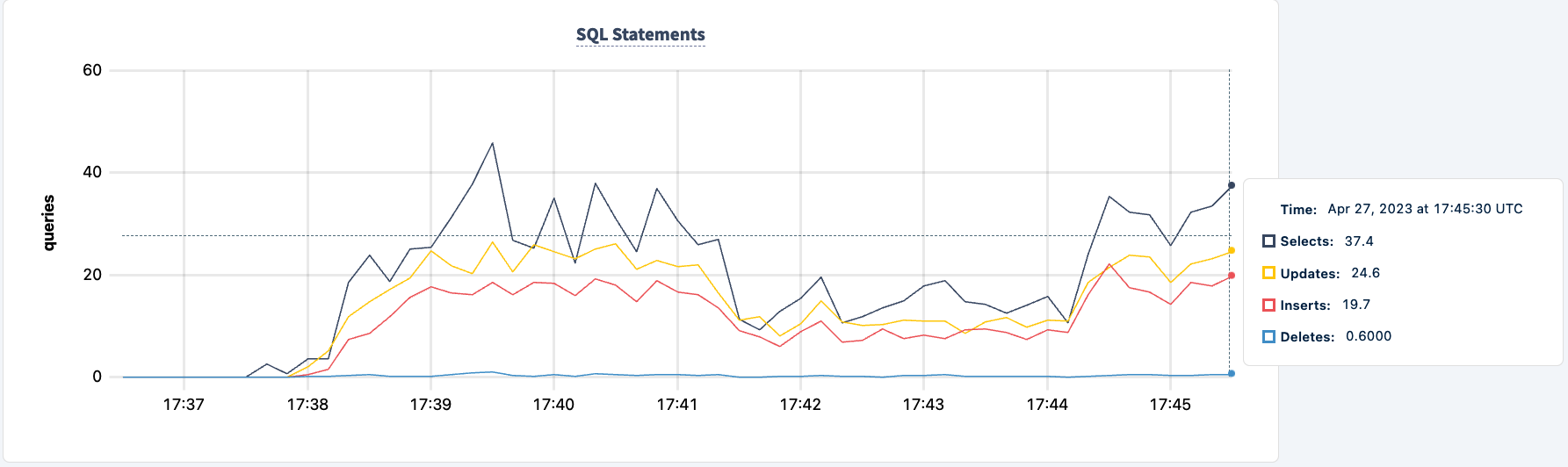
次に、2番目のインスタンスでも同じことができます。同様に、ワークロードはlb2ホストが見つからないというエラーを報告します。
0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:48:28.239032 403 workload/pgx_helpers.go:79 [-] 188 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host] I230427 17:48:28.267355 357 workload/pgx_helpers.go:79 [-] 189 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host]
そして、ステートメント数の減少を観察できます。
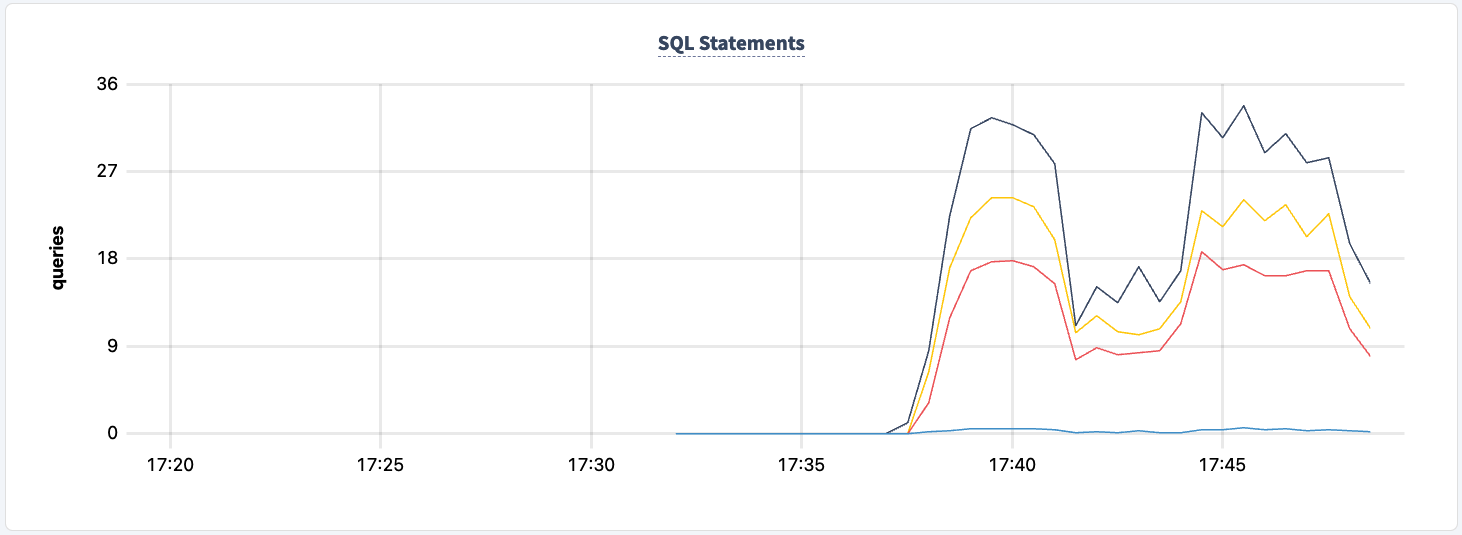
再起動できます:
docker start lb2
改善できる点の1つは、両方の接続文字列でワークロードを開始することです。これにより、HAProxyインスタンスの1つが停止していても、各クライアントが他のpgurlインスタンスにフェイルバックできます。私たちがしなければならないのは、両方のクライアントを停止し、両方の接続文字列で再起動することです。
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable' 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
I am going to do that one client at a time so that the workload does not exit completely.
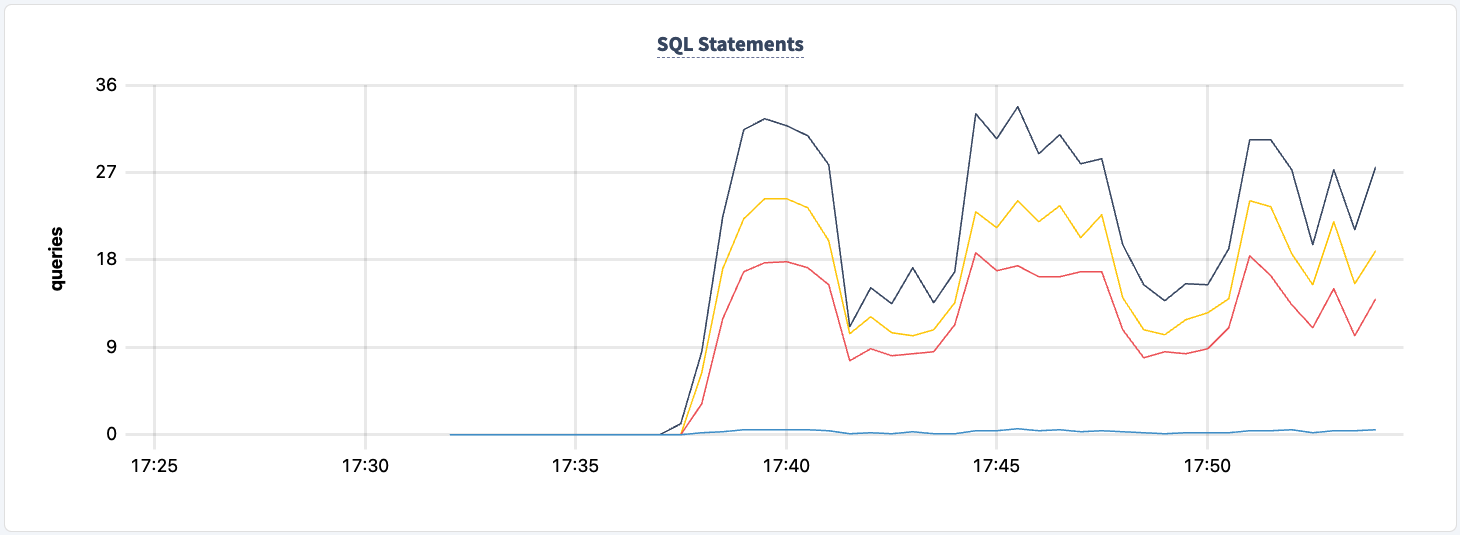
この実験のどの時点でも、クラスターへの読み取り/書き込み能力を失ったことはありません。HAProxyインスタンスの1つを再びシャットダウンして、影響を見てみましょう。
docker kill lb lb
I’m now seeing errors across both clients, but both clients are still executing.
.817268 1 workload/cli/run.go:548 [-] 85 error in stockLevel: lookup lb on 127.0.0.11:53: no such host _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 delivery 156.0s 49 1.0 2.1 31.5 31.5 31.5 31.5 newOrder 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 156.0s 49 1.0 2.0 12.1 12.1 12.1 12.1 payment 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:55:58.558209 354 workload/pgx_helpers.go:79 [-] 86 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.698731 346 workload/pgx_helpers.go:79 [-] 87 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.723643 386 workload/pgx_helpers.go:79 [-] 88 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.726639 370 workload/pgx_helpers.go:79 [-] 89 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.789717 364 workload/pgx_helpers.go:79 [-] 90 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.841283 418 workload/pgx_helpers.go:79 [-] 91 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host]
再起動でき、ワークロードが回復するのに気付くでしょう。
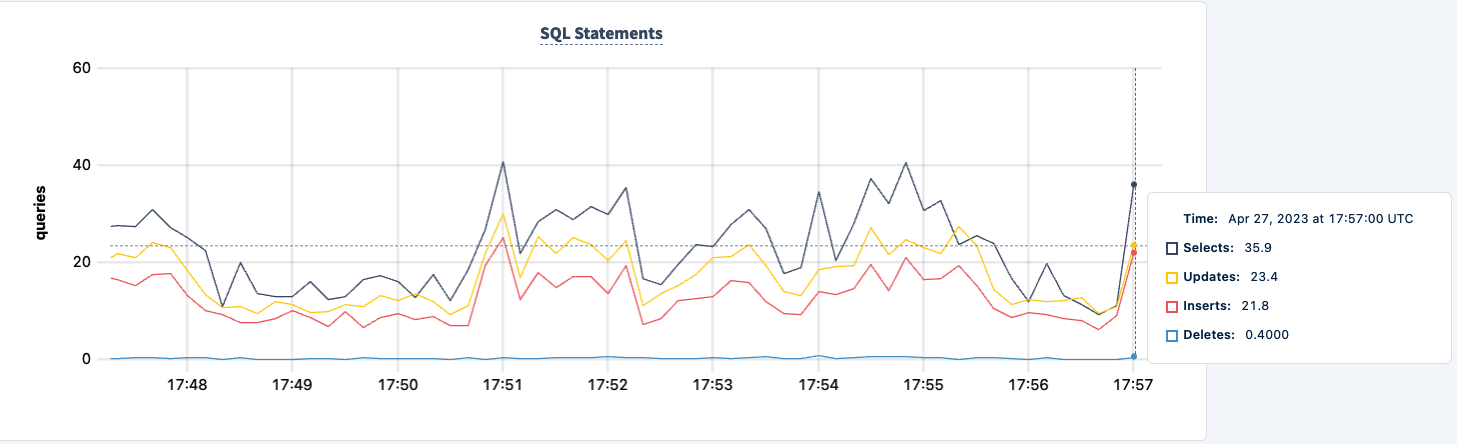
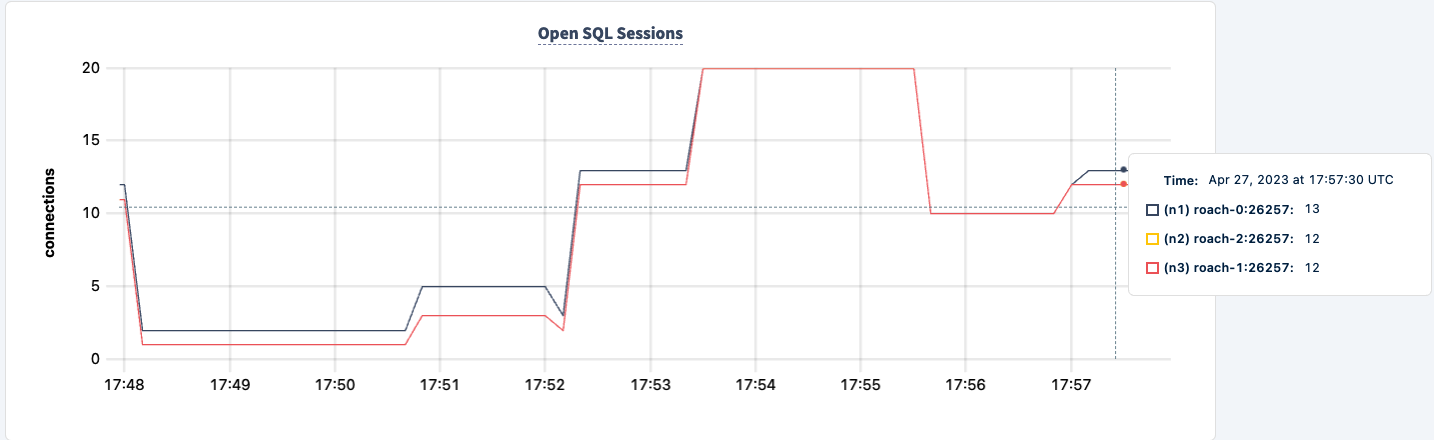
結論
実験全体を通じて、データベースへの読み書き能力を失っていませんでした。トラフィックには落ち込みがありましたが、それは予想されることです。ここでの教訓は、クライアントが複数の接続を見ることができる高可用性の構成を提供することです。
Source:
https://dzone.com/articles/load-balancer-high-availability-with-cockroachdb-a